
ภาพรวม
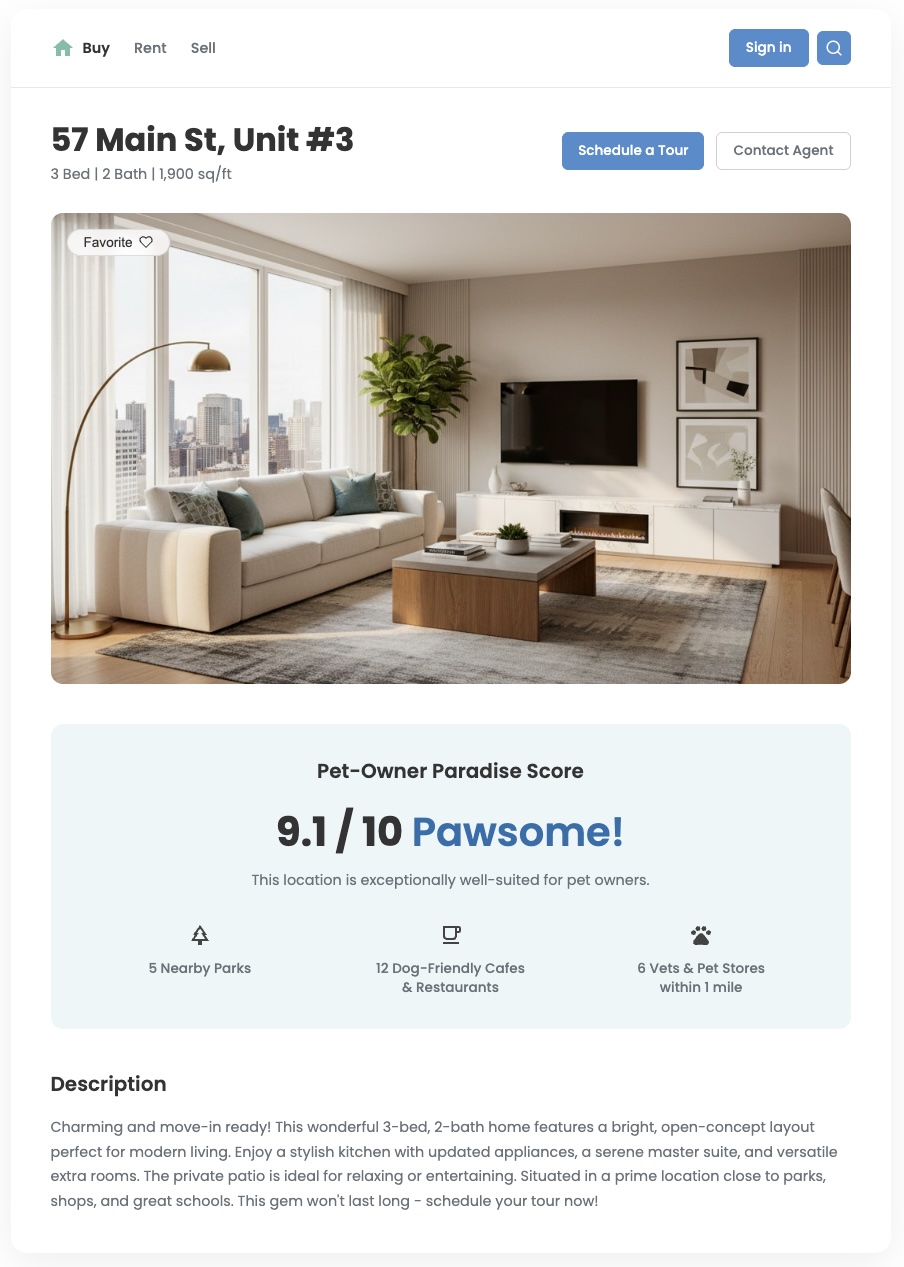
ข้อมูลตำแหน่งมาตรฐานจะบอกคุณได้ว่ามีอะไรอยู่ใกล้ๆ แต่ก็มักจะตอบคำถามที่สำคัญกว่าไม่ได้ นั่นคือ "ย่านนี้เหมาะกับฉันไหม" ความต้องการของ ผู้ใช้มีความแตกต่างกัน ครอบครัวที่มีเด็กเล็กมีลำดับความสำคัญที่แตกต่าง เมื่อเทียบกับคนหนุ่มสาวที่เพิ่งเริ่มทำงานและมีสุนัข คุณต้องให้ข้อมูลเชิงลึกที่สะท้อนความต้องการเฉพาะเหล่านี้เพื่อช่วยให้ผู้ใช้ตัดสินใจได้อย่างมั่นใจ คะแนนตำแหน่งที่กำหนดเองเป็นเครื่องมือที่มีประสิทธิภาพในการมอบมูลค่านี้และสร้างประสบการณ์ของผู้ใช้ที่แตกต่างอย่างเห็นได้ชัด
เอกสารนี้อธิบายวิธีสร้างคะแนนสถานที่ตั้งแบบหลายมิติที่กำหนดเอง โดยใช้ชุดข้อมูล ข้อมูลเชิงลึกเกี่ยวกับสถานที่ ใน BigQuery การเปลี่ยนข้อมูลจุดที่น่าสนใจให้เป็นเมตริกที่มีความหมายจะช่วยเพิ่มคุณค่าให้กับแอปพลิเคชันอสังหาริมทรัพย์ ค้าปลีก หรือการท่องเที่ยว และให้ข้อมูลที่เกี่ยวข้องซึ่งผู้ใช้ต้องการ นอกจากนี้ เรายังมีตัวเลือกในการใช้ Generative AI ใน BigQuery ซึ่งเป็นวิธีที่มีประสิทธิภาพในการคำนวณคะแนนตำแหน่ง
เพิ่มมูลค่าทางธุรกิจด้วยคะแนนที่ปรับแต่ง
ตัวอย่างต่อไปนี้แสดงให้เห็นวิธีที่คุณสามารถแปลข้อมูลตำแหน่งดิบเป็นเมตริกที่เน้นผู้ใช้เป็นหลักที่มีประสิทธิภาพเพื่อปรับปรุงแอปพลิเคชัน
- นักพัฒนาอสังหาริมทรัพย์สามารถสร้าง "คะแนนความเป็นมิตรกับครอบครัว" หรือ "คะแนนในฝันของคนเดินทาง" เพื่อช่วยให้ผู้ซื้อและผู้เช่าเลือกย่านที่เหมาะกับไลฟ์สไตล์ของตนเองได้ ซึ่งจะช่วยเพิ่มการมีส่วนร่วมของผู้ใช้ โอกาสในการขายที่มีคุณภาพสูงขึ้น และ Conversion ที่เร็วขึ้น
- วิศวกรด้านการท่องเที่ยวและโรงแรมสามารถสร้าง "คะแนนสถานบันเทิงยามค่ำคืน" หรือ "คะแนนสวรรค์ของนักท่องเที่ยว" เพื่อช่วยให้นักเดินทางเลือกโรงแรมที่ตรงกับสไตล์การพักผ่อน ซึ่งจะช่วยเพิ่มอัตราการจองและความพึงพอใจของลูกค้า
