

Tại sao một trang web phát triển mạnh mẽ trong khi một trang web khác hoạt động kém hiệu quả mặc dù có nhân sự, kho hàng và quy trình hoạt động nhất quán? Các doanh nghiệp có nhiều địa điểm thường gặp khó khăn trong việc giải thích sự khác biệt về hiệu suất này trong danh mục của họ. Câu trả lời thường nằm ẩn trong môi trường bên ngoài. Bằng cách tận dụng dữ liệu về địa điểm yêu thích (POI), chúng ta có thể vượt ra ngoài những lời giải thích mang tính giai thoại và định lượng chính xác mức độ cạnh tranh tại địa phương cũng như các đặc điểm của khu vực xung quanh quyết định sự thành công của một địa điểm.
Hướng dẫn này minh hoạ cách định lượng tác động của môi trường xung quanh tại địa phương đối với sự thành công của trang web bằng cách sử dụng Thông tin chi tiết về địa điểm và BigQuery ML. Bạn sẽ kết hợp dữ liệu hiệu suất trang web thuộc quyền sở hữu riêng với các tín hiệu không gian địa lý bên ngoài để chẩn đoán các yếu tố thúc đẩy hiệu suất.
Chúng ta sẽ sử dụng một tập dữ liệu về các trang web ở London để xây dựng mô hình Hồi quy tuyến tính. Quy trình làm việc này sử dụng tính năng Lập chỉ mục không gian H3, hệ thống này chia thành phố thành các ô hình lục giác đồng nhất. Bằng cách tổng hợp dữ liệu môi trường vào các ô này, bạn có thể huấn luyện một mô hình để dự đoán tiềm năng hiệu suất của bất kỳ khu vực lân cận nào trong thành phố, không chỉ các địa điểm hiện có của bạn.
Bạn sẽ học được cách:
- Thiết kế các tính năng: Tổng hợp số lượng Địa điểm yêu thích (POI) như phòng tập thể dục, trường học và trạm trung chuyển trong bán kính 500 mét tính từ các trang web của bạn.
- Huấn luyện mô hình: Sử dụng BigQuery ML để xây dựng mô hình hồi quy tương quan các tính năng môi trường này với các chỉ số hiệu suất nội bộ.
- Chấm điểm thành phố: Áp dụng mô hình đã huấn luyện cho toàn bộ lưới H3 của London để xác định các điểm nóng có tiềm năng cao cho việc mở rộng trong tương lai.
Nếu bạn mới sử dụng BigQuery ML, hãy xem bài viết Giới thiệu về BigQuery ML để tìm hiểu về các khái niệm cốt lõi và các loại mô hình được hỗ trợ.
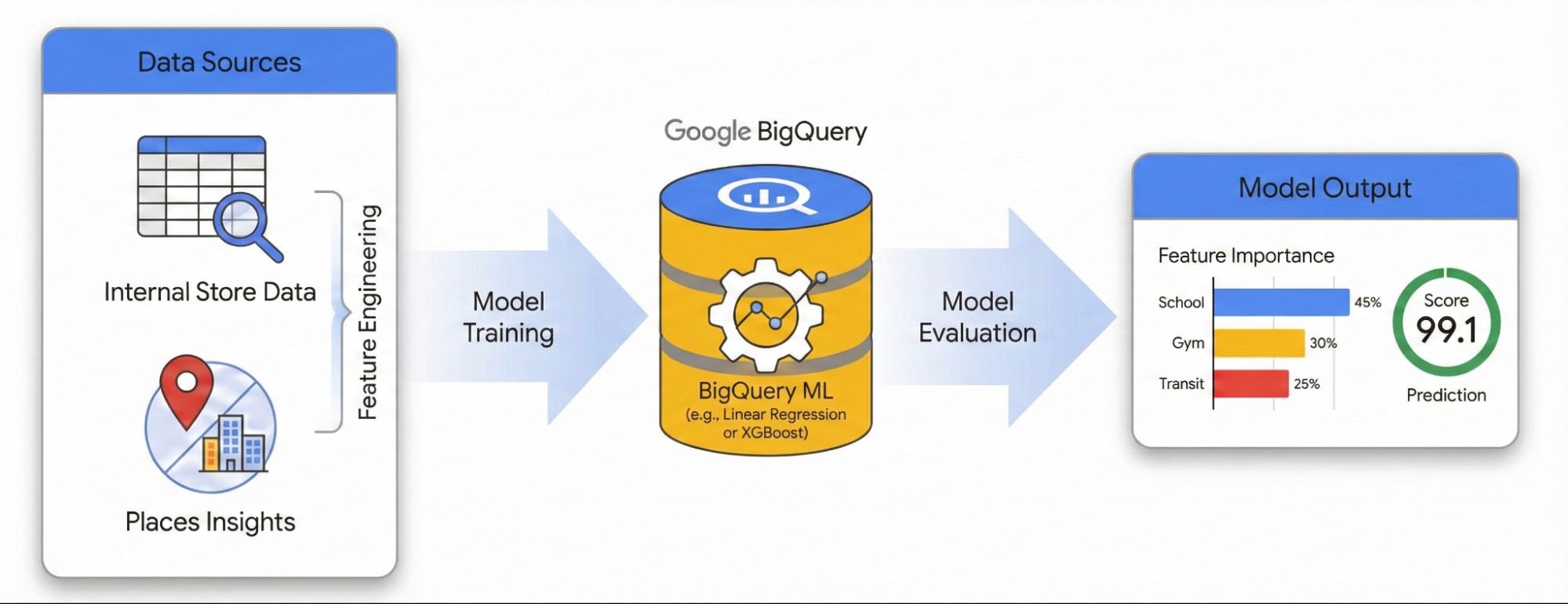
