

일관된 인력, 인벤토리, 운영 관행에도 불구하고 한 사이트는 번성하는 반면 다른 사이트는 실적이 저조한 이유는 무엇인가요? 여러 위치에 있는 비즈니스는 포트폴리오 전반의 실적 차이를 설명하는 데 어려움을 겪는 경우가 많습니다. 답은 일반적으로 외부 환경에 숨겨져 있습니다. 관심 장소 (POI) 데이터를 활용하면 일화적인 설명을 넘어 지역 경쟁 밀도와 동네 특성이 사이트의 성공을 정확히 어떻게 결정하는지 정량화할 수 있습니다.
이 가이드에서는 장소 통계 및 BigQuery ML을 사용하여 사이트 성공에 대한 주변 환경의 영향을 정량화하는 방법을 보여줍니다. 독점 사이트 실적 데이터를 외부 지리 공간 신호와 결합하여 실적 요인을 진단합니다.
런던의 사이트 데이터 세트를 사용하여 선형 회귀 모델을 빌드합니다. 이 워크플로는 H3 공간 색인을 활용합니다. 이 시스템은 도시를 균일한 육각형 셀로 나눕니다. 환경 데이터를 이러한 셀로 집계하면 기존 사이트뿐만 아니라 도시의 모든 지역의 실적 잠재력을 예측하는 모델을 학습시킬 수 있습니다.
학습할 내용
- 기능 엔지니어링: 사이트에서 반경 500m 이내에 있는 헬스장, 학교, 대중교통역과 같은 관심 장소 (POI)의 개수를 집계합니다.
- 모델 학습: BigQuery ML을 사용하여 이러한 환경적 특징과 내부 실적 측정항목을 연관시키는 회귀 모델을 빌드합니다.
- 도시 점수 매기기: 학습된 모델을 런던의 전체 H3 그리드에 적용하여 향후 확장을 위한 잠재력이 높은 핫스팟을 식별합니다.
BigQuery ML을 처음 사용하는 경우 BigQuery ML 소개에서 핵심 개념과 지원되는 모델 유형을 알아보세요.
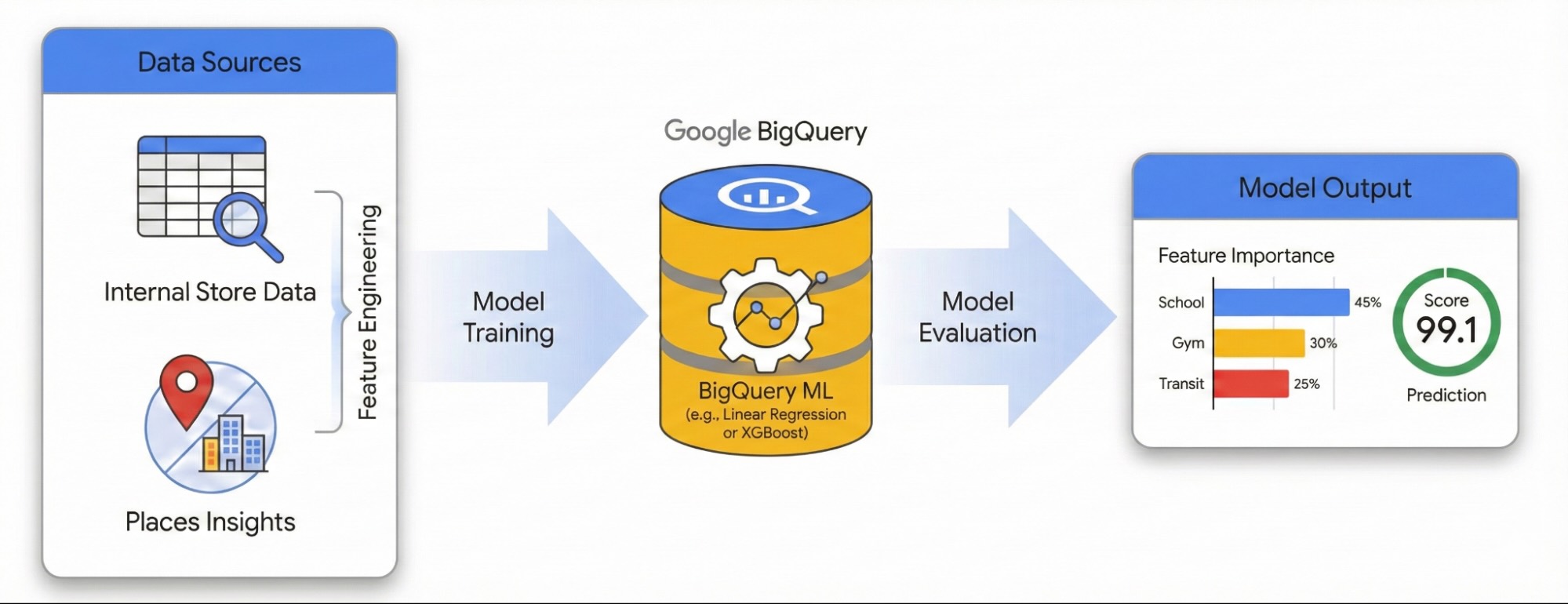
대화형 환경에서 이 워크플로를 살펴보려면 다음 노트북을 실행하세요. BigQuery ML로 예측 모델을 빌드하고 H3 공간 색인 생성을 사용하여 도시 전체의 기회를 시각화하는 방법을 보여줍니다.
