

Mengapa satu situs berkembang pesat sementara situs lain berperforma buruk meskipun memiliki staf, inventaris, dan praktik operasional yang konsisten? Bisnis dengan beberapa lokasi sering kali kesulitan menjelaskan variasi performa ini di seluruh portofolio mereka. Jawabannya biasanya tersembunyi di lingkungan eksternal. Dengan memanfaatkan data tempat menarik (POI), kita dapat melampaui penjelasan anekdotal dan mengukur secara tepat bagaimana kepadatan persaingan lokal dan karakteristik lingkungan menentukan keberhasilan situs.
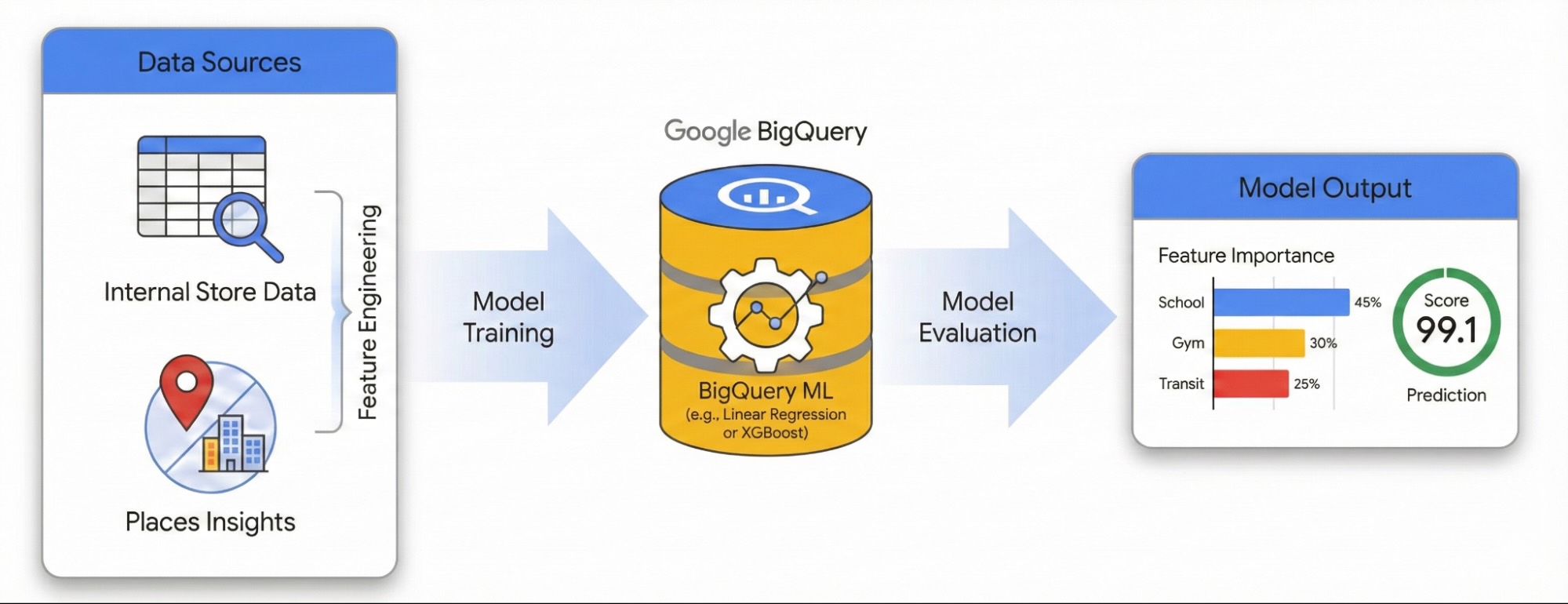
Panduan ini menunjukkan cara mengukur dampak lingkungan sekitar lokal terhadap kesuksesan situs menggunakan Places Insights dan BigQuery ML. Anda akan menggabungkan data performa situs eksklusif dengan sinyal geospasial eksternal untuk mendiagnosis pendorong performa.
Kita akan menggunakan set data situs di London untuk membangun model Regresi Linear. Alur kerja ini memanfaatkan Pengindeksan Spasial H3, sistem ini membagi kota menjadi sel heksagonal yang seragam. Dengan menggabungkan data lingkungan ke dalam sel ini, Anda dapat melatih model untuk memprediksi potensi performa lingkungan mana pun di kota, bukan hanya situs yang sudah ada.
