
סקירה כללית
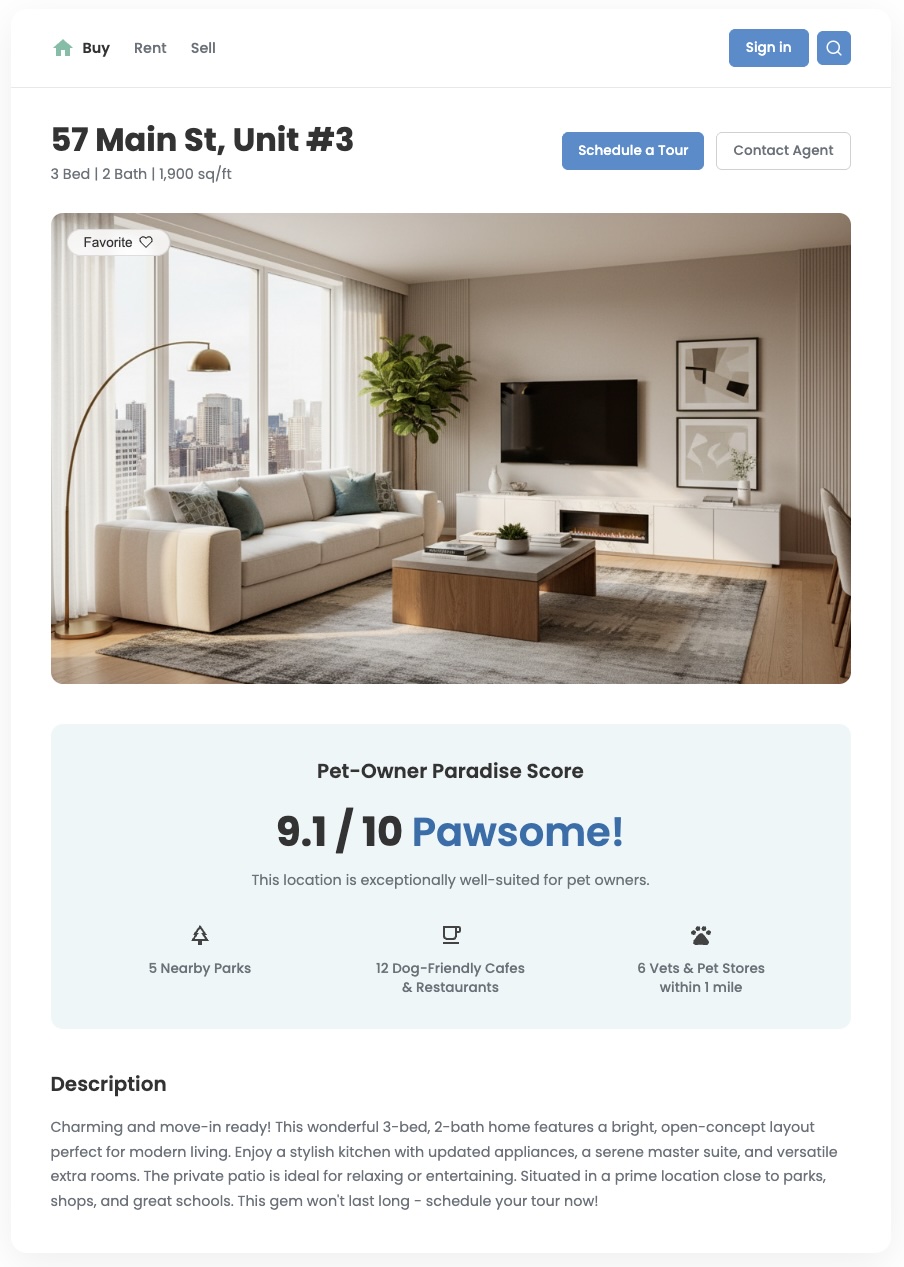
נתוני מיקום רגילים יכולים להגיד לכם מה יש בסביבה, אבל הם לרוב לא יכולים לענות על השאלה החשובה יותר: "עד כמה האזור הזה טוב בשבילי?" הצרכים של המשתמשים שלכם מורכבים. למשפחה עם ילדים קטנים יש סדרי עדיפויות שונים בהשוואה לאיש מקצוע צעיר עם כלב. כדי לעזור להם לקבל החלטות מושכלות, אתם צריכים לספק תובנות שמשקפות את הצרכים הספציפיים האלה. ציון מיקום מותאם אישית הוא כלי יעיל להעברת הערך הזה וליצירת חוויית משתמש ייחודית ומשמעותית.
