

人員配置、在庫、運用方法が同じなのに、あるサイトは好調で、別のサイトは不調なのはなぜでしょうか。複数のロケーションを持つ企業は、ポートフォリオ全体のパフォーマンスのばらつきを説明するのに苦労することがよくあります。通常、その理由は外部環境に隠されています。スポット(POI)データを活用することで、伝聞による説明ではなく、地域の競合店の密度や周辺地域の特性がサイトの成功をどのように左右するのかを正確に定量化できます。
このガイドでは、Places Insights と BigQuery ML を使用して、周辺環境がサイトの成功に与える影響を定量化する方法について説明します。独自のサイト パフォーマンス データと外部の地理空間シグナルを組み合わせて、パフォーマンスの要因を診断します。
ロンドンのサイトのデータセットを使用して、線形回帰モデルを構築します。このワークフローでは、H3 空間 インデックスを使用します。 このシステムは、都市を均一な六角形のセルに分割します。環境データをこれらのセルに集約することで、既存のサイトだけでなく、都市のあらゆる地域のパフォーマンスの可能性を予測するモデルをトレーニングできます。
学習内容は次のとおりです。
- 特徴量エンジニアリング: サイトから半径 500 メートル以内のジム、学校、交通機関の駅などのスポット(POI)の数を集計します。
- モデルのトレーニング: BigQuery ML を使用して、これらの環境の特徴量と内部のパフォーマンス指標を関連付ける回帰モデルを構築します。
- 都市のスコアリング: トレーニング済みのモデルをロンドンの H3 グリッド全体に適用して、将来の拡大の可能性が高いホットスポットを特定します。
BigQuery ML を初めて使用する場合は、BigQuery ML の概要で基本的なコンセプトとサポートされているモデルタイプをご確認ください。
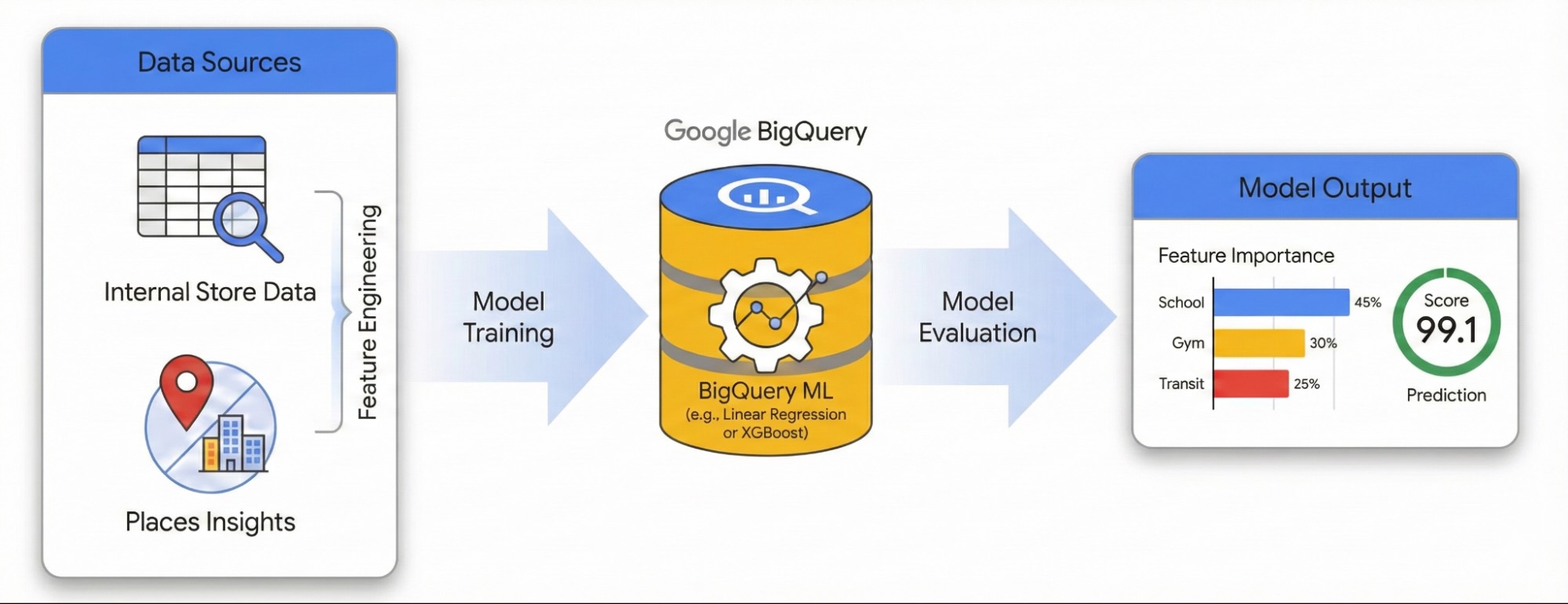
インタラクティブな環境でこのワークフローを試すには、次のノートブックを実行します。このノートブックでは、BigQuery ML で予測モデルを構築し、H3 空間インデックスを使用して都市全体の機会を可視化する方法を示します。
 [View source on GitHub]
[View source on GitHub]
前提条件
始める前に、次の準備をしてください。
Google Cloud プロジェクト:
- 課金を有効にした Google Cloud プロジェクト
データアクセス:
- BigQuery の Places Insights サブスクリプション 。