- นักวิเคราะห์ค้าปลีกสามารถสร้าง "คะแนนฟิตเนสและสุขภาพ" เพื่อระบุ สถานที่ตั้งที่เหมาะสมที่สุดสำหรับยิมหรือร้านขายอาหารเพื่อสุขภาพแห่งใหม่โดยอิงตาม ธุรกิจเสริมที่อยู่ใกล้เคียง เพื่อเพิ่มศักยภาพในการกำหนดเป้าหมายไปยังกลุ่มประชากรผู้ใช้ที่เหมาะสม ให้ได้สูงสุด
ในคู่มือนี้ คุณจะได้เรียนรู้ระเบียบวิธีแบบ 3 ส่วนที่ยืดหยุ่นสำหรับการสร้างคะแนนสถานที่ตั้งที่กำหนดเองทุกประเภทโดยใช้ข้อมูล Places ใน BigQuery โดยตรง เรา จะอธิบายรูปแบบนี้โดยการสร้างคะแนนตัวอย่างที่แตกต่างกัน 2 รายการ ได้แก่ คะแนนความเป็นมิตรกับครอบครัวและคะแนนสวรรค์ของคนรักสัตว์ แนวทางนี้ ช่วยให้คุณก้าวข้ามการนับสถานที่และใช้ประโยชน์จากแอตทริบิวต์ที่สมบูรณ์และมีรายละเอียด ภายในชุดข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่ คุณใช้ข้อมูล เช่น เวลาทำการ สถานที่เหมาะสำหรับเด็กหรือไม่ หรืออนุญาตให้นำสุนัขเข้าได้หรือไม่ เพื่อ สร้างเมตริกที่ซับซ้อนและมีความหมายสำหรับผู้ใช้ได้
เวิร์กโฟลว์ของโซลูชัน
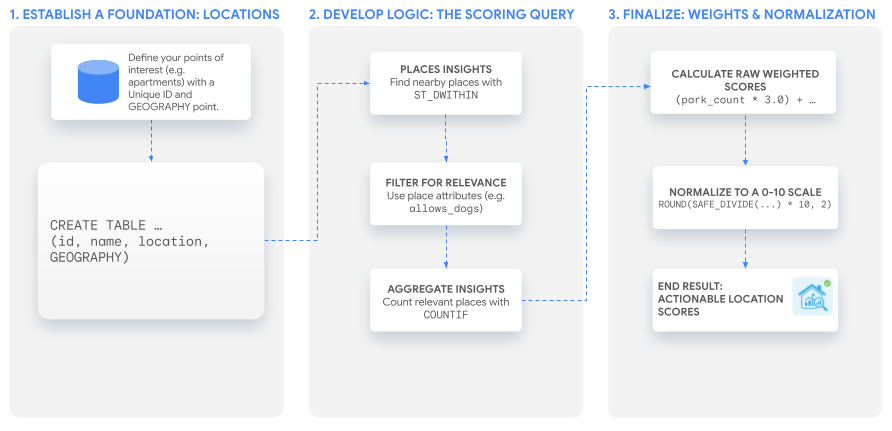
บทแนะนำนี้ใช้การค้นหา SQL ที่มีประสิทธิภาพเพียงรายการเดียวเพื่อสร้างคะแนนที่กำหนดเองซึ่งคุณ สามารถปรับให้เข้ากับกรณีการใช้งานใดก็ได้ เราจะอธิบายกระบวนการนี้โดยการสร้างคะแนนตัวอย่าง 2 รายการสำหรับชุดข้อมูลอพาร์ตเมนต์สมมติ
หากต้องการสำรวจเวิร์กโฟลว์นี้ในสภาพแวดล้อมแบบอินเทอร์แอกทีฟ ให้เรียกใช้สมุดบันทึกต่อไปนี้
วิดีโอนี้แสดงวิธีใช้ฟังก์ชัน
AI.GENERATE ภายใน BigQuery เพื่อสร้างคะแนนตำแหน่ง
 ดูแหล่งที่มาใน GitHub
ดูแหล่งที่มาใน GitHub
ข้อกำหนดเบื้องต้น
ก่อนเริ่มต้น ให้ทำตามวิธีการ เหล่านี้เพื่อตั้งค่าข้อมูลเชิงลึกเกี่ยวกับสถานที่
1. สร้างรากฐาน: สถานที่ที่สนใจ
คุณต้องมีรายชื่อสถานที่ที่ต้องการวิเคราะห์ก่อนจึงจะสร้างคะแนนได้
ขั้นตอนแรกคือการตรวจสอบว่าข้อมูลนี้มีอยู่ในรูปแบบตารางใน BigQuery