במאמר הזה נסביר איך ליצור ציוני מיקום מותאמים אישית עם היבטים רבים באמצעות מערך הנתונים Places Insights ב-BigQuery. הפיכת נתוני נקודות עניין למדדים משמעותיים מאפשרת להעשיר את האפליקציות שלכם בתחומי הנדל"ן, הקמעונאות או התיירות, ולספק למשתמשים את המידע הרלוונטי שהם צריכים. אנחנו גם מספקים אפשרות להשתמש ב-AI גנרטיבי ב-BigQuery כדרך יעילה לחישוב ציוני המיקום.
הגדלת הערך העסקי באמצעות ציונים מותאמים
בדוגמאות הבאות אפשר לראות איך אפשר לתרגם נתוני מיקום גולמיים למדדים עוצמתיים שמבוססים על משתמשים, כדי לשפר את האפליקציה.
- מפתחי נדל "ן יכולים ליצור 'דירוג ידידותי למשפחות' או'דירוג מושלם לנוסעים' כדי לעזור לקונים ולשוכרים לבחור את השכונה המושלמת שתתאים לאורח החיים שלהם. כך הם יכולים להגדיל את רמת המעורבות של המשתמשים, להשיג לידים איכותיים יותר ולהגדיל את קצב ההמרות.
- מהנדסים בתחום התיירות והאירוח יכולים ליצור 'דירוג חיי הלילה' או 'דירוג גן עדן למטיילים' כדי לעזור למטיילים לבחור מלון שמתאים לסגנון החופשה שלהם, וכך להגדיל את שיעורי ההזמנות ואת שביעות רצון הלקוחות
- אנליסטים בתחום הקמעונאות יכולים ליצור 'ציון כושר ובריאות' כדי לזהות את המיקום האופטימלי לחדר כושר חדש או לחנות מזון בריאות, על סמך עסקים משלימים בקרבת מקום, וכך למקסם את הפוטנציאל לטרגט את הדמוגרפיה הנכונה של המשתמשים.
במדריך הזה תלמדו על מתודולוגיה גמישה בת שלושה חלקים ליצירת ניקוד מותאם אישית למיקום כלשהו באמצעות נתונים של 'מקומות' ישירות ב-BigQuery. כדי להמחיש את התבנית הזו, ניצור שני מדדים שונים לדוגמה: מדד ידידותיות למשפחות ומדד גן עדן לבעלי חיות מחמד. הגישה הזו מאפשרת לכם להסתמך על נתונים מעבר לספירת המקומות, וליהנות מהמאפיינים העשירים והמפורטים של קבוצת הנתונים 'Places Insights'. אתם יכולים להשתמש במידע כמו שעות הפתיחה של העסק, אם המקום מתאים לילדים או אם מותר להכניס אליו כלבים, כדי ליצור מדדים מתוחכמים ומשמעותיים למשתמשים שלכם.
תהליך העבודה של הפתרון
במדריך הזה נשתמש בשאילתת SQL אחת ועוצמתית כדי ליצור ניקוד מותאם אישית שאפשר להתאים לכל תרחיש שימוש. כדי להסביר את התהליך הזה, נשתמש בשני ציונים לדוגמה שמתייחסים לקבוצה היפותטית של מודעות להשכרת דירות.
כדי לנסות את תהליך העבודה הזה בסביבה אינטראקטיבית, מריצים את ה-notebook הבא. במדריך מוסבר איך להשתמש בפונקציה AI.GENERATE ב-BigQuery כדי ליצור ציון מיקום.
