
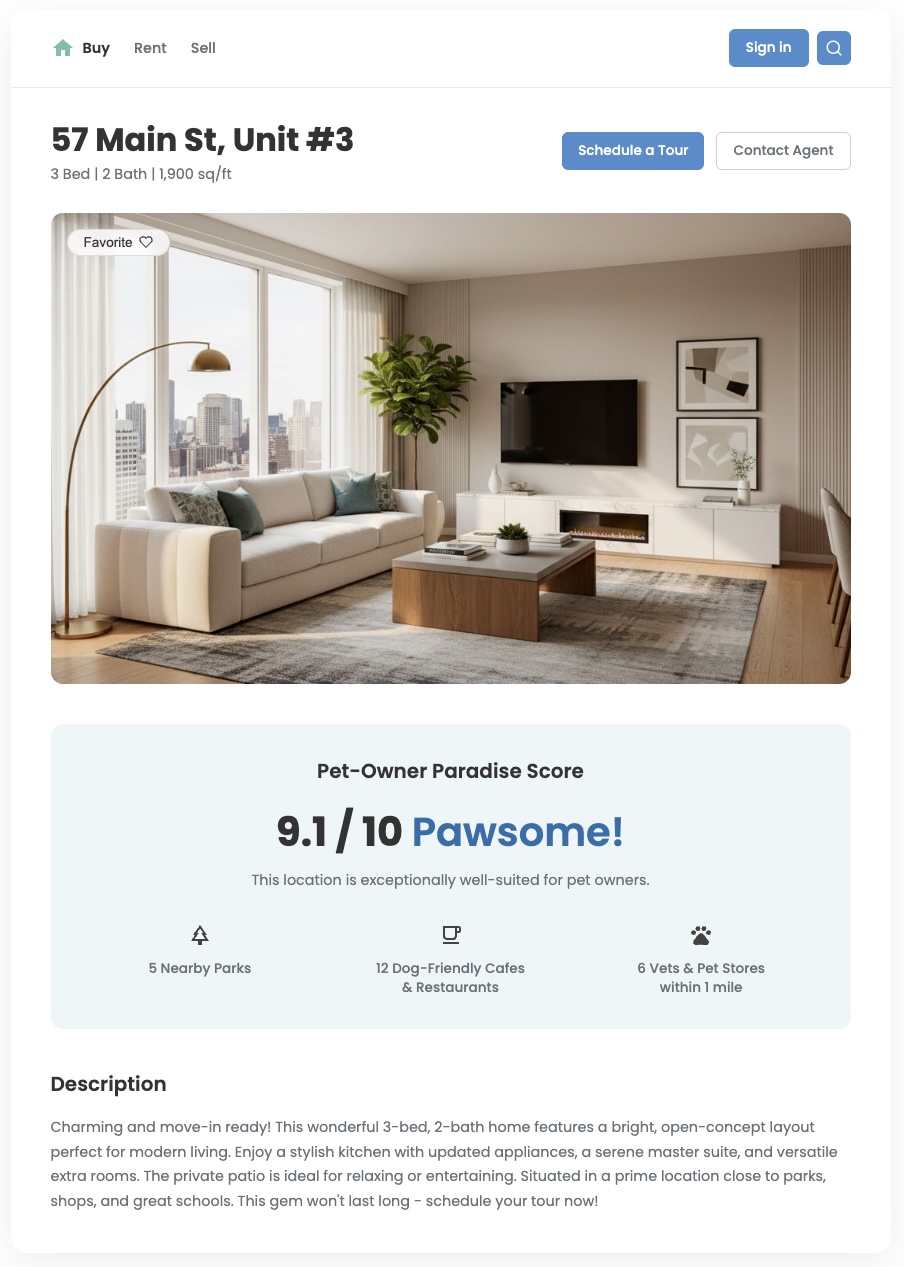
Descripción general
Los datos de ubicación estándar pueden indicarte qué hay cerca, pero, a menudo, no logran responder la pregunta más importante: "¿Qué tan buena es esta área para mí?". Las necesidades de tus usuarios son variadas. Una familia con niños pequeños tiene prioridades diferentes en comparación con un joven profesional con un perro. Para ayudarlos a tomar decisiones seguras, debes proporcionar estadísticas que reflejen estas necesidades específicas. Un nivel de ubicación personalizado es una herramienta poderosa para ofrecer este valor y crear una experiencia del usuario diferenciada y significativa.