 GitHub에서 소스 보기
GitHub에서 소스 보기
기본 요건
시작하기 전에 다음 사항을 확인하세요.
Google Cloud 프로젝트:
- 결제가 사용 설정된 Google Cloud 프로젝트.
데이터 액세스:
- BigQuery의 Places Insights 구독
- 실적 측정항목 (예: 수익)이 포함된 사이트 위치 표 예시 데이터 세트는 튜토리얼 리소스에 있습니다.
Google Maps Platform:
- API 키
- 키에 사용 설정된 API는 다음과 같습니다.
Python 환경 및 라이브러리:
- Google Cloud 콘솔의 Colab Enterprise와 같은 Python 환경
- 다음 라이브러리가 설치되어 있습니다.
라이브러리 설명 pandas-gbqBigQuery와 상호작용 geopandas지리 공간 데이터 작업 처리 folium대화형 지도 만들기 shapely기하학적 조작
IAM 권한:
- 사용자 또는 서비스 계정에 다음 IAM 역할이 있는지 확인합니다.
역할 ID BigQuery 데이터 편집자 roles/bigquery.dataEditorBigQuery 사용자 roles/bigquery.user
- 사용자 또는 서비스 계정에 다음 IAM 역할이 있는지 확인합니다.
비용 인식:
- 이 튜토리얼에서는 비용이 청구될 수 있는 Google Cloud 구성요소를 사용합니다. 다음과 관련된 잠재적 비용을 고려하세요.
- BigQuery ML: 사용된 컴퓨팅 슬롯에 대해 요금이 청구됩니다. BigQuery ML 가격 책정을 참고하세요.
- Places 통계: 쿼리 사용량에 따라 요금이 청구됩니다.
- 이 튜토리얼에서는 비용이 청구될 수 있는 Google Cloud 구성요소를 사용합니다. 다음과 관련된 잠재적 비용을 고려하세요.
장소 통계를 사용한 특성 추출
사이트 실적을 유도하는 외부 요인을 분리하려면 원시 관심 장소 데이터를 정량화 가능한 특징으로 변환해야 합니다. 각 사이트의 반경 500m 내에 있는 특정 편의시설 또는 장소 유형(예: 헬스장, 학교, 대중교통역)의 밀도를 계산합니다. 선택하는 편의시설은 비즈니스와 가장 관련성이 높다고 생각되는 항목에 따라 달라집니다.
