

Por que um site prospera enquanto outro tem desempenho abaixo do esperado, apesar de ter pessoal, inventário e práticas operacionais consistentes? Empresas com várias unidades costumam ter dificuldades para explicar essa variação de performance no portfólio. A resposta geralmente está oculta no ambiente externo. Ao aproveitar os dados de pontos de interesse (POI, na sigla em inglês), podemos ir além das explicações anedóticas e quantificar exatamente como a densidade competitiva local e as características do bairro determinam o sucesso de um site.
Este guia demonstra como quantificar o impacto do entorno local no sucesso do site usando o Insights de Lugares e o BigQuery ML. Você vai combinar seus dados de desempenho do site com indicadores geoespaciais externos para diagnosticar os fatores de desempenho.
Vamos usar um conjunto de dados de sites em Londres para criar um modelo de regressão linear. Esse fluxo de trabalho usa a indexação espacial H3, um sistema que divide a cidade em células hexagonais uniformes. Ao agregar dados ambientais nessas células, é possível treinar um modelo para prever o potencial de desempenho de qualquer bairro da cidade, não apenas dos locais atuais.
Você vai aprender a:
- Recursos de engenharia:agregam contagens de pontos de interesse (PDIs), como academias, escolas e estações de transporte público, em um raio de 500 metros dos seus sites.
- Treinar um modelo:use o BigQuery ML para criar um modelo de regressão que correlacione esses recursos ambientais com suas métricas internas de performance.
- Pontuar a cidade:aplique o modelo treinado a toda a grade H3 de Londres para identificar pontos de interesse de alto potencial para expansão futura.
Se você não conhece o BigQuery ML, consulte Introdução ao BigQuery ML para saber mais sobre os principais conceitos e tipos de modelos compatíveis.
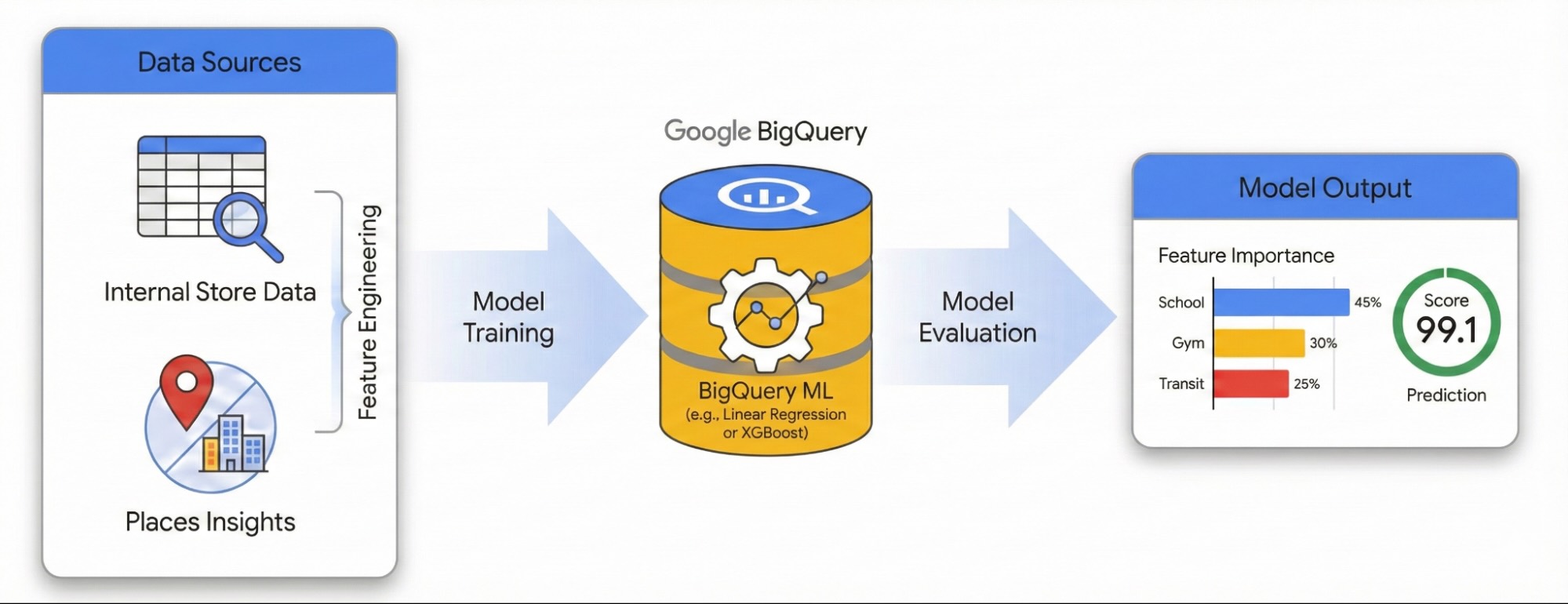
Para conferir esse fluxo de trabalho em um ambiente interativo, execute o seguinte notebook. Ele demonstra como criar um modelo preditivo com o BigQuery ML e visualizar oportunidades em toda a cidade usando a indexação espacial H3.