สิ่งสำคัญคือต้องมีตัวระบุที่ไม่ซ้ำกันสำหรับแต่ละสถานที่และGEOGRAPHY
คอลัมน์ที่จัดเก็บพิกัด
คุณสร้างและป้อนข้อมูลตารางสถานที่เพื่อจัดอันดับด้วยการค้นหาต่อไปนี้ได้
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
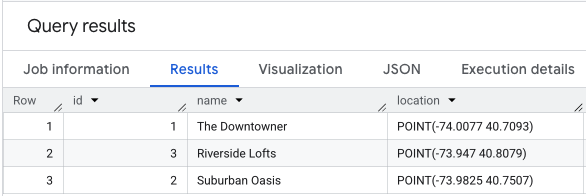
การดำเนินการ SELECT * กับข้อมูลตำแหน่งจะมีลักษณะคล้ายกับตัวอย่างต่อไปนี้
2. พัฒนากฎหลัก: การค้นหาการให้คะแนน
เมื่อกำหนดสถานที่ตั้งแล้ว ขั้นตอนถัดไปคือการค้นหา กรอง และนับ
สถานที่ใกล้เคียงที่เกี่ยวข้องกับคะแนนที่กำหนดเอง ทั้งหมดนี้ทำได้ภายใน
คำสั่ง SELECT เดียว
ค้นหาสิ่งที่อยู่ใกล้เคียงด้วยการค้นหาเชิงพื้นที่
ก่อนอื่น คุณต้องค้นหาสถานที่ทั้งหมดจากชุดข้อมูลข้อมูลเชิงลึกเกี่ยวกับสถานที่ซึ่งอยู่
ภายในระยะทางที่กำหนดจากสถานที่ตั้งแต่ละแห่ง ฟังก์ชัน BigQuery
ST_DWITHIN เหมาะสำหรับกรณีนี้ เราจะทำการJOINระหว่างตาราง apartment_listings กับตาราง places_insights เพื่อค้นหาสถานที่ทั้งหมดภายในรัศมี 800 เมตร LEFT JOIN ช่วยให้มั่นใจได้ว่าระบบจะรวมสถานที่ตั้งเดิมทั้งหมดไว้ในผลการค้นหา แม้ว่าจะไม่พบสถานที่ที่ตรงกันในบริเวณใกล้เคียงก็ตาม
กรองตามความเกี่ยวข้องด้วยแอตทริบิวต์ขั้นสูง
ในส่วนนี้ คุณจะเปลี่ยนแนวคิดที่เป็นนามธรรมของคะแนนให้เป็นตัวกรองข้อมูลที่เป็นรูปธรรมได้ สำหรับคะแนนตัวอย่าง 2 รายการ เกณฑ์จะแตกต่างกันดังนี้
- สำหรับ "คะแนนความเป็นมิตรกับครอบครัว" เราจะพิจารณาจากสวนสาธารณะ พิพิธภัณฑ์ และ ร้านอาหารที่เหมาะสำหรับเด็กโดยเฉพาะ
- สำหรับ "คะแนนสวรรค์ของเจ้าของสัตว์เลี้ยง" เราจะพิจารณาจากสวนสาธารณะ คลินิกสัตวแพทย์ ร้านขายสัตว์เลี้ยง รวมถึงร้านอาหารหรือคาเฟ่ที่อนุญาตให้นำสุนัขเข้าไปได้
คุณกรองแอตทริบิวต์ที่เฉพาะเจาะจงเหล่านี้ได้โดยตรงในอนุประโยค WHERE ของ
การค้นหา
รวบรวมข้อมูลเชิงลึกสำหรับแต่ละสถานที่
สุดท้าย คุณต้องนับจำนวนสถานที่ที่เกี่ยวข้องซึ่งพบสำหรับอพาร์ตเมนต์แต่ละแห่ง
