

Dlaczego jedna witryna dobrze sobie radzi, a inna osiąga słabsze wyniki, mimo że w obu przypadkach stosowane są te same praktyki dotyczące personelu, asortymentu i działania? Firmy z wieloma lokalizacjami często mają trudności z wyjaśnieniem różnic w skuteczności w swoim portfolio. Odpowiedź zwykle jest ukryta w środowisku zewnętrznym. Dzięki wykorzystaniu danych o ciekawych miejscach możemy wyjść poza anegdotyczne wyjaśnienia i dokładnie określić, jak lokalna gęstość konkurencji i charakterystyka sąsiedztwa wpływają na sukces witryny.
Z tego przewodnika dowiesz się, jak określić wpływ lokalnego otoczenia na sukces witryny za pomocą Statystyk miejsc i BigQuery ML. Połączysz własne dane o wydajności witryny z zewnętrznymi sygnałami geoprzestrzennymi, aby zdiagnozować czynniki wpływające na wydajność.
Do utworzenia modelu regresji liniowej użyjemy zbioru danych obszarów w Londynie. Ten przepływ pracy wykorzystuje indeksowanie przestrzenne H3. System dzieli miasto na jednolite sześciokątne komórki. Dzięki agregowaniu danych środowiskowych w tych komórkach możesz wytrenować model, który będzie przewidywać potencjalną skuteczność w dowolnej dzielnicy miasta, a nie tylko w przypadku obecnych lokalizacji.
Dowiesz się, jak:
- Funkcje inżynieryjne: zagregowane liczby ważnych miejsc, takich jak siłownie, szkoły i stacje transportu publicznego, w promieniu 500 metrów od Twoich witryn.
- Trenowanie modelu: użyj BigQuery ML, aby utworzyć model regresji, który koreluje te cechy środowiskowe z wewnętrznymi wskaźnikami wydajności.
- Ocena miasta: zastosuj wytrenowany model do całej siatki H3 w Londynie, aby zidentyfikować miejsca o dużym potencjale rozwoju w przyszłości.
Jeśli dopiero zaczynasz korzystać z BigQuery ML, zapoznaj się z wprowadzeniem do BigQuery ML, aby poznać podstawowe pojęcia i obsługiwane typy modeli.
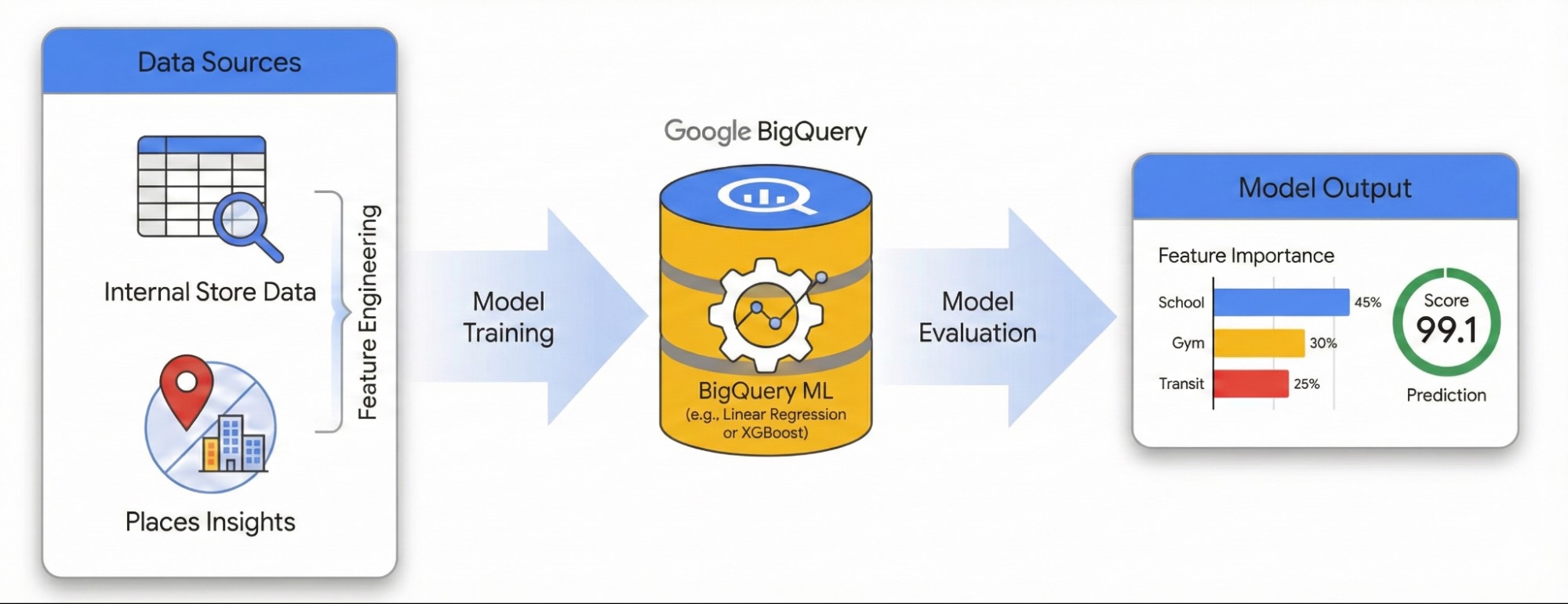
Aby zapoznać się z tym przepływem pracy w interaktywnym środowisku, uruchom ten notatnik. Pokazuje, jak utworzyć model prognozujący za pomocą BigQuery ML i wizualizować możliwości w całym mieście za pomocą indeksowania przestrzennego H3.