 Ver código-fonte no GitHub
Ver código-fonte no GitHub
Pré-requisitos
Antes de começar, verifique se você tem o seguinte:
Projeto do Google Cloud:
- Ter um projeto do Google Cloud com o faturamento ativado.
Acesso a dados:
- Assinatura do Insights de Lugares no BigQuery.
- Sua própria tabela de locais do site com uma métrica de performance (por exemplo, receita). Um conjunto de dados de exemplo está nos recursos do tutorial.
Plataforma Google Maps:
- Uma chave de API.
- As seguintes APIs estão ativadas para sua chave:
Ambiente e bibliotecas do Python:
- Um ambiente Python, como o Colab Enterprise no console do Google Cloud.
- As seguintes bibliotecas instaladas:
Biblioteca Descrição pandas-gbqComo usar o BigQuery. geopandasProcessa operações de dados geoespaciais. foliumCriar mapas interativos. shapelyManipulações geométricas.
Permissões do IAM:
- Verifique se sua conta de usuário ou de serviço tem os seguintes papéis do IAM:
Papel ID Editor de dados do BigQuery roles/bigquery.dataEditorUsuário do BigQuery roles/bigquery.user
- Verifique se sua conta de usuário ou de serviço tem os seguintes papéis do IAM:
Conscientização de custos:
- Neste tutorial, usamos componentes faturáveis do Google Cloud. Esteja ciente dos
custos potenciais relacionados a:
- BigQuery ML:cobrado pelos slots de computação usados. Consulte Preços do BigQuery ML.
- Insights de Lugares:a cobrança é feita com base no uso da consulta.
- Neste tutorial, usamos componentes faturáveis do Google Cloud. Esteja ciente dos
custos potenciais relacionados a:
Engenharia de atributos com o Insights de Lugares
Para isolar os fatores externos que impulsionam o desempenho do site, transforme os dados brutos de PDI em recursos quantificáveis. Você vai calcular a densidade de comodidades ou tipos de lugares específicos, como academias, escolas e estações de transporte público, em um raio de 500 metros de cada local. As comodidades selecionadas dependem do que você acredita ser mais relevante para sua empresa.