โดยGROUP BYจะรวบรวมผลลัพธ์ และฟังก์ชัน COUNTIF
จะนับสถานที่ที่ตรงกับเกณฑ์ที่เฉพาะเจาะจงสำหรับคะแนนแต่ละรายการ
คําค้นหาด้านล่างจะรวม 3 ขั้นตอนนี้เข้าด้วยกันเพื่อคํานวณจํานวนดิบสําหรับคะแนนทั้ง 2 รายการในรอบเดียว
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
ผลลัพธ์ของการค้นหานี้จะคล้ายกับผลลัพธ์ต่อไปนี้
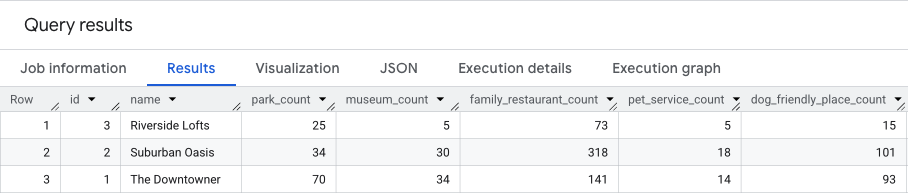
เราจะต่อยอดจากผลลัพธ์เหล่านี้ในส่วนถัดไป
3. สร้างคะแนน
ตอนนี้คุณมีจำนวนสถานที่และการให้น้ำหนักสำหรับสถานที่แต่ละประเภทของแต่ละ สถานที่แล้ว คุณจึงสร้างคะแนนสถานที่ที่กำหนดเองได้ ในส่วนนี้ เราจะพูดถึง 2 ตัวเลือก ได้แก่ การใช้การคำนวณที่กำหนดเองใน BigQuery หรือการใช้ฟังก์ชันปัญญาประดิษฐ์ (AI) แบบ Generative ใน BigQuery
ตัวเลือกที่ 1: ใช้การคำนวณที่กำหนดเองใน BigQuery
จำนวนดิบจากขั้นตอนก่อนหน้ามีประโยชน์ แต่เป้าหมายคือคะแนนเดียวที่ใช้งานง่าย ขั้นตอนสุดท้ายคือการรวมจำนวนเหล่านี้โดยใช้ น้ำหนัก แล้วปรับผลลัพธ์ให้อยู่ในระดับ 0-10
การใช้การถ่วงน้ำหนักที่กำหนดเอง การเลือกการถ่วงน้ำหนักเป็นทั้งศาสตร์และศิลป์ โดยควรสะท้อนถึงลำดับความสำคัญทางธุรกิจของคุณ หรือสิ่งที่คุณเชื่อว่าสำคัญที่สุดสำหรับผู้ใช้ สำหรับคะแนน "เหมาะสำหรับครอบครัว" คุณอาจตัดสินใจว่า สวนสาธารณะสำคัญเป็น 2 เท่าของพิพิธภัณฑ์ เริ่มต้นด้วยสมมติฐานที่ดีที่สุดและ ทำซ้ำตามความคิดเห็นของผู้ใช้
การปรับคะแนนให้เป็นมาตรฐาน คำค้นหาด้านล่างใช้ Common Table Expressions
(CTEs) 2 รายการ โดยรายการแรกจะคำนวณจำนวนดิบเช่นเดียวกับก่อนหน้า และรายการที่ 2 จะคำนวณ
คะแนนแบบถ่วงน้ำหนัก จากนั้นSELECTคำสั่งสุดท้ายจะทำการปรับค่าให้เป็นช่วงต่ำสุด-สูงสุด
ในคะแนนที่มีการถ่วงน้ำหนัก ระบบจะแสดงผลคอลัมน์ location ของตารางตัวอย่าง
apartment_listings เพื่อเปิดใช้การแสดงข้อมูลผ่านภาพบนแผนที่
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