En este documento, se describe cómo crear niveles de ubicación personalizados y multifacéticos con el conjunto de datos de Places Insights en BigQuery. Si transformas los datos de PDI en métricas significativas, puedes enriquecer tus aplicaciones de bienes raíces, comercio minorista o viajes, y proporcionar a los usuarios la información pertinente que necesitan. También ofrecemos una opción para usar IA generativa en BigQuery como una forma eficaz de calcular tus niveles de ubicación.
Impulsa el valor comercial con niveles personalizados
En los siguientes ejemplos, se muestra cómo puedes traducir datos de ubicación sin procesar en métricas potentes y centradas en el usuario para mejorar tu aplicación.
- Los desarrolladores de bienes raíces pueden crear un "Nivel de adecuación para familias" o un "Nivel de sueño para viajeros" para ayudar a los compradores y arrendatarios a elegir el vecindario perfecto que se adapte a su estilo de vida, lo que genera una mayor participación de los usuarios, clientes potenciales de mayor calidad y conversiones más rápidas.
- Los ingenieros de viajes y hotelería pueden crear un "Nivel de vida nocturna" o un "Nivel de paraíso para turistas" para ayudar a los viajeros a elegir un hotel que se adapte a su estilo de vacaciones, lo que aumenta las tasas de reserva y la satisfacción del cliente.
- Los analistas de comercio minorista pueden generar un "Nivel de fitness y bienestar" para identificar la ubicación óptima para un gimnasio nuevo o una tienda de alimentos saludables en función de las empresas complementarias cercanas, lo que maximiza el potencial para segmentar el grupo demográfico de usuarios adecuado.
En esta guía, aprenderás una metodología flexible de tres partes para crear cualquier tipo de nivel de ubicación personalizado con datos de Places directamente en BigQuery. Ilustraremos este patrón creando dos niveles de ejemplo distintos: un Nivel de adecuación para familias y un Nivel de paraíso para dueños de mascotas. Este enfoque te permite ir más allá de los recuentos de lugares y aprovechar los atributos detallados y enriquecidos del conjunto de datos de Places Insights. Puedes usar información como el horario de atención, si un lugar es adecuado para niños o si admite perros para crear métricas sofisticadas y significativas para tus usuarios.
Flujo de trabajo de la solución
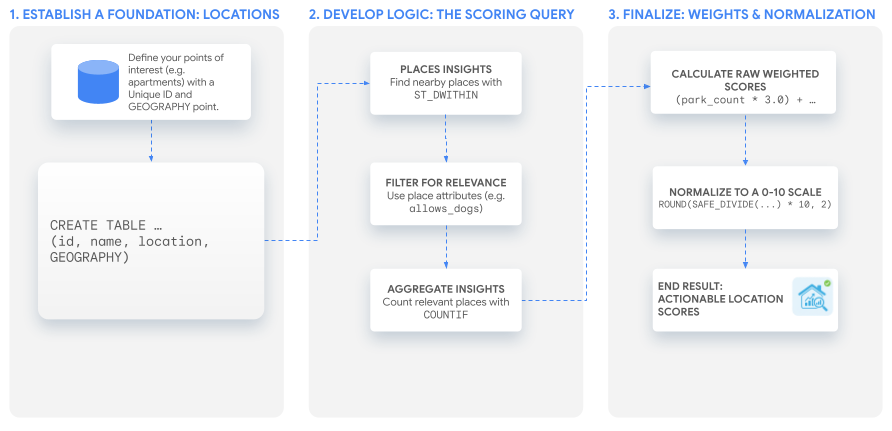
En este instructivo, se usa una sola consulta de SQL potente para crear un nivel personalizado que puedes adaptar a cualquier caso de uso. Te guiaremos por este proceso creando nuestros dos niveles de ejemplo para un conjunto hipotético de anuncios de apartamentos.