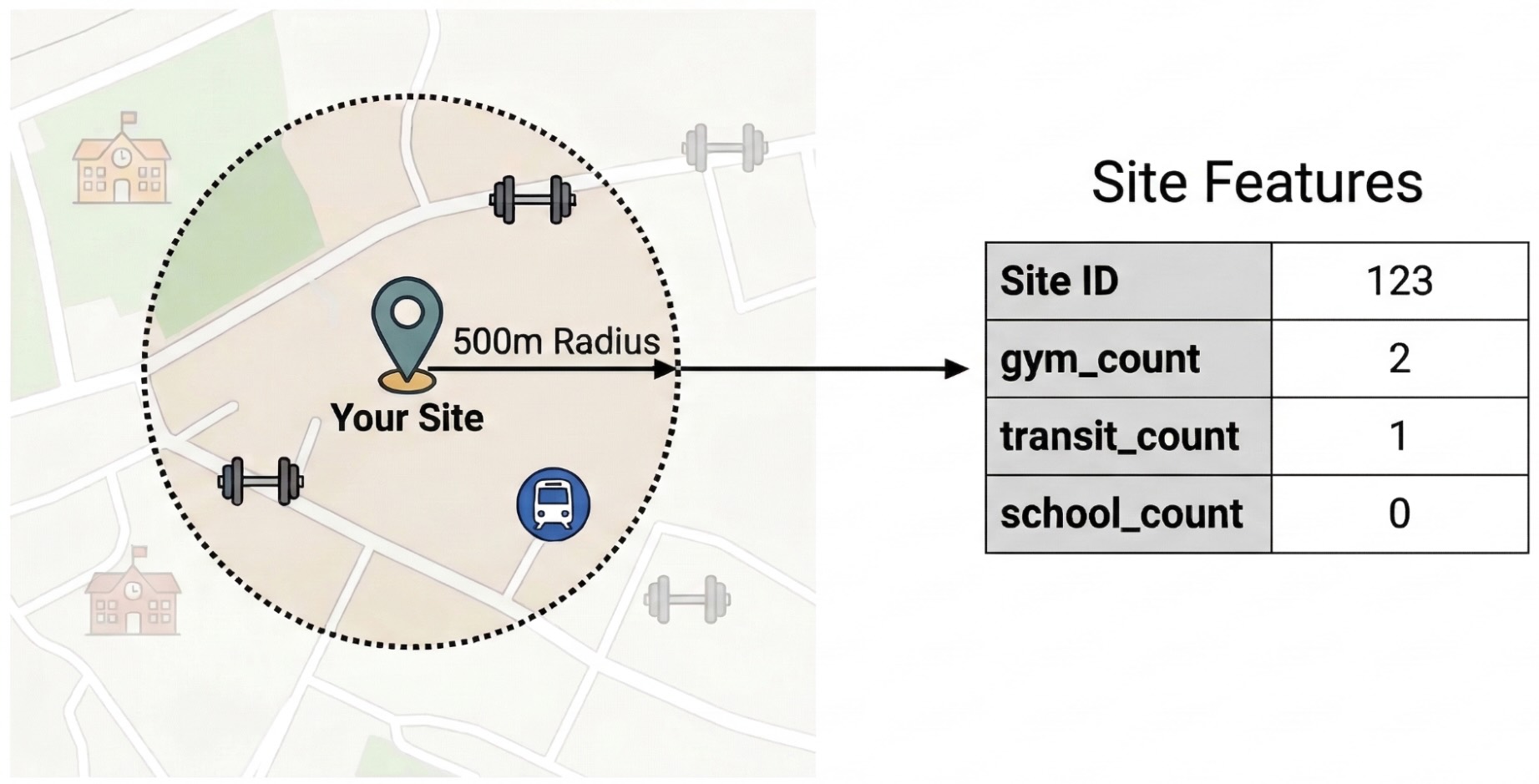
이 단계에서는 Python과 pandas-gbq 라이브러리를 사용합니다. 이 방법을 사용하면 Places Insights 데이터 세트에 액세스하는 데 필요한 SELECT WITH AGGREGATION_THRESHOLD 쿼리를 실행하고 결과를 프로젝트의 새 테이블에 저장할 수 있습니다. 장소 통계 데이터 작업에 관한 자세한 내용은 데이터 세트 직접 쿼리를 참고하세요.
특성 추출 쿼리 실행
환경 (예: Colab Enterprise)에서 다음 Python 스크립트를 실행합니다. 이 스크립트는 내부 사이트 데이터를 Places Insights 데이터 세트와 연결합니다.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
질문 이해하기
ST_DWITHIN: 이 지리 공간 함수는 각 사이트 위치 주변에 500미터 버퍼를 만들고 해당 반경 내에 있는 모든 장소 통계 포인트를 식별합니다.COUNTIF: 이 함수는 각 사이트의 특정 장소 유형(예: 'gym', 'school')의 밀도를 계산합니다. 이 숫자는 머신러닝 모델의 입력 특징 (X)이 됩니다.pandas_gbq.to_gbq: 이 함수는 쿼리 결과를 새 테이블 (site_features)에 유지합니다. 이 영구 테이블은 BigQuery ML 모델의 클린 학습 데이터 세트 역할을 합니다.