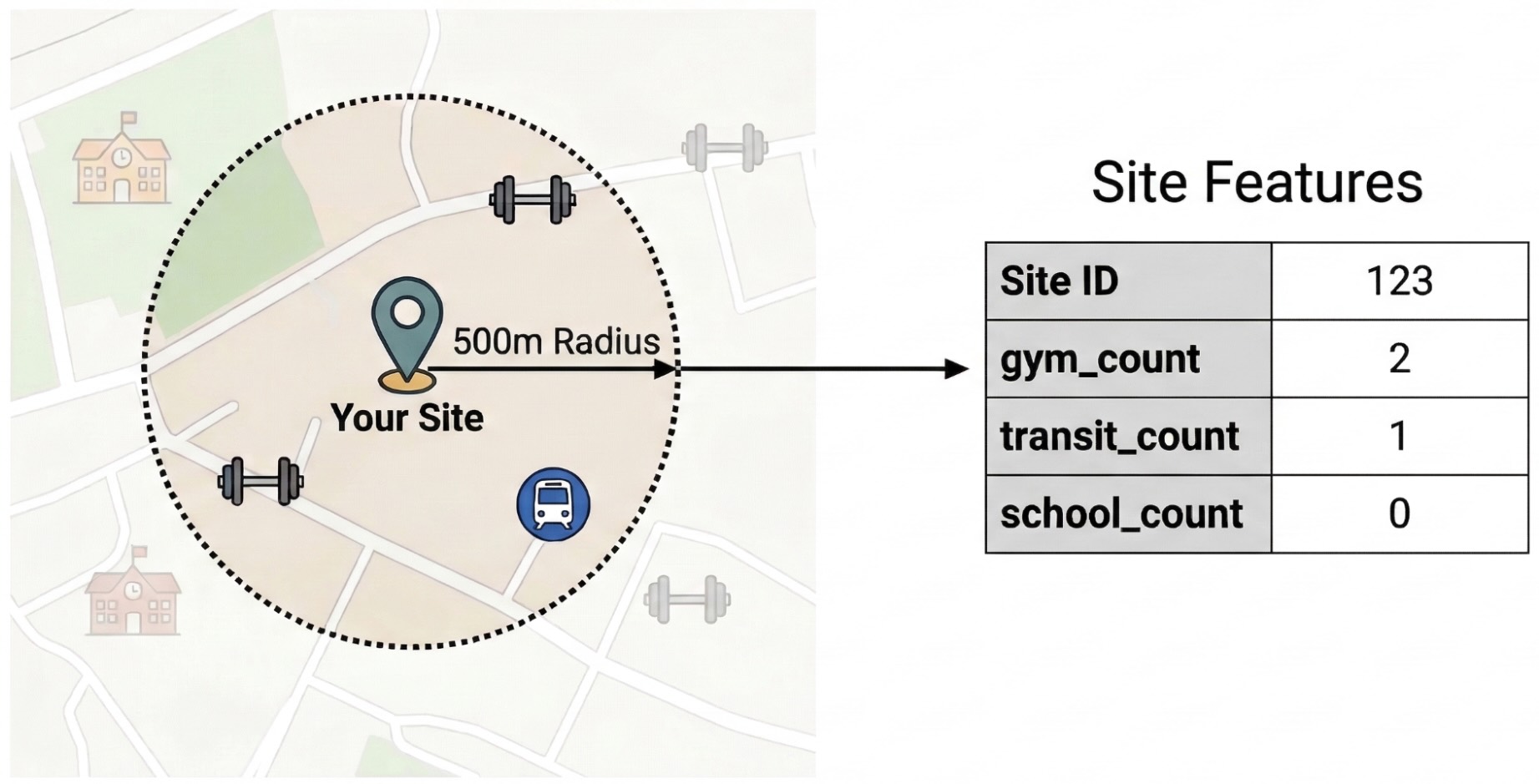
Usamos Python e a biblioteca pandas-gbq para esta etapa. Essa abordagem permite
executar a consulta SELECT WITH AGGREGATION_THRESHOLD, que é necessária para
acessar o conjunto de dados do Insights de Lugares e salvar os resultados em uma nova tabela no seu
projeto. Consulte Consultar o conjunto de dados diretamente para mais informações sobre como trabalhar com dados do Insights de Lugares.
Executar a consulta de engenharia de atributos
Execute o seguinte script Python no seu ambiente (por exemplo, Colab Enterprise). Esse script conecta os dados internos do seu site ao conjunto de dados do Insights de Lugares.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Entender a consulta
ST_DWITHIN: essa função geoespacial cria um buffer de 500 metros ao redor de cada local e identifica todos os pontos de insights de lugares que estão dentro desse raio.COUNTIF: essa função calcula a densidade de tipos de lugares específicos (por exemplo, "academia", "escola") para cada site. Essas contagens se tornam os atributos de entrada (X) para o modelo de machine learning.pandas_gbq.to_gbq: essa função salva os resultados da consulta em uma nova tabela (site_features). Essa tabela permanente serve como o conjunto de dados de treinamento limpo para o modelo do BigQuery ML.
