
Einführung
In diesem Dokument wird beschrieben, wie Sie eine Lösung zur Standortauswahl erstellen, indem Sie das Places Insights-Dataset, öffentliche raumbezogene Daten in BigQueryund die Place Details APIkombinieren.
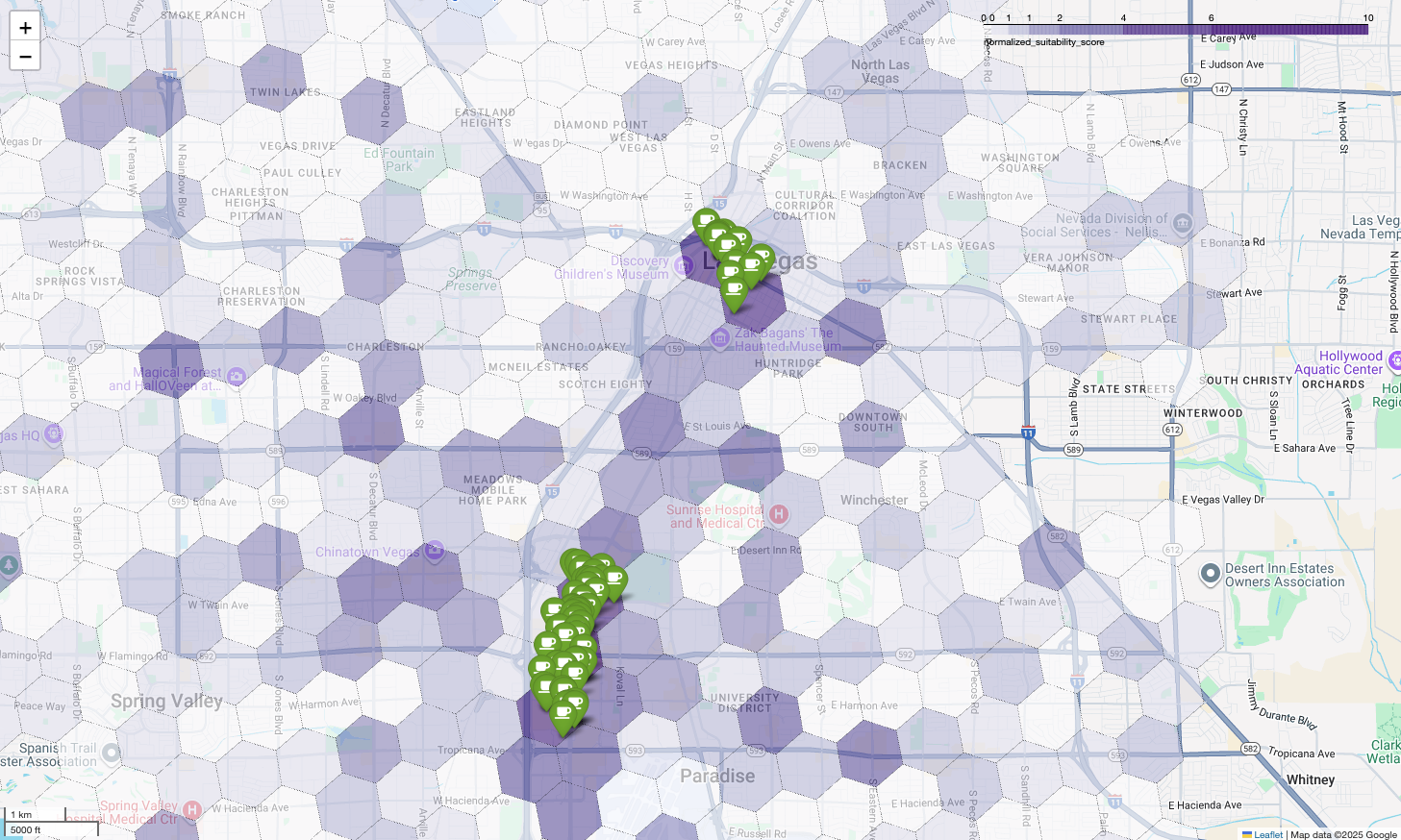
Die Karte oben zeigt die Ausgabe einer Demo, die auf der Google Cloud Next 2025 präsentiert wurde, die auf YouTube verfügbar ist. Sie können den Code, mit dem diese Ergebnisse generiert wurden, mit dem Beispiel-Notebook ausführen.
