

為什麼在人力、庫存和營運做法一致的情況下,一個網站蓬勃發展,另一個網站卻表現不佳?如果商家有多個地點,往往難以解釋投資組合中成效差異的原因。答案通常隱藏在外部環境中。運用興趣點 (POI) 資料,我們就能擺脫軼事說明,準確量化當地競爭密度和社區特徵如何決定網站的成功。
本指南說明如何使用 Places Insights 和 BigQuery ML,量化當地環境對網站成功率的影響。您將結合專屬網站效能資料與外部地理空間信號,診斷效能驅動因素。
我們將使用倫敦的網站資料集,建構線性迴歸模型。這個工作流程會使用 H3 空間索引,將城市劃分為大小一致的六邊形格狀單元。將環境資料匯總到這些儲存格中,即可訓練模型來預測城市中任何社區的成效潛力,而不僅限於現有網站。
您將學會:
- 工程師功能:彙整您網站 500 公尺半徑內的搜尋點 (POI) 數量,例如健身房、學校和轉運站。
- 訓練模型:使用 BigQuery ML 建立迴歸模型,將這些環境特徵與內部成效指標建立關聯。
- 為城市評分:將訓練好的模型套用至倫敦的整個 H3 格線,找出未來擴展的高潛力熱點。
如果您是 BigQuery ML 新手,請參閱「BigQuery ML 簡介」,瞭解核心概念和支援的模型類型。
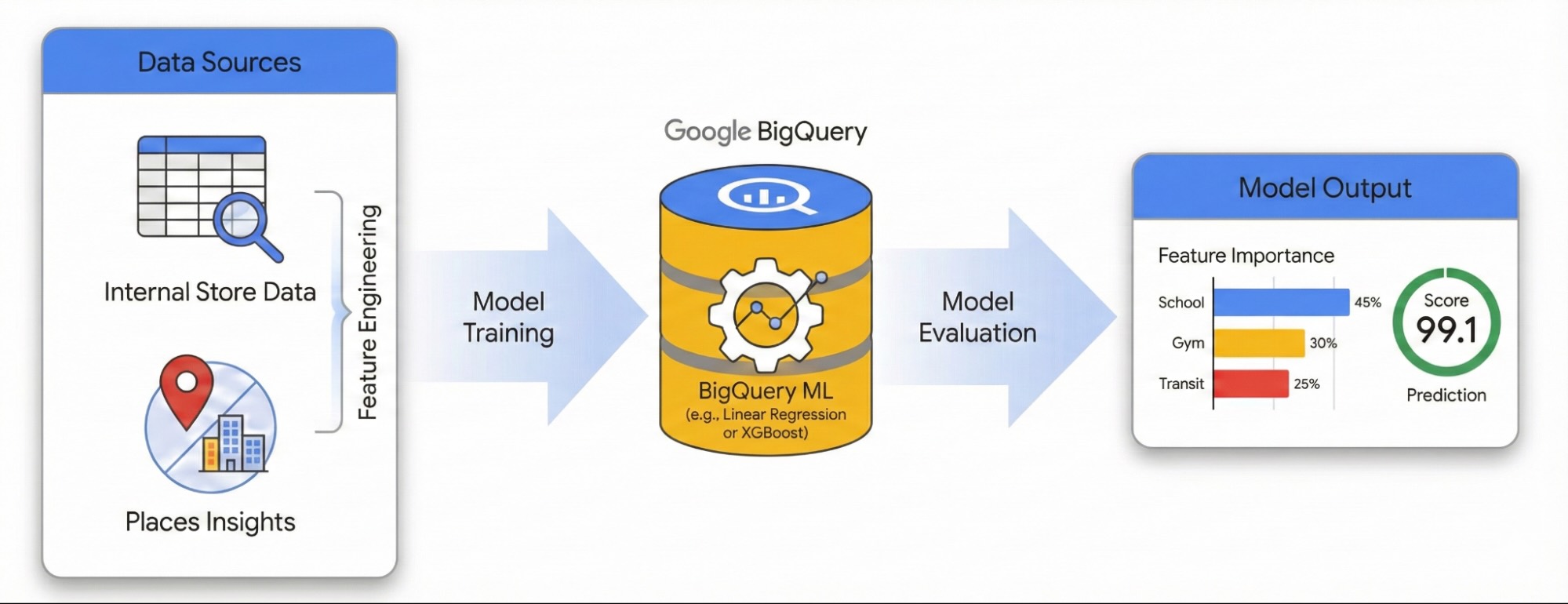
如要在互動式環境中探索這個工作流程,請執行下列筆記本。並示範如何使用 BigQuery ML 建構預測模型,以及如何運用 H3 空間索引建立全市商機的視覺化資料。
 在 GitHub 上查看來源
在 GitHub 上查看來源
必要條件
開始之前,請確認您具備以下項目:
Google Cloud 專案:
- 已啟用計費功能的 Google Cloud 專案。
資料存取權:
- BigQuery 中的Places Insights 訂閱項目。
- 您自己的網站位置表格,其中包含成效指標 (例如收益)。範例資料集位於教學課程資源中。
Google Maps Platform:
- API 金鑰。
- 金鑰已啟用下列 API:
Python 環境和程式庫:
- Python 環境,例如 Google Cloud 控制台中的 Colab Enterprise。
- 已安裝下列程式庫:
媒體庫 說明 pandas-gbq與 BigQuery 互動。 geopandas處理地理空間資料作業。 folium建立互動式地圖。 shapely幾何操作。
