
Introduction
Ce document explique comment créer une solution de sélection de sites en combinant l'ensemble de données Places Insights, des données géospatiales publiques dans BigQuery, et l'API Place Details.
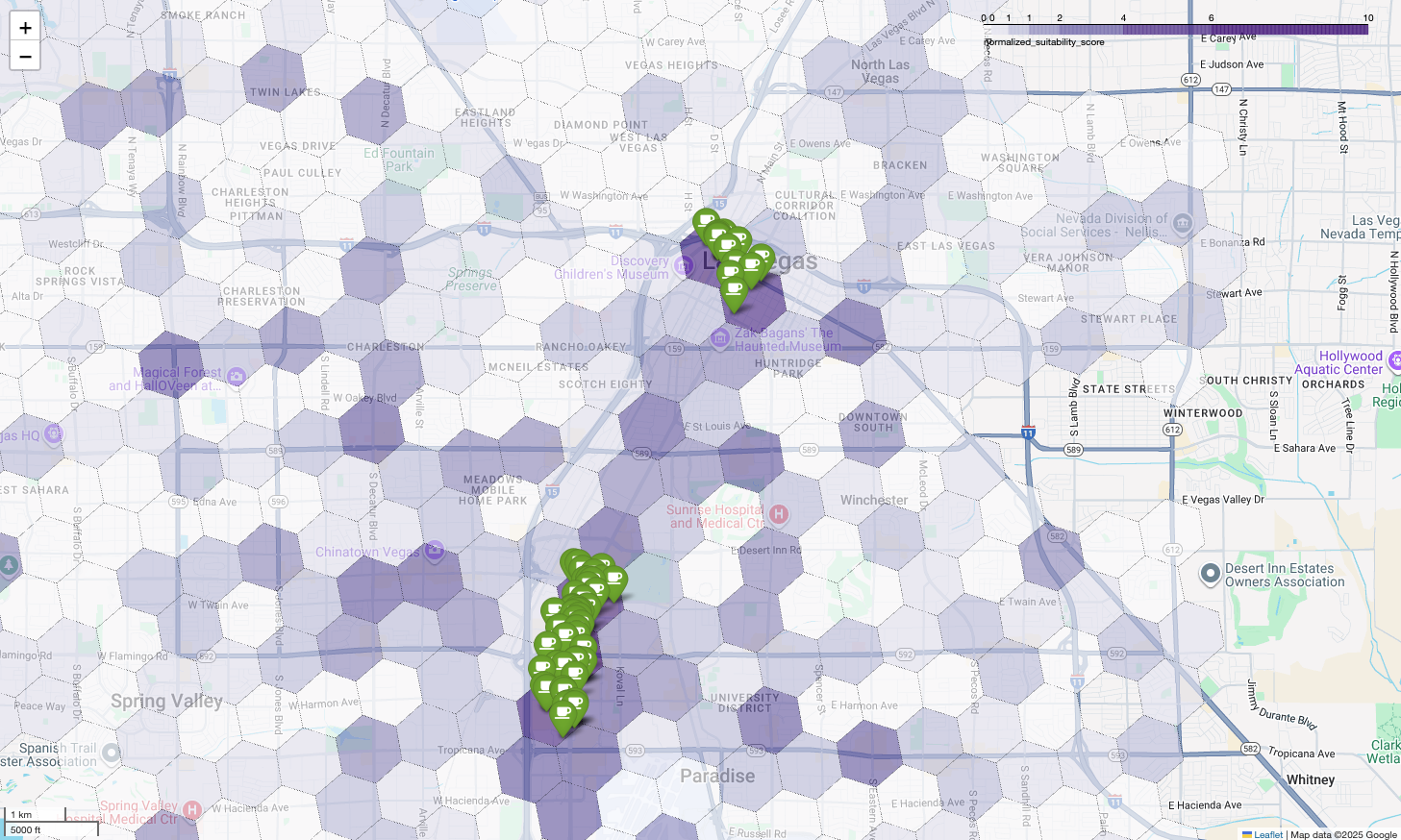
La carte ci-dessus illustre le résultat d'une démonstration présentée lors de Google Cloud Next 2025, qui est disponible sur YouTube. Vous pouvez exécuter le code utilisé pour générer ces résultats à l'aide de l'exemple de notebook.