Để khám phá quy trình làm việc này trong một môi trường tương tác, hãy chạy sổ tay sau. Sổ tay này minh hoạ cách xây dựng mô hình dự đoán bằng BigQuery ML và trực quan hoá các cơ hội trên toàn thành phố bằng cách sử dụng tính năng lập chỉ mục không gian H3.
 Xem nguồn trên GitHub
Xem nguồn trên GitHub
Điều kiện tiên quyết
Trước khi bắt đầu, hãy đảm bảo bạn có những điều sau:
Dự án trên Google Cloud:
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
Quyền truy cập vào dữ liệu:
- Gói thuê bao Thông tin chi tiết về địa điểm trong BigQuery.
- Bảng vị trí trang web của riêng bạn có một chỉ số hiệu suất (ví dụ: doanh thu). Một tập dữ liệu mẫu nằm trong tài nguyên hướng dẫn.
Google Maps Platform:
- Một khoá API.
- Các API sau đây được bật cho khoá của bạn:
Môi trường và thư viện Python:
- Một môi trường Python như Colab Enterprise trong Google Cloud Console.
- Các thư viện sau đây đã được cài đặt:
Thư viện Mô tả pandas-gbqTương tác với BigQuery. geopandasXử lý các thao tác dữ liệu không gian địa lý. foliumTạo bản đồ tương tác. shapelyThao tác hình học.
Quyền IAM:
- Đảm bảo người dùng hoặc tài khoản dịch vụ của bạn có các vai trò IAM
sau đây:
Vai trò ID Người chỉnh sửa dữ liệu BigQuery roles/bigquery.dataEditorNgười dùng BigQuery roles/bigquery.user
- Đảm bảo người dùng hoặc tài khoản dịch vụ của bạn có các vai trò IAM
sau đây:
Nhận biết chi phí:
- Hướng dẫn này sử dụng các thành phần có tính phí của Google Cloud. Hãy lưu ý đến các chi phí tiềm ẩn liên quan đến:
- BigQuery ML: Tính phí cho các khoảng trống tính toán đã sử dụng. Xem giá BigQuery ML.
- Thông tin chi tiết về địa điểm: Tính phí dựa trên mức sử dụng truy vấn.
- Hướng dẫn này sử dụng các thành phần có tính phí của Google Cloud. Hãy lưu ý đến các chi phí tiềm ẩn liên quan đến:
Thiết kế tính năng bằng Thông tin chi tiết về địa điểm
Để tách biệt các yếu tố bên ngoài thúc đẩy hiệu suất trang web, bạn phải chuyển đổi dữ liệu POI thô thành các tính năng có thể định lượng. Bạn sẽ tính toán mật độ của các tiện nghi hoặc loại địa điểm cụ thể như phòng tập thể dục, trường học và trạm trung chuyển trong bán kính 500 mét tính từ mỗi trang web. Các tiện nghi mà bạn chọn sẽ tuỳ thuộc vào những gì bạn tin là phù hợp nhất cho doanh nghiệp của mình.
