

چرا یک سایت با وجود کارکنان، موجودی و شیوههای عملیاتی ثابت، رشد میکند در حالی که سایت دیگر عملکرد ضعیفی دارد؟ کسبوکارهایی که چندین شعبه دارند، اغلب برای توضیح این تفاوت عملکرد در کل مجموعه خود دچار مشکل میشوند. پاسخ معمولاً در محیط خارجی پنهان است. با استفاده از دادههای نقاط مورد علاقه (POI)، میتوانیم فراتر از توضیحات روایی حرکت کنیم و دقیقاً مشخص کنیم که چگونه تراکم رقابتی محلی و ویژگیهای همسایگی، موفقیت یک سایت را تعیین میکند.
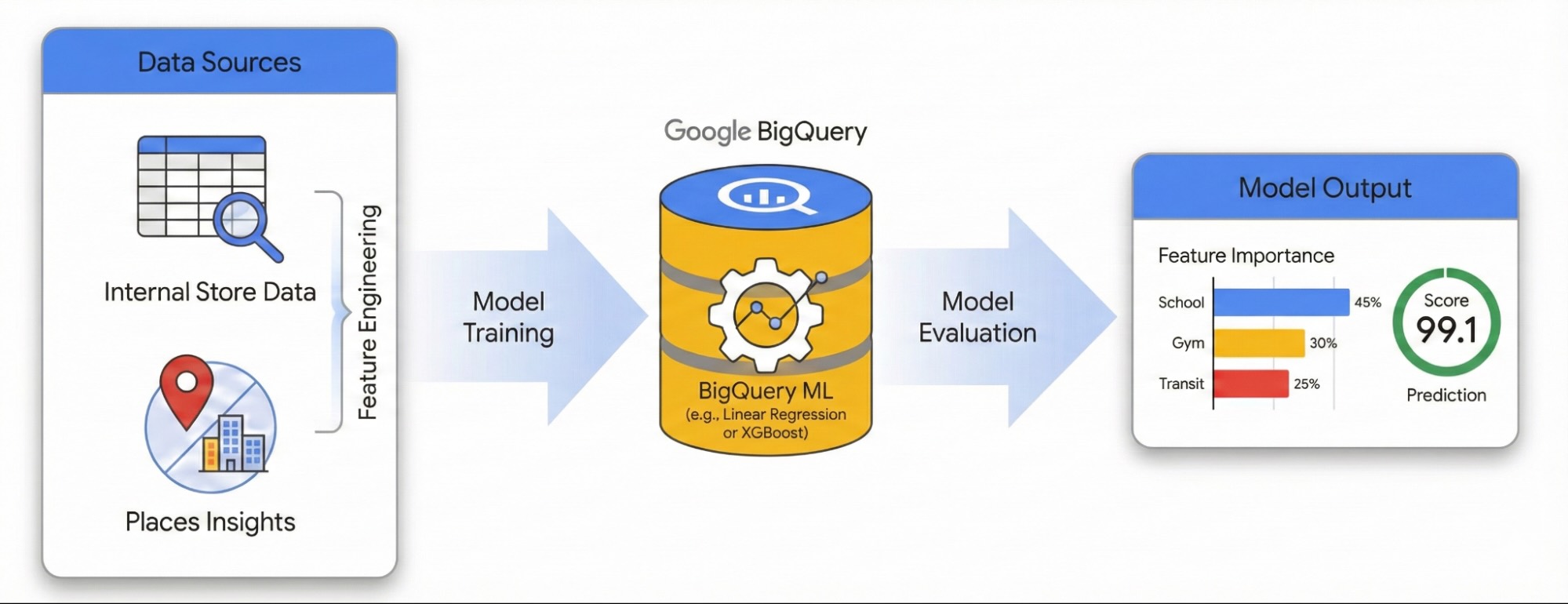
این راهنما نحوهی سنجش تأثیر محیط محلی بر موفقیت سایت را با استفاده از Places Insights و BigQuery ML نشان میدهد. شما دادههای عملکرد اختصاصی سایت خود را با سیگنالهای جغرافیایی خارجی ترکیب خواهید کرد تا عوامل مؤثر بر عملکرد را تشخیص دهید.