 Afficher la source sur GitHub
Afficher la source sur GitHub
Le défi de l'entreprise
Imaginez que vous possédez une chaîne de cafés à succès et que vous souhaitez vous étendre à un nouvel État, comme le Nevada, où vous n'êtes pas encore présent. L'ouverture d'un nouvel établissement représente un investissement important. Il est donc essentiel de prendre une décision basée sur les données pour réussir. Et par où commencer ?
Ce guide vous explique comment effectuer une analyse à plusieurs niveaux pour identifier l'emplacement optimal d'un nouveau café. Nous commencerons par une vue à l'échelle de l'État, puis nous affinerons progressivement notre recherche jusqu'à un comté et une zone commerciale spécifiques. Enfin, nous effectuerons une analyse hyperlocale pour évaluer les zones individuelles et identifier les lacunes du marché en cartographiant les concurrents.
Solution workflow
Ce processus suit un entonnoir logique, en commençant par une recherche large, puis en devenant progressivement plus précis pour affiner la zone de recherche et renforcer la confiance dans la sélection finale du site.
Prérequis et configuration de l'environnement
Avant de commencer l'analyse, vous avez besoin d'un environnement doté de quelques fonctionnalités clés. Bien que ce guide présente une implémentation à l'aide de SQL et de Python, les principes généraux peuvent être appliqués à d'autres piles technologiques.
Assurez-vous que votre environnement peut effectuer les opérations suivantes :
- Exécuter des requêtes dans BigQuery
- Accéder à Places Insights. Pour en savoir plus, consultez Configurer Places Insights.
- S'abonner aux ensembles de données publics de
bigquery-public-dataet aux totaux de population par comté du Bureau du recensement des États-Unis
Vous devez également être en mesure de visualiser les données géospatiales sur une carte, ce qui est essentiel pour interpréter les résultats de chaque étape analytique. Il existe de nombreuses façons d'y parvenir. Vous pouvez utiliser des outils de BI comme Looker Studio, qui se connectent directement à BigQuery, ou des langages de science des données comme Python.
Analyse au niveau de l'État : trouver le meilleur comté
La première étape consiste à effectuer une analyse générale pour identifier le comté le plus prometteur du Nevada. Nous définissons le terme prometteur comme une combinaison d'une population élevée et d'une forte densité de restaurants existants, ce qui indique une culture gastronomique forte.
Notre requête BigQuery y parvient en exploitant les composants d'adresse intégrés disponibles dans l'ensemble de données Places Insights. La requête compte les restaurants en filtrant d'abord les données pour n'inclure que les établissements situés dans l'État du Nevada, à l'aide du champ administrative_area_level_1_name. Elle affine ensuite cet ensemble pour n'inclure que les établissements dont le tableau de types contient 'restaurant'. Enfin, elle regroupe ces résultats par nom de comté (administrative_area_level_2_name) pour produire un décompte pour chaque comté. Cette approche utilise la structure d'adresse intégrée et pré-indexée de l'ensemble de données.
Cet extrait montre comment nous associons les géométries de comté à Places Insights et filtrons un type de lieu spécifique, restaurant :
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Un décompte brut des restaurants ne suffit pas. Nous devons l'équilibrer avec les données démographiques pour avoir une idée précise de la saturation et des opportunités du marché. Nous utiliserons les données démographiques des totaux de population par comté du Bureau du recensement des États-Unis .
Pour comparer ces deux métriques très différentes (un décompte de lieux par rapport à un grand nombre de personnes), nous utilisons la normalisation min-max. Cette technique met à l'échelle les deux métriques dans une plage commune (de 0 à 1). Nous les combinons ensuite en un seul normalized_score, en attribuant à chaque métrique une pondération de 50 % pour une comparaison équilibrée.
Cet extrait montre la logique de base pour calculer le score. Il combine les décomptes normalisés de la population et des restaurants :
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Une fois la requête complète exécutée, une liste des comtés, du nombre de restaurants, de la population et du score normalisé est renvoyée. Le tri par normalized_score
DESC révèle que le comté de Clark est le grand gagnant pour une étude plus approfondie en tant que
principal candidat.