 הצגת המקור ב-GitHub
הצגת המקור ב-GitHub
דרישות מוקדמות
לפני שמתחילים, צריך לפעול בהתאם להוראות האלה כדי להגדיר את התובנות לגבי מקומות.
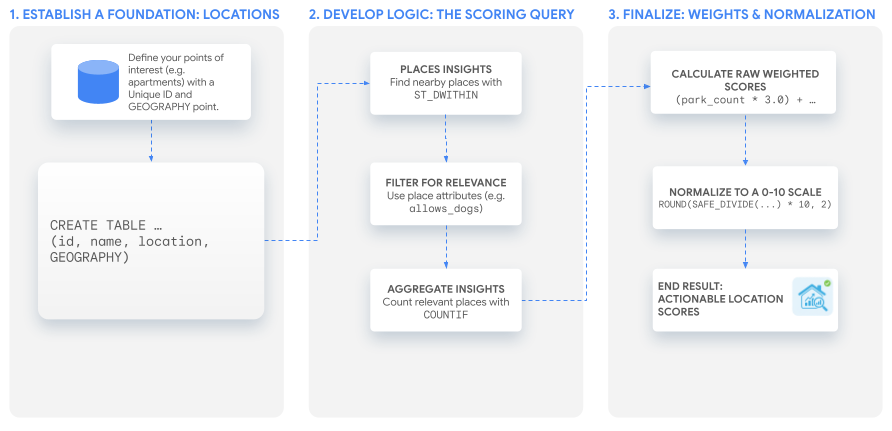
1. הנחת בסיס: המיקומים שיכולים לעניין את המשתמשים
כדי ליצור ציונים, צריך קודם ליצור רשימה של המיקומים שרוצים לנתח. השלב הראשון הוא לוודא שהנתונים האלה קיימים כטבלה ב-BigQuery.
העיקר הוא שיהיה מזהה ייחודי לכל מיקום וGEOGRAPHYעמודה שבה מאוחסנות הקואורדינטות שלו.
אתם יכולים ליצור טבלה של מיקומים ולמלא אותה באמצעות שאילתה כמו זו:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
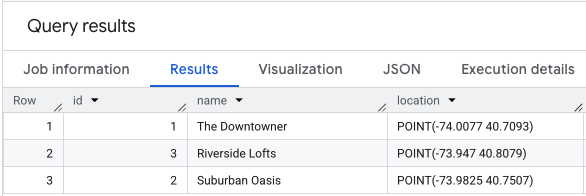
הפעולה SELECT * על נתוני המיקום תיראה בערך כך.
2. פיתוח הלוגיקה המרכזית: שאילתת הניקוד
אחרי שמגדירים את המיקומים, השלב הבא הוא למצוא, לסנן ולספור את המקומות הסמוכים שרלוונטיים לציון המותאם אישית. הכול מתבצע בהצהרת SELECT אחת.
חיפוש מקומות בסביבה באמצעות חיפוש גיאו-מרחבי
קודם כל, צריך למצוא את כל המקומות ממערך הנתונים של Places Insights שנמצאים במרחק מסוים מכל אחד מהמיקומים שלכם. הפונקציה ST_DWITHIN ב-BigQuery מתאימה בדיוק למטרה הזו. נבצע JOIN בין הטבלה apartment_listings לבין הטבלה places_insights כדי למצוא את כל המקומות ברדיוס של 800 מטרים. LEFT JOIN מוודא שכל המיקומים המקוריים שלכם נכללים בתוצאות, גם אם לא נמצאו מקומות תואמים בקרבת מקום.
סינון לפי רלוונטיות באמצעות מאפיינים מתקדמים
כאן מתרגמים את המושג המופשט של ניקוד למסנני נתונים קונקרטיים. בדוגמאות של שני הציונים, הקריטריונים שונים:
- בדירוג 'מתאים למשפחות', אנחנו מתייחסים לפארקים, למוזיאונים ולמסעדות שמתאימים במיוחד לילדים.
