

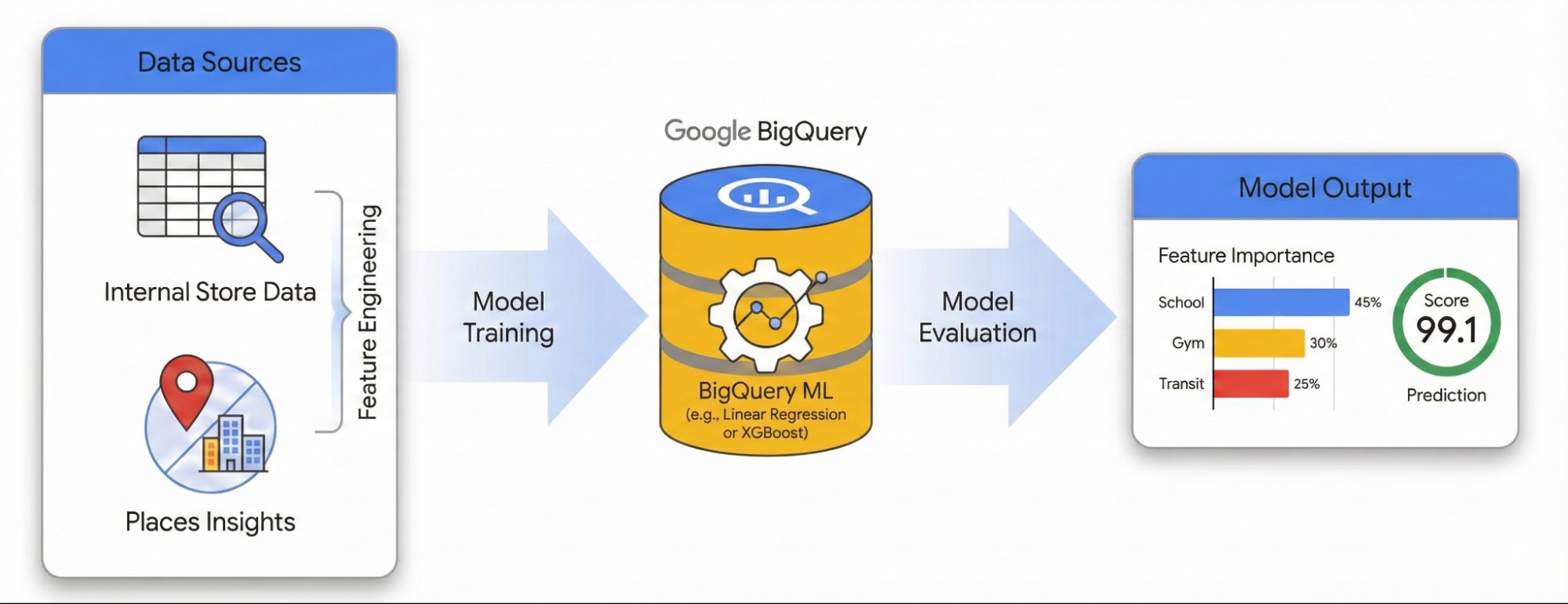
Perché un sito prospera mentre un altro ha un rendimento inferiore nonostante personale, inventario e pratiche operative coerenti? Le attività con più sedi spesso faticano a spiegare questa variazione di rendimento nel loro portafoglio. La risposta di solito si nasconde nell'ambiente esterno. Sfruttando i dati sui punti di interesse (POI), possiamo andare oltre le spiegazioni aneddotiche e quantificare esattamente in che modo la densità competitiva locale e le caratteristiche del quartiere determinano il successo di un sito.
Questa guida mostra come quantificare l'impatto dell'ambiente locale sul successo del sito utilizzando Places Insights e BigQuery ML. Combinerai i dati sulle prestazioni del sito proprietario con indicatori geospaziali esterni per diagnosticare i fattori che determinano il rendimento.
Utilizzeremo un set di dati di siti a Londra per creare un modello di regressione lineare. Questo workflow utilizza l'indicizzazione spaziale H3, un sistema che divide la città in celle esagonali uniformi. Aggregando i dati ambientali in queste celle, puoi addestrare un modello per prevedere il potenziale di rendimento di qualsiasi quartiere della città, non solo dei siti esistenti.
