

Pourquoi un site prospère-t-il alors qu'un autre sous-performe malgré des pratiques cohérentes en termes de personnel, d'inventaire et d'opérations ? Les entreprises possédant plusieurs établissements ont souvent du mal à expliquer cette variation de performances dans leur portefeuille. La réponse se trouve généralement dans l'environnement externe. En exploitant les données sur les points d'intérêt (POI), nous pouvons aller au-delà des explications anecdotiques et quantifier précisément la façon dont la densité concurrentielle locale et les caractéristiques du quartier déterminent le succès d'un site.
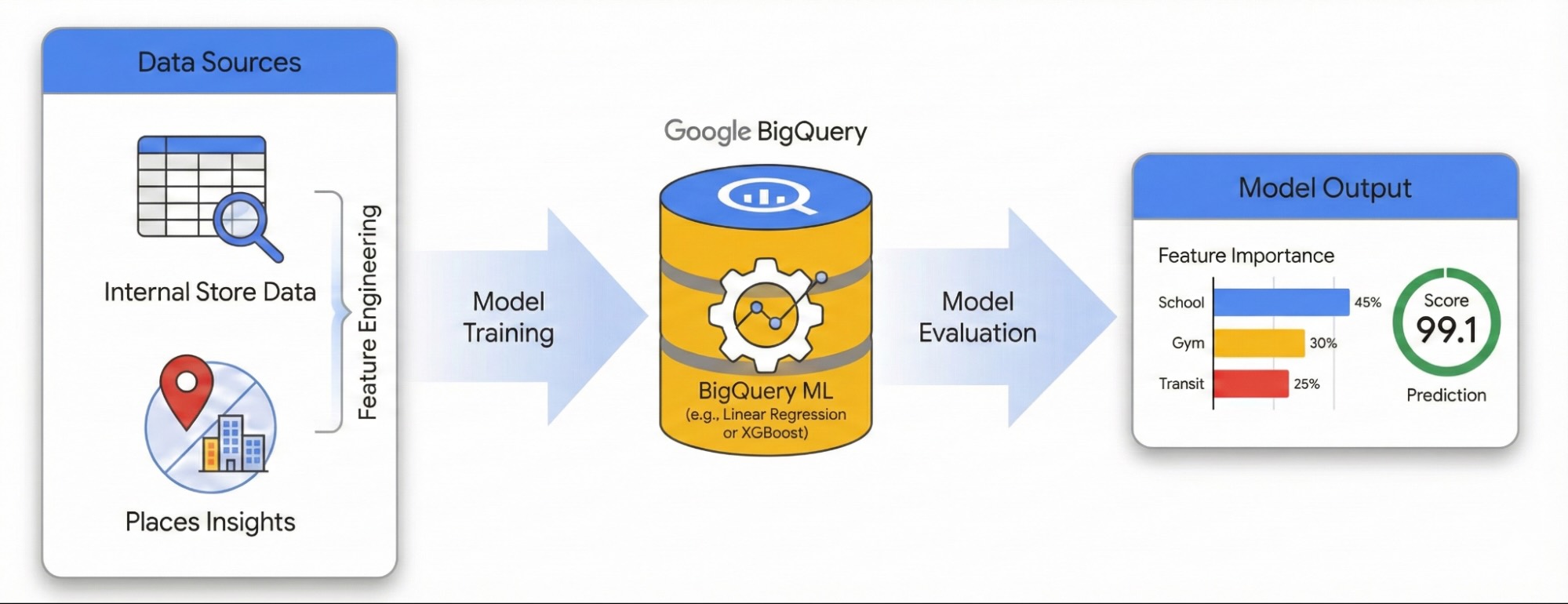
Ce guide explique comment quantifier l'impact de l'environnement local sur le succès d'un site à l'aide de Places Insights et de BigQuery ML. Vous combinerez vos données propriétaires sur les performances de votre site avec des signaux géospatiaux externes pour identifier les facteurs de performances.
Nous allons utiliser un ensemble de données de sites à Londres pour créer un modèle de régression linéaire. Ce workflow utilise l'indexation spatiale H3, qui divise la ville en cellules hexagonales uniformes. En agrégeant les données environnementales dans ces cellules, vous pouvez entraîner un modèle pour prédire le potentiel de performances de n'importe quel quartier de la ville, et pas seulement de vos sites existants.