Para explorar este flujo de trabajo en un entorno interactivo, ejecuta el siguiente notebook. En él, se muestra cómo usar la
AI.GENERATE función en
BigQuery para crear un nivel de ubicación.
 Ver código fuente en GitHub
Ver código fuente en GitHub
Requisitos previos
Antes de comenzar, sigue estas instrucciones para configurar Places Insights.
1. Establece una base: tus ubicaciones de interés
Antes de crear niveles, necesitas una lista de las ubicaciones que deseas analizar. El primer paso es asegurarte de que estos datos existan como una tabla en BigQuery.
La clave es tener un identificador único para cada ubicación y una columna GEOGRAPHY que almacene sus coordenadas.
Puedes crear y propagar una tabla de ubicaciones para calificar con una consulta como esta:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
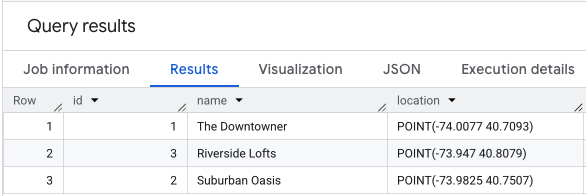
Realizar un SELECT * en tus datos de ubicación se vería de manera similar a lo siguiente.
2. Desarrolla la lógica principal: la consulta de puntuación
Una vez que se establezcan tus ubicaciones, el siguiente paso es encontrar, filtrar y contar los lugares cercanos que son pertinentes para tu nivel personalizado. Todo esto se realiza dentro de una sola instrucción SELECT.
Encuentra lo que está cerca con una búsqueda geoespacial
Primero, debes encontrar todos los lugares del conjunto de datos de Places Insights que se encuentren a una distancia determinada de cada una de tus ubicaciones. La función ST_DWITHIN de BigQuery es perfecta para esto. Realizaremos una JOIN entre nuestra tabla apartment_listings y la tabla places_insights para encontrar todos los lugares dentro de un radio de 800 metros. Una LEFT JOIN garantiza que todas tus ubicaciones originales se incluyan en los resultados, incluso si no se encuentran lugares coincidentes cerca.
Filtra por relevancia con atributos avanzados
Aquí es donde traduces el concepto abstracto de un nivel en filtros de datos concretos. Para nuestros dos niveles de ejemplo, los criterios son diferentes:
- Para el "Nivel de adecuación para familias", nos interesan los parques, los museos y los restaurantes que son explícitamente buenos para los niños.
- Para el "Nivel de paraíso para dueños de mascotas", nos interesan los parques, las clínicas veterinarias, las tiendas de mascotas y cualquier restaurante o cafetería que admita perros.
Puedes filtrar estos atributos específicos directamente en la cláusula WHERE de tu consulta.
Agrega las estadísticas de cada ubicación
Por último, debes contar cuántos lugares pertinentes encontraste para cada apartamento. La cláusula GROUP BY agrega los resultados, y la función COUNTIF cuenta los lugares que coinciden con los criterios específicos de cada uno de nuestros niveles.
En la siguiente consulta, se combinan estos tres pasos y se calculan los recuentos sin procesar de ambos niveles en una sola pasada:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
El resultado de esta consulta será similar al siguiente.
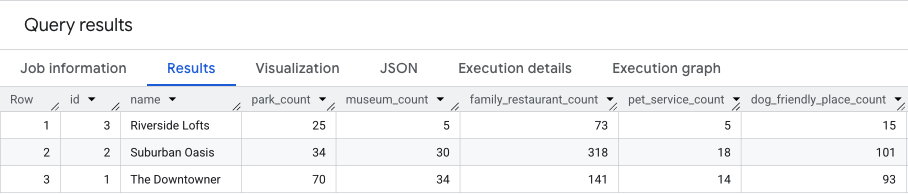
En la siguiente sección, aprovecharemos estos resultados.
3. Crea el nivel
Ahora que tienes el recuento de lugares y la ponderación para cada tipo de lugar de cada ubicación, puedes generar el nivel de ubicación personalizado. En esta sección, analizaremos dos opciones: usar tu propio cálculo personalizado en BigQuery o usar funciones de inteligencia artificial (IA) generativa en BigQuery.