 Wyświetl źródło w GitHubie
Wyświetl źródło w GitHubie
Wymagania wstępne
Zanim zaczniesz, upewnij się, że masz:
Projekt Google Cloud:
- Projekt Google Cloud z włączonymi płatnościami.
Dostęp do danych:
- subskrypcję Statystyk miejsc w BigQuery.
- Twoja tabela lokalizacji witryn z danymi o skuteczności (np. przychodami). Przykładowy zbiór danych znajdziesz w materiałach do samouczka.
Google Maps Platform:
- Klucz interfejsu API.
- Interfejsy API włączone dla Twojego klucza:
Środowisko i biblioteki Pythona:
- Środowisko Pythona, takie jak Colab Enterprise w konsoli Google Cloud.
- Zainstalowane biblioteki:
Biblioteka Opis pandas-gbqInterakcja z BigQuery. geopandasobsługi operacji na danych geoprzestrzennych, foliumtworzenie interaktywnych map, shapelymanipulacje geometryczne,
Uprawnienia:
- Sprawdź, czy Twoje konto użytkownika lub konto usługi ma te role uprawnień:
Rola Identyfikator Edytujący dane BigQuery roles/bigquery.dataEditorUżytkownik BigQuery roles/bigquery.user
- Sprawdź, czy Twoje konto użytkownika lub konto usługi ma te role uprawnień:
Świadomość kosztów:
- W tym samouczku używane są płatne komponenty Google Cloud. Pamiętaj o potencjalnych kosztach związanych z:
- BigQuery ML: opłata za użyte przedziały obliczeniowe. Zobacz cennik BigQuery ML.
- Statystyki miejsc: opłaty są naliczane na podstawie wykorzystania zapytań.
- W tym samouczku używane są płatne komponenty Google Cloud. Pamiętaj o potencjalnych kosztach związanych z:
Inżynieria cech z wykorzystaniem Statystyk miejsc
Aby odizolować czynniki zewnętrzne wpływające na wydajność witryny, musisz przekształcić surowe dane o punktach POI w mierzalne cechy. Obliczysz gęstość występowania określonych udogodnień lub typów miejsc, takich jak siłownie, szkoły i stacje transportu publicznego, w promieniu 500 metrów od każdego miejsca. Wybrane udogodnienia będą zależeć od tego, co Twoim zdaniem może być najbardziej istotne dla Twojej firmy.