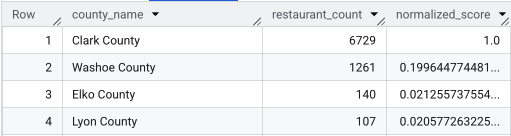
Cette capture d'écran montre les quatre principaux comtés par score normalisé. Le décompte brut de la population a été volontairement omis de cet exemple.
Analyse au niveau du comté : trouver les zones commerciales les plus fréquentées
Maintenant que nous avons identifié le comté de Clark, l'étape suivante consiste à zoomer pour trouver les codes postaux où l'activité commerciale est la plus élevée. D'après les données de nos cafés existants, nous savons que les performances sont meilleures lorsque nous sommes situés à proximité d'une forte densité de grandes marques. Nous allons donc utiliser cette information comme indicateur de forte fréquentation.
Cette requête utilise la table brands de Places Insights, qui contient des informations sur des marques spécifiques. Cette table peut être
interrogée pour découvrir la liste des
marques compatibles. Nous définissons d'abord une liste de nos marques cibles, puis nous l'associons à l'ensemble de données principal Places Insights pour compter le nombre de ces magasins spécifiques dans chaque code postal du comté de Clark.
La méthode la plus efficace pour y parvenir consiste à suivre une approche en deux étapes :
- Tout d'abord, nous allons effectuer une agrégation rapide et non géospatiale pour compter les marques dans chaque code postal.
- Ensuite, nous allons associer ces résultats à un ensemble de données public pour obtenir les limites de la carte à des fins de visualisation.
Compter les marques à l'aide du champ postal_code_names
Cette première requête effectue la logique de décompte de base. Elle filtre les lieux du comté de Clark, puis dissocie le tableau postal_code_names pour regrouper les décomptes de marques par code postal.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
Le résultat est une table de codes postaux et de leurs décomptes de marques correspondants.
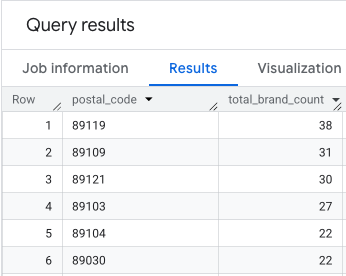
Associer des géométries de code postal pour la cartographie
Maintenant que nous avons les décomptes, nous pouvons obtenir les formes polygonales nécessaires à la visualisation. Cette deuxième requête prend notre première requête, l'encapsule dans une expression de table commune (CTE) nommée brand_counts_by_zipet associe ses résultats à la
table publique geo_us_boundaries.zip_codes table. Cela associe efficacement la géométrie à nos décomptes précalculés.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
Le résultat est une table de codes postaux, de leurs décomptes de marques correspondants et de la géométrie du code postal.
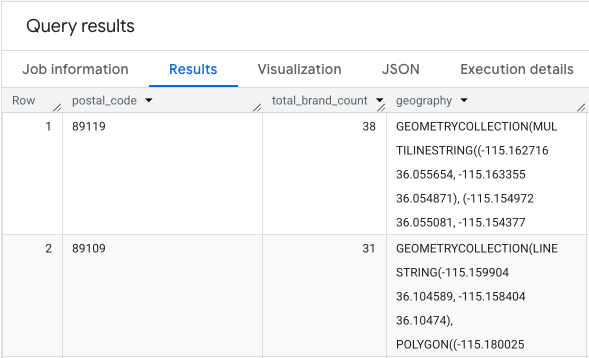
Nous pouvons visualiser ces données sous forme de carte de densité. Les zones rouge foncé indiquent une plus forte concentration de nos marques cibles, ce qui nous oriente vers les zones les plus denses sur le plan commercial de Las Vegas.