 Quelle auf GitHub anzeigen
Quelle auf GitHub anzeigen
Die Herausforderung
Stellen Sie sich vor, Sie besitzen eine erfolgreiche Kaffeekette und möchten in einen neuen Bundesstaat wie Nevada expandieren, in dem Sie noch nicht vertreten sind. Die Eröffnung eines neuen Standorts ist eine erhebliche Investition. Eine datengestützte Entscheidung ist daher entscheidend für den Erfolg. Wo fangen Sie an?
In diesem Leitfaden wird eine mehrschichtige Analyse beschrieben, mit der Sie den optimalen Standort für ein neues Café ermitteln können. Wir beginnen mit einer Analyse auf Bundesstaatsebene, grenzen unsere Suche schrittweise auf ein bestimmtes County und eine bestimmte Gewerbezone ein und führen schließlich eine hyperlokale Analyse durch, um einzelne Gebiete zu bewerten und Marktlücken zu ermitteln, indem wir Wettbewerber erfassen.
Solution Workflow
Dieser Prozess folgt einem logischen Trichter. Er beginnt breit gefächert und wird schrittweise immer detaillierter, um den Suchbereich einzugrenzen und die Zuverlässigkeit der endgültigen Standortauswahl zu erhöhen.
Voraussetzungen und Umgebungseinrichtung
Bevor Sie mit der Analyse beginnen, benötigen Sie eine Umgebung mit einigen wichtigen Funktionen. In diesem Leitfaden wird eine Implementierung mit SQL und Python beschrieben. Die allgemeinen Prinzipien können jedoch auch auf andere Technologie-Stacks angewendet werden.
Ihre Umgebung muss folgende Voraussetzungen erfüllen:
- Abfragen in BigQuery ausführen
- Zugriff auf Places Insights haben. Weitere Informationen finden Sie unter Places Insights einrichten.
- Öffentliche Datasets aus
bigquery-public-dataund die US Census Bureau County Population Totals abonnieren
Außerdem müssen Sie raumbezogene Daten auf einer Karte visualisieren können. Das ist entscheidend, um die Ergebnisse der einzelnen Analyseschritte zu interpretieren. Es gibt verschiedene Möglichkeiten, diese Anforderung zu erfüllen. Sie können BI-Tools wie Looker Studio verwenden, die direkt mit BigQuery verbunden sind, oder Data-Science-Sprachen wie Python.
Analyse auf Bundesstaatsebene: Das beste County finden
Der erste Schritt ist eine umfassende Analyse, um das vielversprechendste County in Nevada zu ermitteln. Wir definieren vielversprechend als eine Kombination aus hoher Bevölkerungszahl und hoher Dichte an bestehenden Restaurants, was auf eine starke Gastronomiekultur hindeutet.
Mit unserer BigQuery-Abfrage wird dies erreicht, indem die integrierten Adresskomponenten im Places Insights-Dataset genutzt werden. Die Abfrage zählt Restaurants, indem die Daten zuerst so gefiltert werden, dass nur Orte im Bundesstaat Nevada berücksichtigt werden. Dazu wird das Feld administrative_area_level_1_name verwendet. Anschließend wird diese Menge weiter eingeschränkt, sodass nur Orte berücksichtigt werden, bei denen das Array „types“ den Wert „restaurant“ enthält. Schließlich werden diese Ergebnisse nach County-Name (administrative_area_level_2_name) gruppiert, um eine Anzahl für jedes County zu erhalten. Bei diesem Ansatz wird die integrierte, vorindexierte Adressstruktur des Datasets verwendet.