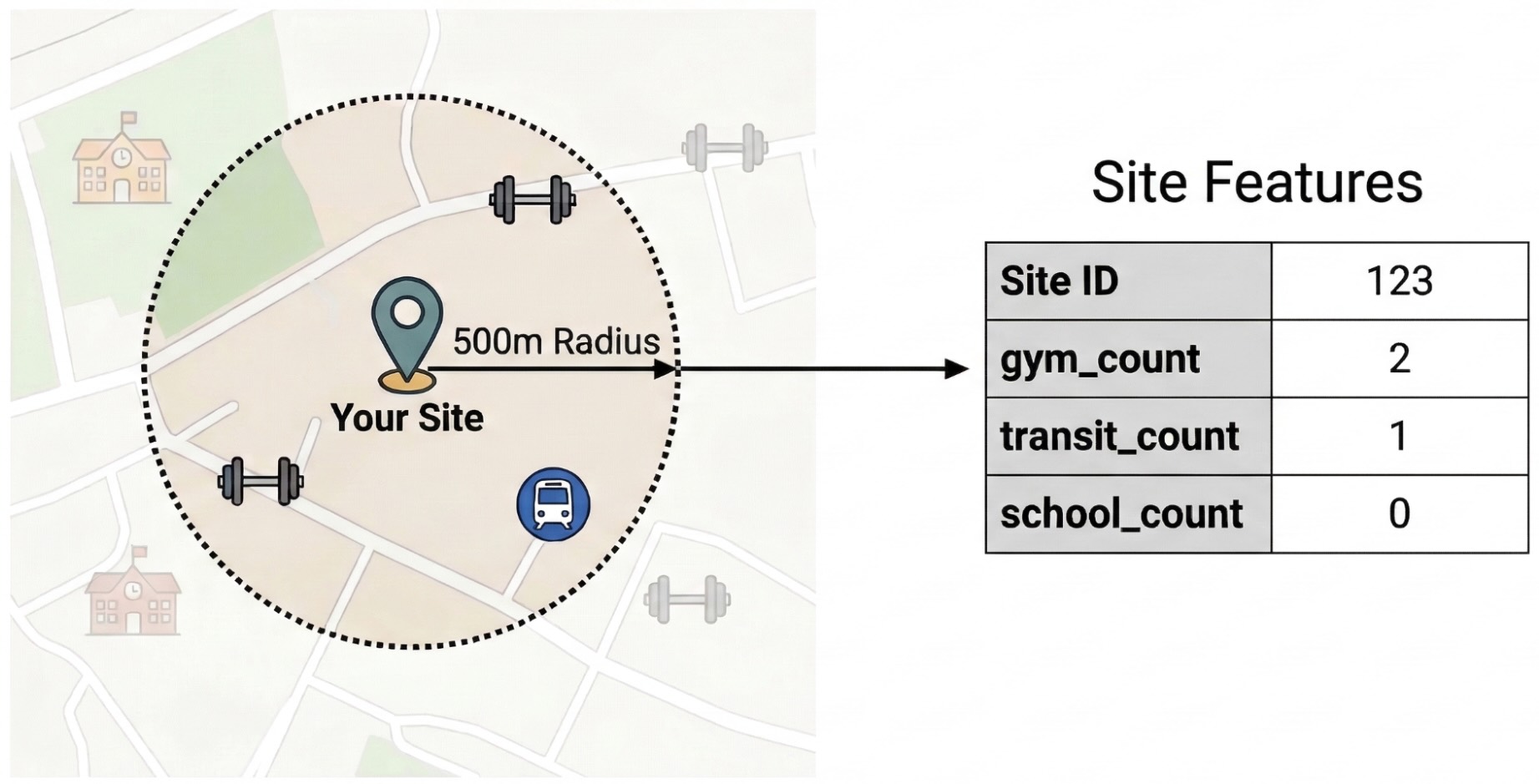
W tym kroku używamy Pythona i biblioteki pandas-gbq. To podejście umożliwia wykonanie zapytania SELECT WITH AGGREGATION_THRESHOLD, które jest wymagane do uzyskania dostępu do zbioru danych Statystyki miejsc, i zapisanie wyników w nowej tabeli w projekcie. Więcej informacji o pracy z danymi Statystyk miejsc znajdziesz w artykule Bezpośrednie wysyłanie zapytań do zbioru danych.
Uruchom zapytanie dotyczące inżynierii cech
Uruchom w swoim środowisku ten skrypt w Pythonie (np. Colab Enterprise). Ten skrypt łączy wewnętrzne dane witryny ze zbiorem danych Statystyk miejsc.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Zrozumienie zapytania
ST_DWITHIN: ta funkcja geoprzestrzenna tworzy 500-metrowy bufor wokół każdej lokalizacji witryny i identyfikuje wszystkie punkty Statystyk miejsc, które znajdują się w tym promieniu.COUNTIF: ta funkcja oblicza gęstość występowania określonych typów miejsc (np. „siłownia”, „szkoła”) w przypadku każdej witryny. Te liczby stają się danymi wejściowymi (X) dla modelu uczenia maszynowego.pandas_gbq.to_gbq: ta funkcja zapisuje wyniki zapytania w nowej tabeli (site_features). Ta stała tabela służy jako oczyszczony zestaw danych treningowych dla modelu BigQuery ML.