Vous allez apprendre à effectuer les tâches suivantes :
- Fonctionnalités d'ingénierie : agrègent le nombre de points d'intérêt (POI) tels que les salles de sport, les écoles et les stations de transport en commun dans un rayon de 500 mètres autour de vos sites.
- Entraîner un modèle : utilisez BigQuery ML pour créer un modèle de régression qui met en corrélation ces caractéristiques environnementales avec vos métriques de performances internes.
- Évaluez la ville : appliquez le modèle entraîné à l'ensemble de la grille H3 de Londres pour identifier les zones à fort potentiel pour une future expansion.
Si vous ne connaissez pas BigQuery ML, consultez la présentation de BigQuery ML pour en savoir plus sur les concepts de base et les types de modèles compatibles.
Pour explorer ce workflow dans un environnement interactif, exécutez le notebook suivant. Il explique comment créer un modèle prédictif avec BigQuery ML et visualiser les opportunités à l'échelle d'une ville à l'aide de l'indexation spatiale H3.
 Afficher la source sur GitHub
Afficher la source sur GitHub
Prérequis
Avant de commencer, assurez-vous de disposer des éléments suivants :
Projet Google Cloud :
- Un projet Google Cloud avec facturation activée.
Accès aux données :
- Abonnement Places Insights dans BigQuery.
- Votre propre tableau des emplacements sur le site avec une métrique de performances (par exemple, les revenus). Un exemple d'ensemble de données se trouve dans les ressources du tutoriel.
Google Maps Platform :
- Une clé API.
- Les API suivantes sont activées pour votre clé :
Environnement et bibliothèques Python :
- Un environnement Python tel que Colab Enterprise dans la console Google Cloud.
- Les bibliothèques suivantes sont installées :
Bibliothèque Description pandas-gbqInteragir avec BigQuery geopandasGérer les opérations sur les données géospatiales. foliumCréer des cartes interactives shapelyManipulations géométriques.
Autorisations IAM :
- Assurez-vous que votre compte utilisateur ou de service dispose des rôles IAM suivants :
Rôle ID Éditeur de données BigQuery roles/bigquery.dataEditorUtilisateur BigQuery roles/bigquery.user
- Assurez-vous que votre compte utilisateur ou de service dispose des rôles IAM suivants :
Sensibilisation aux coûts :
- Ce tutoriel utilise des composants Google Cloud facturables. Tenez compte des coûts potentiels liés aux éléments suivants :
- BigQuery ML : facturation des emplacements de calcul utilisés. Consultez les tarifs de BigQuery ML.
- Places Insights : facturé en fonction de l'utilisation des requêtes.
- Ce tutoriel utilise des composants Google Cloud facturables. Tenez compte des coûts potentiels liés aux éléments suivants :
Ingénierie des caractéristiques avec Places Insights
Pour isoler les facteurs externes qui influencent les performances du site, vous devez transformer les données brutes des points d'intérêt en caractéristiques quantifiables. Vous calculerez la densité de certains équipements ou types de lieux (salles de sport, écoles et stations de transport en commun, par exemple) dans un rayon de 500 mètres autour de chaque site. Les équipements que vous sélectionnez dépendent de ce qui vous semble le plus pertinent pour votre établissement.