IAM 權限:
- 確認使用者或服務帳戶具備下列 IAM 角色:
角色 ID BigQuery 資料編輯者 roles/bigquery.dataEditorBigQuery 使用者 roles/bigquery.user
- 確認使用者或服務帳戶具備下列 IAM 角色:
費用提醒:
- 本教學課程使用 Google Cloud 的計費元件,請注意下列相關的潛在費用:
- BigQuery ML:系統會根據使用的運算單元收費。請參閱 BigQuery ML 定價。
- Places Insights:根據查詢用量計費。
- 本教學課程使用 Google Cloud 的計費元件,請注意下列相關的潛在費用:
運用 Places 洞察進行特徵工程
如要找出影響網站效能的外部因素,您必須將原始興趣點資料轉換為可量化的特徵。您將計算每個地點 500 公尺半徑範圍內特定設施或地點類型 (例如健身房、學校和轉運站) 的密度。選取的設施取決於你認為最適合自家業務的項目。
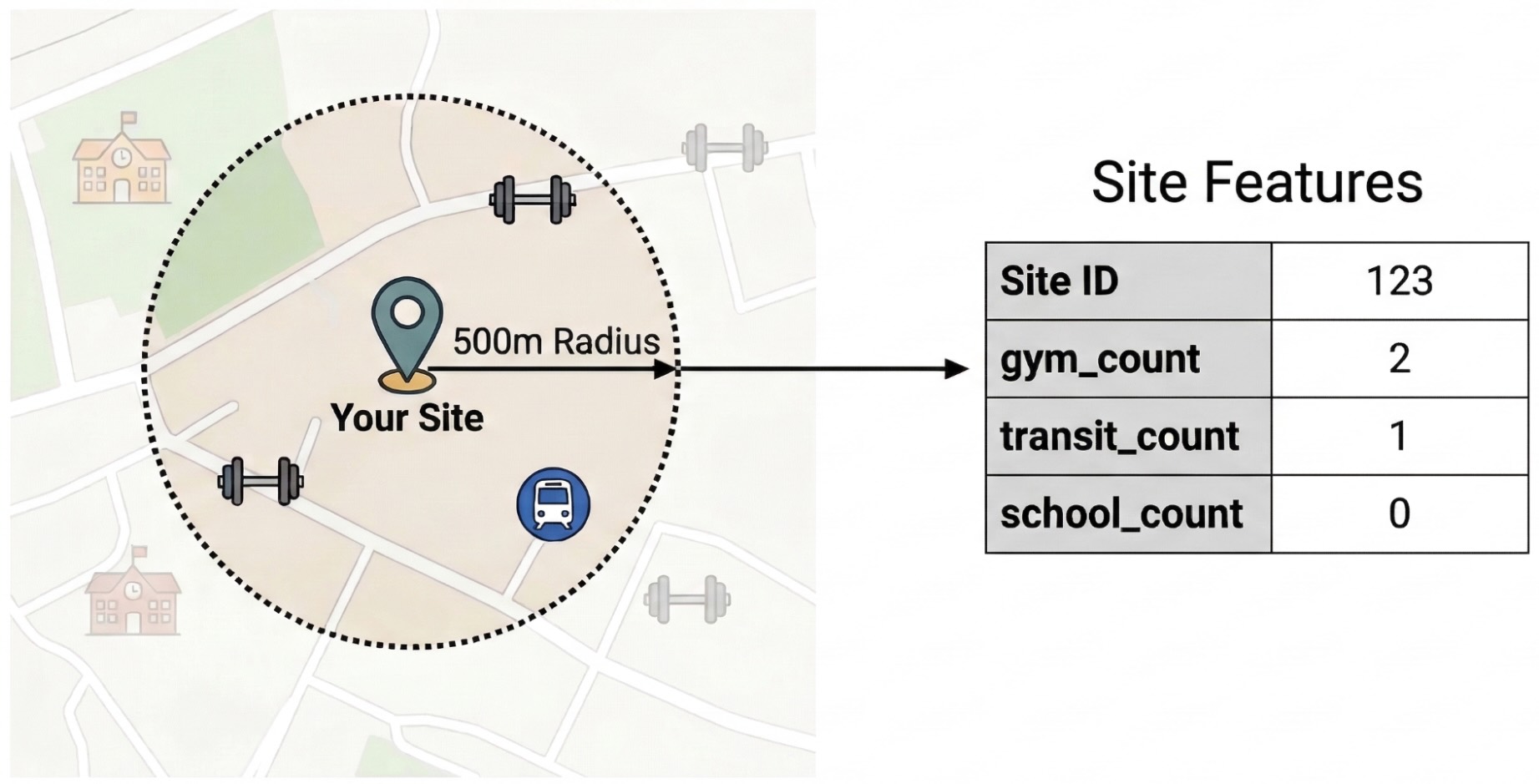
我們將使用 Python 和 pandas-gbq 程式庫執行這個步驟。這個方法可讓您執行 SELECT WITH AGGREGATION_THRESHOLD 查詢 (存取 Places Insights 資料集時必須執行這項查詢),並將結果儲存在專案的新資料表中。如要進一步瞭解如何使用 Places Insights 資料,請參閱「直接查詢資料集」。
執行特徵工程查詢
在環境中執行下列 Python 指令碼 (例如 Colab Enterprise)。這項指令碼會將內部網站資料與 Places Insights 資料集連結。
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
瞭解查詢
ST_DWITHIN:這項地理空間函式會在每個地點位置周圍建立 500 公尺的緩衝區,並找出該半徑內的所有 Places Insights 資料點。COUNTIF:這項函式會計算每個地點的特定地點類型密度 (例如「健身房」、「學校」)。這些計數會成為機器學習模型的輸入特徵 (X)。pandas_gbq.to_gbq:這個函式會將查詢結果儲存到新資料表 (site_features)。這個永久性資料表會做為 BigQuery ML 模型的乾淨訓練資料集。