W przypadku bardziej zaawansowanych zastosowań w rzeczywistym świecie rozważ obliczanie cech w różnych odległościach (np. 250 m, 500 m, 1 km) i korzystanie z innych atrybutów Statystyk miejsc, takich jak rating, price_level lub regular_opening_hours. Pełną listę atrybutów Statystyk miejsc znajdziesz w sekcji obsługiwane typy miejsc i w podstawowym schemacie.
Trenowanie modelu za pomocą BigQuery ML
Po zapisaniu zaprojektowanych cech w tabeli site_features możesz wytrenować model regresji liniowej.
Ten model uczy się optymalnych wag (β) dla każdej cechy środowiskowej (X), aby prognozować wydajność witryny (Y).
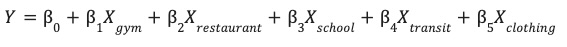
Obsługa wartości odstających za pomocą skalowania odpornego na wartości odstające
Dane geoprzestrzenne często zawierają skrajne wartości odstające, które mogą zniekształcać standardowe modele liniowe. Na przykład w dzielnicy West End w Londynie w promieniu 500 metrów może znajdować się 200 restauracji, a na przedmieściach tylko 2. Jeśli używasz skalowania standardowego (średnia/odchylenie standardowe), wartość odstająca (200) zniekształca rozkład i zmusza model do nadania priorytetu dopasowaniu tej ekstremalnej wartości.
Aby rozwiązać ten problem, w definicji modelu używamy skalowania odpornego (ML.ROBUST_SCALER). Ta technika skaluje funkcje na podstawie mediany i zakresu międzykwartylowego (IQR), dzięki czemu model jest odporny na wartości odstające i uczy się na podstawie typowego rozkładu witryn.
Tworzenie modelu
Aby utworzyć i wytrenować model, uruchom w BigQuery to zapytanie SQL:
Używamy klauzuli
TRANSFORM
do zastosowania niezawodnego skalowania do wszystkich cech wejściowych. Ustawiamy też optimize_strategy = 'NORMAL_EQUATION', ponieważ jest to najbardziej wydajna metoda trenowania stosunkowo małych zbiorów danych, takich jak typowe portfolio lokalizacji sklepów. Na koniec odfiltrowujemy wartości odstające o wysokiej skuteczności (store_performance <
75), aby skupić model na przewidywaniu typowych wzorców wzrostu.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Ocena skuteczności modelu
Zanim zaczniesz ufać statystykom modelu o tym, co wpływa na wydajność witryny, musisz sprawdzić, czy jego prognozy są dokładne.
Po trenowaniu użyj funkcji ML.EVALUATE, aby ocenić prognozy modelu na podstawie „wyłączonego” zbioru danych, który nie był używany podczas trenowania.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Sprawdź wartość R2 (r2_score) i średni błąd bezwzględny (mean_absolute_error), aby określić, czy model jest gotowy do wdrożenia:
- Współczynnik R2 określa, w jakim stopniu zmienność wyników jest wyjaśniana przez zewnętrzne czynniki środowiskowe (pobliskie punkty POI). Wartość R2 wynosząca 0,70 oznacza, że 70% sukcesu witryny jest związanych z lokalnym środowiskiem. Im bliżej 1,0, tym silniejsza jest korelacja między udogodnieniami środowiskowymi a wydajnością witryny.
- MAE informuje o średnim błędzie w punktach. Na przykład MAE na poziomie 1,5 oznacza, że prognozy modelu zwykle mieszczą się w zakresie +/- 1,5 punktu od rzeczywistego wyniku.
Rozwiązywanie problemów z niskimi wynikami
Jeśli Twój wynik R2 jest niski, rozważ wprowadzenie tych ulepszeń:
- Rozwiń typy obiektów: dodaj do zapytania różne typy miejsc (np.
tourist_attraction,subway_station). - Dostosuj promień obszaru docelowego: zmień odległość
ST_DWITHIN. Promień 500 metrów może być zbyt duży w przypadku kawiarni, ale zbyt mały w przypadku sklepu meblowego. - Zwiększ rozmiar danych: upewnij się, że trenujesz model na wystarczającej liczbie lokalizacji sklepów, aby znaleźć istotny statystycznie wzorzec.