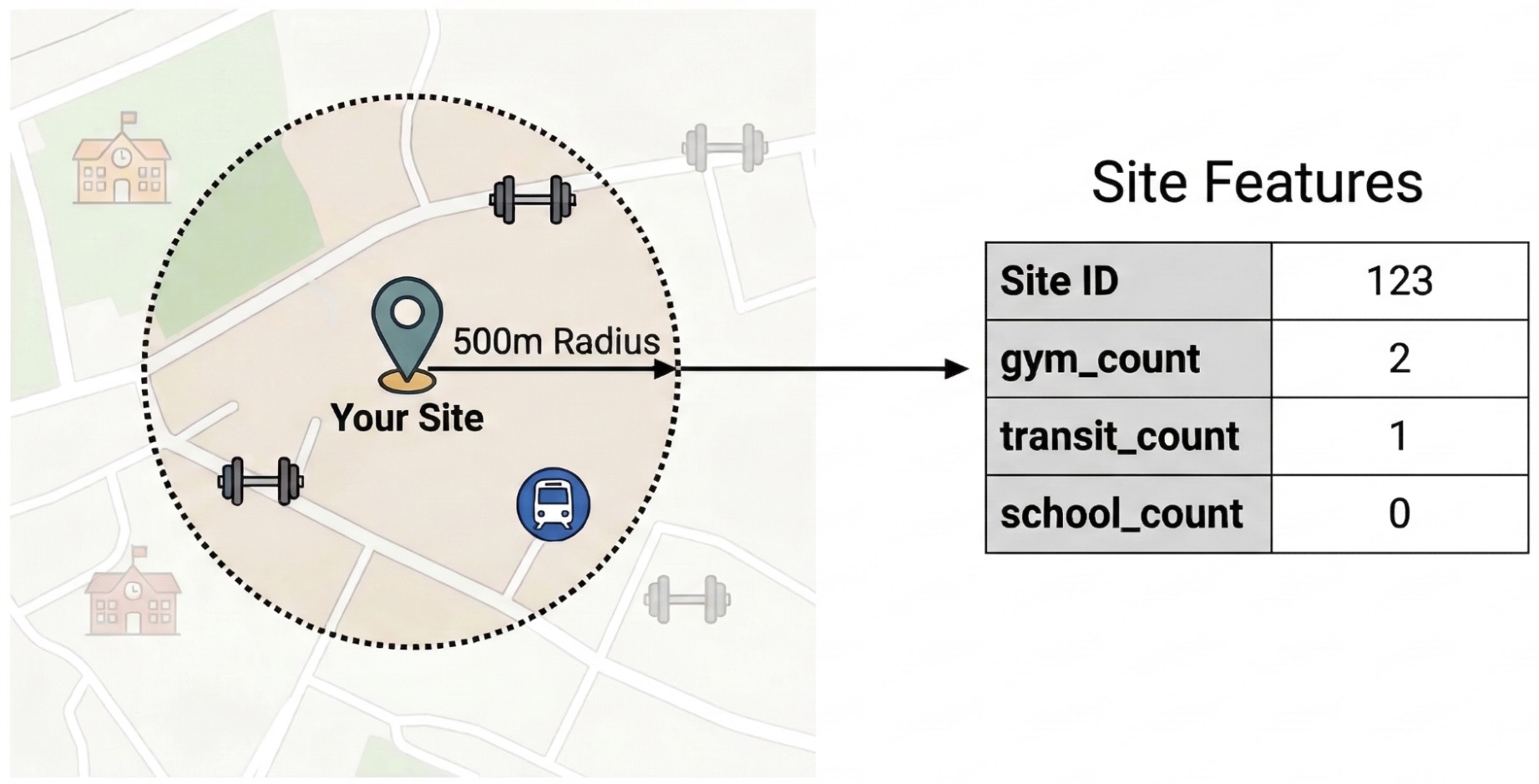
Chúng tôi sử dụng Python và thư viện pandas-gbq cho bước này. Phương pháp này cho phép bạn thực thi truy vấn SELECT WITH AGGREGATION_THRESHOLD, truy vấn này là bắt buộc để truy cập vào tập dữ liệu Thông tin chi tiết về địa điểm và lưu kết quả vào một bảng mới trong dự án của bạn. Xem bài viết Truy vấn trực tiếp tập dữ liệu
để biết thêm thông tin về cách làm việc với dữ liệu Thông tin chi tiết về địa điểm.