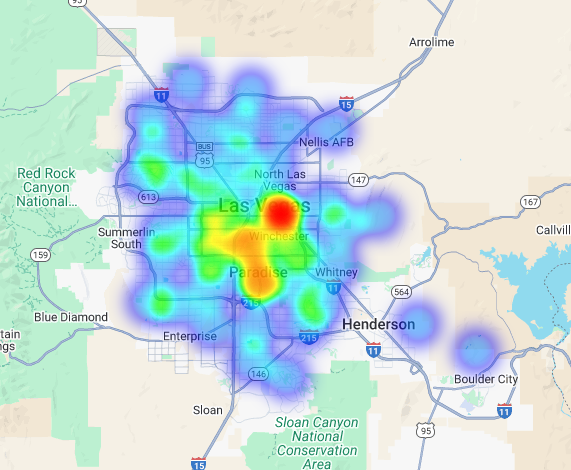
Analyse hyperlocale : évaluer les zones de grille individuelles
Maintenant que nous avons identifié la zone générale de Las Vegas, il est temps de procéder à une analyse précise. C'est là que nous intégrons nos connaissances spécifiques de l'entreprise. Nous savons qu'un bon café prospère à proximité d'autres entreprises qui sont fréquentées pendant nos heures de pointe, comme la fin de matinée et le déjeuner.
Notre requête suivante est très spécifique. Elle commence par créer une grille hexagonale précise sur l'agglomération de Las Vegas à l'aide de l'index géospatial H3 standard (à la résolution 8) pour analyser la zone au niveau micro. La requête identifie d'abord toutes les entreprises complémentaires ouvertes pendant notre période de pointe (du lundi au vendredi, de 10h à 14h).
Nous appliquons ensuite un score pondéré à chaque type de lieu. Un restaurant à proximité est plus intéressant pour nous qu'une supérette. Il reçoit donc un multiplicateur plus élevé. Cela nous donne un suitability_score personnalisé pour chaque petite zone.
Cet extrait met en évidence la logique de score pondéré, qui fait référence à un indicateur précalculé (is_open_monday_window) pour vérifier les horaires d'ouverture :
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Développer pour afficher la requête complète
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
La visualisation de ces scores sur une carte révèle clairement les emplacements gagnants. Les tuiles violet foncé, principalement situées près du Strip de Las Vegas et du centre-ville, sont les zones les plus prometteuses pour notre nouveau café.
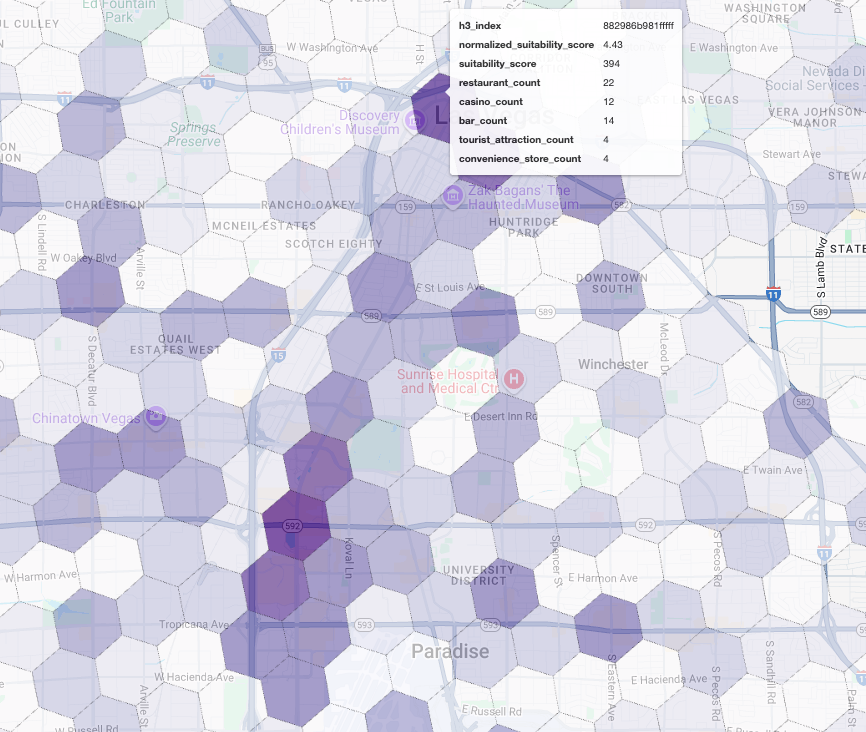
Analyse de la concurrence : identifier les cafés existants
Notre modèle d'adéquation a identifié avec succès les zones les plus prometteuses, mais un score élevé ne garantit pas le succès. Nous devons maintenant superposer ces données avec celles de nos concurrents. L'emplacement idéal est une zone à fort potentiel avec une faible densité de cafés existants, car nous recherchons une lacune claire sur le marché.