Para aplicações mais avançadas no mundo real, considere calcular recursos em várias distâncias (por exemplo, 250 m, 500 m, 1 km) e explorar outros atributos do Insights de Lugares, como rating, price_level ou regular_opening_hours. Consulte os tipos de lugar compatíveis e a referência do esquema principal para ver a lista completa de atributos do Insights de Lugares.
Treinar o modelo com o BigQuery ML
Com os recursos projetados salvos na tabela site_features, agora é possível treinar um modelo de regressão linear.
Esse modelo aprende os pesos ideais (β) para cada atributo ambiental (X) e prevê a performance do seu site (Y).
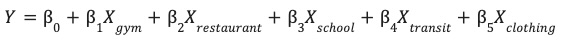
Como lidar com outliers usando o escalonamento robusto
Os dados geoespaciais geralmente contêm outliers extremos que podem distorcer modelos lineares padrão. Por exemplo, um site no West End de Londres pode ter 200 restaurantes em um raio de 500 metros, enquanto um site suburbano tem apenas dois. Se você usar o escalonamento padrão (média/desvio padrão), o outlier (200) vai distorcer a distribuição e forçar o modelo a priorizar o ajuste desse valor extremo.
Para resolver isso, usamos o dimensionamento robusto (ML.ROBUST_SCALER) na definição do modelo. Essa técnica dimensiona os recursos com base na mediana e no intervalo interquartil (IQR, na sigla em inglês), tornando o modelo resiliente a outliers e garantindo que ele aprenda com a distribuição típica dos seus sites.
Criar o modelo
Execute a seguinte consulta SQL no BigQuery para criar e treinar o modelo.
Usamos a cláusula
TRANSFORM
para aplicar o escalonamento robusto a todos os atributos de entrada. Também definimos optimize_strategy = 'NORMAL_EQUATION' porque é o método de treinamento mais eficiente para conjuntos de dados relativamente pequenos, como um portfólio típico de locais de lojas. Por fim, filtramos os outliers de alta performance (store_performance <
75) para concentrar o modelo na previsão de padrões de crescimento típicos.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Avaliar o desempenho do modelo
Antes de confiar nos insights do modelo sobre o que impulsiona o desempenho do site, é preciso verificar se as previsões dele são precisas.
Após o treinamento, use a função ML.EVALUATE para avaliar as previsões do modelo em relação a um conjunto de dados de "validação" que não foi usado durante o treinamento.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Verifique a pontuação R2 (r2_score) e o erro absoluto médio (mean_absolute_error) para determinar se o modelo está pronto para produção:
- Uma pontuação R2 mede o quanto da variância de desempenho é realmente explicada pelos fatores ambientais externos (pontos de interesse próximos). Uma pontuação de R2 de 0,70 significa que 70% do sucesso de um site está vinculado ao ambiente local. Quanto mais próximo de 1,0, mais forte é a correlação entre as comodidades ambientais e o desempenho do site.
- O MAE informa o erro médio em pontos. Por exemplo, um MAE de 1,5 significa que as previsões do modelo geralmente estão dentro de +/- 1,5 pontos da pontuação de desempenho real.
Solução de problemas com pontuações baixas
Se a pontuação R² for baixa, considere as seguintes melhorias:
- Expandir tipos de recursos:adicione diferentes tipos de lugar à sua consulta (por exemplo,
tourist_attraction,subway_station). - Ajustar raio de alcance:mude a distância
ST_DWITHIN. Um raio de 500 metros pode ser muito amplo para uma cafeteria, mas muito pequeno para uma loja de móveis. - Aumente o tamanho dos dados:treine com locais de lojas suficientes para encontrar um padrão estatisticamente significativo.