Chạy truy vấn thiết kế tính năng
Chạy tập lệnh Python sau trong môi trường của bạn (ví dụ: Colab Enterprise). Tập lệnh này kết nối dữ liệu trang web nội bộ của bạn với tập dữ liệu Thông tin chi tiết về địa điểm.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Tìm hiểu truy vấn
ST_DWITHIN: Hàm không gian địa lý này tạo vùng đệm 500 mét xung quanh mỗi vị trí trang web và xác định tất cả các điểm Thông tin chi tiết về địa điểm nằm trong bán kính đó.COUNTIF: Hàm này tính toán mật độ của các loại địa điểm cụ thể (ví dụ: "gym", "school") cho mỗi trang web. Các số lượng này trở thành các tính năng đầu vào (X) cho mô hình học máy.pandas_gbq.to_gbq: Hàm này duy trì kết quả truy vấn vào một bảng mới (site_features). Bảng vĩnh viễn này đóng vai trò là tập dữ liệu huấn luyện sạch cho mô hình BigQuery ML.
Đối với các ứng dụng thực tế nâng cao hơn, hãy cân nhắc tính toán các tính năng ở nhiều khoảng cách (ví dụ: 250m, 500m, 1km) và khám phá các thuộc tính Thông tin chi tiết về địa điểm khác như rating, price_level hoặc regular_opening_hours. Xem
các loại địa điểm được hỗ trợ và
tài liệu tham khảo về giản đồ cốt lõi
để biết danh sách đầy đủ các thuộc tính Thông tin chi tiết về địa điểm.
Huấn luyện mô hình bằng BigQuery ML
Sau khi lưu các tính năng được thiết kế trong bảng site_features, giờ đây, bạn có thể
huấn luyện mô hình Hồi quy
tuyến tính.
Mô hình này tìm hiểu các trọng số tối ưu (β) cho từng tính năng môi trường (X) để dự đoán hiệu suất của trang web (Y).
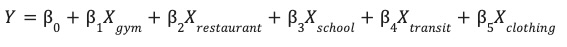
Xử lý điểm ngoại lai bằng tính năng chuyển tỉ lệ mạnh mẽ
Dữ liệu không gian địa lý thường chứa các điểm ngoại lệ cực đoan có thể làm sai lệch các mô hình tuyến tính tiêu chuẩn. Ví dụ: một địa điểm ở West End của London có thể có 200 nhà hàng trong vòng 500 mét, trong khi một địa điểm ở vùng ngoại ô chỉ có 2 nhà hàng. Nếu bạn sử dụng tính năng chuyển tỉ lệ tiêu chuẩn (Giá trị trung bình/Độ lệch chuẩn), điểm ngoại lai (200) sẽ làm sai lệch phân phối và buộc mô hình ưu tiên khớp với giá trị cực đoan đó.
Để giải quyết vấn đề này, chúng tôi sử dụng Chuyển tỉ lệ mạnh mẽ
(ML.ROBUST_SCALER) trong định nghĩa mô hình. Kỹ thuật này điều chỉnh các tính năng dựa trên Giá trị trung vị và Khoảng tứ phân vị (IQR), giúp mô hình có khả năng phục hồi trước các điểm ngoại lai và đảm bảo mô hình học được từ phân phối điển hình của các trang web của bạn.
Tạo mô hình
Chạy truy vấn SQL sau trong BigQuery để tạo và huấn luyện mô hình.