ما از مجموعه دادههایی از مکانها در لندن برای ساخت یک مدل رگرسیون خطی استفاده خواهیم کرد. این گردش کار از H3 Spatial Indexing استفاده میکند، این سیستم شهر را به سلولهای شش ضلعی یکنواخت تقسیم میکند. با تجمیع دادههای محیطی در این سلولها، میتوانید مدلی را آموزش دهید تا پتانسیل عملکرد هر محله در شهر، نه فقط مکانهای موجود شما، را پیشبینی کند.
شما یاد خواهید گرفت که:
- ویژگیهای مهندسی: تعداد کل نقاط مورد علاقه (POI) مانند باشگاههای ورزشی، مدارس و ایستگاههای حمل و نقل عمومی در شعاع ۵۰۰ متری از مکانهای شما.
- آموزش یک مدل: از BigQuery ML برای ساخت یک مدل رگرسیون استفاده کنید که این ویژگیهای محیطی را با معیارهای عملکرد داخلی شما مرتبط میکند.
- امتیازدهی به شهر: مدل آموزشدیده را روی کل شبکه H3 لندن اعمال کنید تا نقاط حساس با پتانسیل بالا برای توسعههای آینده را شناسایی کنید.
اگر در BigQuery ML تازهکار هستید، برای آشنایی با مفاهیم اصلی و انواع مدلهای پشتیبانیشده ، به بخش «مقدمهای بر BigQuery ML» مراجعه کنید.
برای بررسی این گردش کار در یک محیط تعاملی، دفترچه یادداشت زیر را اجرا کنید. این دفترچه نشان میدهد که چگونه میتوان با BigQuery ML یک مدل پیشبینی ساخت و با استفاده از نمایهسازی مکانی H3، فرصتهای سطح شهر را تجسم کرد.
 مشاهده منبع در گیتهاب
مشاهده منبع در گیتهابپیشنیازها
قبل از شروع، مطمئن شوید که موارد زیر را دارید:
پروژه ابری گوگل:
- یک پروژه گوگل کلود با قابلیت پرداخت.
دسترسی به دادهها:
- اشتراک Places Insights در BigQuery.
- جدول خودتان از مکانهای سایت به همراه یک معیار عملکرد (مثلاً درآمد). یک مجموعه داده نمونه در منابع آموزشی موجود است.
پلتفرم نقشه گوگل:
- یک کلید API .
- API های زیر برای کلید شما فعال شده اند:
محیط و کتابخانههای پایتون:
- یک محیط پایتون مانند Colab Enterprise در کنسول ابری گوگل.
- کتابخانههای زیر نصب شدهاند:
کتابخانه توضیحات pandas-gbqتعامل با BigQuery geopandasمدیریت عملیات دادههای مکانی foliumایجاد نقشههای تعاملی shapelyدستکاریهای هندسی.
مجوزهای IAM:
- مطمئن شوید که حساب کاربری یا سرویس شما نقشهای IAM زیر را دارد:
نقش شناسه ویرایشگر داده BigQuery roles/bigquery.dataEditorکاربر بیگکوئری roles/bigquery.user
- مطمئن شوید که حساب کاربری یا سرویس شما نقشهای IAM زیر را دارد:
آگاهی از هزینهها:
- این آموزش از اجزای Google Cloud قابل پرداخت استفاده میکند. از هزینههای احتمالی مربوط به موارد زیر آگاه باشید:
- BigQuery ML: برای اسلاتهای محاسباتی استفاده شده هزینه دریافت میشود. به قیمتگذاری BigQuery ML مراجعه کنید.
- اطلاعات مکانها: بر اساس میزان استفاده از جستجو هزینه دریافت میشود.
- این آموزش از اجزای Google Cloud قابل پرداخت استفاده میکند. از هزینههای احتمالی مربوط به موارد زیر آگاه باشید:
مهندسی ویژگی با بینشهای مکانی
برای جداسازی عوامل خارجی مؤثر بر عملکرد سایت، باید دادههای خام نقاط مورد توجه (POI) را به ویژگیهای قابل سنجش تبدیل کنید. شما تراکم امکانات خاص یا انواع مکانها مانند باشگاههای ورزشی، مدارس و ایستگاههای حمل و نقل را در شعاع ۵۰۰ متری هر سایت محاسبه خواهید کرد. امکاناتی که انتخاب میکنید به آنچه که فکر میکنید ممکن است برای کسب و کار شما مرتبطتر باشد، بستگی دارد.