Anda akan mempelajari cara:
- Fitur Rekayasa: Menggabungkan jumlah Lokasi Menarik (POI) seperti gym, sekolah, dan stasiun transportasi umum dalam radius 500 meter dari situs Anda.
- Melatih Model: Gunakan BigQuery ML untuk membuat model regresi yang mengorelasikan fitur lingkungan ini dengan metrik performa internal Anda.
- Menilai Kota: Terapkan model terlatih ke seluruh petak H3 London untuk mengidentifikasi hotspot berpotensi tinggi untuk ekspansi di masa mendatang.
Jika Anda baru menggunakan BigQuery ML, lihat Pengantar BigQuery ML untuk mempelajari konsep inti dan jenis model yang didukung.
Untuk mempelajari alur kerja ini di lingkungan interaktif, jalankan notebook berikut. Modul ini menunjukkan cara membangun model prediktif dengan BigQuery ML dan memvisualisasikan peluang di seluruh kota menggunakan pengindeksan spasial H3.
 Lihat sumber di GitHub
Lihat sumber di GitHub
Prasyarat
Sebelum memulai, pastikan Anda memiliki hal-hal berikut:
Project Google Cloud:
- Project Google Cloud yang mengaktifkan penagihan.
Akses Data:
- Langganan Places Insights di BigQuery.
- Tabel lokasi situs Anda sendiri dengan metrik performa (misalnya, pendapatan). Contoh set data ada di tutorial resources.
Google Maps Platform:
- Kunci API.
- API berikut diaktifkan untuk kunci Anda:
Lingkungan & Library Python:
- Lingkungan Python seperti Colab Enterprise di Konsol Google Cloud.
- Library berikut diinstal:
Koleksi Deskripsi pandas-gbqBerinteraksi dengan BigQuery. geopandasMenangani operasi data geospasial. foliumMembuat peta interaktif. shapelyManipulasi geometris.
Izin IAM:
- Pastikan akun pengguna atau akun layanan Anda memiliki peran
IAM berikut:
Peran ID Editor Data BigQuery roles/bigquery.dataEditorBigQuery User roles/bigquery.user
- Pastikan akun pengguna atau akun layanan Anda memiliki peran
IAM berikut:
Kesadaran Biaya:
- Tutorial ini menggunakan komponen Google Cloud yang dapat ditagih. Perhatikan potensi biaya terkait:
- BigQuery ML: Ditagih untuk slot komputasi yang digunakan. Lihat harga BigQuery ML.
- Insight Tempat: Ditagih berdasarkan penggunaan kueri.
- Tutorial ini menggunakan komponen Google Cloud yang dapat ditagih. Perhatikan potensi biaya terkait:
Rekayasa Fitur dengan Insight Tempat
Untuk mengisolasi faktor eksternal yang mendorong performa situs, Anda harus mengubah data POI mentah menjadi fitur yang dapat diukur. Anda akan menghitung kepadatan fasilitas atau jenis tempat tertentu seperti pusat kebugaran, sekolah, dan stasiun transit dalam radius 500 meter dari setiap situs. Fasilitas yang Anda pilih akan bergantung pada apa yang Anda yakini paling relevan untuk bisnis Anda.