- パフォーマンス指標(収益など)を含むサイト ロケーションの独自のテーブル。サンプル データセットはチュートリアル リソースにあります。
Google Maps Platform:
- API キー。
- キーに対して次の API が有効になっていること。
Python 環境とライブラリ:
- Google Cloud コンソールの Colab Enterprise などの Python 環境。
- 次のライブラリがインストールされていること。
ライブラリ 説明 pandas-gbqBigQuery の操作。 geopandas地理空間データ オペレーションの処理。 foliumインタラクティブ マップの作成。 shapely幾何学的な操作。
IAM 権限:
- ユーザー アカウントまたはサービス アカウントに次の IAM
ロールがあることを確認します。
ロール ID BigQuery データ編集者 roles/bigquery.dataEditorBigQuery ユーザー roles/bigquery.user
- ユーザー アカウントまたはサービス アカウントに次の IAM
ロールがあることを確認します。
費用意識:
- このチュートリアルでは、課金対象の Google Cloud コンポーネントを使用します。次の項目に関連する費用が発生する可能性があります。
- BigQuery ML: 使用したコンピューティング スロットに対して課金されます。BigQuery ML の料金をご覧ください。
- Places Insights: クエリの使用量に基づいて課金されます。
- このチュートリアルでは、課金対象の Google Cloud コンポーネントを使用します。次の項目に関連する費用が発生する可能性があります。
Places Insights を使用した特徴量エンジニアリング
サイト パフォーマンスを左右する外部要因を特定するには、未加工のスポットデータを定量化可能な特徴量に変換する必要があります。各敷地から半径 500 メートル以内の特定の設備や場所のタイプ(ジム、学校、乗り継ぎ駅など)の密度を計算します。選択する 設備は、 ビジネスに最も関連すると思われるものによって異なります。
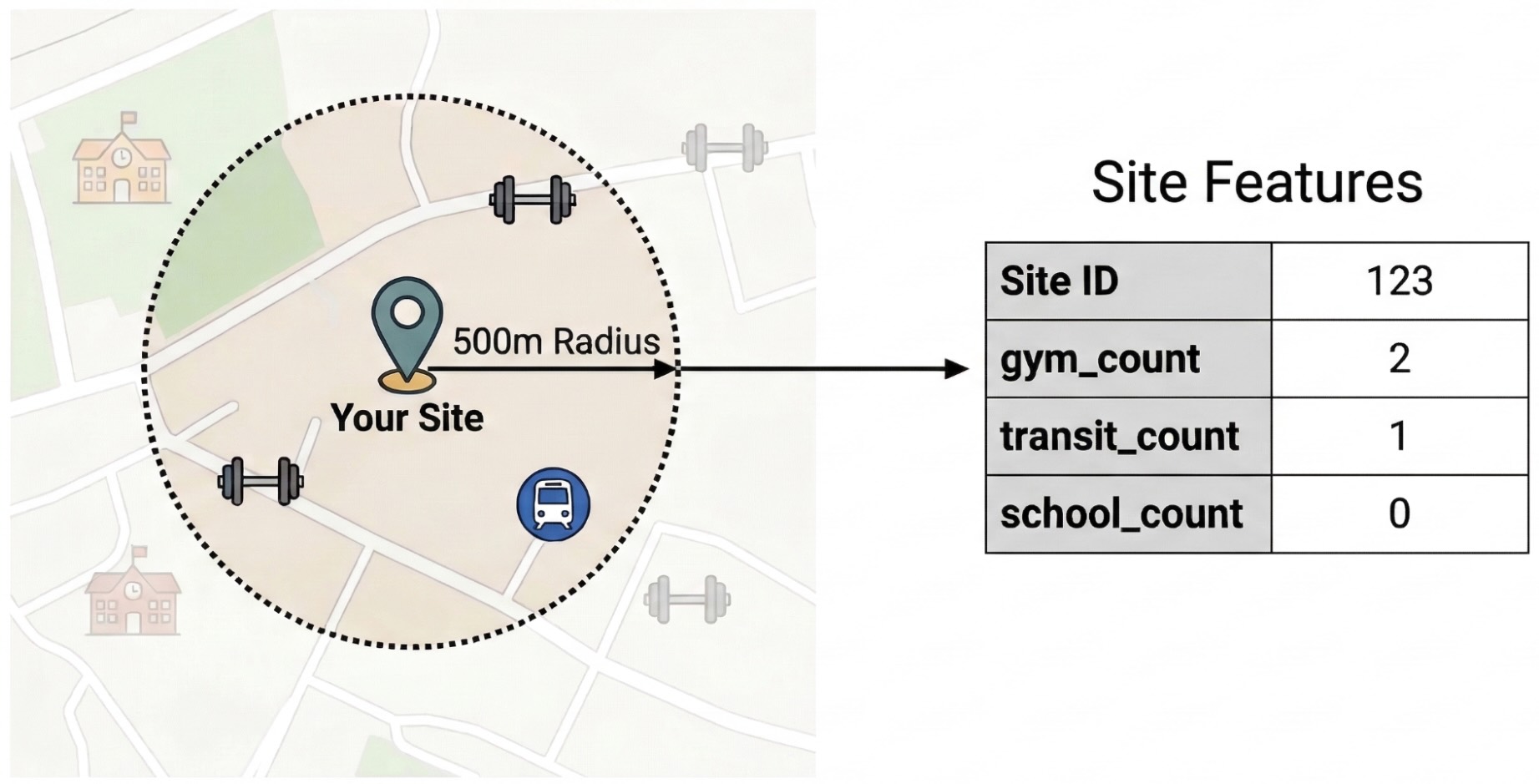
この手順では、Python と pandas-gbq ライブラリを使用します。この方法では、Places Insights データセットにアクセスするために必要な SELECT WITH AGGREGATION_THRESHOLD クエリを実行し、結果をプロジェクトの新しいテーブルに保存できます。Places Insights データの操作について詳しくは、データセットに直接クエリを実行するをご覧ください。