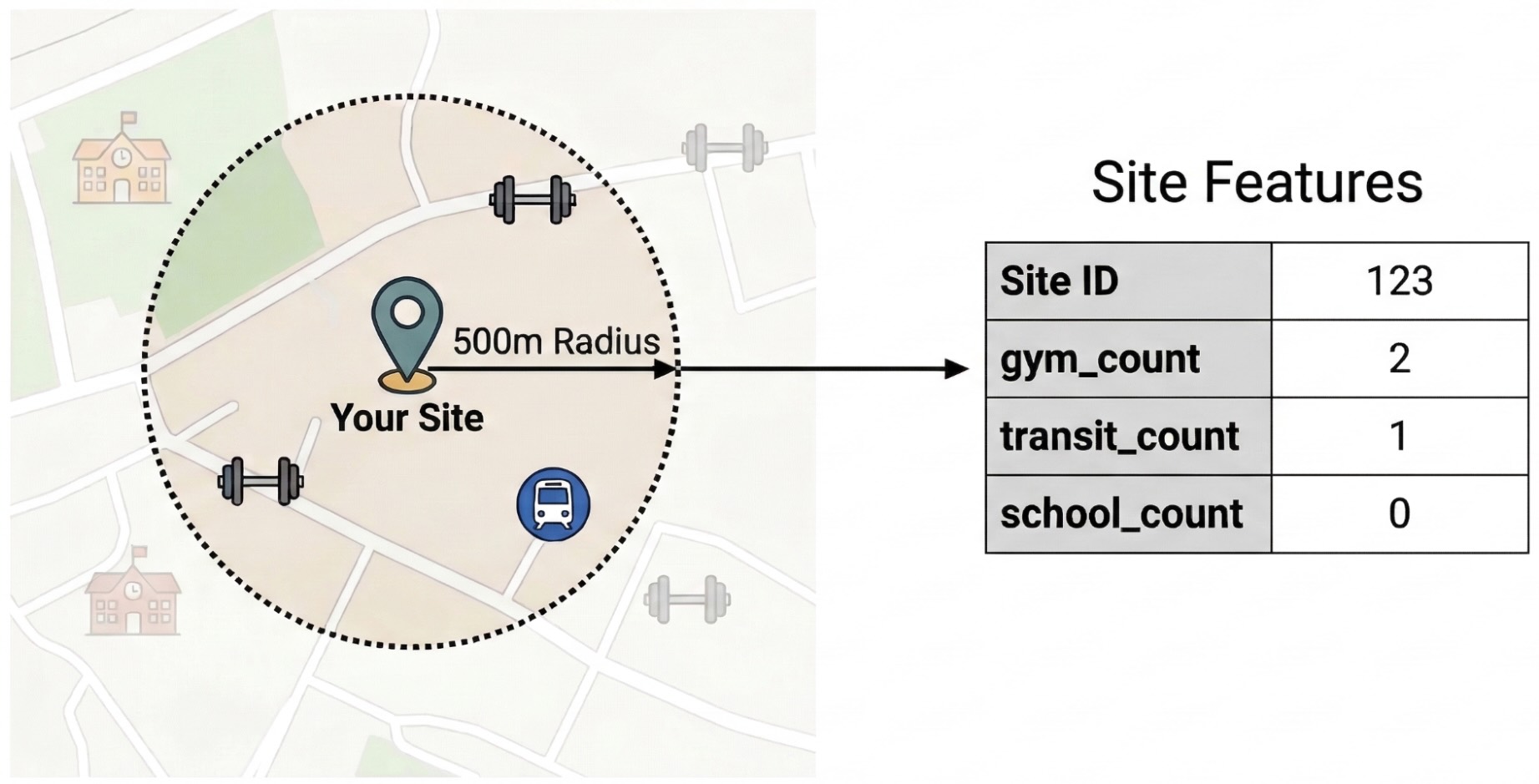
Pour cette étape, nous utilisons Python et la bibliothèque pandas-gbq. Cette approche vous permet d'exécuter la requête SELECT WITH AGGREGATION_THRESHOLD, qui est nécessaire pour accéder à l'ensemble de données Places Insights, et d'enregistrer les résultats dans une nouvelle table de votre projet. Pour en savoir plus sur l'utilisation des données Places Insights, consultez Interroger directement l'ensemble de données.
Exécuter la requête d'ingénierie des caractéristiques
Exécutez le script Python suivant dans votre environnement (par exemple, Colab Enterprise). Ce script associe les données de votre site interne à l'ensemble de données Places Insights.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Comprendre la requête
ST_DWITHIN: cette fonction géospatiale crée une zone tampon de 500 mètres autour de chaque emplacement de site et identifie tous les points Places Insights qui se trouvent dans ce rayon.COUNTIF: cette fonction calcule la densité de types de lieux spécifiques (par exemple, "salle de sport", "école") pour chaque site. Ces nombres deviennent les caractéristiques d'entrée (X) du modèle de machine learning.pandas_gbq.to_gbq: cette fonction conserve les résultats de la requête dans une nouvelle table (site_features). Cette table permanente sert d'ensemble de données d'entraînement propre pour le modèle BigQuery ML.
