

Почему один объект процветает, а другой показывает низкие результаты, несмотря на стабильный штат сотрудников, запасы и операционные методы? Компании с несколькими филиалами часто испытывают трудности с объяснением этой разницы в показателях эффективности по всему портфелю. Ответ обычно кроется во внешней среде. Используя данные о достопримечательностях (POI), мы можем выйти за рамки отдельных объяснений и точно количественно оценить, как плотность конкуренции на местном уровне и характеристики района определяют успех объекта.
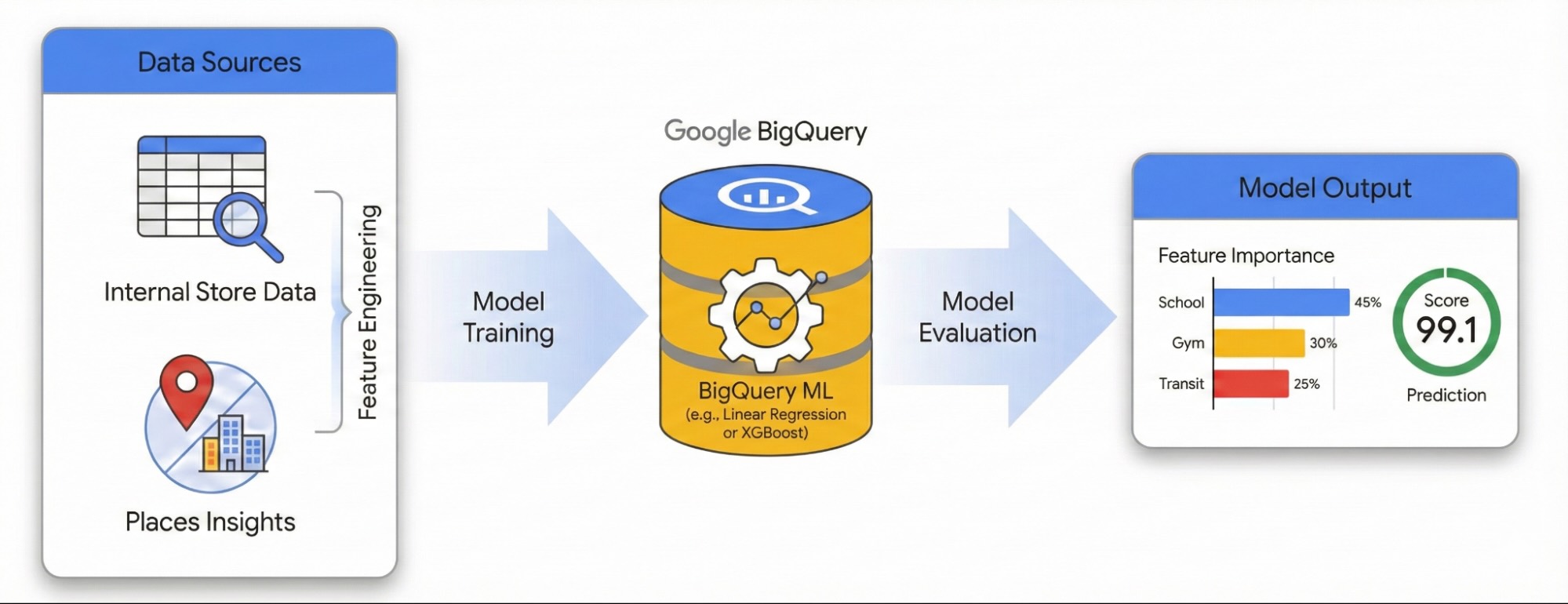
В этом руководстве показано, как количественно оценить влияние окружающей среды на успешность сайта с помощью Places Insights и BigQuery ML . Вы объедините собственные данные о производительности сайта с внешними геопространственными сигналами для выявления факторов, влияющих на производительность.
Для построения модели линейной регрессии мы будем использовать набор данных по объектам в Лондоне. В этом рабочем процессе используется пространственная индексация H3 , которая делит город на однородные шестиугольные ячейки. Агрегируя данные об окружающей среде в эти ячейки, можно обучить модель прогнозировать потенциал производительности любого района города, а не только существующих объектов.