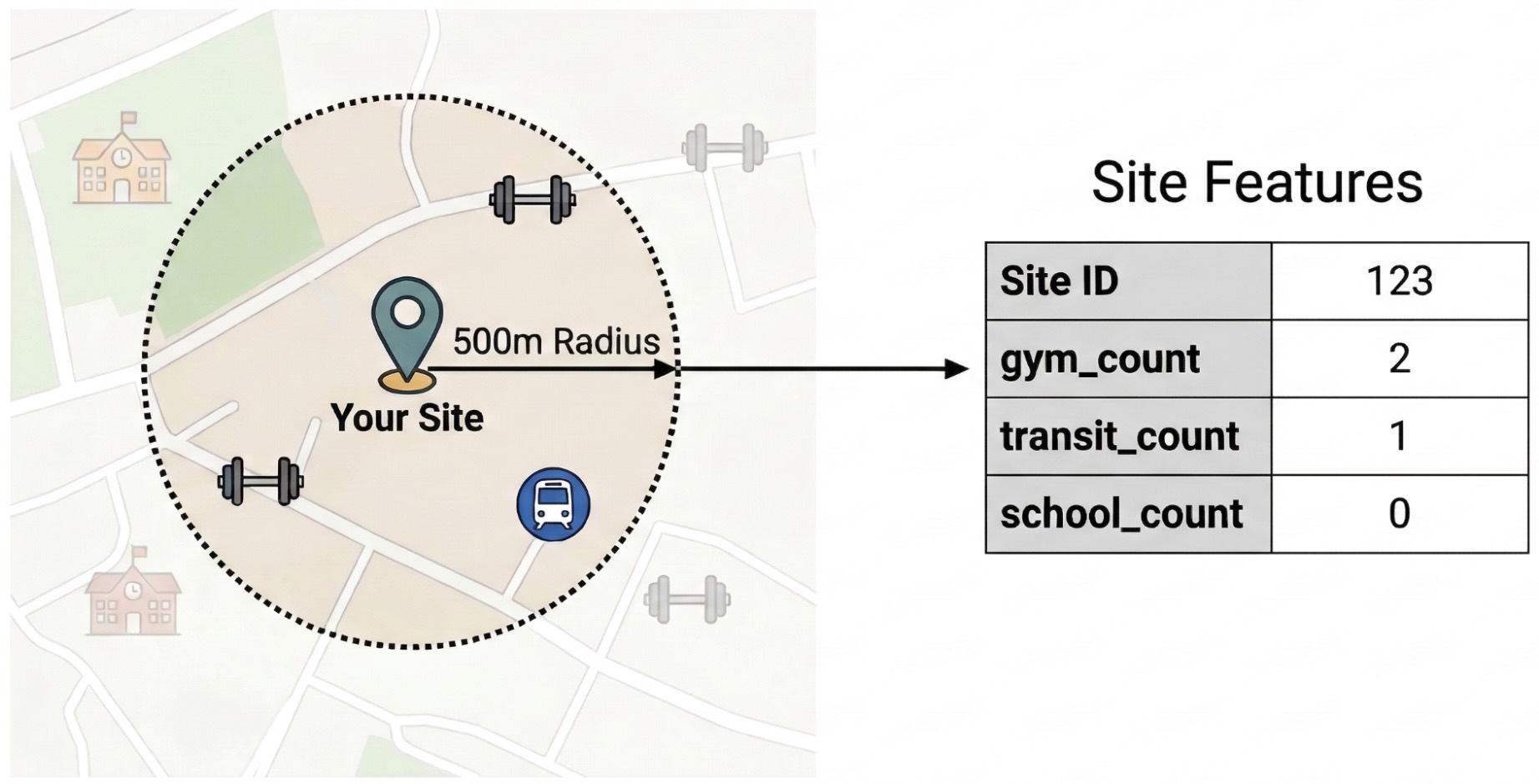
Kita menggunakan Python dan library pandas-gbq untuk langkah ini. Pendekatan ini memungkinkan Anda menjalankan kueri SELECT WITH AGGREGATION_THRESHOLD, yang diperlukan untuk mengakses set data Insight Tempat, dan menyimpan hasilnya ke tabel baru dalam project Anda. Lihat Mengirim kueri set data secara langsung untuk mengetahui informasi selengkapnya tentang cara menggunakan data Insight Tempat.
Menjalankan Kueri Rekayasa Fitur
Jalankan skrip Python berikut di lingkungan Anda (misalnya, Colab Enterprise). Skrip ini menghubungkan data situs internal Anda dengan set data Places Insights.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Memahami Kueri
ST_DWITHIN: Fungsi geospasial ini membuat buffer 500 meter di sekitar setiap lokasi situs dan mengidentifikasi semua titik Places Insights yang berada dalam radius tersebut.COUNTIF: Fungsi ini menghitung kepadatan jenis tempat tertentu (misalnya, 'gym', 'sekolah') untuk setiap situs. Jumlah ini menjadi fitur input (X) untuk model machine learning.pandas_gbq.to_gbq: Fungsi ini menyimpan hasil kueri ke dalam tabel baru (site_features). Tabel permanen ini berfungsi sebagai set data pelatihan bersih untuk model BigQuery ML.