Pour ce faire, nous utilisons la
PLACES_COUNT_PER_H3
fonction. Cette fonction est conçue pour renvoyer efficacement les décomptes de lieux dans une zone géographique spécifiée, par cellule H3.
Tout d'abord, nous définissons dynamiquement la zone géographique pour l'ensemble de l'agglomération de Las Vegas.
Au lieu de nous appuyer sur une seule localité, nous interrogeons l'ensemble de données public Overture Maps pour obtenir les limites de Las Vegas et de ses principales localités environnantes, en les fusionnant en un seul polygone avec ST_UNION_AGG. Nous transmettons ensuite cette zone à la fonction, en lui demandant de compter tous les cafés en activité.
Cette requête définit l'agglomération et appelle la fonction pour obtenir le nombre de cafés dans les cellules H3 :
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
La fonction renvoie une table qui inclut l'index de la cellule H3, sa géométrie, le nombre total de cafés et un exemple de leurs ID de lieu :
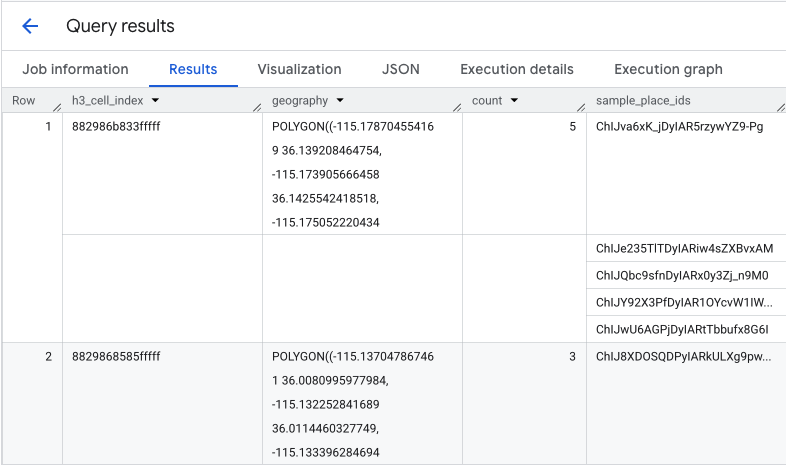
Bien que le décompte agrégé soit utile, il est essentiel de voir les concurrents réels.
C'est là que nous passons de l'ensemble de données Places Insights à l'API
Places. En extrayant les
sample_place_ids des cellules ayant le score d'adéquation normalisé le plus élevé,
nous pouvons appeler l'API Place Details pour récupérer des informations détaillées sur chaque concurrent, telles que son nom, son adresse, sa note et son emplacement.
Pour cela, il est nécessaire de comparer les résultats de la requête précédente, où le score d'adéquation a été généré, et la requête PLACES_COUNT_PER_H3. L'index de la cellule H3 peut être utilisé pour obtenir le nombre de cafés et les ID des cellules ayant le score d'adéquation normalisé le plus élevé.
Ce code Python montre comment effectuer cette comparaison.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Nous disposons maintenant de la liste des ID de lieu des cafés déjà existants dans les cellules H3 ayant le score d'adéquation le plus élevé. Nous pouvons demander des informations supplémentaires sur chaque lieu.
Pour ce faire, vous pouvez envoyer une requête directement à l'API
Place Details pour chaque
ID de lieu ou utiliser une bibliothèque
cliente pour effectuer l'
appel. N'oubliez pas de définir le
FieldMask
paramètre pour ne demander que les données dont vous avez besoin.
Enfin, nous combinons tous les éléments en une seule visualisation puissante. Nous traçons notre carte choroplèthe d'adéquation violette comme couche de base, puis nous ajoutons des repères pour chaque café individuel récupéré à partir de l'API Places. Cette carte finale offre une vue d'ensemble qui synthétise l'ensemble de notre analyse : les zones violet foncé indiquent le potentiel, et les repères verts montrent la réalité du marché actuel.