Вы научитесь:
- Функции инженера: Подсчет общего количества объектов, представляющих интерес (POI), таких как спортивные залы, школы и станции общественного транспорта, в радиусе 500 метров от ваших объектов.
- Обучение модели: Используйте BigQuery ML для построения регрессионной модели, которая сопоставляет эти характеристики окружающей среды с вашими внутренними показателями производительности.
- Оценка города: Примените обученную модель ко всей сетке H3 Лондона, чтобы выявить перспективные места для будущего развития.
Если вы новичок в BigQuery ML, ознакомьтесь с разделом «Введение в BigQuery ML» , чтобы узнать об основных концепциях и поддерживаемых типах моделей.
Чтобы изучить этот рабочий процесс в интерактивной среде, запустите следующий блокнот. Он демонстрирует, как построить прогностическую модель с помощью BigQuery ML и визуализировать возможности в масштабах всего города, используя пространственную индексацию H3.
 Посмотреть исходный код на GitHub
Посмотреть исходный код на GitHubПредварительные требования
Прежде чем начать, убедитесь, что у вас есть следующее:
Проект Google Cloud:
- Проект Google Cloud с включенной функцией выставления счетов.
Доступ к данным:
- Подписка Places Insights в BigQuery.
- Ваша собственная таблица местоположений сайтов с показателем эффективности (например, доход). Пример набора данных приведен в учебных материалах .
Платформа Google Maps:
- Ключ API .
- Для вашего ключа активированы следующие API:
Среда разработки и библиотеки Python:
- Для работы необходима среда Python, например, Colab Enterprise в консоли Google Cloud.
- Установлены следующие библиотеки:
Библиотека Описание pandas-gbqВзаимодействие с BigQuery. geopandasОбработка геопространственных данных. foliumСоздание интерактивных карт. shapelyГеометрические преобразования.
Разрешения IAM:
- Убедитесь, что у вашей учетной записи пользователя или службы есть следующие роли IAM :
Роль ИДЕНТИФИКАТОР Редактор данных BigQuery roles/bigquery.dataEditorПользователь BigQuery roles/bigquery.user
- Убедитесь, что у вашей учетной записи пользователя или службы есть следующие роли IAM :
Информирование о затратах:
- В этом руководстве используются платные компоненты Google Cloud. Обратите внимание на возможные затраты, связанные с:
- BigQuery ML: плата взимается за использованные вычислительные ресурсы. См. цены на BigQuery ML .
- Places Insights: Оплата производится в зависимости от количества запросов.
- В этом руководстве используются платные компоненты Google Cloud. Обратите внимание на возможные затраты, связанные с:
Разработка функциональных областей с помощью Places Insights
Чтобы выделить внешние факторы, влияющие на эффективность работы объекта, необходимо преобразовать исходные данные о POI в количественно измеримые характеристики. Вы рассчитаете плотность конкретных объектов или типов мест, таких как спортивные залы, школы и транспортные станции, в радиусе 500 метров от каждого объекта. Выбор объектов будет зависеть от того, что, по вашему мнению, наиболее важно для вашего бизнеса.