Untuk aplikasi dunia nyata yang lebih canggih, pertimbangkan untuk menghitung fitur pada beberapa jarak (misalnya, 250 m, 500 m, 1 km) dan menjelajahi atribut Places Insights lainnya seperti rating, price_level, atau regular_opening_hours. Lihat
jenis tempat yang didukung dan
referensi skema inti
untuk mengetahui daftar lengkap atribut Insight Tempat.
Melatih Model dengan BigQuery ML
Dengan fitur yang telah direkayasa dan disimpan dalam tabel site_features, Anda kini dapat melatih model Linear
Regression.
Model ini mempelajari bobot optimal (β) untuk setiap fitur lingkungan (X) guna memprediksi performa situs Anda (Y).
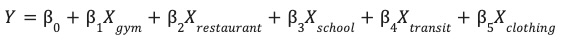
Menangani Pencilan dengan Penskalaan yang Kuat
Data geospasial sering kali berisi pencilan ekstrem yang dapat mendistorsi model linear standar. Misalnya, situs di West End, London, mungkin memiliki 200 restoran dalam radius 500 meter, sementara situs di pinggiran kota hanya memiliki 2 restoran. Jika Anda menggunakan penskalaan standar (Rata-Rata/Standar Deviasi), pencilan (200) akan memiringkan distribusi dan memaksa model untuk memprioritaskan penyesuaian nilai ekstrem tersebut.
Untuk mengatasinya, kita menggunakan Robust
Scaling
(ML.ROBUST_SCALER) dalam definisi model. Teknik ini menskalakan fitur berdasarkan Median dan Rentang Interkuartil (IQR), sehingga model menjadi tangguh terhadap pencilan dan memastikan model belajar dari distribusi umum situs Anda.
Membuat Model
Jalankan kueri SQL berikut di BigQuery untuk membuat dan melatih model.
Kita menggunakan klausa
TRANSFORM
untuk menerapkan penskalaan yang kuat ke semua fitur input. Kami juga menetapkan
optimize_strategy = 'NORMAL_EQUATION' karena merupakan metode pelatihan
paling efisien untuk set data yang relatif kecil, seperti portofolio lokasi
toko pada umumnya. Terakhir, kami memfilter pencilan berperforma tinggi (store_performance <
75) untuk memfokuskan model pada prediksi pola pertumbuhan umum.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Mengevaluasi Performa Model
Sebelum Anda dapat memercayai insight model tentang faktor pendorong performa situs, Anda harus memverifikasi bahwa prediksinya akurat.
Setelah pelatihan, gunakan fungsi ML.EVALUATE untuk menilai prediksi model terhadap set data "holdout" yang tidak digunakan selama pelatihan.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Periksa Skor R2
(r2_score) dan Mean Absolute
Error
(mean_absolute_error) untuk menentukan apakah model Anda siap untuk produksi:
- Skor R2 mengukur seberapa besar varians performa yang sebenarnya dijelaskan oleh faktor lingkungan eksternal (POI di sekitar). Skor R2 sebesar 0,70 berarti 70% kesuksesan situs terkait dengan lingkungan lokal. Semakin mendekati 1,0, semakin kuat korelasi antara fasilitas lingkungan dan performa situs.
- MAE memberi tahu Anda error rata-rata dalam poin. Misalnya, MAE sebesar 1,5 berarti prediksi model biasanya berada dalam +/- 1,5 poin dari skor performa sebenarnya.
Memecahkan Masalah Skor Rendah
Jika skor R2 Anda rendah, pertimbangkan peningkatan berikut:
- Perluas Jenis Fitur: Tambahkan Jenis Tempat yang berbeda ke kueri Anda (misalnya,
tourist_attraction,subway_station). - Menyesuaikan Radius Area Pemasaran: Ubah jarak
ST_DWITHIN. Radius 500 meter mungkin terlalu luas untuk kedai kopi, tetapi terlalu kecil untuk toko furnitur. - Tingkatkan Ukuran Data: Pastikan Anda melatih cukup banyak lokasi toko untuk menemukan pola yang signifikan secara statistik.
Memberi Skor Kota dengan Pengindeksan Spasial H3
Kami menggunakan Pengindeksan Spasial H3 untuk membagi kota London menjadi petak seragam sel heksagonal (Resolusi 8, sekitar 0,7 km²). Dengan menggabungkan data Insight Tempat ke dalam sel ini, kami dapat menerapkan model terlatih kami ke setiap lingkungan, mengidentifikasi area berpotensi tinggi yang cocok dengan profil lingkungan situs berperforma terbaik Anda.