Pour des applications concrètes plus avancées, envisagez de calculer les caractéristiques à plusieurs distances (par exemple, 250 m, 500 m, 1 km) et d'explorer d'autres attributs Places Insights tels que rating, price_level ou regular_opening_hours. Pour obtenir la liste complète des attributs Places Insights, consultez les types de lieux acceptés et la documentation de référence sur le schéma principal.
Entraîner le modèle avec BigQuery ML
Maintenant que les caractéristiques extraites sont enregistrées dans votre table site_features, vous pouvez entraîner un modèle de régression linéaire.
Ce modèle apprend les pondérations optimales (β) pour chaque caractéristique environnementale (X) afin de prédire les performances de votre site (Y).
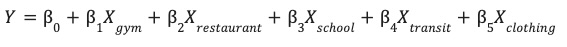
Gérer les valeurs aberrantes avec la mise à l'échelle robuste
Les données géospatiales contiennent souvent des valeurs aberrantes extrêmes qui peuvent fausser les modèles linéaires standards. Par exemple, un site dans le West End de Londres peut compter 200 restaurants dans un rayon de 500 mètres, tandis qu'un site de banlieue n'en compte que deux. Si vous utilisez une mise à l'échelle standard (moyenne/écart-type), la valeur aberrante (200) fausse la distribution et oblige le modèle à privilégier l'ajustement de cette valeur extrême.
Pour résoudre ce problème, nous utilisons la mise à l'échelle robuste (ML.ROBUST_SCALER) dans la définition du modèle. Cette technique met à l'échelle les caractéristiques en fonction de la médiane et de l'écart interquartile (IQR, Interquartile Range). Le modèle est ainsi résistant aux valeurs aberrantes et apprend à partir de la distribution typique de vos sites.
Créer le modèle
Exécutez la requête SQL suivante dans BigQuery pour créer et entraîner le modèle.
Nous utilisons la clause TRANSFORM pour appliquer une mise à l'échelle robuste à toutes les caractéristiques d'entrée. Nous définissons également optimize_strategy = 'NORMAL_EQUATION', car il s'agit de la méthode d'entraînement la plus efficace pour les ensembles de données relativement petits, comme un portefeuille type de magasins. Enfin, nous filtrons les valeurs aberrantes très performantes (store_performance <
75) pour que le modèle se concentre sur la prédiction des schémas de croissance typiques.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Évaluer les performances du modèle
Avant de pouvoir faire confiance aux insights du modèle sur les facteurs qui déterminent les performances du site, vous devez vérifier l'exactitude de ses prédictions.
Après l'entraînement, utilisez la fonction ML.EVALUATE pour évaluer les prédictions du modèle par rapport à un ensemble de données "de validation" qui n'a pas été utilisé lors de l'entraînement.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Vérifiez le score R2 (r2_score) et l'erreur absolue moyenne (mean_absolute_error) pour déterminer si votre modèle est prêt pour la production :
- Le score R2 mesure la part de la variance des performances qui est réellement expliquée par les facteurs environnementaux externes (points d'intérêt à proximité). Un score R2 de 0,70 signifie que 70 % du succès d'un site est lié à l'environnement local. Plus la valeur est proche de 1, plus la corrélation entre les aménagements environnementaux et les performances du site est forte.
- L'EAM indique l'erreur moyenne en points. Par exemple, une MAE de 1,5 signifie que les prédictions du modèle se situent généralement à +/- 1,5 point du score de performances réel.
Résoudre les problèmes de scores faibles
Si votre score R2 est faible, envisagez les améliorations suivantes :
- Élargissez les types de caractéristiques : ajoutez différents types de lieux à votre requête (par exemple,
tourist_attraction,subway_station). - Ajuster le rayon de couverture : modifiez la distance
ST_DWITHIN. Un rayon de 500 mètres peut être trop large pour un café, mais trop petit pour un magasin de meubles. - Augmentez la taille des données : assurez-vous d'entraîner votre modèle sur un nombre suffisant de magasins pour trouver un modèle statistiquement pertinent.