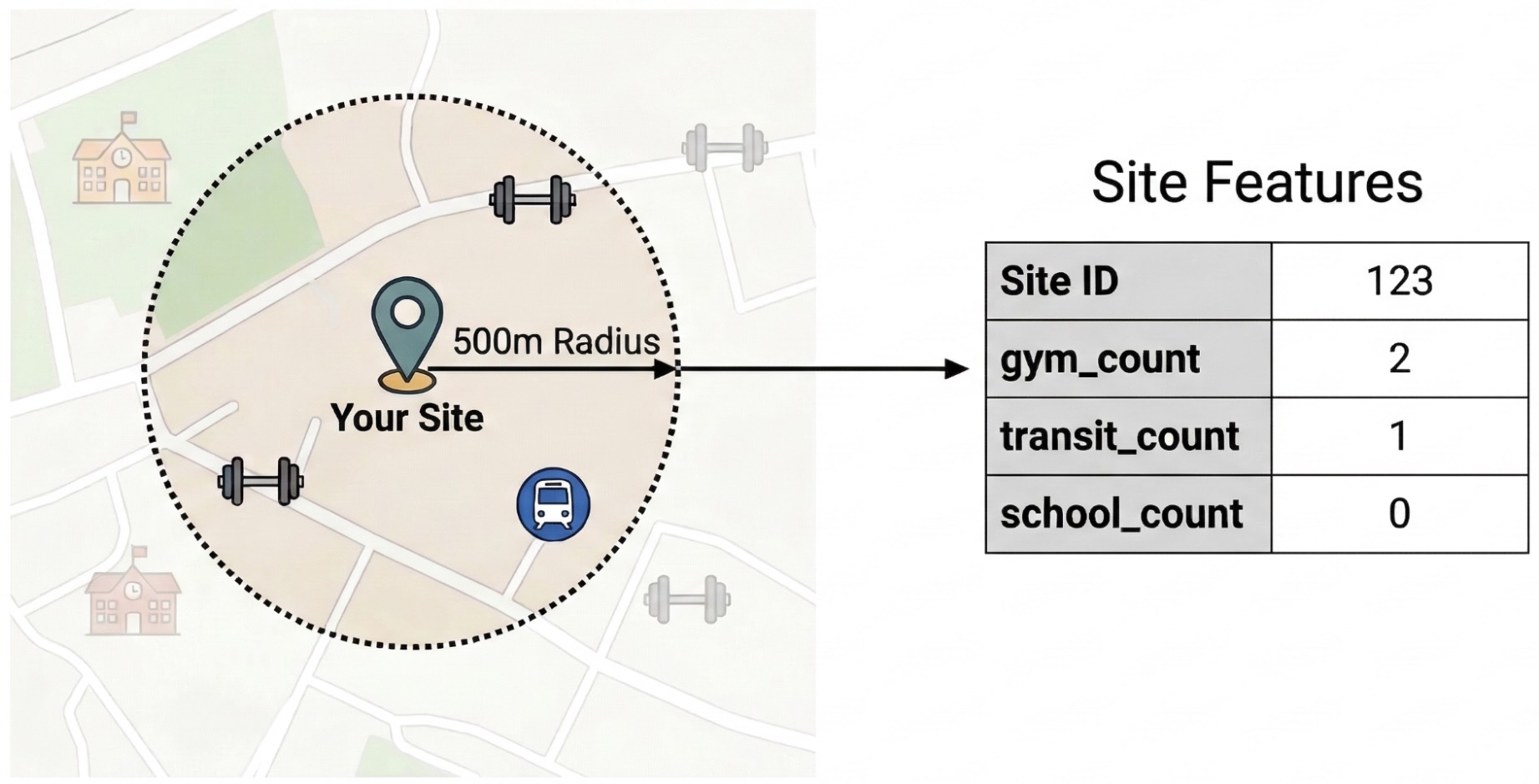
Для этого шага мы используем Python и библиотеку pandas-gbq . Такой подход позволяет выполнить запрос SELECT WITH AGGREGATION_THRESHOLD , необходимый для доступа к набору данных Places Insights, и сохранить результаты в новую таблицу в вашем проекте. Дополнительную информацию о работе с данными Places Insights см. в разделе «Запрос к набору данных напрямую» .
Выполните запрос инженерии признаков.
Запустите следующий скрипт Python в вашей среде (например, Colab Enterprise ). Этот скрипт связывает данные вашего внутреннего сайта с набором данных Places Insights.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Разберитесь в запросе.
-
ST_DWITHIN: Эта геопространственная функция создает буфер в 500 метров вокруг каждого местоположения объекта и определяет все точки Places Insights, попадающие в этот радиус. -
COUNTIF: Эта функция вычисляет плотность определенных типов мест (например, «спортзал», «школа») для каждого объекта. Эти значения становятся входными признаками ( X ) для модели машинного обучения. -
pandas_gbq.to_gbq: Эта функция сохраняет результаты запроса в новую таблицу (site_features). Эта постоянная таблица служит чистым обучающим набором данных для модели машинного обучения BigQuery.