如要瞭解更進階的實際應用,請考慮計算多個距離 (例如 250 公尺、500 公尺、1 公里) 的特徵,並探索其他 Places Insights 屬性,例如 rating、price_level 或 regular_opening_hours。如需 Places Insights 屬性的完整清單,請參閱支援的地點類型和核心結構定義參考資料。
使用 BigQuery ML 訓練模型
現在,您可以使用 site_features 資料表中的工程化特徵,訓練線性迴歸模型。
這個模型會學習各項環境特徵 (X) 的最佳權重 (β),藉此預測網站效能 (Y)。
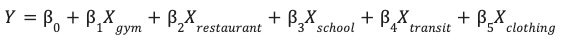
使用穩健的縮放功能處理離群值
地理空間資料通常包含極端離群值,可能會扭曲標準線性模型。舉例來說,倫敦西區的某個地點方圓 500 公尺內可能有 200 間餐廳,而郊區的地點只有 2 間。如果您使用標準縮放 (平均值/標準差),離群值 (200) 會使分配偏斜,並強制模型優先調整該極端值。
為解決這個問題,我們在模型定義中使用了 Robust Scaling (ML.ROBUST_SCALER)。這項技術會根據中位數和四分位數間距 (IQR) 調整特徵,讓模型能夠抵禦離群值,並確保模型從網站的典型分布情況中學習。
建立模型
在 BigQuery 中執行下列 SQL 查詢,即可建立及訓練模型。
我們使用
TRANSFORM
子句,對所有輸入特徵套用強大的縮放功能。我們也設定了 optimize_strategy = 'NORMAL_EQUATION',因為這是相對較小資料集 (例如一般商店位置組合) 最有效率的訓練方法。最後,我們會篩除成效優異的離群值 (store_performance <
75),讓模型專注於預測一般成長模式。
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
評估模型效能
如要信任模型提供的網站效能影響因素洞察資料,請務必先驗證預測結果是否準確。
訓練完成後,請使用 ML.EVALUATE 函式,根據訓練期間未使用的「保留」資料集,評估模型的預測結果。
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