ผลลัพธ์ของคำค้นหาจะคล้ายกับด้านล่าง 2 คอลัมน์สุดท้ายคือ คะแนนที่ปรับให้เป็นค่าปกติ

ทำความเข้าใจคะแนนที่ปรับแล้ว
คุณควรเข้าใจว่าเหตุใดขั้นตอนการปรับให้เป็นมาตรฐานขั้นสุดท้ายนี้จึงมีคุณค่ามาก
คะแนนถ่วงน้ำหนักดิบอาจมีตั้งแต่ 0 ไปจนถึงจำนวนที่อาจมาก
โดยขึ้นอยู่กับความหนาแน่นของเมืองในสถานที่ตั้งของคุณ คะแนน 500
ไม่มีความหมายสำหรับผู้ใช้ที่ไม่มีบริบท
การปรับให้เป็นมาตรฐานจะเปลี่ยนตัวเลขเชิงนามธรรมเหล่านี้เป็นการจัดอันดับแบบสัมพัทธ์ การปรับขนาดผลลัพธ์จาก 0 ถึง 10 จะช่วยให้คะแนนสื่อสารได้อย่างชัดเจนว่าแต่ละ สถานที่ตั้งเป็นอย่างไรเมื่อเทียบกับสถานที่ตั้งอื่นๆ ในชุดข้อมูลที่เฉพาะเจาะจง
- ระบบจะกำหนดคะแนน 10 ให้กับสถานที่ที่มีคะแนนดิบสูงสุด เพื่อทำเครื่องหมายให้เป็นตัวเลือกที่ดีที่สุดในชุดปัจจุบัน
- ระบบจะกำหนดคะแนน 0 ให้กับสถานที่ที่มีคะแนนดิบต่ำที่สุด ซึ่งจะกลายเป็นเกณฑ์พื้นฐานสำหรับการเปรียบเทียบ ซึ่งไม่ได้หมายความว่าที่พักไม่มีสิ่งอำนวยความสะดวกเลย แต่หมายความว่าที่พักนั้นไม่เหมาะสมที่สุดเมื่อเทียบกับตัวเลือกอื่นๆ ที่กำลังประเมิน
- คะแนนอื่นๆ ทั้งหมดจะอยู่ระหว่างคะแนนเหล่านี้ตามสัดส่วน ซึ่งจะช่วยให้ผู้ใช้มีวิธีที่ชัดเจนและใช้งานง่ายในการเปรียบเทียบตัวเลือกต่างๆ ได้อย่างรวดเร็ว
ตัวเลือกที่ 2: ใช้ฟังก์ชัน AI.GENERATE (Gemini)
คุณสามารถใช้ฟังก์ชัน BigQuery AI.GENERATE แทนการใช้สูตรทางคณิตศาสตร์แบบคงที่เพื่อคำนวณคะแนนสถานที่ที่กำหนดเองได้โดยตรงภายในเวิร์กโฟลว์ SQL
แม้ว่าตัวเลือกที่ 1 จะเหมาะสำหรับการให้คะแนนเชิงปริมาณโดยอิงตามจำนวนสิ่งอำนวยความสะดวก แต่ก็ไม่สามารถนำข้อมูลเชิงคุณภาพมาพิจารณาได้ง่ายๆ ฟังก์ชัน AI.GENERATE ช่วยให้คุณรวมตัวเลขจากการค้นหาข้อมูลเชิงลึกเกี่ยวกับสถานที่กับข้อมูลที่ไม่มีโครงสร้าง เช่น คำอธิบายข้อความของข้อมูลอพาร์ตเมนต์ (เช่น "ที่พักนี้เหมาะสำหรับครอบครัวและเงียบสงบในตอนกลางคืน") หรือค่ากำหนดโปรไฟล์ผู้ใช้ที่เฉพาะเจาะจง (เช่น "ผู้ใช้รายนี้จองที่พักสำหรับครอบครัวและต้องการที่พักในย่านที่เงียบสงบในทำเลใจกลางเมือง") ซึ่งช่วยให้คุณสร้างคะแนนที่ซับซ้อนมากขึ้น ซึ่งตรวจจับความแตกต่างที่การนับอย่างเข้มงวดอาจพลาดไปได้ เช่น สถานที่ที่มีสิ่งอำนวยความสะดวกหนาแน่นสูงแต่ก็อธิบายว่า "เสียงดังเกินไปสำหรับเด็ก"
สร้างพรอมต์
หากต้องการใช้ฟังก์ชันนี้ ระบบจะจัดรูปแบบผลลัพธ์ของการรวม (จากขั้นตอนที่ 2) เป็นพรอมต์ภาษาธรรมชาติ ซึ่งทำได้แบบไดนามิกใน SQL โดย เชื่อมต่อคอลัมน์ข้อมูลกับคำสั่งสำหรับโมเดล
ในคำค้นหาด้านล่าง insight_counts จะรวมกับคำอธิบายข้อความของ
อพาร์ตเมนต์เพื่อสร้างพรอมต์สำหรับแต่ละแถว นอกจากนี้ ยังมีการกำหนดโปรไฟล์ผู้ใช้เป้าหมาย
เพื่อเป็นแนวทางในการให้คะแนนด้วย
สร้างคะแนนด้วย SQL
การค้นหาต่อไปนี้จะดำเนินการทั้งหมดใน BigQuery ได้แก่
- รวมจำนวนสถานที่ (ตามที่อธิบายไว้ในขั้นตอนที่ 2)
- สร้างพรอมต์สำหรับแต่ละสถานที่
- เรียกฟังก์ชัน
AI.GENERATEเพื่อวิเคราะห์พรอมต์โดยใช้โมเดล Gemini - แยกวิเคราะห์ผลลัพธ์เป็นรูปแบบที่มีโครงสร้างพร้อมใช้งานในแอปพลิเคชัน ของคุณ
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
ทําความเข้าใจการกําหนดค่า
- การรับรู้ต้นทุน: ฟังก์ชันนี้จะส่งอินพุตของคุณไปยังโมเดล Gemini และ จะมีการเรียกเก็บเงินใน Vertex AI ทุกครั้งที่มีการเรียกใช้ หากมีการวิเคราะห์สถานที่จำนวนมาก (เช่น ข้อมูลอพาร์ตเมนต์หลายพันรายการ) เราขอแนะนำให้กรองชุดข้อมูลไปยังผู้สมัครที่มีความเกี่ยวข้องมากที่สุดก่อน ดูรายละเอียดเพิ่มเติมเกี่ยวกับการลดต้นทุนได้ที่แนวทางปฏิบัติแนะนำ