Menjalankan Kueri Prospeksi
Untuk membuat petak ini, kami menggunakan fungsi
PLACES_COUNT_PER_H3
yang disediakan oleh set data Places Insights (Pelajari lebih lanjut cara membuat kueri
Places Insights menggunakan fungsi
Jumlah Tempat).
Fungsi ini menghitung jumlah POI untuk sel petak H3 dalam satu operasi.
Jalankan kueri SQL berikut untuk melakukan tiga langkah dalam satu eksekusi:
- Pengindeksan & Penghitungan H3: Kita memanggil
PLACES_COUNT_PER_H3menggunakan objek konfigurasi JSON untuk menemukan semua tempat operasional dalam radius 25 km dari pusat London. Kita membuat kueri ini secara terpisah untuk setiap jenis fasilitas (gym, sekolah, dll.) dan menggabungkannya menggunakanUNION ALL. - Memutar (Rekayasa Fitur): Karena model machine learning kami mengharapkan kolom fitur yang berbeda (seperti
gym_countdanrestaurant_count), kami mengelompokkan sel dan menggunakan agregasi bersyarat(SUM(IF(...)))untuk memutar data ke dalam skema yang benar. - Prediksi: Kita memasukkan fitur petak yang di-pivot ini langsung ke dalam fungsi
ML.PREDICTuntuk menghasilkan skor performa bagi setiap lingkungan.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Menafsirkan Hasil
Kueri ini menampilkan tabel dengan setiap baris mewakili area heksagonal di London.
h3_index: ID unik untuk sel heksagonal.predicted_store_performance: Perkiraan skor model untuk situs yang terletak di sel ini, hanya berdasarkan lingkungan sekitar.h3_geography: Geometri poligon sel, yang akan kita gunakan untuk visualisasi pada langkah berikutnya.
Nilai yang tinggi menunjukkan area dengan kepadatan sekolah, pusat kebugaran, dan transportasi umum yang cocok dengan pola yang ditemukan di sekitar situs lama Anda yang paling berhasil.
Memvisualisasikan Peta Prospek
Untuk membuat data dapat ditindaklanjuti, visualisasikan hasil di peta. Meskipun output tabular memberikan skor mentah, peta mengungkapkan kelompok spasial dan koridor potensi tinggi yang tidak terlihat jelas dalam daftar.