In diesem Auszug sehen Sie, wie wir County-Geometrien mit Places Insights verknüpfen und nach einem bestimmten Ortstyp filtern, nämlich restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Eine reine Anzahl von Restaurants reicht nicht aus. Wir müssen sie mit Bevölkerungsdaten abgleichen, um ein realistisches Bild der Marktsättigung und der Marktchancen zu erhalten. Wir verwenden Bevölkerungsdaten aus den US Census Bureau County Population Totals.
Um diese beiden sehr unterschiedlichen Messwerte (eine Anzahl von Orten im Vergleich zu einer großen Bevölkerungszahl) zu vergleichen, verwenden wir die Min-Max-Normalisierung. Mit dieser Methode werden beide Messwerte auf einen gemeinsamen Bereich (0 bis 1) skaliert. Anschließend kombinieren wir sie zu einem einzigen normalized_score, wobei jeder Messwert eine Gewichtung von 50% erhält, um einen ausgewogenen Vergleich zu ermöglichen.
Dieser Auszug zeigt die Kernlogik für die Berechnung des Scores. Dabei werden normalisierte Bevölkerungs- und Restaurantzahlen kombiniert:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Nach Ausführung der vollständigen Abfrage wird eine Liste der Countys, der Anzahl der Restaurants, der Bevölkerungszahl und des normalisierten Scores zurückgegeben. Wenn wir nach normalized_score
DESC sortieren, erweist sich Clark County als klarer Gewinner für weitere Untersuchungen als der
Top-Anwärter.
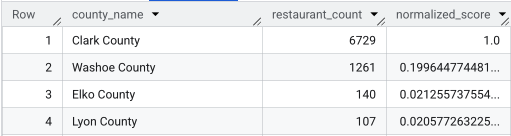
Dieser Screenshot zeigt die vier Countys mit dem höchsten normalisierten Score. Die Rohdaten zur Bevölkerungszahl wurden in diesem Beispiel bewusst weggelassen.
Analyse auf County-Ebene: Die geschäftigsten Gewerbezonen finden
Nachdem wir Clark County ermittelt haben, müssen wir nun die Postleitzahlen mit der höchsten gewerblichen Aktivität finden. Basierend auf Daten aus unseren bestehenden Cafés wissen wir, dass die Leistung besser ist, wenn sie sich in der Nähe einer hohen Dichte großer Marken befinden. Wir verwenden dies daher als Proxy für eine hohe Besucherfrequenz.
Diese Abfrage verwendet die Tabelle brands in Places Insights, die Informationen zu bestimmten Marken enthält. Diese Tabelle kann abgefragt
werden, um die Liste der
unterstützten Marken zu ermitteln. Zuerst definieren wir eine Liste unserer Zielmarken und verknüpfen diese dann mit dem Haupt-Dataset von Places Insights, um zu zählen, wie viele dieser Geschäfte in jeder Postleitzahl in Clark County vorhanden sind.
Die effizienteste Methode dafür ist ein zweistufiger Ansatz:
- Zuerst führen wir eine schnelle, nicht raumbezogene Aggregation durch, um die Marken in jeder Postleitzahl zu zählen.
- Anschließend verknüpfen wir diese Ergebnisse mit einem öffentlichen Dataset um die Kartengrenzen für die Visualisierung zu erhalten.
Marken mit dem Feld postal_code_names zählen
Die erste Abfrage führt die Kernlogik für das Zählen aus. Sie filtert nach Orten in Clark County und hebt dann das Array postal_code_names auf, um die Anzahl der Marken nach Postleitzahl zu gruppieren.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
Die Ausgabe ist eine Tabelle mit Postleitzahlen und den entsprechenden Anzahlen von Marken.
