
従来の企業間見込み顧客の発掘では、静的なディレクトリや業界リストを購入してテリトリーの可能性を定義することがよくあります。ただし、これらの静的な地図スポット(POI)データセットはすぐに古くなります。最新の営業状況や詳細な場所タイプの分類が不足していることが多いため、フィールド セールスチームは、閉業している、カテゴリが誤っている、理想的な顧客プロファイルと無関係なビジネスを追いかけることで、貴重な時間を無駄にするリスクがあります。
このガイドでは、Places Insights と Places API を使用して、このギャップを埋めるワークフローについて説明します。現在のビジネスブックをプレイス ID にマッピングすることで、BigQuery を使用して、顧客関係管理(CRM)データベースにまだ登録されていない地域内のすべての営業拠点を特定できます。このガイドでは、除外エンジンを構築して、フィールド担当者にハイパー ターゲティングされた検証済みの見込み顧客リストを提供する方法について説明します。
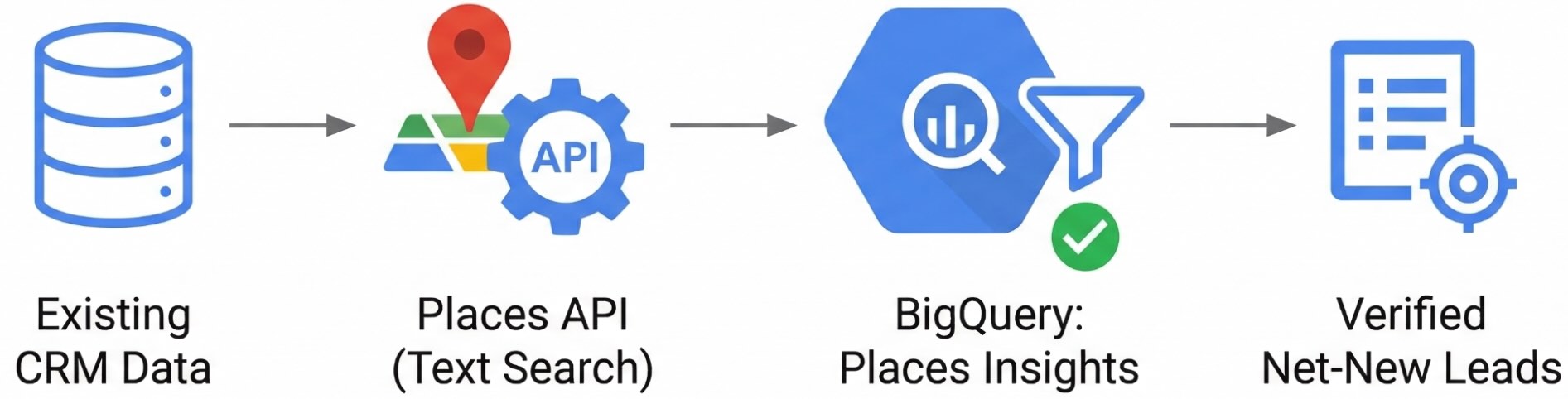
サンプル アプリケーション
ニューヨーク市でフィールド セールスの拡大を計画している POS プロバイダを考えてみましょう。通常、組織は郵便番号ごとの食品および飲料施設の総数に関するレポートを取得します。このアプローチでは、販売担当者が古いデータ(閉業した店舗など)や無関係な見込み顧客(店舗のないプライベート ケータリング キッチンなど)に依存するリスクがあります。代わりに、Google マップのグローバルな規模と、複数のソースで検証された最新のデータを活用する Places Insights を使用した最新のアプローチを考えてみましょう。Places Insights は、500 近くの場所カテゴリと 70 以上の属性をサポートしており、特定の業種(scandinavian_restaurant など)、営業時間、サービス内容(accepts_credit_cards など)に基づいて、見込み顧客を高い精度で絞り込むことができます。Places Insights を社内 CRM と照合することで、営業チームに、高い可能性を秘めた、まだ連絡を取っていない見込み顧客のリストを、高い精度でターゲットを絞って提供できます。
ソリューションのワークフロー
このガイドでは、現在のビジネスを自動的に除外して、営業チームが追跡すべき新規の運用リードのみを残す動的な「リードマップ」を作成するための技術フレームワークを提供します。
4 ステップのアーキテクチャ
- ターゲットの場所のタイプを定義する: 理想的な顧客プロファイルを場所のタイプにマッピングします。
- 有望なエリアを特定する: BigQuery で Places Count 関数を実行して、運用対象のビジネスの密度ヒートマップを生成します。
- CRM データをプレイス ID に正規化する: データ クレンジング パイプラインで非構造化 CRM レコードを処理し、Address Validation、ジオコーディング、Places API を利用して、既存の顧客のプレイス ID を見つけます。
- 空白除外を実行する: BigQuery の Places Insights データに対して CRM のプレイス ID を結合し、既存の顧客を動的に除外して、新規リードのリストを出力します。
前提条件
始める前に、次の準備をしてください。
Google Cloud プロジェクト:
- 課金を有効にした Google Cloud プロジェクト
データアクセス:
- BigQuery の Places Insights サブスクリプション。
- 除外リストとして機能する、既存の顧客の会社名と住所を含む独自の CRM データセット(BigQuery テーブルなど)。
Google Maps Platform:
- API キー。
- キーで有効になっている API は次のとおりです。
IAM 権限:
- クエリを実行してデータセットを管理するには、ユーザー アカウントまたはサービス アカウントに次の IAM ロールがあることを確認します。
ロール ID BigQuery データ編集者 roles/bigquery.dataEditorBigQuery ユーザー roles/bigquery.user
- クエリを実行してデータセットを管理するには、ユーザー アカウントまたはサービス アカウントに次の IAM ロールがあることを確認します。
費用意識:
- このチュートリアルでは、課金対象となる Google Cloud コンポーネントを使用します。次の項目に関連する費用が発生する可能性があることに注意してください。
- BigQuery: クエリ実行中に使用されたコンピューティング スロットまたは処理されたデータに対して課金されます。