- בחישוב הציון 'גן עדן לבעלי חיות מחמד' אנחנו מתייחסים לפארקים, למרפאות וטרינריות, לחנויות לחיות מחמד ולכל מסעדה או בית קפה שמאפשרים כניסה עם כלבים.
אפשר לסנן לפי המאפיינים הספציפיים האלה ישירות בפסקה WHERE של השאילתה.
צבירת התובנות לכל מיקום
לבסוף, צריך לספור כמה מקומות רלוונטיים מצאתם לכל דירה. הפסקה GROUP BY צוברת את התוצאות, והפונקציה COUNTIF סופרת את המקומות שתואמים לקריטריונים הספציפיים של כל אחד מהציונים.
השאילתה הבאה משלבת את שלושת השלבים האלה ומחשבת את הספירות הגולמיות של שני הציונים במעבר אחד:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
התוצאה של השאילתה הזו תהיה דומה לזו.
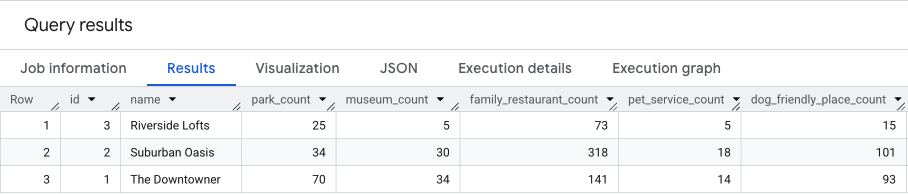
בקטע הבא נרחיב על התוצאות האלה.
3. יצירת הניקוד
עכשיו יש לכם את מספר המקומות ואת המשקל של כל סוג מקום בכל מיקום, ואתם יכולים ליצור את ציון המיקום המותאם אישית. בקטע הזה נדון בשתי אפשרויות: שימוש בחישוב מותאם אישית משלכם ב-BigQuery או שימוש בפונקציות של בינה מלאכותית (AI) גנרטיבית ב-BigQuery.
אפשרות 1: שימוש בחישוב מותאם אישית משלכם ב-BigQuery
הנתונים הגולמיים מהשלב הקודם מספקים תובנות חשובות, אבל המטרה היא לקבל ציון יחיד ונוח למשתמש. השלב האחרון הוא לשלב את הספירות האלה באמצעות משקלים, ואז לנרמל את התוצאה לסולם של 0 עד 10.
החלת משקלים מותאמים אישית בחירת המשקלים היא גם אומנות וגם מדע. הם צריכים לשקף את העדיפויות העסקיות שלכם או את מה שלדעתכם הכי חשוב למשתמשים. לדוגמה, כדי לקבל ציון של 'ידידותיות למשפחות', יכול להיות שתחליטו שפארק חשוב פי שניים ממוזיאון. כדאי להתחיל עם ההנחות הכי טובות שלכם ולבצע שינויים על סמך המשוב מהמשתמשים שלנו.
נרמול הניקוד בשאילתה שלמטה נעשה שימוש בשני ביטויי טבלה נפוצים (CTE): הראשון מחשב את הספירות הגולמיות כמו קודם, והשני מחשב את הניקוד המשוקלל. ההצהרה הסופית SELECT מבצעת נורמליזציה של מינימום-מקסימום בציונים המשוקללים. הפלט של העמודה location בטבלת הדוגמה apartment_listings מאפשר להציג את הנתונים במפה.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
תוצאות השאילתה יהיו דומות לתוצאות שמופיעות בהמשך. שתי העמודות האחרונות הן הציונים המנורמלים.

הסבר על הציון הנורמלי
חשוב להבין למה שלב הנורמליזציה הסופי הזה כל כך חשוב.
הציונים הגולמיים המשוקללים יכולים לנוע בין 0 למספר גדול מאוד, בהתאם לצפיפות העירונית של המיקומים שלכם. ציון של 500 לא אומר כלום למשתמש בלי הקשר.