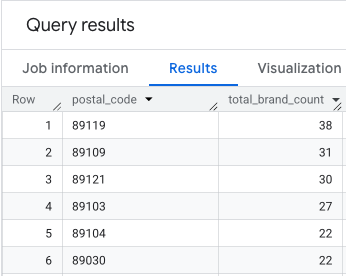
Postleitzahl-Geometrien für die Kartenerstellung anhängen
Nachdem wir die Anzahlen haben, können wir die Polygone abrufen, die für die Visualisierung erforderlich sind. Die zweite Abfrage verwendet unsere erste Abfrage, umschließt sie mit einem allgemeinen
Tabellenausdruck (Common Table Expression, CTE) namens brand_counts_by_zip und verknüpft die Ergebnisse mit der
öffentlichen Tabelle geo_us_boundaries.zip_codes table. So wird die Geometrie effizient an unsere vorab berechneten Anzahlen angehängt.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
Die Ausgabe ist eine Tabelle mit Postleitzahlen, den entsprechenden Anzahlen von Marken und der Postleitzahl-Geometrie.
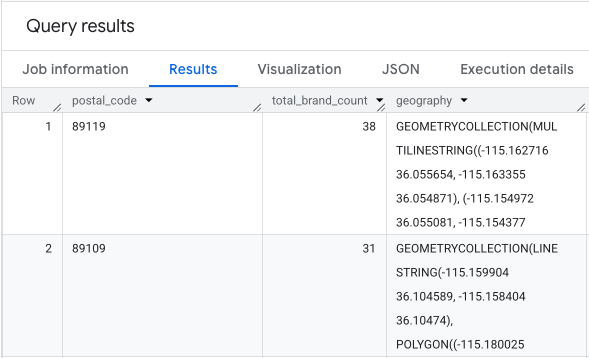
Wir können diese Daten als Heatmap visualisieren. Die dunkelroten Bereiche weisen auf eine höhere Konzentration unserer Zielmarken hin und zeigen uns die kommerziell dichtesten Zonen in Las Vegas.
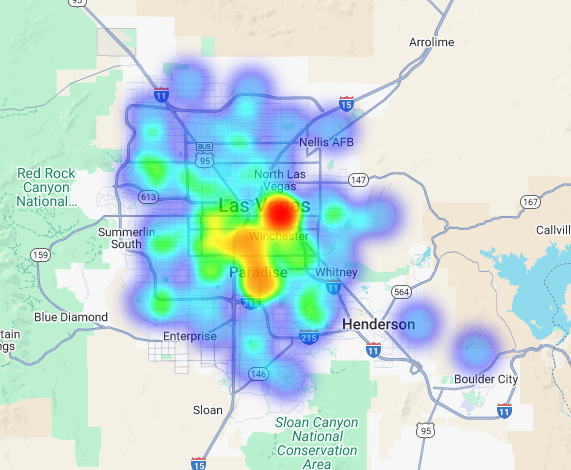
Hyperlokale Analyse: Einzelne Rasterbereiche bewerten
Nachdem wir den allgemeinen Bereich von Las Vegas ermittelt haben, ist es Zeit für eine detaillierte Analyse. Hier bringen wir unser spezifisches Geschäftswissen ein. Wir wissen, dass ein erfolgreiches Café in der Nähe anderer Geschäfte liegt, die während unserer Hauptgeschäftszeiten gut besucht sind, z. B. am späten Vormittag und zur Mittagszeit.
Unsere nächste Abfrage ist sehr spezifisch. Zuerst wird ein feingliedriges hexagonales Raster über dem Großraum Las Vegas erstellt. Dazu wird der standardmäßige raumbezogene H3-Index (mit Auflösung 8) verwendet, um den Bereich auf Mikroebene zu analysieren. Die Abfrage ermittelt zuerst alle ergänzenden Geschäfte, die während unserer Hauptgeschäftszeiten geöffnet sind (Montag, 10:00 bis 14:00 Uhr).
Anschließend weisen wir jedem Ortstyp einen gewichteten Score zu. Ein Restaurant in der Nähe ist für uns wertvoller als ein Minimarkt und erhält daher einen höheren Multiplikator. So erhalten wir für jeden kleinen Bereich einen benutzerdefinierten suitability_score.