Imparerai a:
- Eseguire il feature engineering: aggregare i conteggi dei punti di interesse (POI) come palestre, scuole e stazioni di transito in un raggio di 500 metri dai tuoi siti.
- Addestrare un modello: utilizzare BigQuery ML per creare un modello di regressione che correli queste caratteristiche ambientali con le metriche sul rendimento interno.
- Valutare la città: applicare il modello addestrato all'intera griglia H3 di Londra per identificare gli hotspot ad alto potenziale per l'espansione futura.
Se non hai familiarità con BigQuery ML, consulta Introduzione a BigQuery ML per scoprire i concetti di base e i tipi di modelli supportati.
Per esplorare questo workflow in un ambiente interattivo, esegui il seguente notebook. Mostra come creare un modello predittivo con BigQuery ML e visualizzare le opportunità a livello di città utilizzando l'indicizzazione spaziale H3.
 Visualizza il codice sorgente in GitHub
Visualizza il codice sorgente in GitHub
Prerequisiti
Prima di iniziare, assicurati di avere quanto segue:
Progetto Google Cloud:
- Un progetto Google Cloud con la fatturazione abilitata.
Accesso ai dati:
- Abbonamento a Places Insights in BigQuery.
- Una tabella personalizzata delle sedi dei siti con una metrica sul rendimento (ad es. entrate). Un set di dati di esempio è disponibile nelle risorse del tutorial.
Google Maps Platform:
- Una chiave API.
- Le seguenti API abilitate per la chiave:
Ambiente e librerie Python:
- Un ambiente Python come Colab Enterprise nella console Google Cloud.
- Le seguenti librerie installate:
Libreria Descrizione pandas-gbqInterazione con BigQuery. geopandasGestione delle operazioni sui dati geospaziali. foliumCreazione di mappe interattive. shapelyManipolazioni geometriche.
Autorizzazioni IAM:
- Assicurati che l'utente o il service account disponga dei seguenti ruoli IAM:
Ruolo ID BigQuery Data Editor roles/bigquery.dataEditorUtente BigQuery roles/bigquery.user
- Assicurati che l'utente o il service account disponga dei seguenti ruoli IAM:
Consapevolezza dei costi:
- Questo tutorial utilizza i componenti fatturabili di Google Cloud. Tieni presente i potenziali costi relativi a:
- BigQuery ML: addebito per gli slot di calcolo utilizzati. Consulta Prezzi di BigQuery ML.
- Places Insights: addebito in base all'utilizzo delle query.
- Questo tutorial utilizza i componenti fatturabili di Google Cloud. Tieni presente i potenziali costi relativi a:
Feature engineering con Places Insights
Per isolare i fattori esterni che determinano le prestazioni del sito, devi trasformare i dati PDI non elaborati in caratteristiche quantificabili. Calcolerai la densità di servizi o tipi di luoghi specifici, come palestre, scuole e stazioni di transito, in un raggio di 500 metri da ogni sito. I servizi selezionati saranno dipendenti da ciò che ritieni possa essere più pertinente per la tua attività.