查看 R2 分數 (r2_score) 和平均絕對誤差 (mean_absolute_error),判斷模型是否已準備好投入生產:
- R 平方分數會評估外部環境因素 (附近的興趣點) 實際說明瞭多少的成效變異數。R2 分數為 0.70 表示網站 70% 的成功與當地環境有關。越接近 1.0,表示環境設施與網站效能的關聯性越強。
- 平均絕對誤差會顯示平均誤差 (以點數為單位)。舉例來說,MAE 為 1.5 表示模型的預測結果通常與實際成效分數相差 +/- 1.5 分。
排解分數偏低的問題
如果 R2 分數偏低,請考慮進行下列改善:
- 擴展地圖項目類型:在查詢中新增不同的地點類型 (例如
tourist_attraction、subway_station)。 - 調整集水區半徑:變更
ST_DWITHIN距離。500 公尺的半徑對咖啡店來說可能太廣,但對家具店來說可能太小。 - 增加資料大小:請確保訓練的商店位置數量足夠,可找出具統計顯著性的模式。
使用 H3 空間索引為城市評分
我們使用 H3 空間索引將倫敦市劃分為六邊形單元格的統一網格 (解析度 8,約 0.7 平方公里)。將 Places Insights 資料匯總到這些單元格後,我們就能將訓練好的模型套用至每個社區,找出符合您頂尖網站環境特徵的高潛力區域。
執行開發潛在客戶查詢
如要產生這個格線,我們使用 Places Insights 資料集提供的 PLACES_COUNT_PER_H3 函式 (進一步瞭解如何使用地點計數函式查詢 Places Insights)。這項函式可在單一作業中,計算 H3 格狀儲存格的興趣點數量。
執行下列 SQL 查詢,在單一執行作業中完成三個步驟:
- H3 索引和計數:我們使用 JSON 設定物件呼叫
PLACES_COUNT_PER_H3,找出倫敦市中心方圓 25 公里內的所有營業地點。我們會針對每種設施類型 (健身房、學校等) 分別查詢,並使用UNION ALL合併。 - 樞紐分析 (特徵工程):由於機器學習模型會預期有不同的特徵欄 (例如
gym_count和restaurant_count),因此我們會將儲存格分組,並使用條件式匯總(SUM(IF(...)))將資料透視為正確的結構定義。 - 預測:我們會將這些透視格線特徵直接饋送至
ML.PREDICT函式,為每個鄰近地區產生效能分數。