- Places Insights: クエリの使用量に基づいて課金されます。
- Google Maps Platform: Address Validation API、Geocoding API、テキスト検索 API のリクエストごとに課金されます。
- このチュートリアルでは、課金対象となる Google Cloud コンポーネントを使用します。次の項目に関連する費用が発生する可能性があることに注意してください。
ステップ 1: ターゲットの場所のタイプを定義する
Places Insights は、約 500 の場所カテゴリと 70 以上の属性(営業時間、支払い方法、営業状況など)をサポートしています。データセット全体を無差別にクエリすると、効率が悪く、コストも高くなります。
基本的な手順として、Gemini などの LLM を使用して、社内の顧客プロファイルを Place Types に変換します。これは、Places Insights のクエリを作成する際に使用されます。このマクロレベルの分類定義により、後続の BigQuery 検索の対象が絞り込まれ、コンピューティング処理のオーバーヘッドが削減されます。
たとえば、POS システムのワークフローを設計している場合は、Gemini に場所のタイプのリストを提供し、次のプロンプトを使用できます。
「市場アナリストとして、サポートされている Google マップの場所タイプのうち、POS システム プロバイダの主なターゲットはどれですか?決定を正当化してください。」
このプロンプトに基づいて、Gemini は分類を分析し、BigQuery の types フィルタで使用する関連する場所タイプのターゲット サブセットを返します。
| メインカテゴリ | 理由 | 主なプレイスタイプ |
|---|---|---|
| 飲食店 | 高速なトランザクション処理、テーブル管理、注文チケット発行、チップ処理が必要です。 | restaurant、bar、cafe、coffee_shop |
| ショッピング | 堅牢な在庫追跡、バーコード スキャン、返品処理、ポイントカードの統合が必要です。 | clothing_store、grocery_store、supermarket、convenience_store |
| サービスと健康管理 | 予約、スケジュール設定、顧客プロファイル、手数料の追跡が統合されている必要があります。 | hair_salon、beauty_salon、spa、massage |
| エンターテイメント、レクリエーション、スポーツ | 顧客の急増、デジタル チケットのスキャン、売店の迅速な販売に対応する必要があります。 | movie_theater、amusement_park、bowling_alley、stadium |
このガイドでは、飲食カテゴリの推奨される場所タイプに焦点を当てます。
ステップ 2: 事業所数を抽出して有望な地域を特定する
機会の多いエリアを特定するには、まずビジネスの密度をマクロで把握する必要があります。これは、BigQuery で場所のカウント関数(PLACES_COUNT_PER_H3 や PLACES_COUNT_PER_GEO など)を実行することで実現できます。
データセットを直接クエリすることもできますが、プレイス数関数は、5 つ以上の場所という標準の集計しきい値を適用しない、事前定義された最適化済みの SQL クエリです(標準の直接クエリでは、1 ~ 4 つのビジネスを含む行は除外されますが、これらの関数を使用すると、1 つの見込み顧客が存在する場所を正確に確認できます)。重要なのは、これらの関数は sample_place_ids 列を使用して、地理的エリアごとに最大 250 個のプレイス ID の配列を返すことです。これにより、テリトリー プランナー向けの統計ヒートマップと、見込み顧客の発掘に必要な基本的な識別子の両方が提供されます。
次のクエリは、公開データセットを使用して複雑なポリゴン(ニューヨーク市の境界全体)を動的に取得し、その地理情報を Places Count 関数に渡す方法を示しています。都市全体でより広範な解像度(8)で H3 空間インデックスを使用すると、マクロレベルの密度マップを生成できます。
さらに、すべての列(SELECT *)を選択すると、関数は H3 セルを表すポリゴンである geography 列を返します。これにより、BigQuery の結果をビジネス インテリジェンス ツール(Looker Studio など)にすぐにインポートして、市場のホットスポットを視覚的に明らかにする塗りつぶし地図の可視化を作成できます。
-- Illustrative logic: Extracting target business counts per H3 cell across New York City