הנרמול הופך את המספרים המופשטים האלה לדירוג יחסי. התוצאות מוצגות בסולם של 0 עד 10, כך שקל להבין את ההשוואה בין כל מיקום למיקומים האחרים במערך הנתונים הספציפי שלכם:
- ציון של 10 מוקצה למיקום עם הציון הגולמי הכי גבוה, והוא מסומן כאפשרות הטובה ביותר בקבוצה הנוכחית.
- ציון של 0 מוקצה למיקום עם הציון הגולמי הנמוך ביותר, והוא משמש כנקודת ההשוואה. זה לא אומר שבמיקום אין שירותים, אלא שהוא הכי פחות מתאים ביחס לאפשרויות האחרות שנבדקות.
- כל שאר הציונים ממוקמים באופן יחסי בין שני הקצוות, וכך המשתמשים יכולים להשוות בין האפשרויות שלהם במבט חטוף בצורה ברורה ואינטואיטיבית.
אפשרות 2: שימוש בפונקציה AI.GENERATE (Gemini)
במקום להשתמש בנוסחה מתמטית קבועה, אפשר להשתמש בפונקציה AI.GENERATE של BigQuery כדי לחשב ציוני מיקום מותאמים אישית ישירות בתהליך העבודה של SQL.
אפשרות 1 מצוינת לדירוג כמותי בלבד שמבוסס על מספר השירותים, אבל קשה להשתמש בה כדי לשקלל נתונים איכותיים. הפונקציה AI.GENERATE מאפשרת לכם לשלב את המספרים משאילתת Places Insights עם נתונים לא מובנים, כמו תיאור הטקסט של רשימת הדירות (לדוגמה, "המיקום הזה מתאים למשפחות והאזור שקט בלילה") או העדפות ספציפיות בפרופיל המשתמש (לדוגמה, "המשתמש הזה מזמין עבור משפחה ומעדיף אזור שקט במיקום מרכזי"). כך אפשר ליצור ניקוד מדויק יותר שמזהה ניואנסים שספירה מדויקת עלולה לפספס, כמו מיקום עם צפיפות גבוהה של מתקנים אבל גם עם תיאור של 'רועש מדי לילדים'.
הרכבת ההנחיה
כדי להשתמש בפונקציה הזו, התוצאות של הצבירה (משלב 2) מעוצבות להנחיה בשפה טבעית. אפשר לעשות זאת באופן דינמי ב-SQL על ידי שרשור של עמודות נתונים עם הוראות למודל.
בשורה הבאה, insight_counts משולבים עם תיאור הטקסט של הדירה כדי ליצור הנחיה לכל שורה. פרופיל משתמש יעד מוגדר גם כדי להנחות את הניקוד.
יצירת הניקוד באמצעות SQL
השאילתה הבאה מבצעת את כל הפעולה ב-BigQuery. התיוג האוטומטי:
- מצטבר את ספירת המקומות (כפי שמתואר בשלב 2).
- בונה הנחיה לכל מיקום.
- קוראת לפונקציה
AI.GENERATEכדי לנתח את ההנחיה באמצעות מודל Gemini. - מנתח את התוצאה לפורמט מובנה שמוכן לשימוש באפליקציה.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
הסבר על ההגדרה
- מודעות לעלויות: הפונקציה הזו מעבירה את הקלט שלכם למודל Gemini, וכל קריאה שלה כרוכה בחיוב ב-Vertex AI. אם מנתחים מספר גדול של מיקומים (למשל, אלפי רשימות של דירות), מומלץ לסנן את מערך הנתונים כדי להציג קודם את המיקומים הרלוונטיים ביותר. פרטים נוספים על צמצום העלויות זמינים במאמר בנושא שיטות מומלצות.
-
endpoint: בדוגמה הזו מצויןgemini-flash-latestכדי לתת עדיפות למהירות וליעילות מבחינת עלות. אבל אתם יכולים לבחור את המודל שהכי מתאים לצרכים שלכם. כדי להתנסות בגרסאות שונות (למשל, Gemini Pro למשימות מורכבות יותר של חשיבה רציונלית) ולמצוא את הגרסה שהכי מתאימה לתרחיש השימוש שלכם, אפשר לעיין במסמכי התיעוד של מודלים של Gemini. output_schema: במקום לנתח טקסט גולמי, מופעלת סכימה (FLOAT64לניקוד ו-STRINGלנימוק). כך אפשר להשתמש בתוצאה באופן מיידי באפליקציה או בכלי הוויזואליזציה שלכם בלי לבצע עיבוד נוסף.