Для более сложных практических задач рассмотрите возможность расчета параметров на разных расстояниях (например, 250 м, 500 м, 1 км) и изучите другие атрибуты Places Insights, такие как rating , price_level или regular_opening_hours . Полный список поддерживаемых типов мест и справочник по основной схеме см. в соответствующем разделе.
Обучите модель с помощью BigQuery ML
Сохранив параметры, заданные инженерами, в таблице site_features , вы можете обучить модель линейной регрессии .
Эта модель обучается определять оптимальные веса ( β ) для каждой характеристики окружающей среды ( X ), чтобы прогнозировать производительность вашего сайта ( Y ).
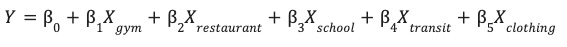
Обработка выбросов с помощью надежного масштабирования
Геопространственные данные часто содержат экстремальные выбросы, которые могут искажать стандартные линейные модели. Например, в районе Вест-Энда в Лондоне может находиться 200 ресторанов в радиусе 500 метров, в то время как в пригороде — всего 2. Если использовать стандартное масштабирование (среднее значение/стандартное отклонение), выброс (200) искажает распределение и заставляет модель отдавать приоритет подгонке именно этого экстремального значения.
Для решения этой проблемы мы используем робастное масштабирование ( ML.ROBUST_SCALER ) в определении модели. Этот метод масштабирует признаки на основе медианы и межквартильного размаха (IQR), что делает модель устойчивой к выбросам и гарантирует, что она обучается на основе типичного распределения ваших сайтов.
Создайте модель
Выполните следующий SQL-запрос в BigQuery, чтобы создать и обучить модель.
Мы используем оператор TRANSFORM для применения робастного масштабирования ко всем входным признакам. Мы также устанавливаем optimize_strategy = 'NORMAL_EQUATION' , поскольку это наиболее эффективный метод обучения для относительно небольших наборов данных, таких как типичный портфель местоположений магазинов. Наконец, мы отфильтровываем высокоэффективные выбросы ( store_performance < 75 ), чтобы сфокусировать модель на прогнозировании типичных моделей роста.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Оцените производительность модели.
Прежде чем доверять выводам модели о факторах, влияющих на производительность сайта, необходимо убедиться в точности ее прогнозов.
После обучения используйте функцию ML.EVALUATE для оценки точности прогнозов модели на «контрольном» наборе данных, который не использовался во время обучения.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Проверьте показатель R2 ( r2_score ) и среднюю абсолютную ошибку ( mean_absolute_error ), чтобы определить, готова ли ваша модель к использованию в производстве:
- Показатель R2 измеряет, какая часть дисперсии производительности фактически объясняется внешними факторами окружающей среды (близлежащими объектами интереса). Показатель R2, равный 0,70, означает, что 70% успеха объекта связано с местной окружающей средой. Чем ближе к 1,0, тем сильнее корреляция между благоприятной окружающей средой и производительностью объекта.
- Показатель MAE отражает среднюю ошибку в баллах. Например, значение MAE, равное 1,5, означает, что прогнозы модели обычно находятся в пределах +/- 1,5 балла от фактического показателя эффективности.
Устранение неполадок, связанных с низкими результатами.
Если ваш показатель R2 низкий, рассмотрите следующие варианты улучшения:
- Разверните раздел «Типы объектов»: добавьте в запрос различные типы мест (например,
tourist_attraction,subway_station»). - Настройте радиус охвата: измените расстояние
ST_DWITHIN. Радиус в 500 метров может быть слишком широким для кофейни, но слишком маленьким для мебельного магазина. - Увеличьте объем данных: убедитесь, что вы проводите обучение на достаточном количестве торговых точек, чтобы выявить статистически значимую закономерность.
Оцените город с помощью пространственной индексации H3.
Мы используем пространственное индексирование H3 для разделения города Лондона на равномерную сетку шестиугольных ячеек (разрешение 8, приблизительно 0,7 км²). Агрегируя данные Places Insights в эти ячейки, мы можем применить нашу обученную модель к каждому району, выявляя перспективные территории, соответствующие экологическому профилю ваших наиболее эффективных участков.