DECLARE geo GEOGRAPHY;
-- Get the geography for New York City using the Overture Maps public dataset
SET geo = (SELECT geometry FROM `bigquery-public-data.overture_maps.division_area`
WHERE country = 'US' AND subtype = 'locality' AND names.primary = 'New York' LIMIT 1);
SELECT *
FROM `YOUR_PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', geo,
'h3_resolution', 8,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
)
ORDER BY count DESC;
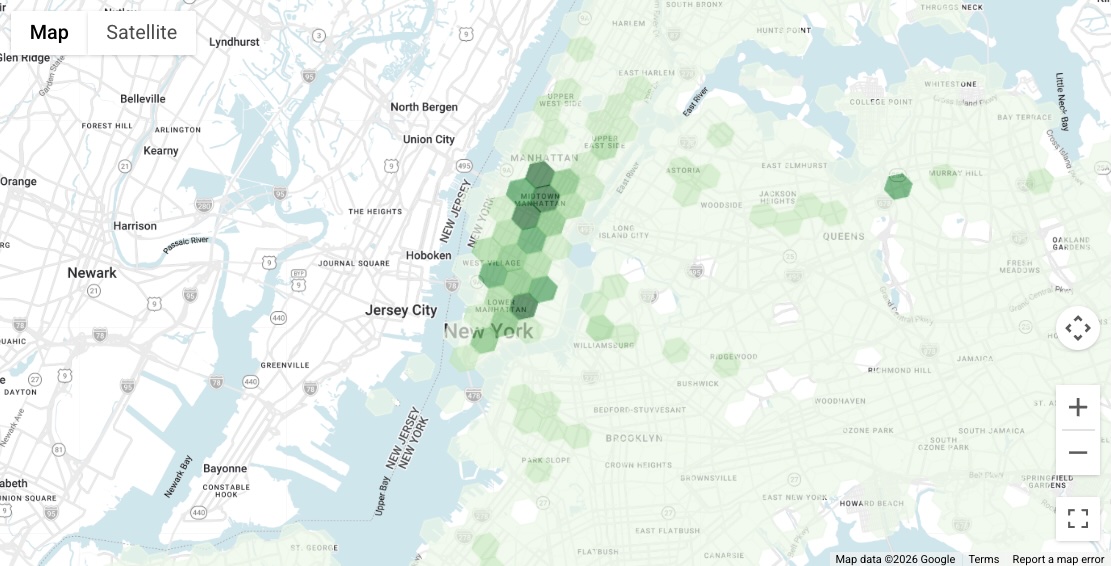
結果として得られた可視化でわかるように、マンハッタン全体にわたってターゲット ビジネスの密度が高いエリアが明確に存在します。このドキュメントの残りの部分では、これらの有望なエリアの 1 つであるユニオン スクエア周辺に焦点を当て、見込み顧客の発掘の取り組みを詳しく見ていきます。
ステップ 3: CRM データをプレイス ID に正規化する
除外分析を行うには、まず CRM レコードをプレイス ID に変換する必要があります。CRM データは構造化されていないことが多いため、検索 API に未加工のテキストを渡すと、一致率が低くなります。この 2 段階のパイプラインを使用して、住所をクリーンアップし、地域ごとの API の対象範囲を考慮して、BigQuery の正しい Establishment Place ID を抽出します。
ニューヨーク市に所在する次の 5 つのレストランの顧客が CRM に登録されているとします。
| 場所の名前 | 住所 |
|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States |
| Gramercy Tavern | 42 E 20th St, New York, NY 10003, United States |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States |
| Union Square Cafe | 101 E 19th St, New York, NY 10003, United States |
これらのレコードは非構造化テキストで構成されているため、BigQuery の Places Insights データと直接結合することはできません。代わりに、次のパイプラインで各行を処理して、テキストを標準化し、プレイス ID を抽出します。
ステップ 3a: 住所のクレンジングと直接照合
まず、住所データを標準化します。対象国に基づいて API を選択します。
オプション 1: Address Validation API
サポートされているリージョンでは、CRM のビジネス名と住所を連結して API に渡します。レスポンスの result.geocode.placeTypes 配列を調べます。
- Establishment Match:
establishmentまたはpoint_of_interestが含まれている場合、API はビジネスを正常に解決しました。このplaceIdをデータセットに追加して、次の CRM レコードに進みます。このエントリに対して API 呼び出しは不要です。 - 非設立一致: これらのビジネスタイプが含まれていない場合、API は事業体を明確に確認できませんでした。返されるプレイス ID は、地理的特徴(建物、道路、都市など)を表します。このプレイス ID を BigQuery で使用しないでください。除外結合が失敗します。代わりに、
result.address.formattedAddressを保存してステップ 3b に進みます。
オプション 2: Geocoding API
Address Validation の対象外の地域については、CRM の住所のみを Geocoding API に渡します。Geocoding API が予測不可能な結果を返す可能性があるため、ビジネス名は含めないでください。結果の formattedAddress を抽出し、ステップ 3b に進みます。
高度なアーキテクチャ: LLM を使用した非構造化データの処理