特徴量エンジニアリング クエリを実行する
環境(Colab Enterprise など)で次の Python スクリプトを実行します。このスクリプトは、内部サイトデータを Places Insights データセットに接続します。
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
クエリについて
ST_DWITHIN: この地理空間関数は、各サイト ロケーションの周囲に 500 メートルのバッファを作成し、その半径内にあるすべての Places Insights ポイントを特定します。COUNTIF: この関数は、各敷地の特定の場所のタイプ(「ジム」、「学校」など)の密度を計算します。これらのカウントは、ML モデルの入力特徴量(X)になります。pandas_gbq.to_gbq: この関数は、クエリ結果を新しいテーブル(site_features)に保存します。この永続テーブルは、BigQuery ML モデルのクリーンなトレーニング データセットとして機能します。
より高度な実際のアプリケーションでは、複数の距離(250 メートル、500 メートル、1 km など)で特徴量を計算し、rating、price_level、regular_opening_hours などの他の Places Insights 属性を調べることを検討してください。Places Insights 属性の完全なリストについては、
サポートされている場所のタイプと
コアスキーマ リファレンス
をご覧ください。
BigQuery ML でモデルをトレーニングする
設計された特徴量が site_features テーブルに保存されたので、
線形回帰
モデルをトレーニングできます。
このモデルは、各環境の特徴量(X)の最適な重み付け(β)を学習して、サイトのパフォーマンス(Y)を予測します。
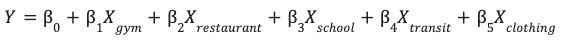
外れ値をロバスト スケーリングで処理する
地理空間データには、標準的な線形モデルを歪める可能性のある極端な外れ値が含まれていることがよくあります。たとえば、ロンドンのウェストエンドにあるサイトの半径 500 メートル以内には 200 件のレストランがありますが、郊外のサイトには 2 件しかありません。標準スケーリング(平均/標準偏差)を使用すると、外れ値(200)によって分布が歪み、モデルはその極端な値に適合することを優先します。