Dalam notebook pendamping, kita menggunakan library geopandas untuk mengurai geometri poligon H3 dan folium untuk merender peta interaktif.
Hasilnya adalah peta koroplet yang setiap sel heksagonalnya diberi warna sesuai dengan skor yang diprediksi.
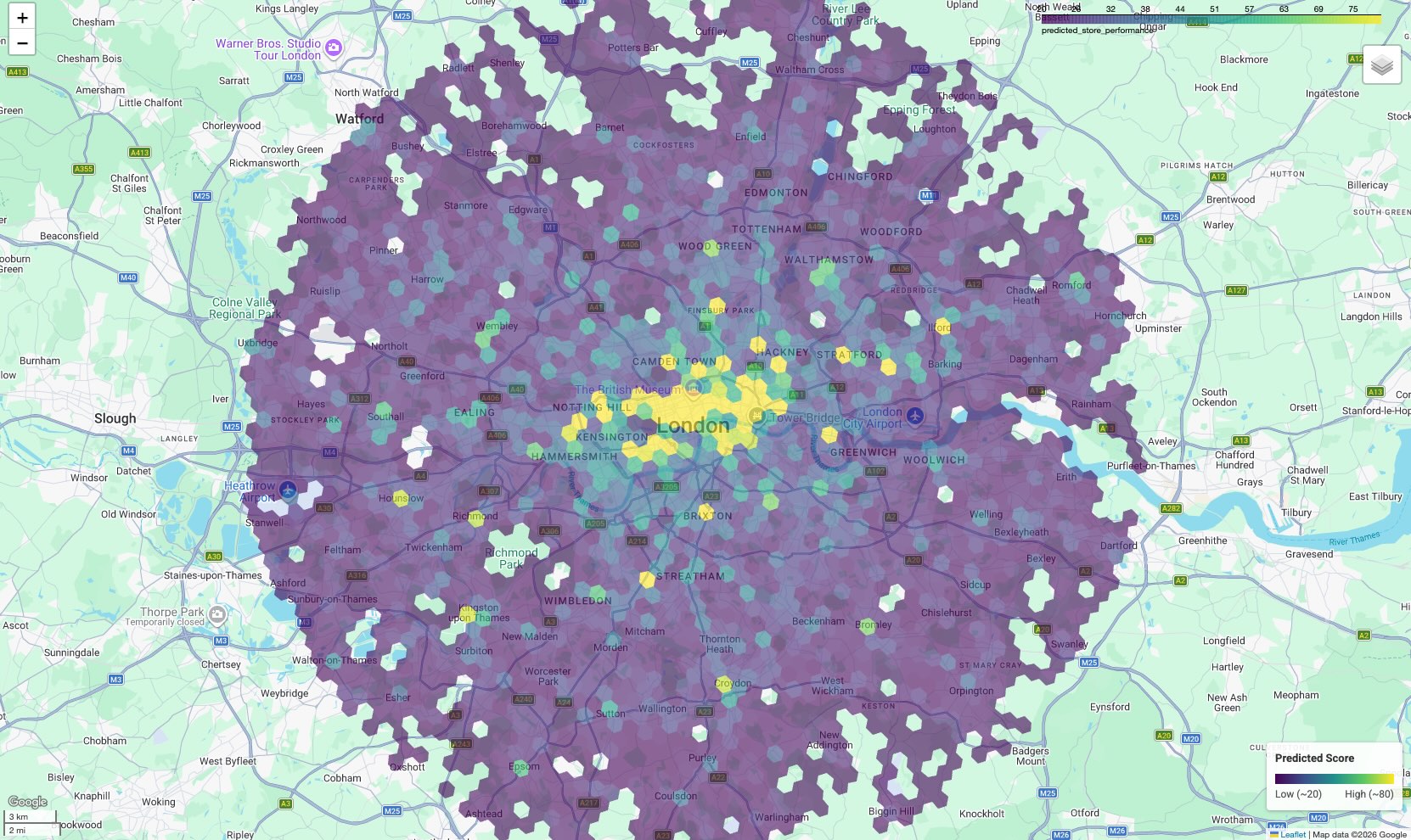
Menafsirkan Peta:
- Hotspot (Kuning/Hijau): Area ini memiliki skor performa yang diprediksi tinggi. Mereka memiliki kepadatan sekolah, pusat kebugaran, dan transportasi umum yang optimal yang berkorelasi dengan situs Anda yang berhasil. Lokasi ini adalah kandidat utama untuk pemilihan lokasi baru.
- Area dingin (Ungu): Area ini tidak memiliki fitur lingkungan pendukung yang ditemukan di dekat area dengan performa terbaik Anda.
- Pemeriksaan Interaktif: Di lingkungan notebook, Anda dapat mengarahkan kursor ke sel mana pun untuk melihat jumlah spesifik fasilitas (misalnya, "Gym: 12") yang berkontribusi pada skor spesifik tersebut.
Kesimpulan
Anda telah berhasil menggabungkan data operasional internal dengan Insight Tempat untuk mendiagnosis performa situs. Dengan menganalisis bobot model, Anda mengidentifikasi karakteristik lingkungan tertentu yang berkorelasi dengan metrik yang ada. Dengan menggunakan pengindeksan spasial H3, Anda menskalakan analisis ini dari beberapa ratus situs menjadi ribuan lingkungan potensial di seluruh London.
Tindakan Berikutnya
- Perluas Rekayasa Fitur: Tambahkan Jenis Tempat yang lebih spesifik ke kueri Anda, untuk mendapatkan pendorong khusus kunjungan langsung.
- Jelajahi Model Tingkat Lanjut: Meskipun Regresi Linear memberikan keterjelasan yang baik, bereksperimenlah dengan
BOOSTED_TREE_REGRESSORdi BigQuery ML yang dikombinasikan dengan strategi validasi silang yang sesuai untuk mencakup hubungan non-linear. - Mengoperasikan Peta: Ekspor hasil petak H3 ke dasbor kustom menggunakan Maps JavaScript API untuk membagikan hasil analisis ini kepada tim Anda.
Kontributor
- Henrik Valve | DevX Engineer
- Gennadii Donchyts | Staff Customer Engineer