Chúng tôi sử dụng mệnh đề
TRANSFORM
để áp dụng tính năng chuyển tỉ lệ mạnh mẽ cho tất cả các tính năng thông tin đầu vào. Chúng tôi cũng đặt
optimize_strategy = 'NORMAL_EQUATION' vì đây là phương pháp huấn luyện hiệu quả nhất
cho các tập dữ liệu tương đối nhỏ, chẳng hạn như danh mục đầu tư điển hình về vị trí cửa hàng. Cuối cùng, chúng tôi lọc ra các điểm ngoại lai có hiệu quả cao (store_performance <
75) để tập trung mô hình vào việc dự đoán các mô hình tăng trưởng điển hình.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Đánh giá hiệu suất mô hình
Trước khi có thể tin tưởng vào thông tin chi tiết của mô hình về những yếu tố thúc đẩy hiệu suất trang web, bạn phải xác minh rằng các dự đoán của mô hình là chính xác.
Sau khi huấn luyện, hãy sử dụng hàm ML.EVALUATE để đánh giá các dự đoán của mô hình dựa trên một tập dữ liệu "giữ lại" không được sử dụng trong quá trình huấn luyện.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Kiểm tra Điểm R2 (r2_score) và Lỗi tuyệt đối Trung bình (mean_absolute_error) để xác định xem mô hình của bạn đã sẵn sàng cho quá trình sản xuất hay chưa:
- Điểm R2 đo lường mức độ biến động hiệu suất thực sự được giải thích bởi các yếu tố môi trường bên ngoài (địa điểm yêu thích gần đó). Điểm R2 là 0,70 có nghĩa là 70% sự thành công của một địa điểm gắn liền với môi trường địa phương. Điểm R2 càng gần 1, 0 thì mối tương quan giữa các tiện nghi môi trường và hiệu suất trang web càng mạnh.
- MAE cho biết lỗi trung bình tính bằng điểm. Ví dụ: MAE là 1,5 có nghĩa là các dự đoán của mô hình thường nằm trong khoảng +/- 1,5 điểm so với điểm hiệu suất thực tế.
Khắc phục sự cố điểm số thấp
Nếu điểm R2 của bạn thấp, hãy cân nhắc những cải tiến sau:
- Mở rộng các loại tính năng: Thêm các Loại địa điểm
khác vào truy vấn của bạn (ví dụ:
tourist_attraction,subway_station). - Điều chỉnh bán kính thu hút: Thay đổi khoảng cách
ST_DWITHIN. Bán kính 500 mét có thể quá rộng đối với một quán cà phê nhưng lại quá nhỏ đối với một cửa hàng nội thất. - Tăng kích thước dữ liệu: Đảm bảo bạn đang huấn luyện trên đủ số lượng vị trí cửa hàng để tìm thấy một mô hình có ý nghĩa thống kê.
Chấm điểm thành phố bằng tính năng Lập chỉ mục không gian H3
Chúng tôi sử dụng tính năng Lập chỉ mục không gian H3 để chia thành phố London thành một lưới đồng nhất gồm các ô hình lục giác (Độ phân giải 8, khoảng 0,7 km²). Bằng cách tổng hợp dữ liệu Thông tin chi tiết về địa điểm vào các ô này, chúng tôi có thể áp dụng mô hình đã huấn luyện cho mọi khu vực lân cận, xác định các khu vực có tiềm năng cao khớp với hồ sơ môi trường của các trang web hoạt động hiệu quả nhất.
Chạy truy vấn thăm dò
Để tạo lưới này, chúng tôi sử dụng
PLACES_COUNT_PER_H3
hàm do tập dữ liệu Thông tin chi tiết về địa điểm cung cấp (Tìm hiểu thêm về cách truy vấn
Thông tin chi tiết về địa điểm bằng các hàm Đếm địa điểm).
Hàm này tính toán số lượng POI cho các ô lưới H3 trong một thao tác.