Évaluer la ville avec l'indexation spatiale H3
Nous utilisons l'indexation spatiale H3 pour diviser la ville de Londres en une grille uniforme de cellules hexagonales (résolution 8, environ 0,7 km²). En agrégeant les données Places Insights dans ces cellules, nous pouvons appliquer notre modèle entraîné à chaque quartier, en identifiant les zones à fort potentiel qui correspondent au profil environnemental de vos sites les plus performants.
Exécuter la requête de prospection
Pour générer cette grille, nous utilisons la fonction PLACES_COUNT_PER_H3 fournie par l'ensemble de données Places Insights. Pour en savoir plus, consultez Interroger Places Insights à l'aide des fonctions Places Count.
Cette fonction calcule le nombre de points d'intérêt pour les cellules de la grille H3 en une seule opération.
Exécutez la requête SQL suivante pour effectuer trois étapes en une seule exécution :
- Indexation et comptage H3 : nous appelons
PLACES_COUNT_PER_H3à l'aide d'un objet de configuration JSON pour trouver tous les lieux opérationnels dans un rayon de 25 km autour du centre de Londres. Nous interrogeons cette valeur séparément pour chaque type d'établissement (salles de sport, écoles, etc.) et les combinons à l'aide deUNION ALL. - Table croisée dynamique (extraction de caractéristiques) : comme notre modèle de machine learning attend des colonnes de caractéristiques distinctes (comme
gym_countetrestaurant_count), nous regroupons les cellules et utilisons l'agrégation conditionnelle(SUM(IF(...)))pour créer une table croisée dynamique des données dans le schéma approprié. - Prédiction : nous transmettons ces caractéristiques de grille pivotées directement à la fonction
ML.PREDICTpour générer un score de performances pour chaque quartier.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Interpréter les résultats
La requête renvoie un tableau où chaque ligne représente une zone hexagonale à Londres.
h3_index: identifiant unique de la cellule hexagonale.predicted_store_performance: score estimé du modèle pour un site situé dans cette cellule, basé uniquement sur l'environnement environnant.h3_geography: géométrie polygonale de la cellule, que nous utiliserons pour la visualisation à l'étape suivante.
Les valeurs élevées indiquent les zones où la densité des écoles, des salles de sport et des transports en commun correspond aux schémas observés autour de vos sites existants les plus performants.
Visualiser la carte de prospection