endpoint: มีการระบุgemini-flash-latestสำหรับตัวอย่างนี้เพื่อ จัดลำดับความสำคัญของความเร็วและประสิทธิภาพด้านต้นทุน อย่างไรก็ตาม คุณสามารถเลือกโมเดล ที่เหมาะกับความต้องการของคุณมากที่สุดได้ ดูเอกสารประกอบโมเดล Gemini เพื่อทดลองใช้เวอร์ชันต่างๆ (เช่น Gemini Pro สำหรับงานให้เหตุผลที่ซับซ้อนมากขึ้น) และค้นหาเวอร์ชันที่เหมาะกับกรณีการใช้งานของคุณมากที่สุดoutput_schema: มีการบังคับใช้สคีมาแทนการแยกวิเคราะห์ข้อความดิบ (FLOAT64สำหรับคะแนนและSTRINGสำหรับเหตุผล) ซึ่งจะช่วยให้คุณใช้เอาต์พุตในแอปพลิเคชันหรือเครื่องมือแสดงภาพได้ทันที โดยไม่ต้องทำการประมวลผลภายหลัง
ตัวอย่างเอาต์พุต
การค้นหาจะแสดงตาราง BigQuery มาตรฐานที่มีคะแนนที่กำหนดเองและเหตุผลของโมเดล
| id | ชื่อ | family_friendliness_score | การให้เหตุผล |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | มีสิ่งอำนวยความสะดวกที่ยอดเยี่ยม (สวนสาธารณะ ร้านอาหาร) ซึ่งเป็นไปตามเมตริกเชิงปริมาณ อย่างไรก็ตาม ข้อมูลเชิงคุณภาพระบุว่ามีเสียงรบกวนในช่วงสุดสัปดาห์มากเกินไปและมุ่งเน้นไปที่สถานบันเทิงยามค่ำคืน ซึ่งขัดแย้งโดยตรงกับความต้องการความเงียบของผู้ใช้เป้าหมาย |
| 2 | Suburban Oasis | 9.8 | ข้อมูลเชิงปริมาณที่โดดเด่นรวมกับคำอธิบาย ("ถนนที่เงียบสงบและมีต้นไม้เรียงราย") ซึ่งสอดคล้องกับโปรไฟล์ครอบครัวเป้าหมายอย่างสมบูรณ์ ตัวปรับค่าบวกสูงจะส่งผลให้ได้คะแนนที่เกือบสมบูรณ์ |
กระบวนการนี้ช่วยให้คุณแสดงคะแนนที่มีการปรับเปลี่ยนในแบบของคุณสูง ซึ่งดู เข้าใจง่ายและปรับให้เหมาะกับผู้ใช้แต่ละรายได้ทั้งหมดภายในคําค้นหา SQL เดียว
4. แสดงภาพคะแนนของคุณบนแผนที่
BigQuery Studio มีการแสดงภาพแผนที่แบบผสานรวม
สําหรับผลการค้นหาใดๆ ที่มีคอลัมน์ GEOGRAPHY เนื่องจากเอาต์พุตการค้นหาของเรา
คือคอลัมน์ location คุณจึงเห็นภาพคะแนนได้ทันที
การคลิกแท็บ Visualization จะแสดงแผนที่ และData Column
เมนูแบบเลื่อนลงจะควบคุมคะแนนสถานที่เพื่อแสดงภาพ ในตัวอย่างนี้ normalized_pet_score จะแสดงภาพจากตัวอย่างตัวเลือกที่ 1 โปรดทราบว่าเราได้เพิ่มสถานที่ตั้งอื่นๆ ลงในตาราง apartment_listings สำหรับตัวอย่างนี้