더 고급 실제 애플리케이션의 경우 여러 거리 (예: 250m, 500m, 1km)에서 기능을 계산하고 rating, price_level, regular_opening_hours와 같은 다른 장소 통계 속성을 살펴보세요. Places Insights 속성의 전체 목록은 지원되는 장소 유형 및 핵심 스키마 참조를 참고하세요.
BigQuery ML로 모델 학습
추출된 특징이 site_features 테이블에 저장되었으므로 이제 선형 회귀 모델을 학습시킬 수 있습니다.
이 모델은 사이트의 실적 (Y)을 예측하기 위해 각 환경 기능 (X)의 최적 가중치 (β)를 학습합니다.
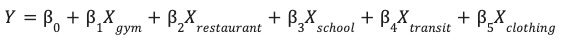
강력한 스케일링으로 이상치 처리
지리 공간 데이터에는 표준 선형 모델을 왜곡할 수 있는 극단적인 이상치가 포함되는 경우가 많습니다. 예를 들어 런던 웨스트엔드에 있는 사이트에는 500m 이내에 200개의 레스토랑이 있을 수 있지만, 교외에 있는 사이트에는 2개만 있을 수 있습니다. 표준 스케일링 (평균/표준 편차)을 사용하면 이상치 (200)가 분포를 왜곡하고 모델이 극단값을 우선적으로 맞추도록 강제합니다.
이 문제를 해결하기 위해 모델 정의 내에서 Robust Scaling(ML.ROBUST_SCALER)을 사용합니다. 이 기법은 중앙값과 사분위수 범위 (IQR)를 기반으로 기능을 확장하여 모델이 이상치에 탄력적으로 대응하고 사이트의 일반적인 분포에서 학습하도록 합니다.
모델 만들기
BigQuery에서 다음 SQL 쿼리를 실행하여 모델을 만들고 학습시킵니다.
TRANSFORM 절을 사용하여 모든 입력 특성에 강력한 스케일링을 적용합니다. 또한 일반적인 매장 위치 포트폴리오와 같이 비교적 작은 데이터 세트의 경우 optimize_strategy = 'NORMAL_EQUATION'가 가장 효율적인 학습 방법이므로 optimize_strategy = 'NORMAL_EQUATION'를 설정합니다. 마지막으로 모델이 일반적인 성장 패턴을 예측하는 데 집중할 수 있도록 실적이 우수한 이상치 (store_performance <
75)를 필터링합니다.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
모델 성능 평가
사이트 실적을 개선하는 요인에 대한 모델의 통계를 신뢰하려면 모델의 예측이 정확한지 확인해야 합니다.
학습 후 ML.EVALUATE 함수를 사용하여 학습 중에 사용되지 않은 '홀드아웃' 데이터 세트에 대해 모델의 예측을 평가합니다.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
R2 점수(r2_score)와 평균 절대 오차(mean_absolute_error)를 확인하여 모델이 프로덕션에 적합한지 확인합니다.
- R2 점수는 성능 분산 중 실제로 외부 환경 요인 (근처 POI)으로 설명되는 정도를 측정합니다. R2 점수가 0.70이면 사이트의 성공 중 70% 가 지역 환경과 관련이 있다는 의미입니다. 1.0에 가까울수록 환경 편의시설과 사이트 성능 간의 상관관계가 강합니다.
- MAE는 평균 오류를 포인트로 나타냅니다. 예를 들어 MAE가 1.5이면 모델의 예측이 일반적으로 실제 성능 점수에서 +/- 1.5점 이내임을 의미합니다.
낮은 점수 문제 해결
R2 점수가 낮은 경우 다음 개선사항을 고려하세요.
- 기능 유형 확장: 쿼리에 다양한 장소 유형 (예:
tourist_attraction,subway_station)을 추가합니다. - 유역 반경 조정:
ST_DWITHIN거리를 변경합니다. 반경 500m는 커피숍에는 너무 넓지만 가구점에는 너무 작을 수 있습니다. - 데이터 크기 늘리기: 통계적으로 유의미한 패턴을 찾을 수 있을 만큼 충분한 매장 위치에서 학습해야 합니다.