Dieser Auszug zeigt die gewichtete Scoring-Logik, die ein vorab berechnetes Flag (is_open_monday_window) für die Überprüfung der Öffnungszeiten verwendet:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Vollständige Abfrage maximieren
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
Wenn wir diese Scores auf einer Karte visualisieren, werden klare Gewinnerstandorte sichtbar. Die dunkelsten violetten Kacheln, hauptsächlich in der Nähe des Las Vegas Strip und der Innenstadt, sind die Bereiche mit dem höchsten Potenzial für unser neues Café.
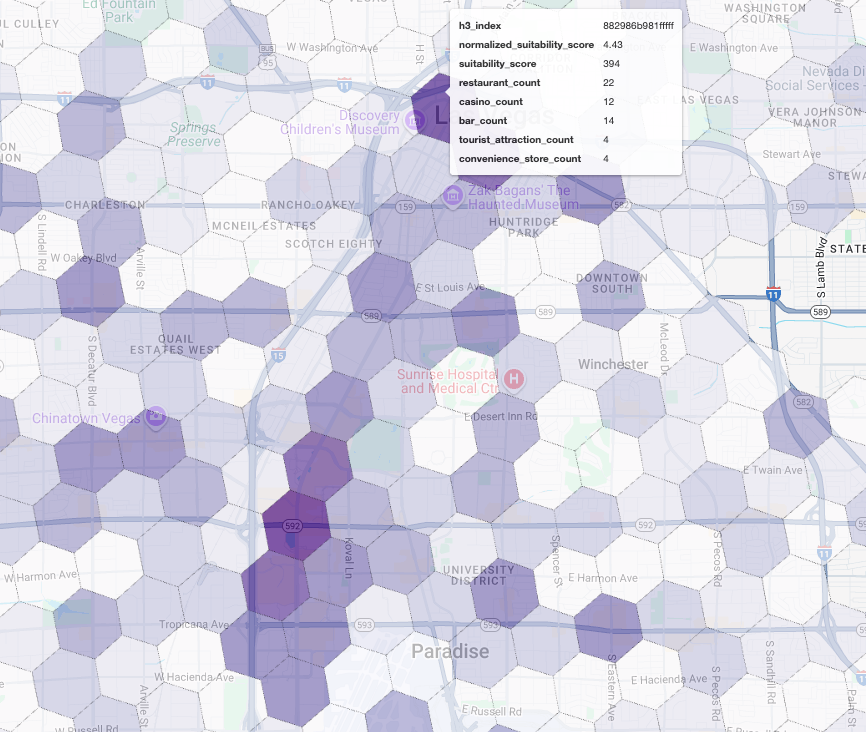
Wettbewerbsanalyse: Bestehende Cafés ermitteln
Unser Modell zur Eignung hat die vielversprechendsten Zonen ermittelt. Ein hoher Score allein garantiert jedoch keinen Erfolg. Wir müssen diese Daten nun mit Wettbewerbsdaten überlagern. Der ideale Standort ist ein Gebiet mit hohem Potenzial und einer geringen Dichte an bestehenden Cafés, da wir eine klare Marktlücke suchen.
Dazu verwenden wir die
PLACES_COUNT_PER_H3
Funktion. Diese Funktion wurde entwickelt, um effizient die Anzahl der Orte in einem bestimmten geografischen Gebiet nach H3-Zelle zurückzugeben.
Zuerst definieren wir dynamisch das geografische Gebiet für den gesamten Großraum Las Vegas.
Anstatt uns auf einen einzelnen Ort zu verlassen, fragen wir das öffentliche Overture Maps-Dataset ab, um die Grenzen für Las Vegas und die wichtigsten umliegenden Orte zu erhalten. Diese werden dann mit ST_UNION_AGG zu einem einzigen Polygon zusammengeführt. Anschließend übergeben wir diesen Bereich an die Funktion, um alle in Betrieb befindlichen Cafés zu zählen.