Pontuar a cidade com a indexação espacial H3
Usamos a indexação espacial H3 para dividir a cidade de Londres em uma grade uniforme de células hexagonais (resolução 8, aproximadamente 0,7 km²). Ao agregar dados do Places Insights nessas células, podemos aplicar nosso modelo treinado a todos os bairros, identificando áreas de alto potencial que correspondem ao perfil ambiental dos seus sites de melhor desempenho.
Executar a consulta de prospecção
Para gerar essa grade, usamos a função
PLACES_COUNT_PER_H3
fornecida pelo conjunto de dados do Insights de Lugares. Saiba mais sobre como consultar
o Insights de Lugares usando funções
de contagem de lugares.
Essa função calcula as contagens de PDI para células de grade H3 em uma única operação.
Execute a seguinte consulta SQL para realizar três etapas em uma única execução:
- Indexação e contagem do H3:chamamos
PLACES_COUNT_PER_H3usando um objeto de configuração JSON para encontrar todos os lugares operacionais em um raio de 25 km do centro de Londres. Consultamos isso separadamente para cada tipo de comodidade (academias, escolas etc.) e combinamos usandoUNION ALL. - Tabelas dinâmicas (engenharia de atributos): como nosso modelo de aprendizado de máquina espera colunas de atributos distintas (como
gym_counterestaurant_count), agrupamos as células e usamos a agregação condicional(SUM(IF(...)))para criar uma tabela dinâmica com os dados no esquema correto. - Previsão:inserimos esses recursos de grade dinamizada diretamente na função
ML.PREDICTpara gerar uma pontuação de desempenho para cada bairro.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Interpretar os resultados
A consulta retorna uma tabela em que cada linha representa uma área hexagonal em Londres.
h3_index: o identificador exclusivo da célula hexagonal.predicted_store_performance: a pontuação estimada do modelo para um site localizado nessa célula, com base apenas no ambiente ao redor.h3_geography: a geometria do polígono da célula, que usaremos para visualização na próxima etapa.
Valores altos indicam áreas onde a densidade de escolas, academias e transporte público corresponde aos padrões encontrados nos seus sites mais bem-sucedidos.
Visualizar o mapa de prospecção