פלט לדוגמה
השאילתה מחזירה טבלה ב-BigQuery עם הניקוד המותאם אישית וההסבר של המודל.
| id [מזהה] | שם | family_friendliness_score | חשיבה רציונלית |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | מספר רב של מתקנים (פארקים, מסעדות), בהתאם למדדים הכמותיים. עם זאת, הנתונים האיכותיים מצביעים על רעש מוגזם בסופי שבוע ועל התמקדות חזקה בחיי הלילה, וזה סותר ישירות את הצורך של משתמש היעד בשקט. |
| 2 | Suburban Oasis | 9.8 | נתונים כמותיים מצוינים בשילוב עם תיאור ("רחוב שקט עם עצים") שתואם באופן מושלם לפרופיל המשפחתי הממוקד. שימוש במגדילים חיוביים גבוהים יוביל לציון כמעט מושלם. |
התהליך הזה מאפשר לכם לספק ניקוד מותאם אישית מאוד, שנראה מובן ומותאם לכל משתמש בנפרד, והכול בשאילתת SQL אחת.
4. הצגה ויזואלית של הציונים במפה
BigQuery Studio כולל הדמיה משולבת של מפה לכל תוצאה של שאילתה שמכילה עמודה GEOGRAPHY. מכיוון שהשאילתה שלנו מוציאה את העמודה location, אפשר לראות את התוצאות באופן מיידי.
כשלוחצים על הכרטיסייה Visualization, המפה מוצגת, והתפריט הנפתח Data Column מאפשר לבחור את ציון המיקום שרוצים להציג. בדוגמה הזו, normalized_pet_score מוצג באופן חזותי מתוך דוגמה 1. שימו לב שבטבלה apartment_listings נוספו עוד מיקומים בדוגמה הזו.
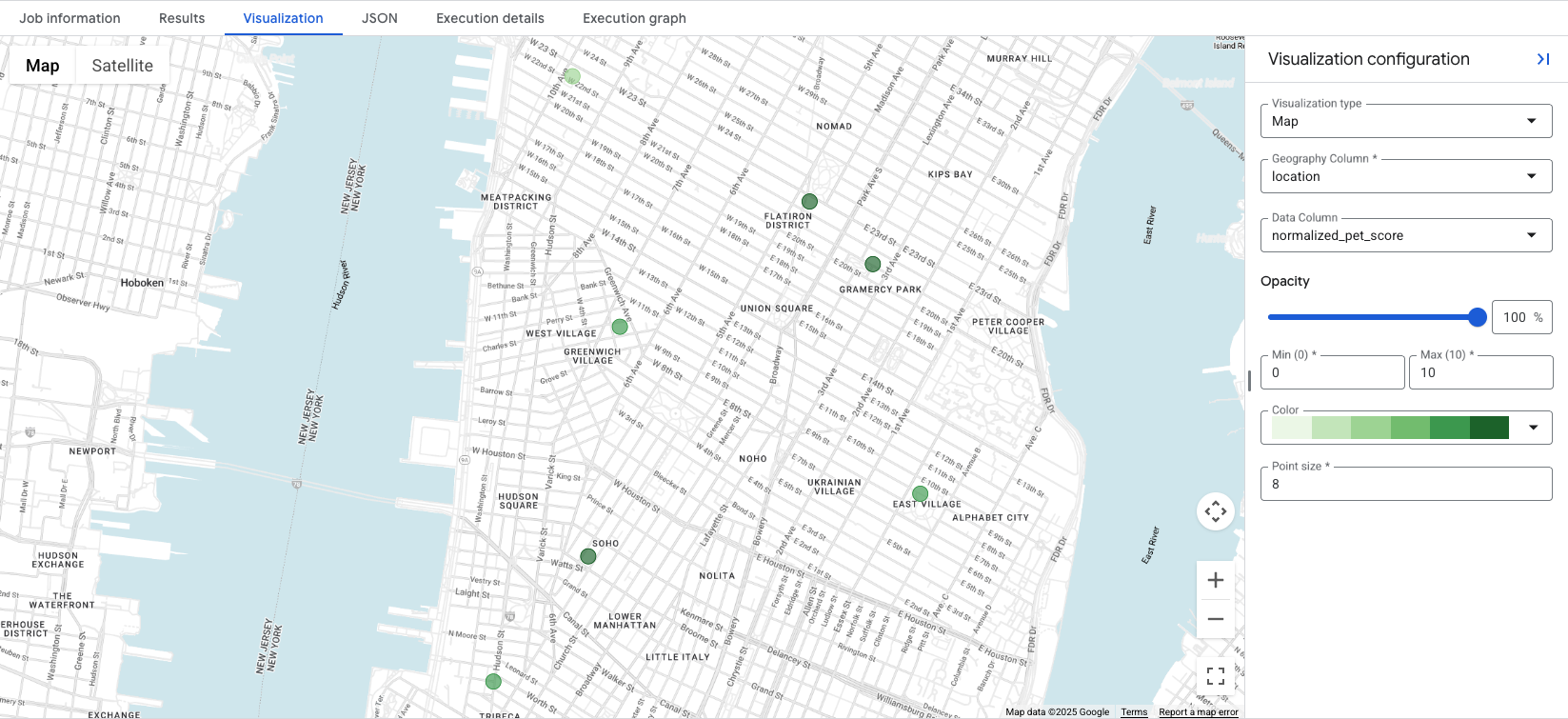
הדמיה של הנתונים מאפשרת לראות במבט חטוף את המיקומים המתאימים ביותר לציון שנוצר, כאשר עיגולים ירוקים כהים יותר מייצגים מיקומים עם normalized_pet_score גבוה יותר, במקרה הזה. אפשרויות נוספות להצגת נתונים של Places Insights מפורטות במאמר בנושא הצגת תוצאות של שאילתות.