この問題を解決するため、モデル定義内でロバスト
スケーリング
(ML.ROBUST_SCALER)を使用します。この手法では、中央値と四分位範囲(IQR)に基づいて特徴量をスケーリングするため、モデルは外れ値に対して復元力があり、サイトの典型的な分布から学習できます。
モデルを作成する
BigQuery で次の SQL クエリを実行して、モデルを作成してトレーニングします。
TRANSFORM
句を使用して、すべての入力特徴量にロバスト スケーリングを適用します。また、
optimize_strategy = 'NORMAL_EQUATION'を設定します。これは、店舗
ロケーションの一般的なポートフォリオなど、比較的小さなデータセットに最も効率的な
トレーニング方法であるためです。最後に、パフォーマンスの高い外れ値(store_performance <
75)を除外して、モデルが典型的な成長パターンを予測するようにします。
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
モデルのパフォーマンスを評価する
サイト パフォーマンスを左右する要因に関するモデルの分析情報を信頼するには、予測が正確であることを確認する必要があります。
トレーニング後、ML.EVALUATE 関数を使用して、トレーニング中に使用されなかったデータの「ホールドアウト」セットに対してモデルの予測を評価します。
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
R2
スコア
(r2_score)と平均絶対
誤差
(mean_absolute_error)を確認して、モデルが本番環境で使用できる状態かどうかを判断します。
- R2 スコア は、パフォーマンスのばらつきのどの程度が外部環境要因(近くのスポット)によって実際に説明されるかを測定します。R2 スコアが 0.70 の場合、サイトの成功の 70% がローカル環境に関連していることを意味します。1.0 に近いほど、環境施設とサイト パフォーマンスの相関関係が強くなります。
- MAE は、ポイントの平均誤差を示します。たとえば、MAE が 1.5 の場合、モデルの予測は通常、実際のパフォーマンス スコアの +/- 1.5 ポイント以内であることを意味します。
スコアが低い場合のトラブルシューティング
R2 スコアが低い場合は、次の改善策を検討してください。
- 特徴量のタイプを増やす: クエリにさまざまな場所のタイプ
(例:
tourist_attraction、subway_station)を追加します。 - 集客範囲を調整する:
ST_DWITHINの距離を変更します。半径 500 メートルは、コーヒー ショップには広すぎる可能性がありますが、家具店には小さすぎる可能性があります。 - データサイズを増やす: 統計的有意性のあるパターンを見つけるのに十分な店舗所在地でトレーニングしていることを確認します。
H3 空間インデックスを使用して都市をスコアリングする
H3 空間インデックスを使用して、ロンドンの都市を六角形のセル(解像度 8、約 0.7 km²)の均一なグリッドに分割します。Places Insights データをこれらのセルに集約することで、トレーニング済みのモデルをすべての地域に適用し、パフォーマンスの高いサイトの環境プロファイルに一致する可能性の高いエリアを特定できます。
プロスペクティング クエリを実行する
このグリッドを生成するには、Places Insights データセットで提供される
PLACES_COUNT_PER_H3
関数を使用します(Places Count
関数を使用した Places Insights の
クエリの詳細)。この関数は、1 回のオペレーションで H3 グリッドセルのスポット数を計算します。
次の SQL クエリを実行して、1 回の実行で次の 3 つの手順を行います。
- H3 インデックスとカウント: JSON 構成オブジェクトを使用して
PLACES_COUNT_PER_H3を呼び出し、ロンドン中心部から半径 25 km 以内のすべての営業中の場所を検索します。このクエリは、施設タイプ(ジム、学校など)ごとに個別に実行し、UNION ALLを使用して結合します。 - ピボット(特徴量エンジニアリング): ML モデルは個別の特徴量列(
gym_count、restaurant_countなど)を想定しているため、セルをグループ化し、条件付き集計(SUM(IF(...)))を使用してデータを正しいスキーマにピボットします。 - 予測: これらのピボットされたグリッドの特徴量を
ML.PREDICT関数に直接フィードして、地域ごとにパフォーマンス スコアを生成します。
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
検索結果を解釈する
クエリは、各行がロンドンの六角形の領域を表すテーブルを返します。
h3_index: 六角形のセルの一意の識別子。predicted_store_performance: 周辺環境のみに基づいて、このセルにある敷地のモデルの推定スコア。h3_geography: セルのポリゴン ジオメトリ。次のステップで可視化に使用します。