Выполните запрос для поиска потенциальных клиентов.
Для создания этой сетки мы используем функцию PLACES_COUNT_PER_H3 , предоставляемую набором данных Places Insights (подробнее о запросах к Places Insights с использованием функций Places Count ). Эта функция вычисляет количество точек интереса (POI) для ячеек сетки H3 за одну операцию.
Выполните следующий SQL-запрос, чтобы запустить три шага за один раз:
- Индексирование и подсчет H3: Мы вызываем функцию
PLACES_COUNT_PER_H3, используя объект конфигурации JSON, чтобы найти все действующие объекты в радиусе 25 км от центра Лондона. Мы выполняем отдельный запрос для каждого типа объектов (спортзалы, школы и т. д.) и объединяем результаты с помощьюUNION ALL. - Преобразование данных в нужную схему (инженерное проектирование признаков): Поскольку наша модель машинного обучения ожидает наличия различных столбцов признаков (например,
gym_countиrestaurant_count), мы группируем ячейки и используем условную агрегацию(SUM(IF(...)))для преобразования данных в правильную схему. - Прогнозирование: Мы передаем эти характеристики опорной сетки непосредственно в функцию
ML.PREDICTдля генерации показателя эффективности для каждого района.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Интерпретируйте результаты.
Запрос возвращает таблицу, где каждая строка представляет собой шестиугольную область в Лондоне.
-
h3_index: Уникальный идентификатор шестиугольной ячейки. -
predicted_store_performance: Оценка модели для сайта, расположенного в этой ячейке, основанная исключительно на окружающей среде. -
h3_geography: Полигональная геометрия ячейки, которую мы будем использовать для визуализации на следующем шаге.
Высокие значения указывают на районы, где плотность школ, спортивных залов и общественного транспорта соответствует закономерностям, наблюдаемым вокруг ваших наиболее успешных существующих объектов.
Визуализируйте карту поиска потенциальных объектов
Чтобы сделать данные пригодными для практического применения, визуализируйте результаты на карте. В то время как табличный вывод предоставляет необработанные оценки, карта выявляет пространственные кластеры и коридоры высокого потенциала, которые не очевидны в списке.