סיכום
עכשיו יש לכם מתודולוגיה חזקה וניתנת לשחזור ליצירת ציוני מיקום מדויקים. התחלתם עם המיקומים שלכם, ויצרתם שאילתת SQL אחת ב-BigQuery שמחפשת מקומות קרובים עם ST_DWITHIN, מסננת אותם לפי מאפיינים מתקדמים כמו good_for_children ו-allows_dogs, ומצטברת את התוצאות עם COUNTIF. החלת משקלים מותאמים אישית ונרמול התוצאה מאפשרים ליצור ציון יחיד ונוח לשימוש שמספק תובנות מעמיקות ופרקטיות. אתם יכולים להשתמש בדפוס הזה ישירות כדי להפוך נתוני מיקום גולמיים ליתרון תחרותי משמעותי.
הפעולות הבאות
עכשיו תורך לבנות. במדריך הזה יש תבנית. אתם יכולים להשתמש במידע המגוון שזמין בסכימת Places Insights כדי ליצור את הציונים שהכי נחוצים לתרחיש השימוש שלכם. אפשר גם ליצור את המדדים הבאים:
- "ציון חיי הלילה": אפשר לשלב בין מסננים של
primary_type(bar,night_club),price_levelושעות פתיחה מאוחרות כדי למצוא את האזורים הכי תוססים אחרי רדת החשכה. - 'ציון כושר ובריאות': ספירת
gyms,parksו-health_food_storesבקרבת מקום, וסינון מסעדות לפי אלה עםserves_vegetarian_foodכדי לתת ציון למיקומים עבור משתמשים שמודעים לבריאות. - המדד 'הציון של חלום הנוסע': מאפשר למצוא מיקומים עם צפיפות גבוהה של מקומות
transit_stationוparkingבקרבת מקום, כדי לעזור למשתמשים שחשוב להם שתהיה גישה לתחבורה.
תורמים
Henrik Valve | DevX Engineer