Chạy truy vấn SQL sau để thực hiện 3 bước trong một lần thực thi:
- Lập chỉ mục và đếm H3: Chúng tôi gọi
PLACES_COUNT_PER_H3bằng đối tượng cấu hình JSON để tìm tất cả các địa điểm đang hoạt động trong bán kính 25 km tính từ trung tâm London. Chúng tôi truy vấn riêng biệt cho từng loại tiện nghi (phòng tập thể dục, trường học, v.v.) và kết hợp chúng bằng cách sử dụngUNION ALL. - Xoay vòng (Kỹ thuật trích xuất tính chất): Vì mô hình học máy của chúng tôi mong đợi các nhóm tính chất riêng biệt (như
gym_countvàrestaurant_count), nên chúng tôi nhóm các ô và sử dụng tính năng tổng hợp có điều kiện(SUM(IF(...)))để xoay vòng dữ liệu thành giản đồ chính xác. - Dự đoán: Chúng tôi đưa trực tiếp các tính năng lưới đã xoay vòng này vào hàm
ML.PREDICTđể tạo điểm hiệu suất cho mọi khu vực lân cận.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Diễn giải kết quả
Truy vấn này trả về một bảng trong đó mỗi hàng đại diện cho một khu vực hình lục giác ở London.
h3_index: Giá trị nhận dạng duy nhất cho ô hình lục giác.predicted_store_performance: Điểm số ước tính của mô hình cho một địa điểm nằm trong ô này, chỉ dựa trên môi trường xung quanh.h3_geography: Hình học đa giác của ô mà chúng ta sẽ sử dụng để trực quan hoá trong bước tiếp theo.
Giá trị cao cho biết các khu vực có mật độ trường học, phòng tập thể dục và phương tiện công cộng khớp với các mô hình được tìm thấy xung quanh các trang web hiện có hoạt động hiệu quả nhất của bạn.
Trực quan hoá bản đồ thăm dò
Để biến dữ liệu thành thông tin hữu ích, hãy trực quan hoá kết quả trên bản đồ. Mặc dù đầu ra dạng bảng cung cấp điểm số thô, nhưng bản đồ sẽ hiển thị các cụm không gian và hành lang có tiềm năng cao mà không hiển thị rõ ràng trong danh sách.
Trong sổ tay đi kèm, chúng tôi sử dụng thư viện geopandas để phân tích cú pháp hình học đa giác H3 và folium để hiển thị bản đồ tương tác.