Opción 1: Usa tu propio cálculo personalizado en BigQuery
Los recuentos sin procesar del paso anterior son reveladores, pero el objetivo es obtener un solo nivel fácil de usar. El paso final es combinar estos recuentos con ponderaciones y, luego, normalizar el resultado a una escala de 0 a 10.
Aplica ponderaciones personalizadas Elegir tus ponderaciones es un arte y una ciencia. Deben reflejar las prioridades de tu empresa o lo que crees que es más importante para tus usuarios. Para un nivel de "Adecuación para familias", puedes decidir que un parque es el doble de importante que un museo. Comienza con tus mejores suposiciones y realiza iteraciones en función de los comentarios de los usuarios.
Normaliza el nivel En la siguiente consulta, se usan dos expresiones de tabla común (CTE): la primera calcula los recuentos sin procesar como antes, y la segunda calcula los niveles ponderados. Luego, la instrucción SELECT final realiza una normalización min-max en los niveles ponderados. Se genera la columna location de la tabla apartment_listings de ejemplo para habilitar la visualización de datos en un mapa.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Los resultados de la consulta serán similares a los siguientes. Las últimas dos columnas son los niveles normalizados.

Comprende el nivel normalizado
Es importante comprender por qué este paso final de normalización es tan valioso.
Los niveles ponderados sin procesar pueden variar de 0 a un número potencialmente muy grande, según la densidad urbana de tus ubicaciones. Un nivel de 500 no tiene sentido para un usuario sin contexto.
La normalización transforma estos números abstractos en una clasificación relativa. Si ajustas los resultados de 0 a 10, el nivel comunica claramente cómo se compara cada ubicación con las demás en tu conjunto de datos específico:
- Se asigna un nivel de 10 a la ubicación con el nivel sin procesar más alto, lo que la marca como la mejor opción en el conjunto actual.
- Se asigna un nivel de 0 a la ubicación con el nivel sin procesar más bajo, lo que la convierte en el modelo de referencia para la comparación. Esto no significa que la ubicación no tenga servicios, sino que es la menos adecuada en relación con las otras opciones que se evalúan.
- Todos los demás niveles se encuentran proporcionalmente en el medio, lo que les brinda a los usuarios una forma clara e intuitiva de comparar sus opciones de un vistazo.
Opción 2: Usa la función AI.GENERATE (Gemini)
Como alternativa a usar una fórmula matemática fija, puedes usar la
función AI.GENERATE
de BigQuery
para calcular niveles de ubicación personalizados directamente en tu flujo de trabajo de SQL.
Si bien la opción 1 es excelente para la puntuación puramente cuantitativa basada en recuentos de servicios, no puede tener en cuenta fácilmente los datos cualitativos. La función AI.GENERATE te permite combinar los números de tu consulta de Places Insights con datos no estructurados, como la descripción de texto del anuncio de apartamento (p.ej., "Esta ubicación es adecuada para familias y el área es tranquila por la noche") o las preferencias específicas del perfil de usuario (p.ej., "Este usuario está reservando para una familia y prefiere un área tranquila en una ubicación central"). Esto te permite generar un nivel más matizado que detecta sutilezas que un recuento estricto podría omitir, como una ubicación que tiene una alta densidad de servicios, pero que también se describe como "demasiado ruidosa para los niños".
Construye la instrucción
Para usar esta función, los resultados de la agregación (del paso 2) se formatean en una instrucción de lenguaje natural. Esto se puede hacer de forma dinámica en SQL concatenando columnas de datos con instrucciones para el modelo.
En la siguiente consulta, se combinan insight_counts con la descripción de texto del apartamento para crear una instrucción para cada fila. También se define un perfil de usuario objetivo para guiar la puntuación.
Genera el nivel con SQL
La siguiente consulta realiza toda la operación en BigQuery. Por ejemplo:
- Agrega los recuentos de lugares (como se describe en el paso 2).
- Construye una instrucción para cada ubicación.