CRM データが非常に貧弱な場合(ビジネス名と住所が 1 つの自由形式のメモ フィールドに混在しているなど)、Gemini などの LLM を使用してレコードを前処理します。Gemini に、このパイプラインにフィードする前に、ビジネス名を場所から適切に解析するよう指示できます。
ステップ 3b: 法人情報を解決する
手順 3a でクリーンアップされた住所のみが返された場合は、元の CRM のお店やサービスの名前と連結して テキスト検索 API に渡します。最初に住所を標準化すると、マッチ率が大幅に向上します。
パフォーマンスと費用を最適化するには、フィールド マスク(X-Goog-FieldMask:
places.id)を使用して "pageSize": 1 を設定し、上位の一致のプレイス ID のみが返されるようにします。
テキスト検索リクエストの例:
curl -X POST -d '{
"textQuery" : "Gramercy Tavern 42 E 20th St, New York, NY 10003-1324, USA",
"pageSize": 1
}' \
-H 'Content-Type: application/json' -H 'X-Goog-Api-Key: YOUR_API_KEY' \
-H 'X-Goog-FieldMask: places.id' \
'https://places.googleapis.com/v1/places:searchText'
パイプラインの出力
この 2 段階のパイプラインで CRM レコードを処理した後、ステップ 3a で ID が正常に抽出されたか、ステップ 3b でテキスト検索を使用して解決されたかにかかわらず、最終的な目標は、新しい place_id 列をデータセットに追加することです。この結果のテーブルは、除外リストとして BigQuery にアップロードできるようになりました。
| 場所の名前 | 住所 | プレイス ID |
|---|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| Gramercy Tavern | 42 E 20th St, New York, NY 10003, United States | ChIJvSQIgqFZwokRFYQbJdzceSs |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States | ChIJQ7XpyqNZwokRQpVfvGEViWM |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States | ChIJFZh0PABZwokRVzoJu0o-mLY |
| Union Square Cafe | 101 E 19th St, New York, NY 10003, United States | ChIJxTHke6JZwokRCLWVd99eDBw |
ステップ 4: BigQuery で空白除外分析を行う
既存顧客をプレイス ID にマッピングしたら、場所のカウント関数を使用して、新規リードを見つけます。
この例では、ユニオン スクエア(40.73595、-73.99043)から半径 850 メートル以内の営業対象ビジネス(レストラン、バー、カフェ、コーヒー ショップ)を検索します。街路レベルのルーティングをより詳細に表示するため、PLACES_COUNT_PER_H3 関数を解像度 10 に増やします。
この関数は、sample_place_ids 列に場所 ID を配列として返すため、配列を UNNEST して、見込み顧客をそれぞれ独自の行に配置する必要があります。次に、既知の顧客のプレイス ID に対して LEFT JOIN を実行します。
このデモで除外ロジックが機能することを証明するため、次のクエリでは CASE ステートメントを使用して結果にフラグを設定し、結果を完全にフィルタリングしないようにしています。また、既存の顧客を結果テーブルの最上部に明示的に並べ替えるため、照合が成功したことを確認できます。
SQL クエリ
WITH existing_customers AS (
-- 1. Simulate the uploaded CRM table
SELECT * FROM UNNEST([
'ChIJc1Vf7KFZwokR1YL2Rn9oxi8', -- Boucherie Union Square
'ChIJvSQIgqFZwokRFYQbJdzceSs', -- Gramercy Tavern
'ChIJQ7XpyqNZwokRQpVfvGEViWM', -- Barn Joo Union Square
'ChIJFZh0PABZwokRVzoJu0o-mLY', -- LOS TACOS No.1
'ChIJxTHke6JZwokRCLWVd99eDBw' -- Union Square Cafe