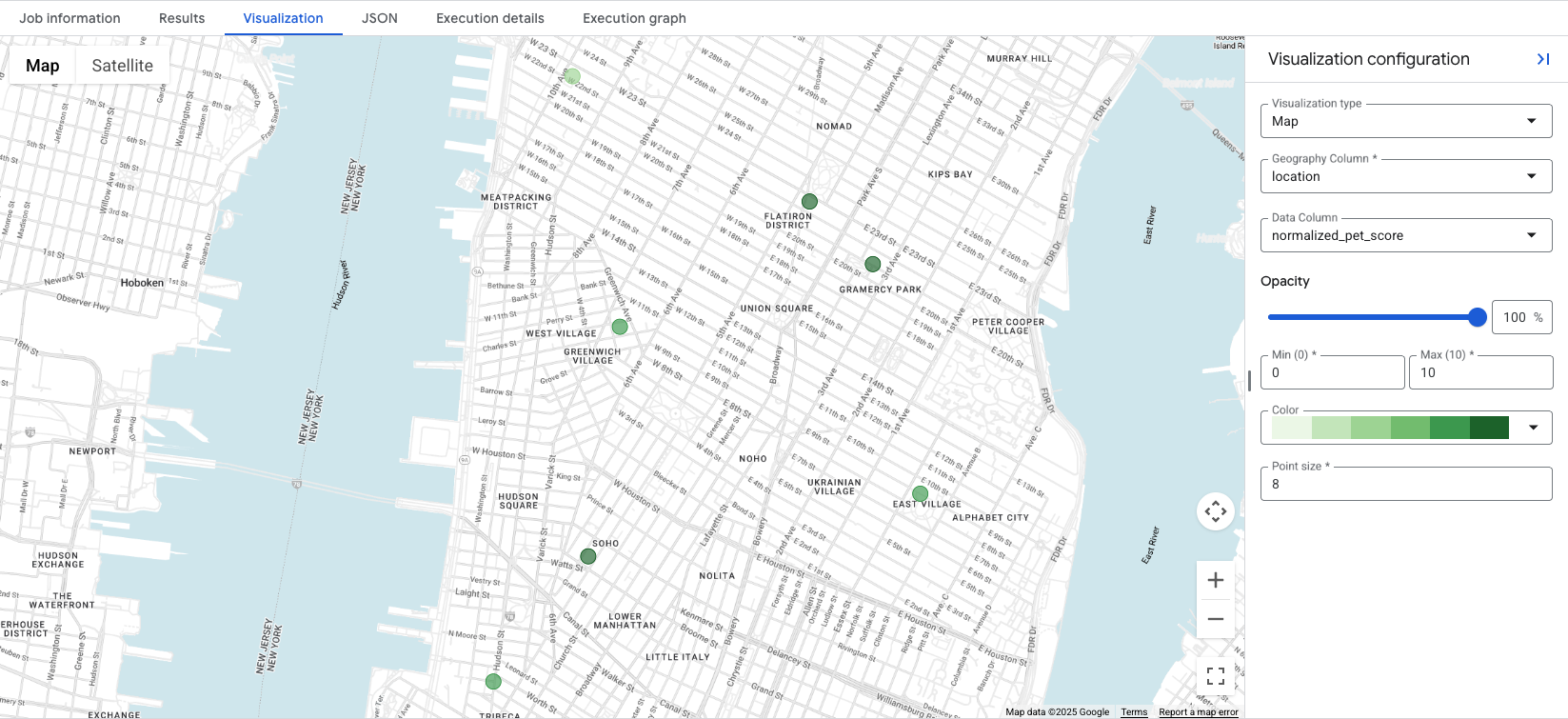
การแสดงข้อมูลด้วยภาพจะเผยให้เห็นในพริบตาว่าสถานที่ที่เหมาะสมที่สุดสำหรับคะแนนที่สร้างขึ้นคือที่ใด โดยวงกลมสีเขียวเข้มแสดงถึงสถานที่ที่มี normalized_pet_score สูงกว่าในกรณีนี้ ดูตัวเลือกการแสดงข้อมูลเชิงลึกเกี่ยวกับสถานที่เพิ่มเติมได้ที่แสดงผลลัพธ์
การค้นหา
บทสรุป
ตอนนี้คุณมีวิธีการที่มีประสิทธิภาพและทำซ้ำได้ในการสร้างคะแนนสถานที่ที่ซับซ้อน
คุณเริ่มต้นด้วยสถานที่ตั้งและสร้างการค้นหา SQL รายการเดียวใน BigQuery ซึ่งจะค้นหาสถานที่ใกล้เคียงที่มี ST_DWITHIN กรองตามแอตทริบิวต์ขั้นสูง เช่น good_for_children และ allows_dogs และรวบรวมผลลัพธ์ด้วย COUNTIF การใช้การถ่วงน้ำหนักที่กำหนดเองและการปรับผลลัพธ์ให้เป็นมาตรฐาน
ทำให้คุณได้คะแนนเดียวที่ใช้งานง่ายซึ่งให้ข้อมูลเชิงลึกที่นำไปใช้ได้จริง
คุณสามารถใช้รูปแบบนี้โดยตรงเพื่อเปลี่ยนข้อมูลตำแหน่งดิบให้เป็นความได้เปรียบทางการแข่งขันที่สำคัญ
การดำเนินการถัดไป
ตอนนี้ถึงตาคุณสร้างแล้ว บทแนะนำนี้มีเทมเพลตให้ คุณสามารถใช้ข้อมูลที่สมบูรณ์ซึ่งมีอยู่ในสคีมาข้อมูลเชิงลึกเกี่ยวกับสถานที่เพื่อสร้างคะแนนที่จำเป็นที่สุดสำหรับกรณีการใช้งานของคุณ พิจารณาคะแนนอื่นๆ ที่คุณสร้างได้
- "คะแนนสถานบันเทิงยามค่ำคืน": รวมตัวกรองสำหรับ
primary_type(bar,night_club),price_levelและเวลาทำการช่วงดึกเพื่อค้นหาพื้นที่ที่มีชีวิตชีวาที่สุดหลังค่ำ - "คะแนนการออกกำลังกายและสุขภาพ": นับ
gyms,parksและhealth_food_storesที่อยู่ใกล้เคียง และกรองร้านอาหารที่มีserves_vegetarian_foodเพื่อให้คะแนนสถานที่ตั้งสำหรับผู้ใช้ที่ใส่ใจสุขภาพ - "คะแนนความฝันของคนเดินทาง": ค้นหาสถานที่ที่มี
transit_stationและparkingจำนวนมากในบริเวณใกล้เคียงเพื่อช่วยผู้ใช้ที่ให้ความสำคัญกับการเข้าถึงระบบขนส่ง
ผู้ร่วมให้ข้อมูล
Henrik Valve | DevX Engineer