- Llama a la función
AI.GENERATEpara analizar la instrucción con el modelo de Gemini. - Analiza el resultado en un formato estructurado listo para usar en tu aplicación.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Comprende la configuración
- Conciencia de los costos: Esta función pasa tu entrada a un modelo de Gemini y genera cargos en Vertex AI cada vez que se llama. Si se analiza una gran cantidad de ubicaciones (p.ej., miles de anuncios de apartamentos), se recomienda filtrar primero el conjunto de datos a los candidatos más pertinentes. Para obtener más detalles sobre cómo minimizar los costos, consulta Prácticas recomendadas.
endpoint: Se especificagemini-flash-latestpara este ejemplo para priorizar la velocidad y la rentabilidad. Sin embargo, puedes elegir el modelo que mejor se adapte a tus necesidades. Consulta la documentación de los modelos de Gemini para experimentar con diferentes versiones (p.ej., Gemini Pro para tareas de razonamiento más complejas) y encontrar la que mejor se adapte a tu caso de uso.output_schema: En lugar de analizar texto sin procesar, se aplica un esquema (FLOAT64para el nivel ySTRINGpara el razonamiento). Esto garantiza que el resultado se pueda usar de inmediato en tu aplicación o herramientas de visualización sin procesamiento posterior.
Resultado de ejemplo
La consulta muestra una tabla estándar de BigQuery con el nivel personalizado y el razonamiento del modelo.
| id | nombre | family_friendliness_score | razonamiento |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | Excelente recuento de servicios (parques, restaurantes), que cumple con las métricas cuantitativas. Sin embargo, los datos cualitativos indican un ruido excesivo los fines de semana y un fuerte enfoque en la vida nocturna, lo que entra en conflicto directamente con la necesidad de tranquilidad del usuario objetivo. |
| 2 | Oasis suburbano | 9.8 | Datos cuantitativos excepcionales combinados con una descripción ("calle tranquila y arbolada") que se alinea perfectamente con el perfil familiar objetivo. Los modificadores positivos altos dan como resultado un nivel casi perfecto. |
Este procedimiento te permite ofrecer una puntuación altamente personalizada que se siente inteligible y adaptada a cada usuario individual, todo dentro de una sola consulta de SQL.
4. Visualiza tus niveles en un mapa
BigQuery Studio incluye una visualización de mapa integrada