]) AS place_id
),
target_area_businesses AS (
-- 2. Query Places Insights for target businesses in the radius
SELECT
h3_cell_index,
place_id
FROM `places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_GEOGPOINT(-73.99043, 40.73595),
'geography_radius', 850,
'h3_resolution', 10,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
),
UNNEST(sample_place_ids) AS place_id
)
-- 3. The "Proof" Output: Flag them instead of filtering them out
SELECT
t.h3_cell_index,
t.place_id,
-- Flag whether the LEFT JOIN found a match in the CRM table
CASE
WHEN e.place_id IS NOT NULL THEN 'Existing Customer (To Be Excluded)'
ELSE 'Net-New Lead'
END AS lead_status,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
ORDER BY
-- Explicitly sort the existing customers to the top (0 comes before 1)
CASE WHEN e.place_id IS NOT NULL THEN 0 ELSE 1 END ASC;
クエリ結果
クエリ出力の抜粋を次に示します。既存顧客が同じ粒度の H3 セル内の新規リードと区別されていることがわかります。
このクエリでは、CONCAT ステートメントを使用して place_id を使用してクロスプラットフォームの Maps URL を作成しています。これにより、actionable_maps_url 列が自動的に生成され、Google マップ モバイルアプリまたはブラウザで特定のビジネスを読み込むためのクリック可能なリンクが、営業チームにすぐに提供されます。
h3_cell_index |
place_id |
lead_status |
actionable_maps_url |
|---|---|---|---|
| 8a2a100d2767fff | ChIJQ7XpyqNZwokRQpVfvGEViWM | 既存のお客様(除外対象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJQ7XpyqNZwokRQpVfvGEViWM |
| 8a2a100d20effff | ChIJvSQIgqFZwokRFYQbJdzceSs | 既存のお客様(除外対象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJvSQIgqFZwokRFYQbJdzceSs |
| 8a2a100d2397fff | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 | 既存のお客様(除外対象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| 8a2a100d2397fff | ChIJFZh0PABZwokRVzoJu0o-mLY | 既存のお客様(除外対象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJFZh0PABZwokRVzoJu0o-mLY |
| 8a2a100d23b7fff | ChIJxTHke6JZwokRCLWVd99eDBw | 既存のお客様(除外対象) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJxTHke6JZwokRCLWVd99eDBw |
| 8a2a1072c96ffff | ChIJ6atD-WRZwokRULgcZ4TWin8 | 新規見込み顧客 | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ6atD-WRZwokRULgcZ4TWin8 |