H3 공간 색인으로 도시 점수 매기기
Google에서는 H3 공간 색인 지정을 사용하여 런던을 육각형 셀의 균일한 그리드 (해상도 8, 약 0.7km²)로 나눕니다. 장소 통계 데이터를 이러한 셀로 집계하면 학습된 모델을 모든 지역에 적용하여 실적이 우수한 사이트의 환경 프로필과 일치하는 잠재력이 높은 지역을 식별할 수 있습니다.
잠재고객 발굴 쿼리 실행
이 그리드를 생성하기 위해 Places Insights 데이터 세트에서 제공하는 PLACES_COUNT_PER_H3 함수를 사용합니다 (장소 수 함수를 사용하여 Places Insights 쿼리에 대해 자세히 알아보기).
이 함수는 단일 작업에서 H3 그리드 셀의 관심 장소 수를 계산합니다.
다음 SQL 쿼리를 실행하여 단일 실행에서 세 단계를 수행합니다.
- H3 색인 생성 및 계산: JSON 구성 객체를 사용하여
PLACES_COUNT_PER_H3를 호출하여 런던 중심부에서 반경 25km 이내에 있는 모든 운영 장소를 찾습니다. 각 편의시설 유형 (헬스장, 학교 등)에 대해 별도로 쿼리하고UNION ALL를 사용하여 결합합니다. - 피벗(특성 추출): 머신러닝 모델은
gym_count,restaurant_count과 같은 고유한 특성 열을 예상하므로 셀을 그룹화하고 조건부 집계(SUM(IF(...)))를 사용하여 데이터를 올바른 스키마로 피벗합니다. - 예측: 이러한 피벗된 그리드 기능을
ML.PREDICT함수에 직접 입력하여 모든 동네의 실적 점수를 생성합니다.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
결과 해석
이 쿼리는 각 행이 런던의 육각형 영역을 나타내는 테이블을 반환합니다.
h3_index: 육각형 셀의 고유 식별자입니다.predicted_store_performance: 주변 환경만을 기반으로 이 셀에 있는 사이트에 대한 모델의 추정 점수입니다.h3_geography: 셀의 다각형 지오메트리입니다. 다음 단계에서 시각화에 사용됩니다.
값이 높을수록 학교, 헬스장, 대중교통의 밀도가 가장 성공적인 기존 사이트 주변에서 발견된 패턴과 일치하는 지역을 나타냅니다.