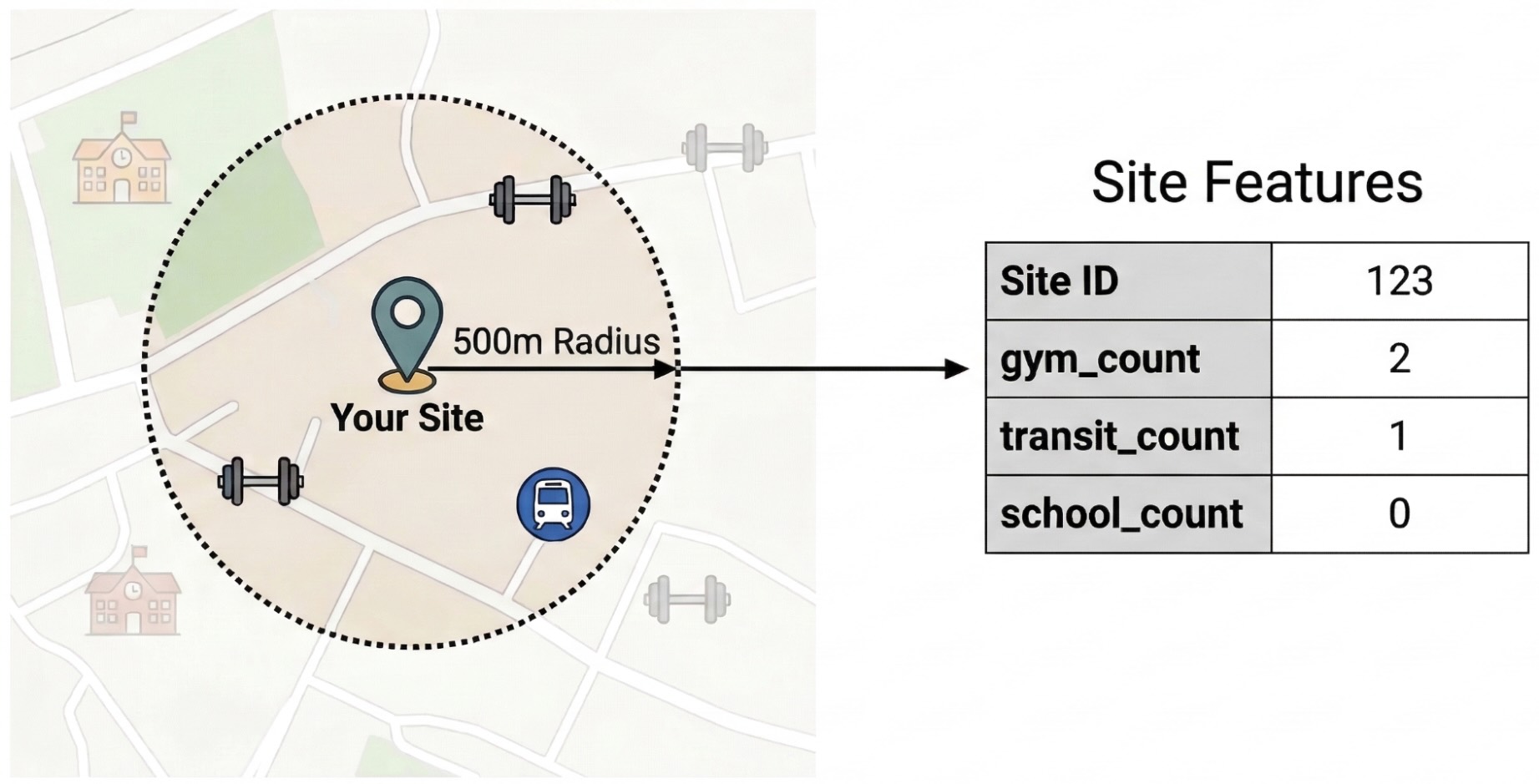
Per questo passaggio utilizziamo Python e la libreria pandas-gbq. Questo approccio ti consente di eseguire la query SELECT WITH AGGREGATION_THRESHOLD, necessaria per accedere al set di dati Places Insights, e di salvare i risultati in una nuova tabella nel tuo progetto. Per ulteriori informazioni sull'utilizzo dei dati di Places Insights, consulta Eseguire query direttamente sul set di dati
.
Eseguire la query di feature engineering
Esegui il seguente script Python nel tuo ambiente (ad es. Colab Enterprise). Questo script collega i dati interni del sito al set di dati Places Insights.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Comprendere la query
ST_DWITHIN: questa funzione geospaziale crea un buffer di 500 metri intorno a ogni sede del sito e identifica tutti i punti di Places Insights che rientrano in questo raggio.COUNTIF: questa funzione calcola la densità di tipi di luoghi specifici (ad es. "palestra", "scuola") per ogni sito. Questi conteggi diventano le caratteristiche di input (X) per il modello di machine learning.pandas_gbq.to_gbq: questa funzione salva i risultati della query in una nuova tabella (site_features). Questa tabella permanente funge da set di dati di addestramento pulito per il modello BigQuery ML.