| 8a2a1072c96ffff | ChIJ09yg-llZwokRKAgp0jg6TCU | 新規見込み顧客 | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ09yg-llZwokRKAgp0jg6TCU |
Places UI キットでリードを可視化する
生の地図 URL を提供する代わりに、place_ids を Places UI キットに直接渡して、営業チーム向けの豊富な社内リード生成ダッシュボードを構築できます。プラットフォーム間で利用できるため、ウェブ、Android、iOS 用の事前構築済みコンポーネントをドロップインできます。これらのコンポーネントは、フロントエンド UI コードを記述したり、API レスポンスを手動で処理したりすることなく、写真、評価、営業時間などの豊富な POI データを自動的に表示します。
データ制限
場所のカウント関数は、sample_place_ids 配列の地理的セルごとに最大 250 個のプレイス ID を返します。エリアの密度が非常に高い場合、その特定のセルの見込み顧客リストは 250 件に制限されます。市場の密度が高い地域で確実にすべての見込み顧客を獲得するには、次の戦略を検討してください。
- 特定のクエリフィルタを使用する: 上の例のように複数のタイプを 1 つのクエリにグループ化するのではなく、場所のタイプごとに個別のクエリを実行します。
- 空間範囲を縮小する: より小さい
geography_radiusを使用して検索範囲全体を縮小するか、H3 解像度を上げて(最大解像度 11 まで)範囲をより細かく分割します。 - 密度による解像度の調整: 人口密度の異なる地域を分析する場合は、検索サイズを動的に調整して、250 個のプレイス ID の上限に達しないようにします。ビジネスが分散している農村部では、より広範な H3 解像度(6 または 7 など)またはより大きな
geography_radiusを使用します。一方、都市部の人口密集地では、リストを切り捨てずにすべての見込み顧客を確実にキャッチできるよう、解像度を細かく設定します(10 または 11 など)。
本番環境クエリ
既存のお客様が正常に識別されたことを確認したら、クエリのプロダクション バージョンに戻すことができます。最後の SELECT ブロックを次の WHERE 句に置き換えて、既存のビジネスブックを永続的に除外します。
SELECT
t.h3_cell_index,
t.place_id,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
WHERE e.place_id IS NULL; -- Filters out the CRM matches
アーキテクチャ ガバナンスとコンプライアンス
パフォーマンスが高く、コンプライアンスに準拠したシステムを維持するには、次の標準に準拠します。
- 永続的な識別子としてのプレイス ID: プレイス ID 以外に、Google マップの利用規約では、Places API から返される個々の POI データ(電話番号や連絡先など)の保存やキャッシュ保存が禁止されています。プレイス ID を、繰り返し行われる空白分析の永続的な識別子として使用してください。
- リアルタイム API 呼び出しで属性の鮮度を確保する: プレイス ID を使用して Place Details API に「ジャスト イン タイム」呼び出しを行い、営業担当者が場所の最新のビジネス情報と連絡先情報を確実に取得できるようにします。また、クエリの出力で示されているように、Google マップの URL を動的に作成して、Google マップのビジネス プロフィールへの直接リンクを営業チームに提供することもできます。
まとめ
プレイス ID を主キーとして標準化することで、高度な市場分析と、実行可能な現場レベルの販売業務との間のギャップを埋めることに成功しました。このアーキテクチャは、従来の人口ベースのターゲティングの不正確さを回避し、大量の計算結合にサーバーレス データ ウェアハウジングを利用し、API レイヤで費用管理とコンプライアンスのベスト プラクティスを厳守します。
次のアクション
- Places Insights のサンプル データセットへのアクセスをリクエストします。
- BigQuery データ エクスチェンジ リスティングを使用して Places Insights データセットを購読し、サンプルまたは国の完全なデータにアクセスします。
- フィルタ パラメータのリファレンスを確認して、ビジネス属性とタイプに基づいて BigQuery SQL クエリを微調整します。
- CRM または販売ルート アプリケーションに動的な Places API ルックアップを実装して、生成された新規リードの最新の準拠した連絡先情報を公開します。
寄稿者
- Henrik Valve | DevX エンジニア