Ocena miasta za pomocą indeksowania przestrzennego H3
Do podziału Londynu na jednolitą siatkę sześciokątnych komórek (rozdzielczość 8, około 0,7 km²) używamy indeksowania przestrzennego H3. Agregując dane Places Insights w tych komórkach, możemy zastosować wytrenowany model do każdej dzielnicy, aby zidentyfikować obszary o wysokim potencjale, które pasują do profilu środowiskowego Twoich najlepiej działających lokalizacji.
Uruchamianie zapytania dotyczącego potencjalnych klientów
Do wygenerowania tej siatki używamy funkcji PLACES_COUNT_PER_H3 udostępnianej przez zbiór danych Statystyki miejsc (więcej informacji o wykonywaniu zapytań dotyczących Statystyk miejsc za pomocą funkcji Places Count).
Ta funkcja oblicza liczbę punktów POI w komórkach siatki H3 w ramach jednej operacji.
Uruchom to zapytanie SQL, aby wykonać 3 czynności w ramach jednego wykonania:
- Indeksowanie i zliczanie H3: wywołujemy
PLACES_COUNT_PER_H3za pomocą obiektu konfiguracji JSON, aby znaleźć wszystkie działające miejsca w promieniu 25 km od centrum Londynu. Wysyłamy osobne zapytania dotyczące każdego typu udogodnienia (siłownie, szkoły itp.) i łączymy je za pomocą funkcjiUNION ALL. - Przekształcanie danych (inżynieria cech): ponieważ nasz model uczenia maszynowego oczekuje odrębnych kolumn cech (np.
gym_countirestaurant_count), grupujemy komórki i używamy agregacji warunkowej(SUM(IF(...))), aby przekształcić dane w odpowiedni schemat. - Prognoza: te przestawione cechy siatki przekazujemy bezpośrednio do funkcji
ML.PREDICT, aby wygenerować wynik skuteczności dla każdej okolicy.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Interpretowanie wyników
Zapytanie zwraca tabelę, w której każdy wiersz reprezentuje obszar sześciokątny w Londynie.
h3_index: unikalny identyfikator komórki sześciokątnej.predicted_store_performance: szacowany przez model wynik dla witryny znajdującej się w tej komórce, oparty wyłącznie na otoczeniu.h3_geography: geometria wielokąta komórki, której użyjemy do wizualizacji w następnym kroku.
Wysokie wartości wskazują obszary, w których gęstość szkół, siłowni i transportu publicznego odpowiada wzorcom występującym w pobliżu Twoich najbardziej skutecznych lokalizacji.