Per applicazioni reali più avanzate, valuta la possibilità di calcolare le caratteristiche a più distanze (ad es. 250 m, 500 m, 1 km) ed esplorare altri attributi di Places Insights come rating, price_level o regular_opening_hours. Per l'elenco completo degli attributi di Places Insights, consulta i
tipi di luoghi supportati e il
riferimento allo schema principale.
Addestrare il modello con BigQuery ML
Dopo aver salvato le caratteristiche di feature engineering nella tabella site_features, puoi ora
addestrare un modello di regressione
lineare.
Questo modello apprende i pesi ottimali (β) per ogni caratteristica ambientale (X) per prevedere il rendimento del sito (Y).
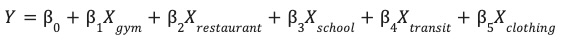
Gestire i valori anomali con la scalabilità robusta
I dati geospaziali spesso contengono valori anomali estremi che possono distorcere i modelli lineari standard. Ad esempio, un sito nel West End di Londra potrebbe avere 200 ristoranti in un raggio di 500 metri, mentre un sito suburbano ne ha solo 2. Se utilizzi la scalabilità standard (media/deviazione standard), il valore anomalo (200) distorce la distribuzione e costringe il modello a dare la priorità all'adattamento a questo valore estremo.
Per risolvere questo problema, utilizziamo Scalabilità
Robusta
(ML.ROBUST_SCALER) all'interno della definizione del modello. Questa tecnica scala le caratteristiche in base alla mediana e all'intervallo interquartile (IQR), rendendo il modello resiliente ai valori anomali e garantendo che apprenda dalla distribuzione tipica dei tuoi siti.
Creare il modello
Esegui la seguente query SQL in BigQuery per creare e addestrare il modello.
Utilizziamo la
TRANSFORM
clausola per applicare la scalabilità robusta a tutte le caratteristiche di input. Impostiamo anche
optimize_strategy = 'NORMAL_EQUATION' perché è il metodo di addestramento più efficiente
per set di dati relativamente piccoli, come un portafoglio tipico di sedi di negozi. Infine, filtriamo i valori anomali con rendimento elevato (store_performance <
75) per concentrare il modello sulla previsione dei pattern di crescita tipici.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Valutare il rendimento del modello
Prima di poter considerare affidabili gli approfondimenti del modello sui fattori che determinano le prestazioni del sito, devi verificare che le previsioni siano accurate.
Dopo l'addestramento, utilizza la funzione ML.EVALUATE per valutare le previsioni del modello rispetto a un set di dati "holdout" che non è stato utilizzato durante l'addestramento.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Controlla il punteggio
R2
(r2_score) e l'errore assoluto
medio
(mean_absolute_error) per determinare se il modello è pronto per la produzione:
- Un punteggio R2 misura la quantità di varianza del rendimento effettivamente spiegata dai fattori ambientali esterni (POI nelle vicinanze). Un punteggio R2 di 0,70 significa che il 70% del successo di un sito è legato all'ambiente locale. Più il valore è vicino a 1,0, più forte è la correlazione tra i servizi ambientali e le prestazioni del sito.
- L'errore assoluto medio indica l'errore medio in punti. Ad esempio, un errore assoluto medio di 1,5 significa che le previsioni del modello sono in genere entro +/- 1,5 punti del punteggio di rendimento effettivo.
Risolvere i problemi relativi a punteggi bassi
Se il punteggio R2 è basso, valuta la possibilità di apportare i seguenti miglioramenti:
- Espandere i tipi di caratteristiche: aggiungi diversi tipi di luoghi
alla query (ad es.
tourist_attraction,subway_station). - Regolare il raggio di influenza: modifica la distanza
ST_DWITHIN. Un raggio di 500 metri potrebbe essere troppo ampio per una caffetteria, ma troppo piccolo per un negozio di arredamento. - Aumentare le dimensioni dei dati: assicurati di addestrare un numero sufficiente di sedi di negozi per trovare un pattern statisticamente significativo.
Valutare la città con l'indicizzazione spaziale H3
Utilizziamo l'indicizzazione spaziale H3 per dividere la città di Londra in una griglia uniforme di celle esagonali (risoluzione 8, circa 0,7 km²). Aggregando i dati di Places Insights in queste celle, possiamo applicare il modello addestrato a ogni quartiere, identificando le aree ad alto potenziale che corrispondono al profilo ambientale dei siti con il rendimento migliore.