para cualquier resultado de la consulta que contenga una columna GEOGRAPHY. Como nuestra consulta genera la columna location, puedes visualizar tus niveles de inmediato.
Si haces clic en la pestaña Visualization, aparecerá el mapa, y el menú desplegable Data Column controla el nivel de ubicación que se visualizará. En este ejemplo, se visualiza el
normalized_pet_score del ejemplo de la opción 1. Ten en cuenta que se agregaron más ubicaciones a la tabla apartment_listings para este ejemplo.
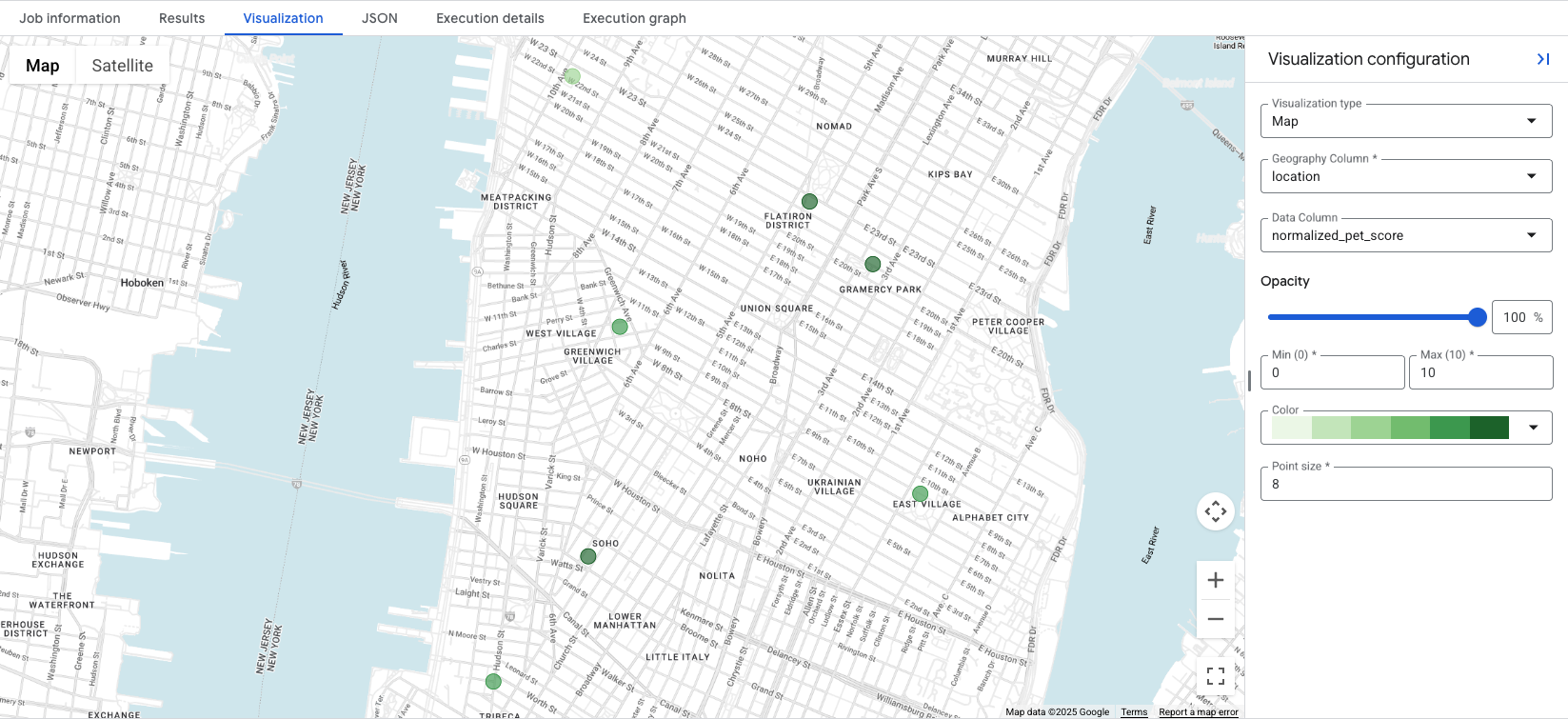
La visualización de los datos revela de un vistazo las ubicaciones más adecuadas para el nivel creado, con círculos verdes más oscuros que representan ubicaciones con un normalized_pet_score más alto, en este caso. Para obtener más opciones de visualización de datos de Places Insights, consulta Visualiza los resultados de la consulta.
Conclusión
Ahora tienes una metodología potente y repetible para crear niveles de ubicación matizados. Comenzando con tus ubicaciones, creaste una sola consulta de SQL en BigQuery que encuentra lugares cercanos con ST_DWITHIN, los filtra por atributos avanzados como good_for_children y allows_dogs, y agrega los resultados con COUNTIF. Si aplicas ponderaciones personalizadas y normalizas el resultado, obtienes un solo nivel fácil de usar que proporciona estadísticas detalladas y prácticas. Puedes aplicar directamente este patrón para transformar los datos de ubicación sin procesar en una ventaja competitiva significativa.
Próximas acciones
Ahora es tu turno de crear. En este instructivo, se proporciona una plantilla. Puedes usar los datos enriquecidos disponibles en el esquema de Places Insights para crear los niveles que sean más necesarios para tu caso de uso. Considera estos otros niveles que podrías crear:
- "Nivel de vida nocturna": Combina filtros para
primary_type(bar,night_club),price_levely el horario de apertura nocturno para encontrar las áreas más vibrantes después del anochecer. - "Nivel de fitness y bienestar": Cuenta los
gyms,parksyhealth_food_storescercanos, y filtra los restaurantes por aquellos conserves_vegetarian_foodpara calificar las ubicaciones para los usuarios preocupados por la salud. - "Nivel de sueño para viajeros": Encuentra ubicaciones con una alta densidad de lugares
transit_stationyparkingcercanos para ayudar a los usuarios que valoran el acceso al transporte.
Colaboradores
Henrik Valve | DevX Ingeniero