잠재고객 발굴 지도 시각화
데이터를 실행 가능하게 만들려면 지도에 결과를 시각화하세요. 표 형식 출력은 원시 점수를 제공하지만 지도에는 목록에서 명확하지 않은 높은 잠재력을 지닌 공간 클러스터와 회랑이 표시됩니다.
함께 제공되는 노트북에서는 geopandas 라이브러리를 사용하여 H3 다각형 지오메트리를 파싱하고 folium를 사용하여 대화형 지도를 렌더링합니다.
그 결과 모든 육각형 셀이 예측 점수에 따라 색상이 지정된 등치 지역도가 표시됩니다.
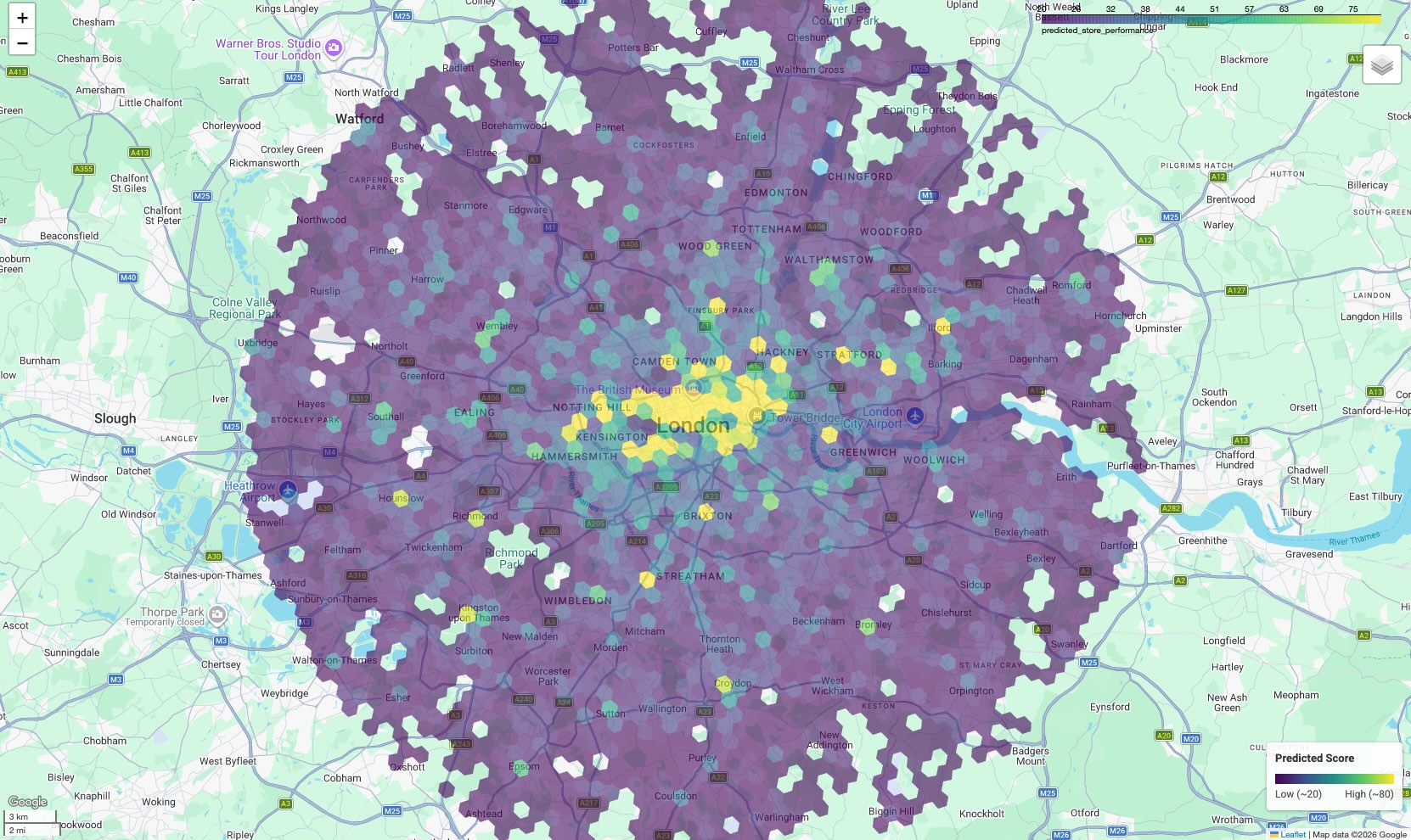
지도 해석:
- 핫스팟 (노란색/녹색): 예측 실적 점수가 높은 영역입니다. 성공적인 사이트와 상관관계가 있는 학교, 헬스장, 대중교통의 밀도가 최적입니다. 이러한 사이트는 새로운 사이트 선택의 주요 후보입니다.
- 콜드스팟 (보라색): 이 영역에는 실적이 우수한 직원 근처에서 발견되는 지원 환경 기능이 없습니다.
- 대화형 검사: 노트북 환경에서 셀 위로 마우스를 가져가면 해당 점수에 기여한 편의시설의 구체적인 수 (예: '헬스장: 12')를 확인할 수 있습니다.
결론
내부 운영 데이터와 장소 통계를 결합하여 사이트 실적을 진단했습니다. 모델 가중치를 분석하여 기존 측정항목과 상관관계가 있는 특정 동네 특성을 파악했습니다. H3 공간 색인 지정을 사용하여 이 분석을 수백 개 사이트에서 런던 전역의 수천 개 잠재적 동네로 확장했습니다.
다음 작업
- 기능 엔지니어링 확장: 틈새 오프라인 매장 방문 유도 요인을 파악하기 위해 검색어에 더 구체적인 장소 유형을 추가합니다.
- 고급 모델 탐색: 선형 회귀는 명확한 설명 가능성을 제공하지만 BigQuery ML에서
BOOSTED_TREE_REGRESSOR을 적절한 교차 검증 전략과 결합하여 비선형 관계를 포착해 보세요. - 지도 운영: Maps JavaScript API를 사용하여 H3 그리드 결과를 맞춤 대시보드로 내보내 팀과 통계를 공유합니다.
참여자
- Henrik Valve | DevX 엔지니어
- 게나디 돈치츠 | 스태프 고객 엔지니어