Diese Abfrage definiert den Großraum und ruft die Funktion auf, um die Anzahl der Cafés in H3-Zellen zu ermitteln:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
Die Funktion gibt eine Tabelle mit dem H3-Zellenindex, der Geometrie, der Gesamtzahl der Cafés und einer Stichprobe ihrer Orts-IDs zurück:
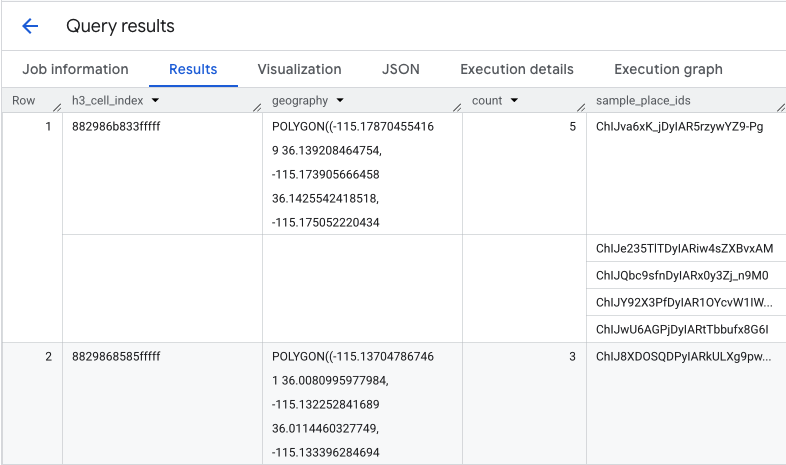
Die aggregierte Anzahl ist zwar nützlich, aber es ist wichtig, die tatsächlichen Wettbewerber zu kennen.
Hier wechseln wir vom Places Insights-Dataset zur Places
API. Indem wir die
sample_place_ids aus den Zellen mit dem höchsten normalisierten Score für die Eignung extrahieren,
können wir die Place Details
API aufrufen, um detaillierte
Informationen zu jedem Wettbewerber abzurufen, z. B. Name, Adresse, Bewertung und Standort.
Dazu müssen die Ergebnisse der vorherigen Abfrage, bei der der Score für die Eignung generiert wurde, mit der Abfrage PLACES_COUNT_PER_H3 verglichen werden. Mit dem H3-Zellenindex können Sie die Anzahl und IDs der Cafés aus den Zellen mit dem höchsten normalisierten Score für die Eignung abrufen.
Dieser Python-Code zeigt, wie dieser Vergleich durchgeführt werden kann.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Jetzt haben wir die Liste der Orts-IDs für Cafés, die bereits in den H3-Zellen mit dem höchsten Score für die Eignung vorhanden sind. Weitere Details zu jedem Ort können angefordert werden.
Dazu können Sie entweder für jede
Orts-ID eine Anfrage direkt an die Place Details
API senden oder eine Client
Library verwenden, um den
Aufruf durchzuführen. Denken Sie daran, den
FieldMask
Parameter so festzulegen, dass nur die benötigten Daten angefordert werden.
Schließlich kombinieren wir alles zu einer einzigen, aussagekräftigen Visualisierung. Wir verwenden unsere violette Choroplethenkarte für die Eignung als Basisebene und fügen dann Markierungen für jedes einzelne Café hinzu, das über die Places API abgerufen wurde. Diese endgültige Karte bietet einen Überblick, der unsere gesamte Analyse zusammenfasst: Die dunkelvioletten Bereiche zeigen das Potenzial und die grünen Markierungen die Realität des aktuellen Marktes.