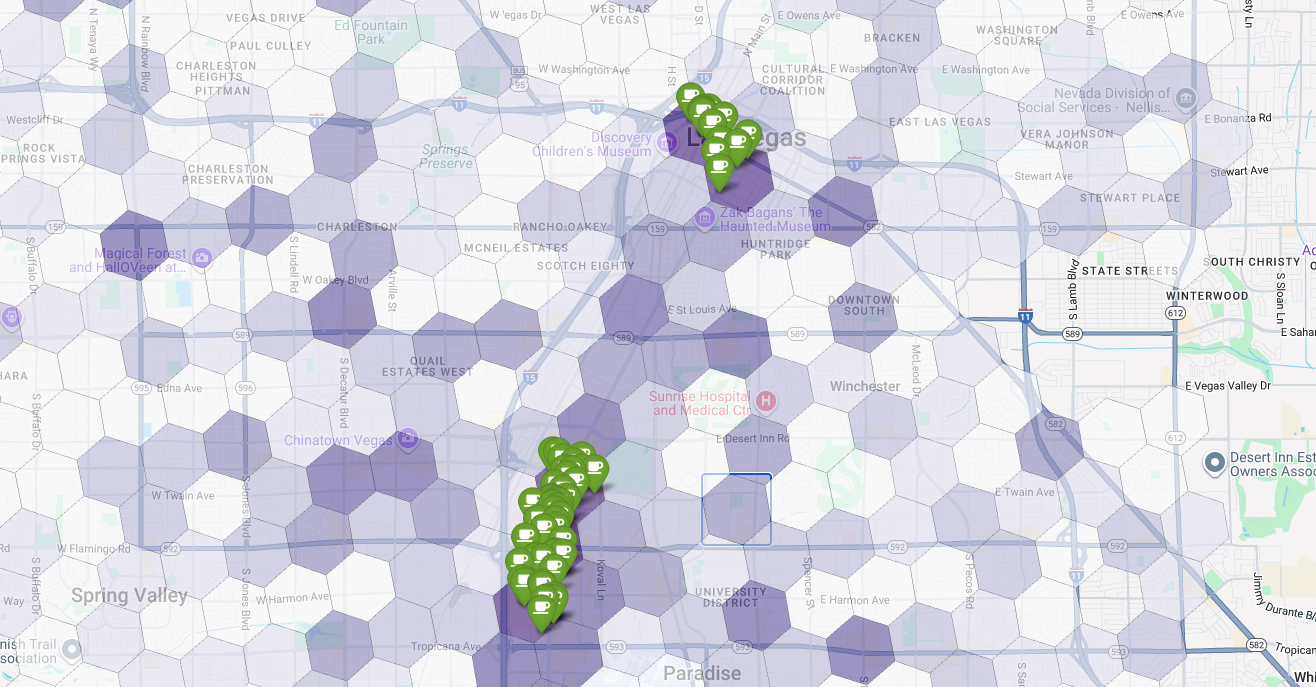
En recherchant des cellules violet foncé avec peu ou pas de repères, nous pouvons identifier avec certitude les zones exactes qui représentent la meilleure opportunité pour notre nouvel établissement.