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
解讀結果
查詢會傳回資料表,其中每個資料列代表倫敦的六邊形區域。
h3_index:六邊形格子的專屬 ID。predicted_store_performance:根據周遭環境,模型估算這個儲存格內網站的分數。h3_geography:儲存格的多邊形幾何圖形,我們會在下一個步驟中用於視覺化。
值越高,表示該區域的學校、健身房和大眾運輸密度,越符合現有最成功地點周圍的模式。
查看開發潛在客戶地圖
如要將資料轉化為行動,請在地圖上以視覺化方式呈現結果。表格輸出內容提供原始分數,但地圖會顯示高潛力空間的叢集和走廊,這些資訊在清單中並不顯眼。
在隨附的筆記本中,我們會使用 geopandas 程式庫剖析 H3 多邊形幾何,並使用 folium 算繪互動式地圖。
結果會顯示 choropleth 地圖,每個六邊形格子的顏色會根據預測分數而有所不同。
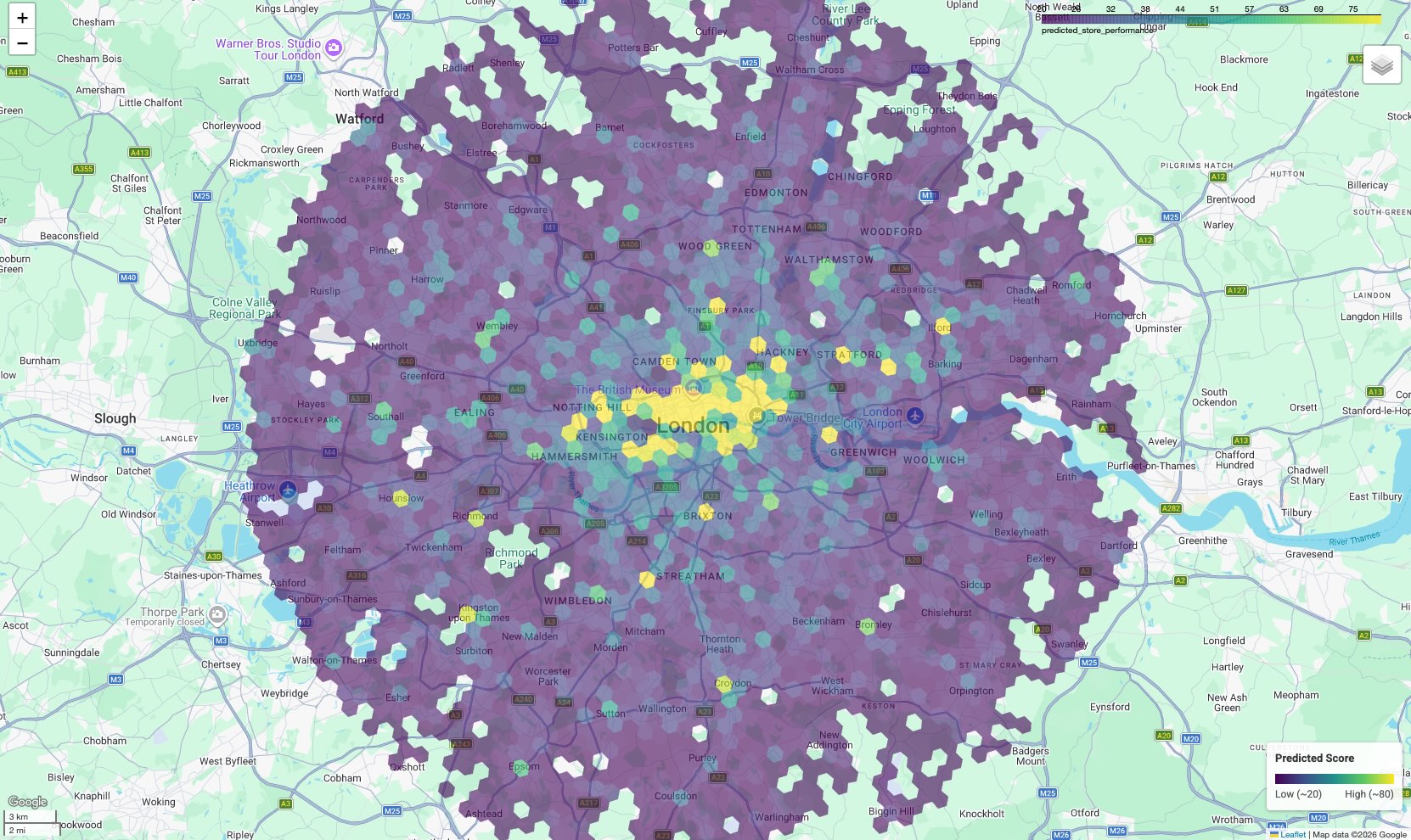
解讀地圖:
- 熱點 (黃色/綠色):這些區域的預測成效分數較高。這些地點的學校、健身房和交通運輸設施密度最理想,與您成功的地點相關。這些是新選址的主要候選地點。
- 冷區 (紫色):這些區域缺乏頂尖商家附近提供的支援環境功能。
- 互動式檢查:在筆記本環境中,您可以將游標懸停在任何儲存格上,查看促成該特定分數的設施具體數量 (例如「健身房:12」)。
結論
您已成功將內部營運資料與 Places Insights 合併,診斷網站效能。透過分析模型權重,您找出與現有指標相關的特定鄰里特徵。您使用 H3 空間索引,將這項分析從數百個地點擴展到倫敦數千個潛在社區。
後續動作
- 擴展特徵工程:在查詢中新增更具體的地點類型,找出吸引來店人潮的小眾因素。
- 探索進階模型:雖然線性迴歸可提供清楚的可解釋性,但請嘗試使用 BigQuery ML 中的
BOOSTED_TREE_REGRESSOR,並搭配適當的交叉驗證策略,擷取非線性關係。 - 將地圖投入運作:使用 Maps JavaScript API 將 H3 格線結果匯出至自訂資訊主頁,與團隊分享這些洞察資料。
貢獻者
- Henrik Valve | 開發人員體驗工程師
- Gennadii Donchyts | 客戶工程師