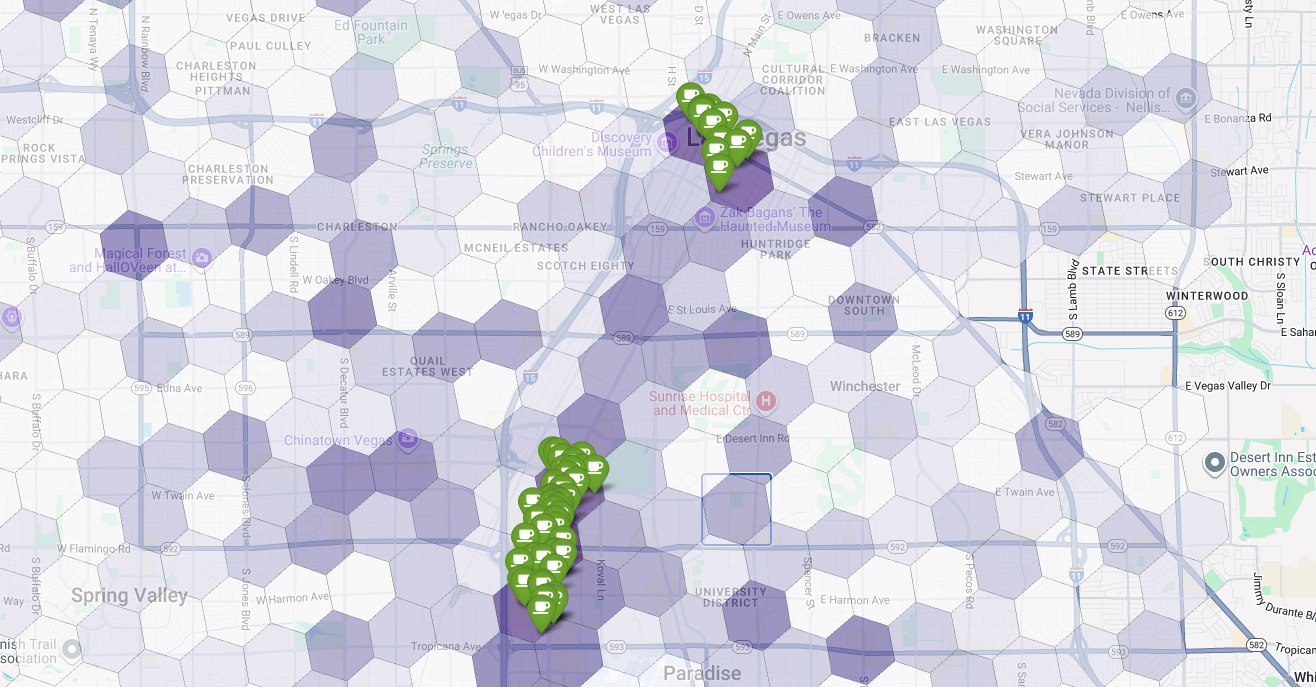
Wenn wir nach dunkelvioletten Zellen mit wenigen oder keinen Markierungen suchen, können wir die genauen Bereiche ermitteln, die die beste Gelegenheit für unseren neuen Standort bieten.
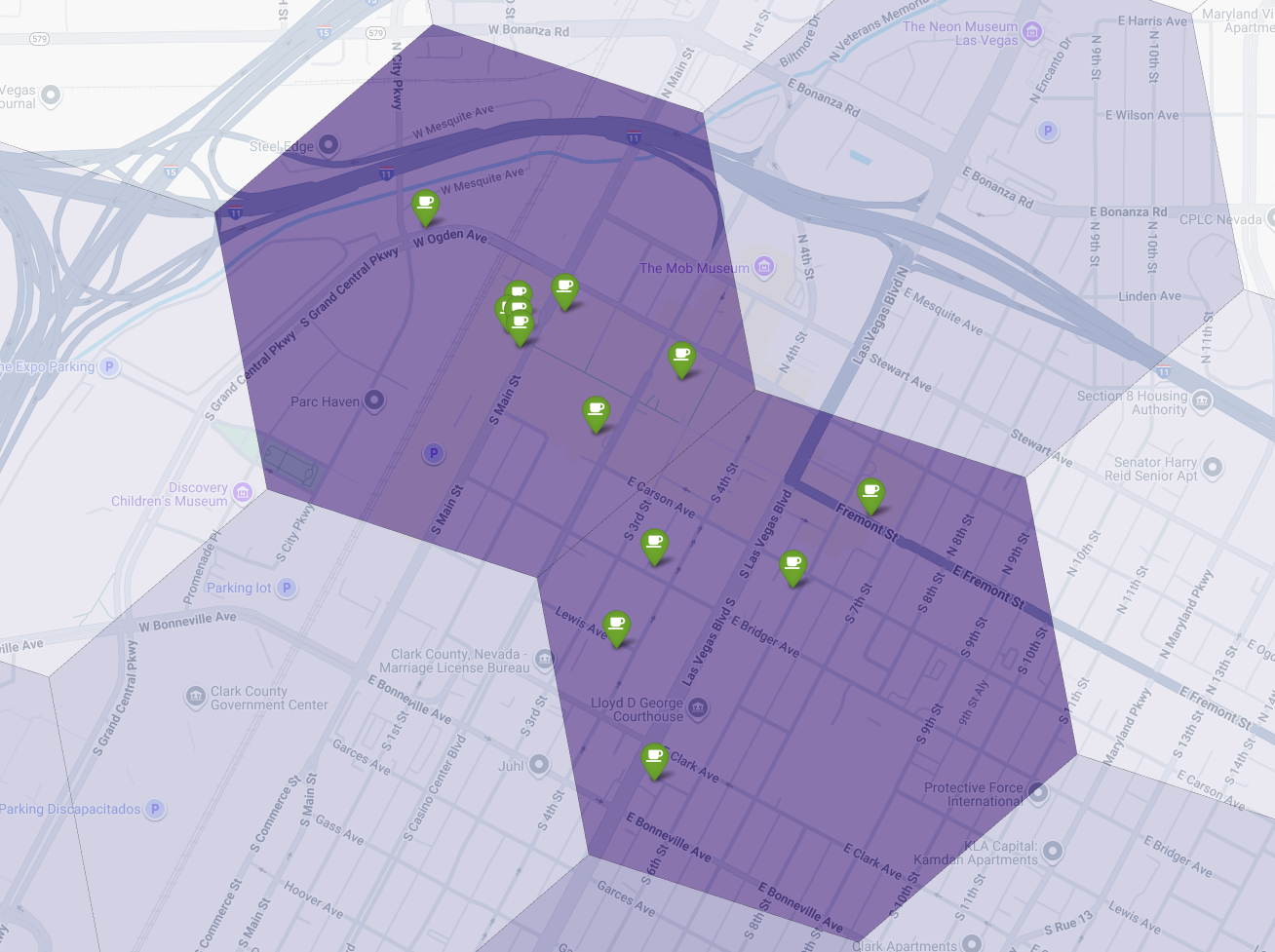
Die beiden oben genannten Zellen haben einen hohen Score für die Eignung, aber einige klare Lücken, die potenzielle Standorte für unser neues Café sein könnten.
Fazit
In diesem Dokument haben wir uns von der Frage Wo expandieren? auf Bundesstaatsebene zu einer datengestützten, lokalen Antwort bewegt. Indem Sie verschiedene Datasets kombinieren und benutzerdefinierte Geschäftslogik anwenden, können Sie das Risiko, das mit einer wichtigen Geschäftsentscheidung verbunden ist, systematisch reduzieren. Dieser Workflow, der die Skalierbarkeit von BigQuery, die Fülle an Informationen von Places Insights und die Echtzeitdetails der Places API kombiniert, bietet eine leistungsstarke Vorlage für jedes Unternehmen, das Standortinformationen für strategisches Wachstum nutzen möchte.
Nächste Schritte
- Passen Sie diesen Workflow mit Ihrer eigenen Geschäftslogik, Zielregionen und proprietären Datasets an.
- Untersuchen Sie andere Datenfelder im Places Insights-Dataset, z. B. die Anzahl der Rezensionen, Preisklassen und Nutzerbewertungen, um Ihr Modell weiter zu optimieren.
- Automatisieren Sie diesen Prozess, um ein internes Dashboard zur Standortauswahl zu erstellen, mit dem Sie neue Märkte dynamisch bewerten können.
Weitere Informationen finden Sie in der Dokumentation:
- Übersicht über Places Insights
- Places Insights-Funktionen
- Raumbezogene Analysen in BigQuery
- Places API
Beitragende
Henrik Valve | DevX Engineer