Pour rendre les données exploitables, visualisez les résultats sur une carte. Alors que le tableau fournit des scores bruts, une carte révèle des clusters spatiaux et des corridors à fort potentiel qui ne sont pas évidents dans une liste.
Dans le notebook qui l'accompagne, nous utilisons la bibliothèque geopandas pour analyser la géométrie du polygone H3 et folium pour afficher une carte interactive.
Le résultat est une carte choroplèthe où chaque cellule hexagonale est colorée en fonction de son score prédit.
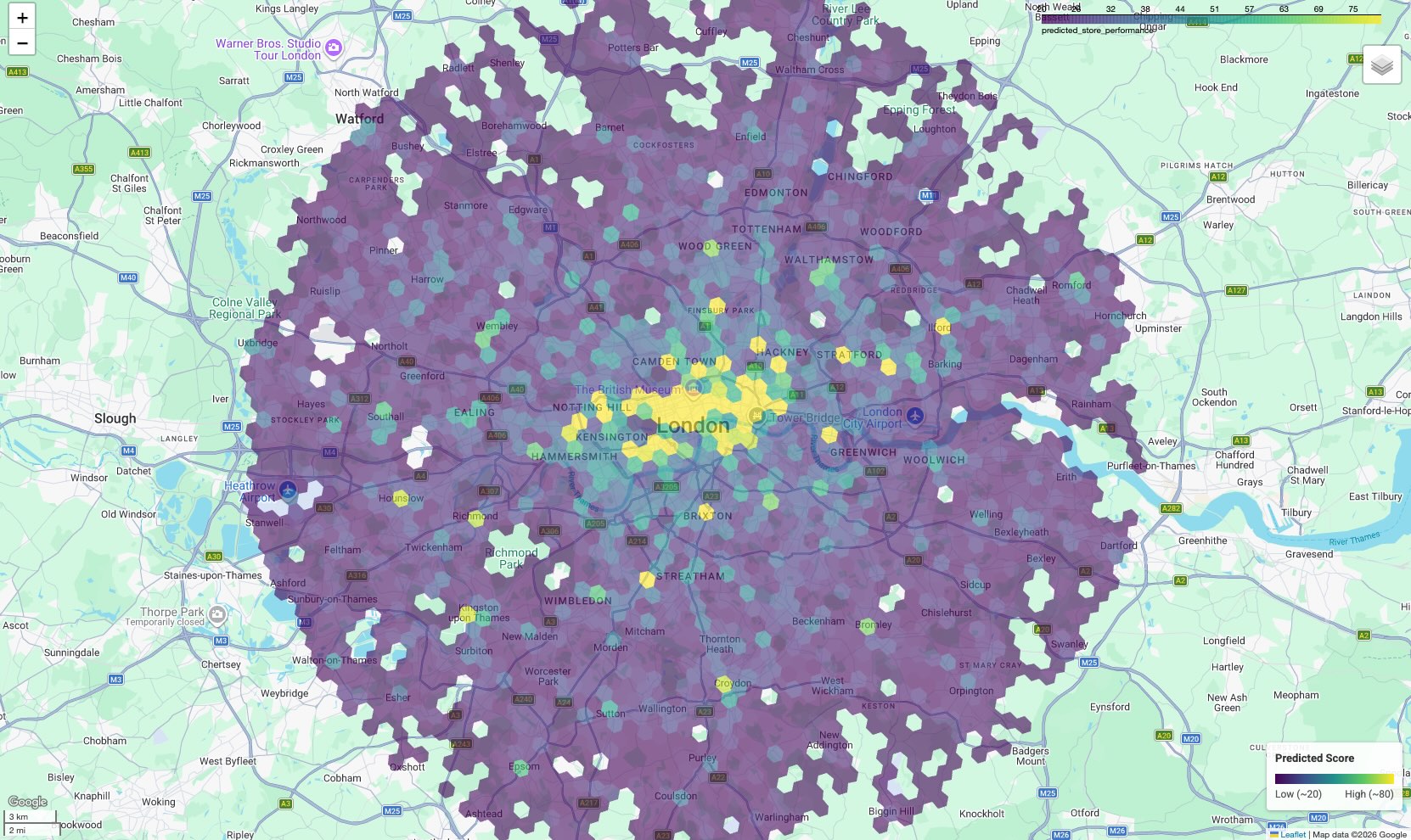
Interpréter la carte :
- Zones chaudes (jaunes/vertes) : ces zones présentent des scores de performances prévus élevés. Elles présentent la densité optimale d'écoles, de salles de sport et de transports en commun qui correspond à vos sites performants. Elles sont de bons candidats pour la sélection de nouveaux sites.
- Zones froides (violet) : ces zones ne disposent pas des caractéristiques environnementales favorables que l'on trouve à proximité de vos zones les plus performantes.
- Inspection interactive : dans l'environnement du notebook, vous pouvez pointer sur n'importe quelle cellule pour afficher le nombre spécifique d'équipements (par exemple, "Salles de sport : 12") qui ont contribué à ce score spécifique.
Conclusion
Vous avez réussi à combiner des données opérationnelles internes avec Places Insights pour diagnostiquer les performances de votre site. En analysant les pondérations du modèle, vous avez identifié les caractéristiques spécifiques du quartier qui sont corrélées à vos métriques existantes. Grâce à l'indexation spatiale H3, vous avez étendu cette analyse de quelques centaines de sites à des milliers de quartiers potentiels à Londres.
Actions suivantes
- Développez l'ingénierie des caractéristiques : ajoutez des types de lieux plus spécifiques à votre requête pour identifier les facteurs de niche qui génèrent du trafic en magasin.
- Explorer les modèles avancés : bien que la régression linéaire offre une explication claire, expérimentez avec
BOOSTED_TREE_REGRESSORdans BigQuery ML, combiné à une stratégie de validation croisée appropriée, pour capturer les relations non linéaires. - Exploitez la carte : exportez les résultats de la grille H3 vers un tableau de bord personnalisé à l'aide de l'API Maps JavaScript pour partager ces insights avec votre équipe.
Contributeurs
- Henrik Valve | DevX Engineer
- Gennadii Donchyts | Ingénieur client