В прилагаемом блокноте мы используем библиотеку geopandas для анализа геометрии полигонов H3 и folium для отображения интерактивной карты.
В результате получается картограмма, где каждая шестиугольная ячейка окрашена в соответствии с прогнозируемым для нее значением.
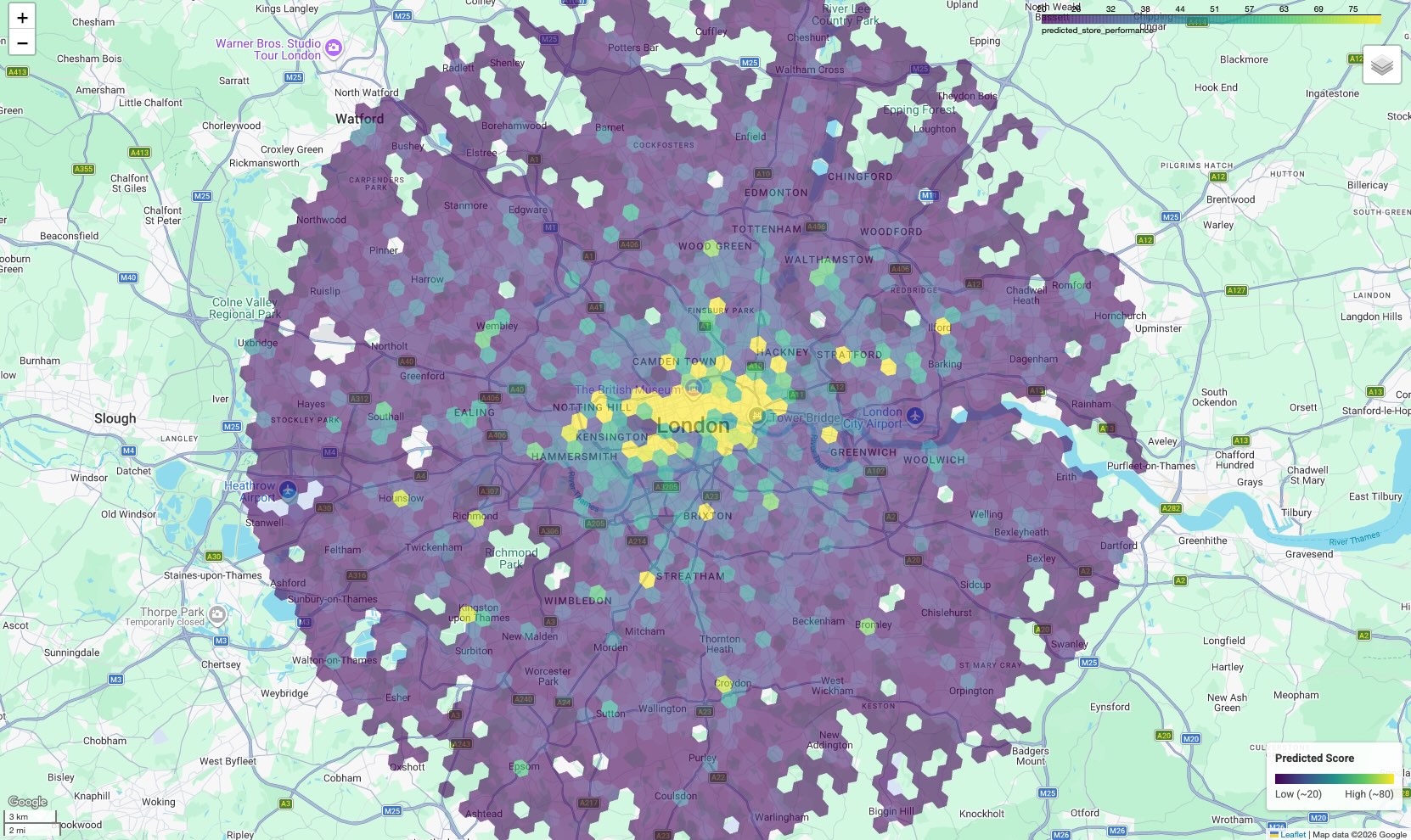
Интерпретируйте карту:
- Горячие точки (желтый/зеленый): Эти районы имеют высокие прогнозируемые показатели эффективности. В них оптимальная плотность школ, спортивных залов и общественного транспорта, что коррелирует с успешными объектами. Это отличные кандидаты для выбора новых площадок.
- Холодные зоны (фиолетовый цвет): В этих областях отсутствуют благоприятные условия окружающей среды, характерные для мест обитания ваших самых успешных животных.
- Интерактивный просмотр: В среде блокнота вы можете навести курсор на любую ячейку, чтобы увидеть конкретное количество удобств (например, «Тренажерные залы: 12»), которые повлияли на этот конкретный показатель.
Заключение
Вы успешно объединили внутренние операционные данные с Places Insights для диагностики эффективности сайтов. Проанализировав весовые коэффициенты модели, вы определили конкретные характеристики районов, которые коррелируют с существующими показателями. Используя пространственную индексацию H3, вы масштабировали этот анализ с нескольких сотен сайтов до тысяч потенциальных районов по всему Лондону.
Следующие действия
- Расширение возможностей проектирования признаков: добавьте в запрос более конкретные типы мест , чтобы выявить нишевые факторы, влияющие на посещаемость.
- Изучите продвинутые модели: хотя линейная регрессия обеспечивает четкую объяснимость, поэкспериментируйте с
BOOSTED_TREE_REGRESSORв BigQuery ML в сочетании с соответствующей стратегией перекрестной проверки для выявления нелинейных зависимостей. - Внедрите карту в практику: экспортируйте результаты сетки H3 на пользовательскую панель мониторинга с помощью JavaScript API карт, чтобы поделиться этими данными со своей командой.
Авторы
- Хенрик Вэлв | Инженер DevX
- Геннадий Дончитс | Инженер по работе с клиентами