値が高いほど、学校、ジム、交通機関の密度が、最も成功している既存のサイトの周辺で見られるパターンと一致していることを示します。
プロスペクティング マップを可視化する
データを実用的なものにするには、地図上に結果を可視化します。表形式の出力には未加工のスコアが表示されますが、地図には、リストではわかりにくい、可能性の高い空間クラスタと回廊が表示されます。
付属のノートブックでは、geopandas ライブラリを使用して H3 ポリゴン ジオメトリを解析し、folium を使用してインタラクティブ マップをレンダリングします。
結果は、六角形のセルごとに予測スコアに応じて色分けされた階級区分図になります。
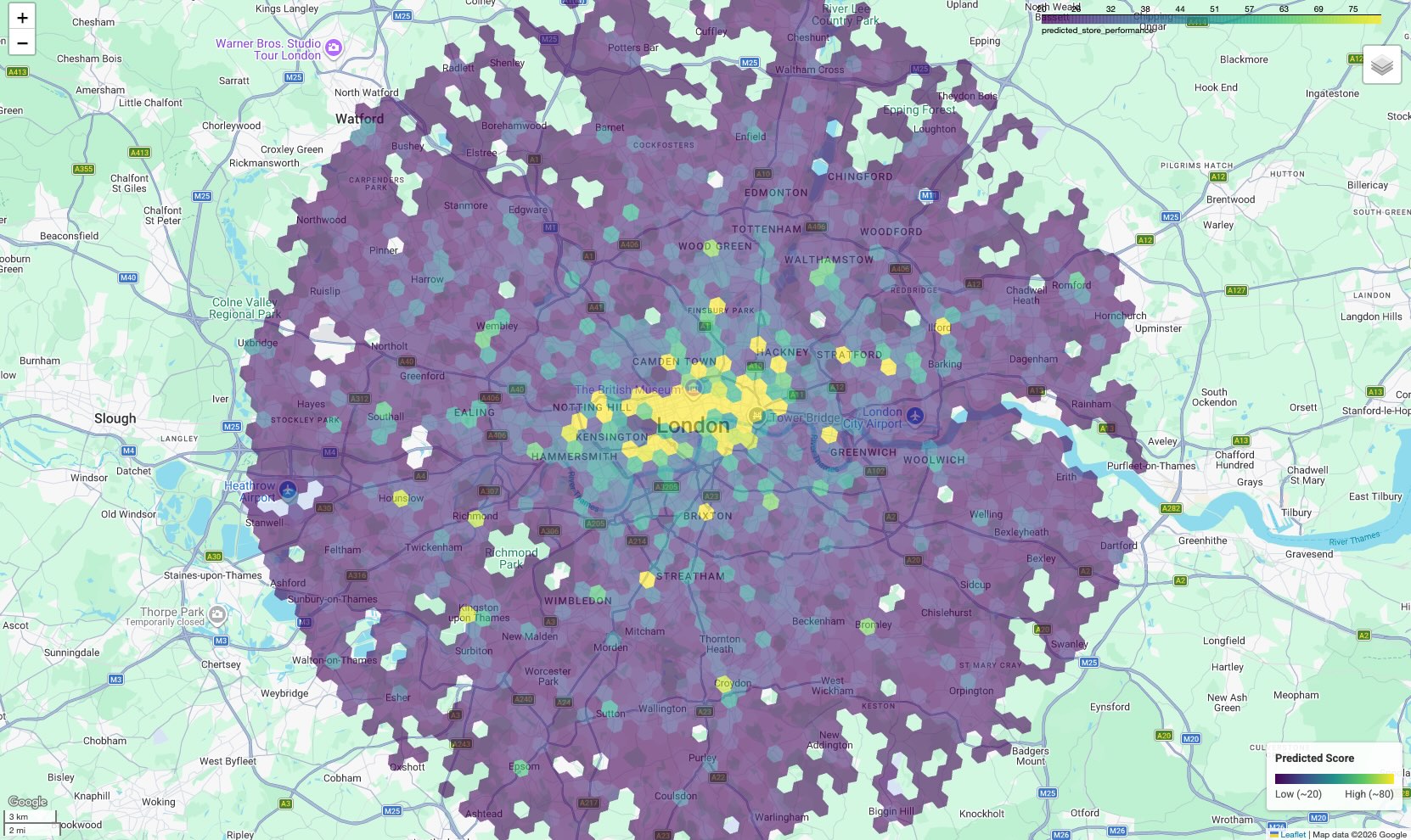
地図を解釈する:
- ホットスポット(黄色/緑色): これらのエリアは、予測パフォーマンス スコアが高くなっています。成功したサイトと相関する学校、ジム、交通機関の最適な密度を備えています。新しいサイトの選択に最適な候補です。
- コールドスポット(紫): これらのエリアには、パフォーマンスの高いサイトの近くにある環境の特徴がありません。
- インタラクティブな検査: ノートブック環境では、セルにカーソルを合わせると、その特定のスコアに寄与した設備の具体的な数(「ジム: 12」など)を確認できます。
まとめ
内部の運用データと Places Insights を組み合わせて、サイト パフォーマンスを診断できました。モデルの重みを分析することで、既存の指標と相関する特定の地域の特性を特定しました。H3 空間インデックスを使用して、この分析を数百のサイトからロンドン全体の数千の潜在的な地域に拡大しました。
次の対策
- 特徴量エンジニアリングを拡張する: クエリにさらに具体的な場所のタイプを追加して、ニッチな来店要因を把握します。
- 高度なモデルを調べる: 線形回帰は明確な
説明可能性を提供しますが、BigQuery ML で
BOOSTED_TREE_REGRESSORを適切な交差検証戦略と組み合わせて、 非線形関係を把握します。 - 地図を運用する: Maps JavaScript API を使用して H3 グリッドの結果をカスタム ダッシュボードにエクスポートし、これらの分析情報をチームと共有します。
コントリビューター
- Henrik Valve | DevX エンジニア
- Gennadii Donchyts | スタッフ カスタマー エンジニア