Eseguire la query di prospezione
Per generare questa griglia, utilizziamo la
PLACES_COUNT_PER_H3
funzione fornita dal set di dati Places Insights (scopri di più sull'esecuzione di query
su Places Insights utilizzando le funzioni di conteggio dei luoghi).
Questa funzione calcola i conteggi dei POI per le celle della griglia H3 in una singola operazione.
Esegui la seguente query SQL per eseguire tre passaggi in una singola esecuzione:
- Indicizzazione e conteggio H3: chiamiamo
PLACES_COUNT_PER_H3utilizzando un oggetto di configurazione JSON per trovare tutti i luoghi operativi in un raggio di 25 km dal centro di Londra. Eseguiamo query separate per ogni tipo di servizio (palestre, scuole e così via) e le combiniamo utilizzandoUNION ALL. - Pivot (feature engineering): poiché il nostro modello di machine learning prevede colonne di caratteristiche distinte (come
gym_counterestaurant_count), raggruppiamo le celle e utilizziamo l'aggregazione condizionale(SUM(IF(...)))per eseguire il pivot dei dati nello schema corretto. - Previsione: inseriamo queste caratteristiche della griglia in pivot direttamente nella funzione
ML.PREDICTper generare un punteggio di rendimento per ogni quartiere.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Interpretare i risultati
La query restituisce una tabella in cui ogni riga rappresenta un'area esagonale di Londra.
h3_index: l'identificatore univoco della cella esagonale.predicted_store_performance: il punteggio stimato del modello per un sito situato in questa cella, basato esclusivamente sull'ambiente circostante.h3_geography: la geometria del poligono della cella, che utilizzeremo per la visualizzazione nel passaggio successivo.
I valori elevati indicano le aree in cui la densità di scuole, palestre e trasporti corrisponde ai pattern riscontrati intorno ai siti esistenti di maggior successo.
Visualizzare la mappa di individuazione di potenziali clienti
Per rendere i dati utilizzabili, visualizza i risultati su una mappa. Sebbene l'output tabulare fornisca punteggi non elaborati, una mappa rivela cluster spaziali e corridoi ad alto potenziale che non sono evidenti in un elenco.