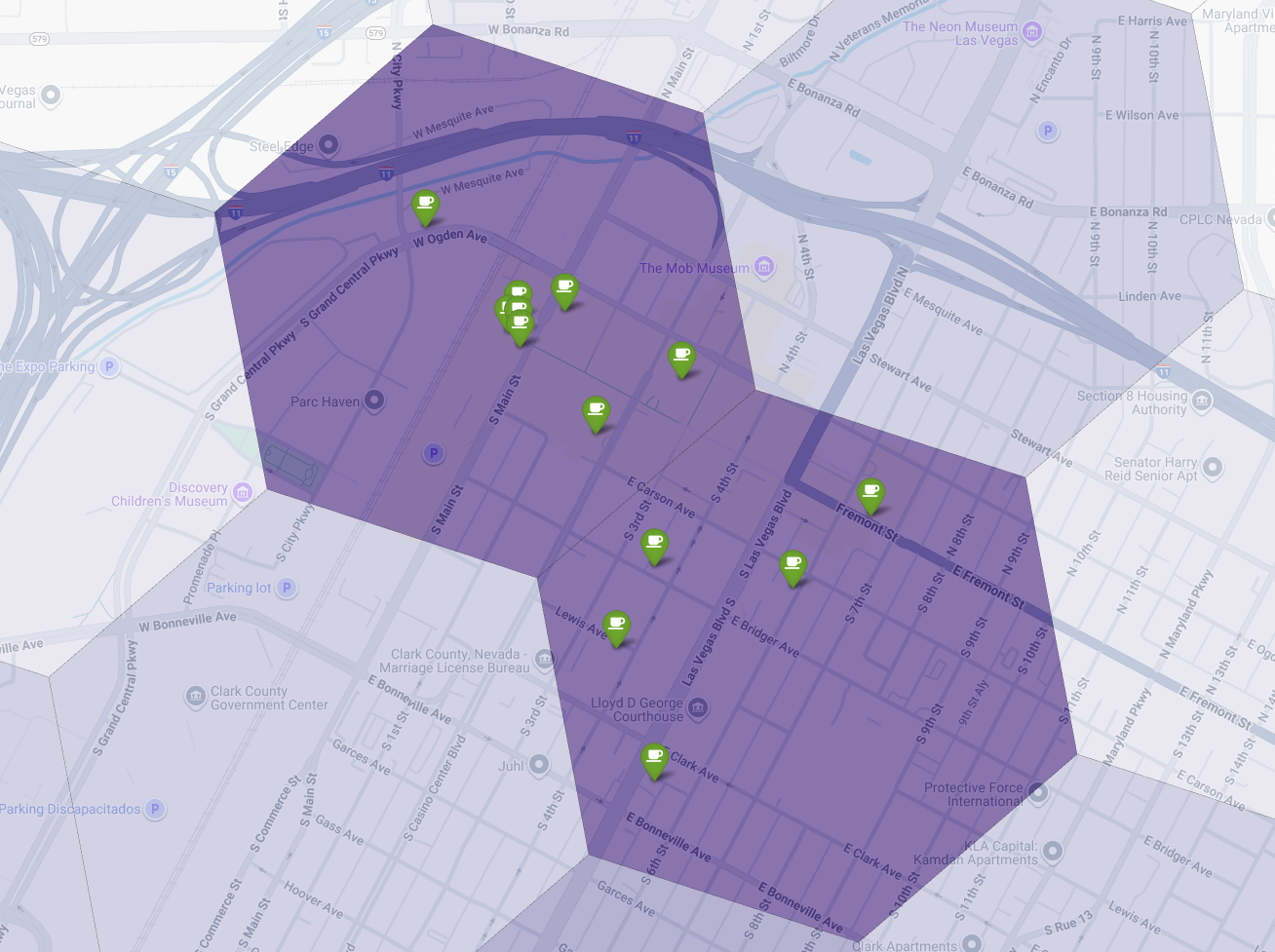
Les deux cellules ci-dessus ont un score d'adéquation élevé, mais présentent des lacunes évidentes qui pourraient être des emplacements potentiels pour notre nouveau café.
Conclusion
Dans ce document, nous sommes passés d'une question à l'échelle de l'État (où nous étendre ?) à une réponse locale basée sur les données. En superposant différents ensembles de données et en appliquant une logique métier personnalisée, vous pouvez réduire systématiquement le risque associé à une décision commerciale majeure. Ce workflow, qui combine l'échelle de BigQuery, la richesse de Places Insights et les détails en temps réel de l'API Places, constitue un modèle puissant pour toute organisation souhaitant utiliser l'intelligence géographique pour une croissance stratégique.
Étapes suivantes
- Adaptez ce workflow avec votre propre logique métier, vos zones géographiques cibles et vos ensembles de données propriétaires.
- Explorez d'autres champs de données dans l'ensemble de données Places Insights, tels que le nombre d'avis, les niveaux de prix et les notes des utilisateurs, pour enrichir davantage votre modèle.
- Automatisez ce processus pour créer un tableau de bord interne de sélection de sites qui peut être utilisé pour évaluer dynamiquement de nouveaux marchés.
Pour en savoir plus, consultez la documentation :
Contributeurs
Henrik Valve | DevX Ingénieur