Wizualizacja mapy potencjalnych klientów
Aby dane były przydatne, wizualizuj wyniki na mapie. Dane wyjściowe w formie tabeli zawierają surowe wyniki, ale mapa pokazuje klastry przestrzenne i korytarze o dużym potencjale, które nie są widoczne na liście.
W dołączonym notatniku używamy biblioteki geopandas do analizowania geometrii wielokąta H3 i biblioteki folium do renderowania interaktywnej mapy.
Wynikiem jest mapa kartogramowa, na której każda komórka sześciokątna jest pokolorowana zgodnie z prognozowanym wynikiem.
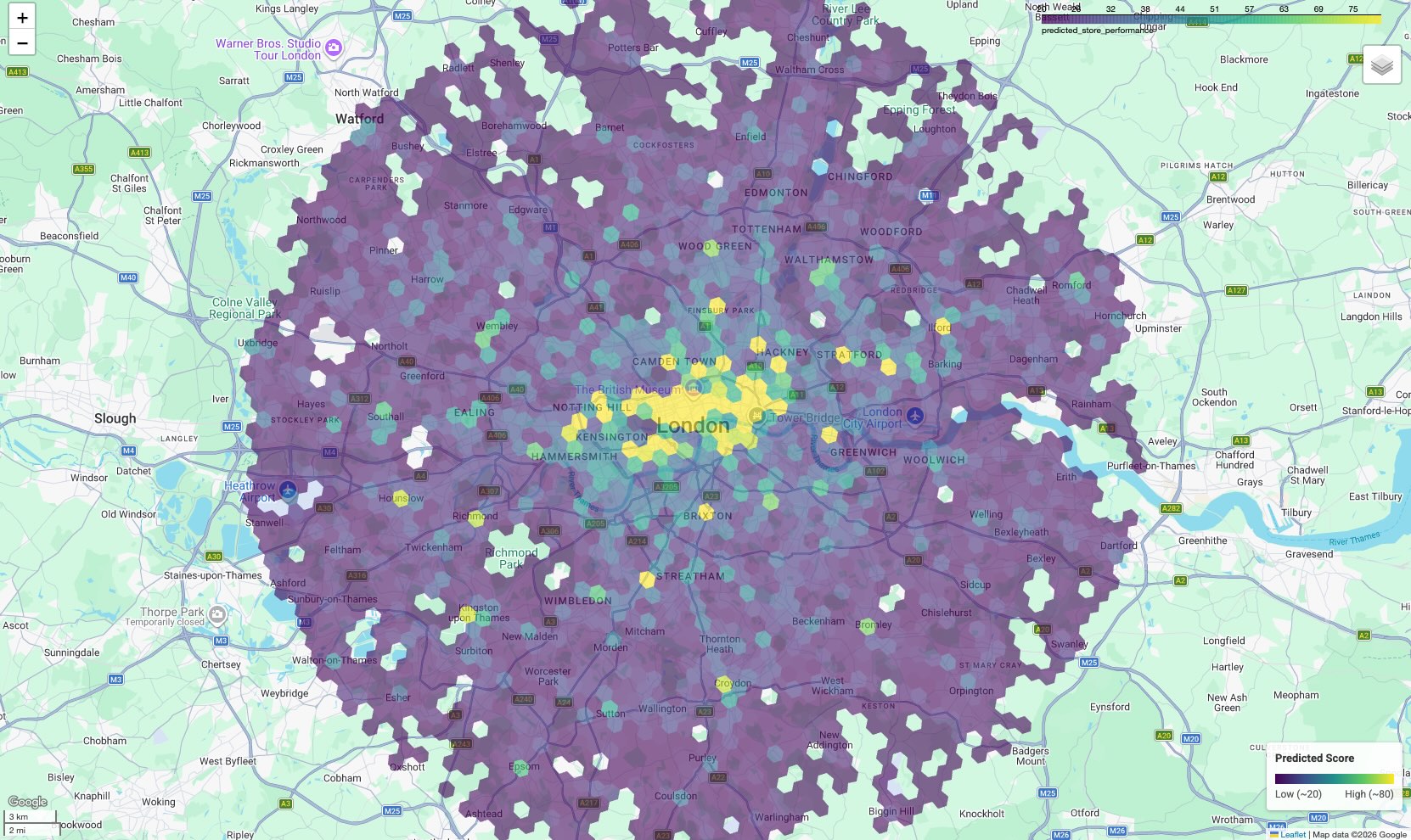
Interpret the Map:
- Hotspoty (żółte/zielone): te obszary mają wysokie prognozowane wyniki skuteczności. Mają one optymalną gęstość szkół, siłowni i transportu publicznego, która jest skorelowana z Twoimi skutecznymi lokalizacjami. Są to idealne miejsca na nowe witryny.
- Miejsca o niskiej skuteczności (fioletowe): w tych obszarach brakuje cech środowiskowych, które występują w pobliżu miejsc o najwyższej skuteczności.
- Interaktywne sprawdzanie: w środowisku notatnika możesz najechać kursorem na dowolną komórkę, aby zobaczyć konkretne liczby udogodnień (np. „Siłownie: 12”), które wpłynęły na dany wynik.
Podsumowanie
Udało Ci się połączyć wewnętrzne dane operacyjne ze Statystykami miejsc, aby zdiagnozować wydajność witryny. Analizując wagi modelu, udało Ci się zidentyfikować konkretne cechy dzielnicy, które są skorelowane z dotychczasowymi danymi. Dzięki indeksowaniu przestrzennemu H3 udało Ci się rozszerzyć analizę z kilkuset obszarów na tysiące potencjalnych okolic w Londynie.
Następne działania
- Rozszerz inżynierię cech: dodaj do zapytania bardziej szczegółowe typy miejsc, aby uwzględnić niszowe czynniki wpływające na ruch w sklepie stacjonarnym.
- Poznaj zaawansowane modele: regresja liniowa zapewnia jasną wyjaśnialność, ale eksperymentuj z
BOOSTED_TREE_REGRESSORw BigQuery ML w połączeniu z odpowiednią strategią walidacji krzyżowej, aby uchwycić nieliniowe zależności. - Wprowadź mapę w życie: wyeksportuj wyniki siatki H3 do niestandardowego panelu za pomocą interfejsu Maps JavaScript API, aby udostępnić te statystyki zespołowi.
Współtwórcy
- Henrik Valve | Inżynier DevX
- Gennadii Donchyts | Staff Customer Engineer