Nel notebook di accompagnamento, utilizziamo la libreria geopandas per analizzare la geometria del poligono H3 e folium per eseguire il rendering di una mappa interattiva.
Il risultato è una mappa coropletica in cui ogni cella esagonale è colorata in base al punteggio previsto.
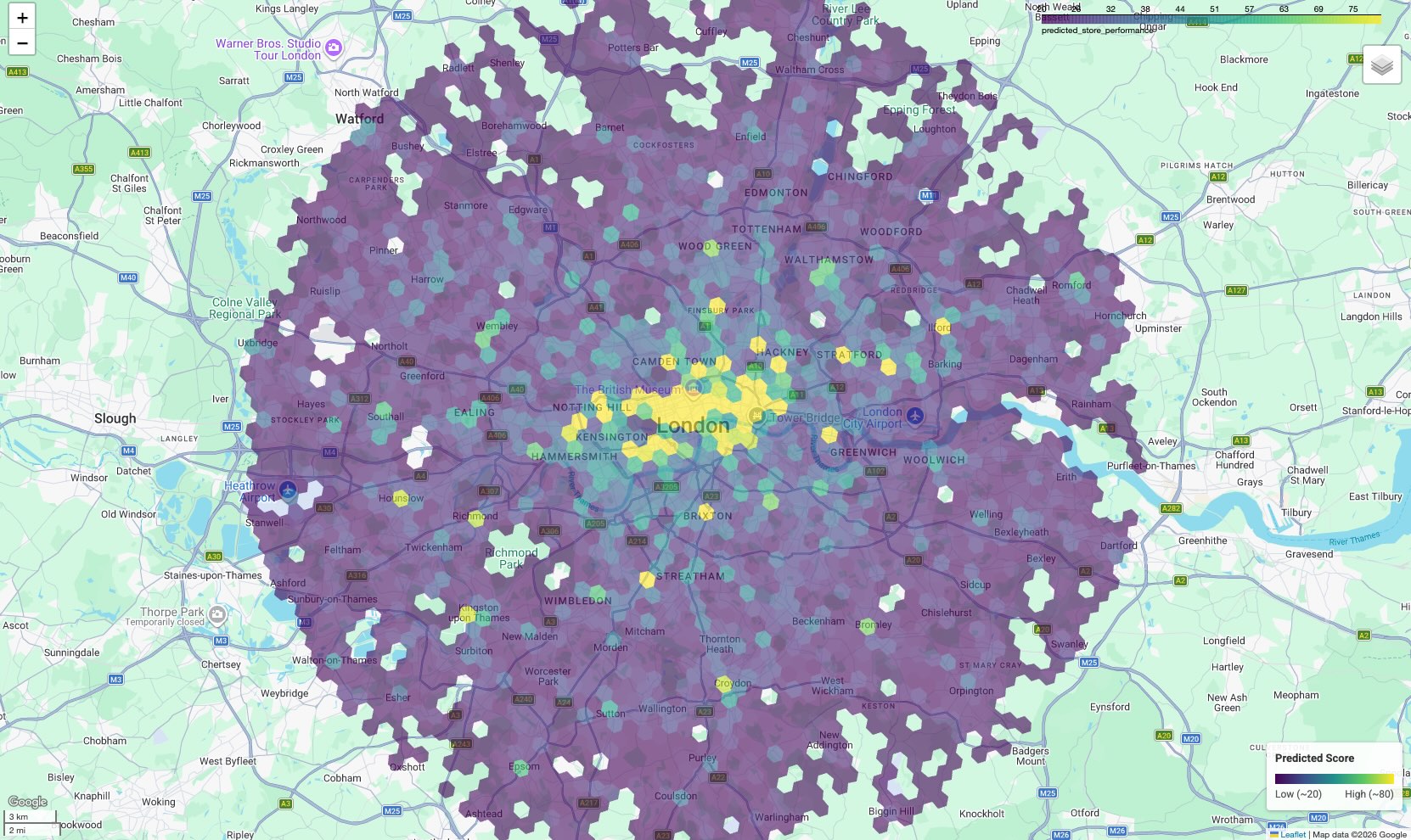
Interpretare la mappa:
- Hotspot (giallo/verde): queste aree hanno punteggi di rendimento previsti elevati. Possiedono la densità ottimale di scuole, palestre e trasporti che è correlata ai tuoi siti di successo. Questi sono i candidati ideali per la selezione di nuovi siti.
- Coldspot (viola): queste aree non dispongono delle caratteristiche ambientali di supporto presenti vicino ai tuoi siti con il rendimento migliore.
- Ispezione interattiva: nell'ambiente del notebook, puoi passare il mouse sopra una cella per visualizzare i conteggi specifici dei servizi (ad es. "Palestre: 12") che hanno contribuito a quel punteggio specifico.
Conclusione
Hai combinato correttamente i dati operativi interni con Places Insights per diagnosticare il rendimento del sito. Analizzando i pesi del modello, hai identificato le caratteristiche specifiche del quartiere che sono correlate alle metriche esistenti. Utilizzando l'indicizzazione spaziale H3, hai scalato questa analisi da poche centinaia di siti a migliaia di potenziali quartieri di Londra.
Azioni successive
- Espandere il feature engineering: aggiungi tipi di luoghi più specifici Tipi di luoghi alla query per acquisire i fattori di nicchia delle visite nei punti vendita.
- Esplorare i modelli avanzati: sebbene la regressione lineare fornisca una chiara
spiegabilità, sperimenta
BOOSTED_TREE_REGRESSORin BigQuery ML combinato con una strategia di convalida incrociata appropriata per acquisire relazioni non lineari. - Operazionalizzare la mappa: esporta i risultati della griglia H3 in una dashboard personalizzata utilizzando l'API Maps JavaScript per condividere questi approfondimenti con il tuo team.
Collaboratori
- Henrik Valve | DevX Engineer
- Gennadii Donchyts | Staff Customer Engineer