Para tornar os dados úteis, visualize os resultados em um mapa. Enquanto a saída tabular fornece pontuações brutas, um mapa revela clusters espaciais e corredores de alto potencial que não são óbvios em uma lista.
No notebook complementar, usamos a biblioteca geopandas para analisar a geometria do polígono H3 e folium para renderizar um mapa interativo.
O resultado é um mapa coroplético em que cada célula hexagonal é colorida de acordo com a pontuação prevista.
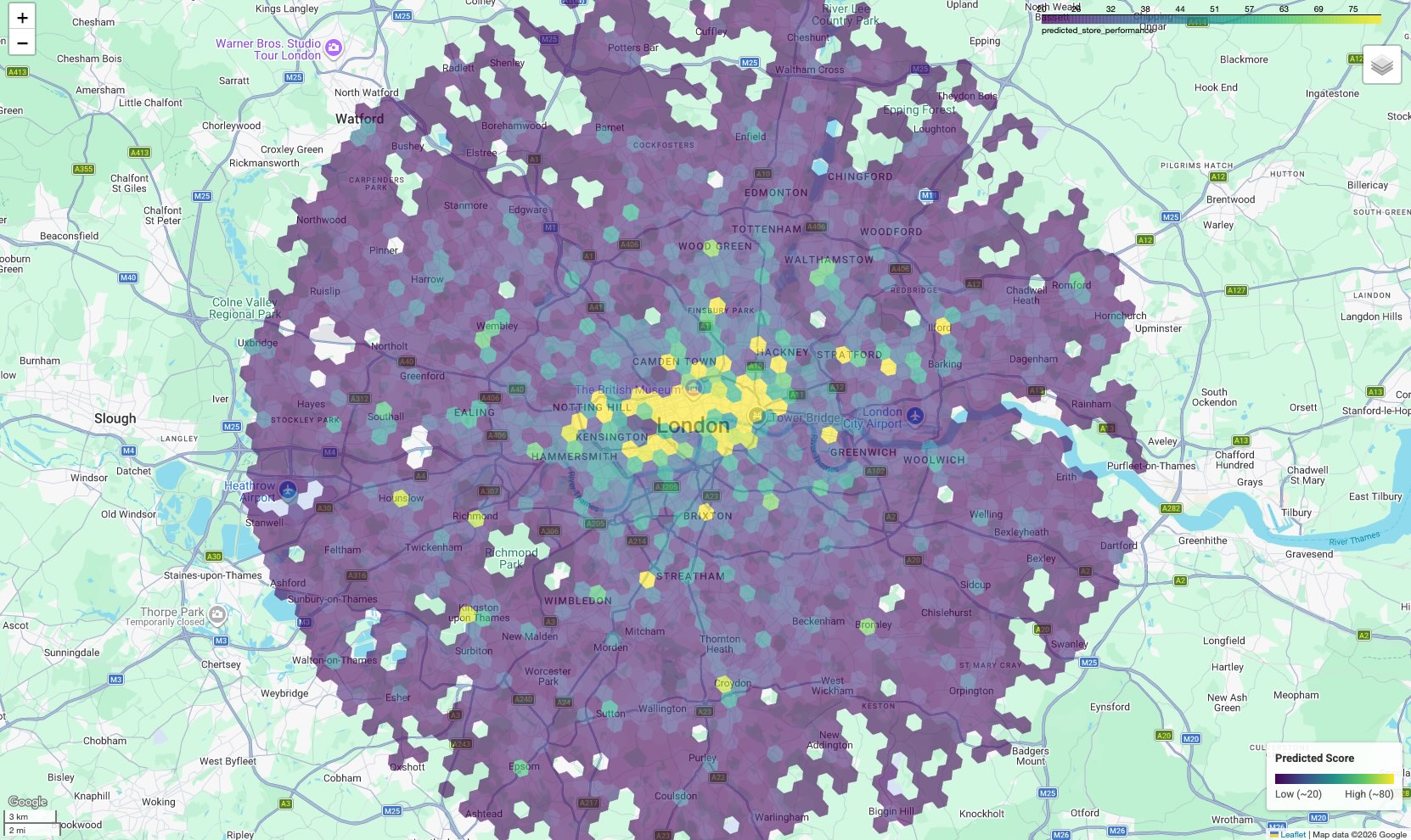
Interpretar o mapa:
- Pontos de interesse (amarelo/verde): essas áreas têm pontuações de performance previstas altas. Elas têm a densidade ideal de escolas, academias e transporte público que se correlaciona com seus sites de sucesso. Esses são os principais candidatos para a seleção de um novo site.
- Pontos frios (roxo): essas áreas não têm os recursos ambientais encontrados perto dos locais de melhor desempenho.
- Inspeção interativa:no ambiente do notebook, passe o cursor sobre qualquer célula para conferir as contagens específicas de comodidades (por exemplo, "Academias: 12") que contribuíram para essa pontuação específica.
Conclusão
Você combinou dados operacionais internos com o Insights de Lugares para diagnosticar o desempenho do site. Ao analisar os pesos do modelo, você identificou as características específicas do bairro que têm correlação com as métricas atuais. Usando a indexação espacial H3, você dimensionou essa análise de algumas centenas de sites para milhares de bairros em potencial em Londres.
Próximas ações
- Amplie a engenharia de atributos:adicione Tipos de lugar mais específicos à sua consulta para capturar os fatores de tráfego a pé de nicho.
- Explore modelos avançados:embora a regressão linear ofereça uma explicabilidade clara, teste o
BOOSTED_TREE_REGRESSORno BigQuery ML combinado com uma estratégia de validação cruzada adequada para capturar relações não lineares. - Operacionalizar o mapa:exporte os resultados da grade H3 para um painel personalizado usando a API Maps JavaScript e compartilhe esses insights com sua equipe.
Colaboradores
- Henrik Valve | Engenheiro de DevX
- Gennadii Donchyts | Engenheiro de clientes da equipe