Kết quả là bản đồ chuyên đề, trong đó mỗi ô hình lục giác được tô màu theo điểm số dự đoán.
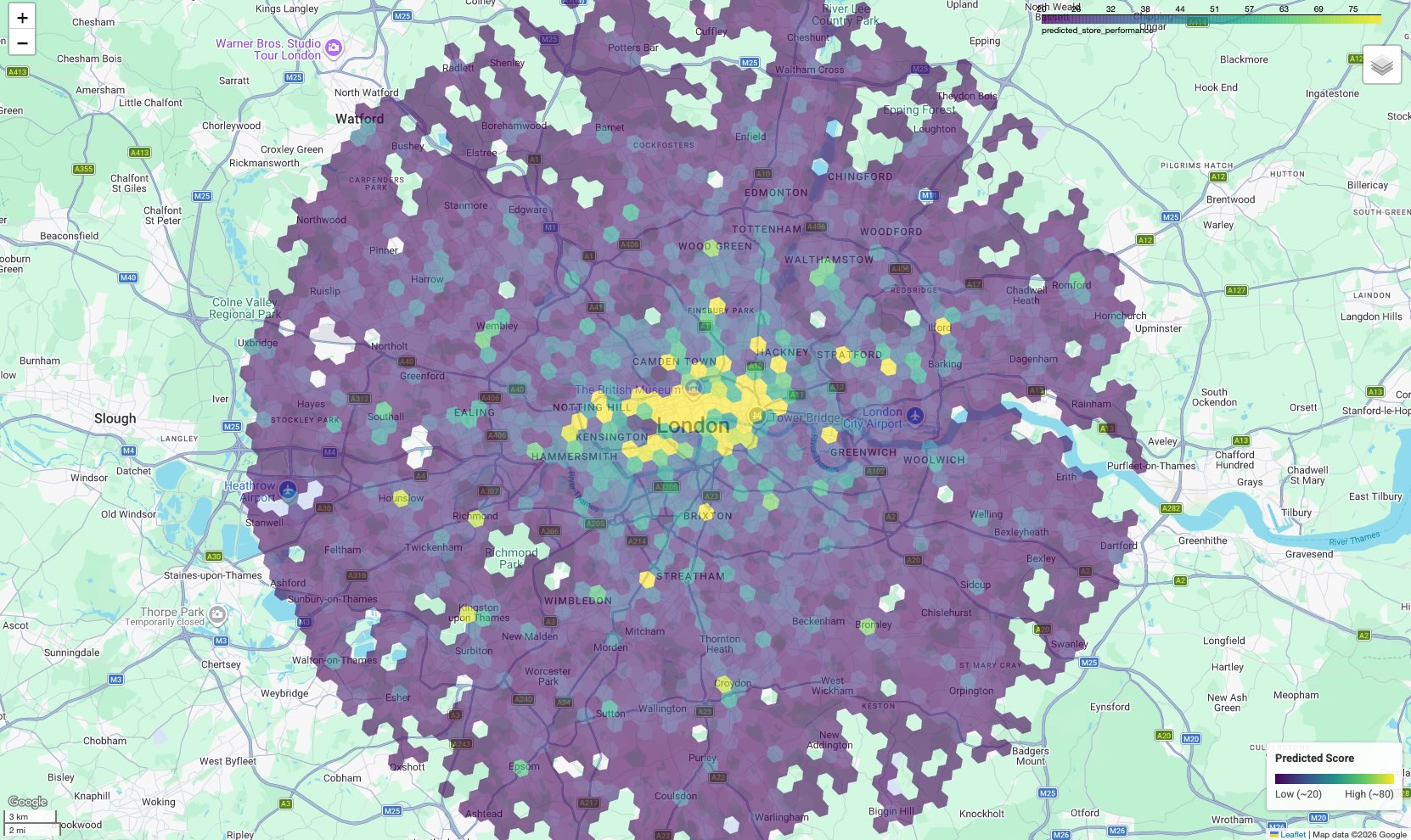
Diễn giải bản đồ:
- Điểm nóng (Màu vàng/Màu xanh lục): Các khu vực này có điểm số dự đoán hiệu suất cao. Chúng có mật độ tối ưu về trường học, phòng tập thể dục và phương tiện công cộng tương quan với các trang web thành công của bạn. Đây là những ứng cử viên hàng đầu cho việc lựa chọn trang web mới.
- Điểm lạnh (Màu tím): Các khu vực này thiếu các tính năng môi trường hỗ trợ được tìm thấy gần những trang web hoạt động hiệu quả nhất của bạn.
- Kiểm tra tương tác: Trong môi trường sổ tay, bạn có thể di chuột qua bất kỳ ô nào để xem số lượng tiện nghi cụ thể (ví dụ: "Phòng tập thể dục: 12") đã đóng góp vào điểm số cụ thể đó.
Kết luận
Bạn đã kết hợp thành công dữ liệu hoạt động nội bộ với Thông tin chi tiết về địa điểm để chẩn đoán hiệu suất trang web. Bằng cách phân tích trọng số mô hình, bạn đã xác định được các đặc điểm cụ thể của khu vực lân cận tương quan với các chỉ số hiện có. Sử dụng tính năng lập chỉ mục không gian H3, bạn đã mở rộng phân tích này từ vài trăm địa điểm lên hàng nghìn khu vực lân cận tiềm năng trên khắp London.
Các bước tiếp theo
- Mở rộng thiết kế tính năng: Thêm các Loại địa điểm cụ thể hơn vào truy vấn của bạn để nắm bắt các yếu tố thúc đẩy lưu lượng người ghé thăm cửa hàng thực tế.
- Khám phá các mô hình nâng cao: Mặc dù Hồi quy tuyến tính cung cấp khả năng giải thích rõ ràng, hãy thử nghiệm
BOOSTED_TREE_REGRESSORtrong BigQuery ML kết hợp với chiến lược xác thực chéo phù hợp để nắm bắt các mối quan hệ phi tuyến tính. - Vận hành bản đồ: Xuất kết quả lưới H3 sang bảng điều khiển tuỳ chỉnh bằng cách sử dụng Maps JavaScript API để chia sẻ thông tin chi tiết này với nhóm của bạn.
Người đóng góp
- Henrik Valve | Kỹ sư DevX
- Gennadii Donchyts | Kỹ sư khách hàng cấp cao