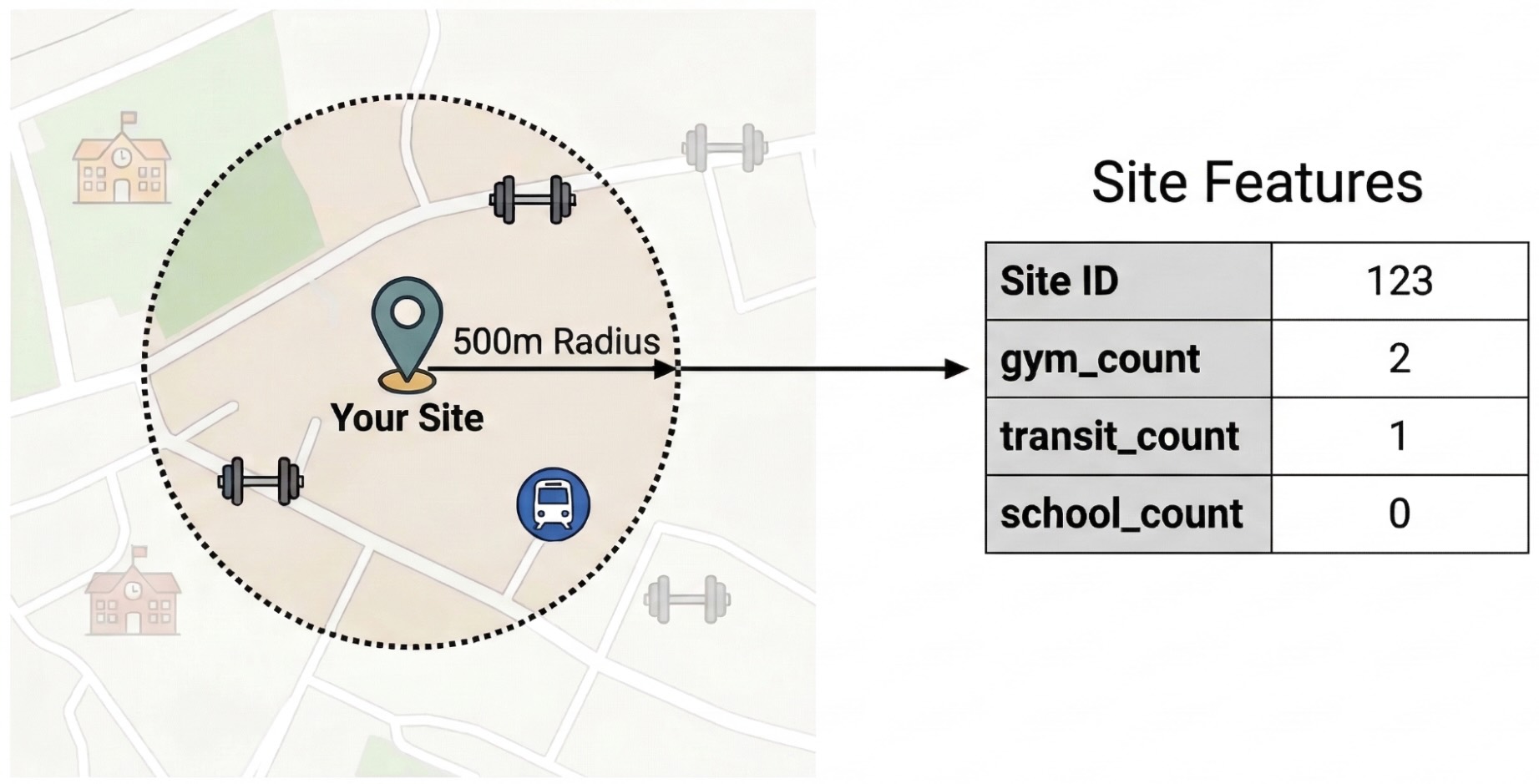
ما برای این مرحله از پایتون و کتابخانه pandas-gbq استفاده میکنیم. این رویکرد به شما امکان میدهد کوئری SELECT WITH AGGREGATION_THRESHOLD را که برای دسترسی به مجموعه دادههای Places Insights لازم است، اجرا کنید و نتایج را در یک جدول جدید در پروژه خود ذخیره کنید. برای اطلاعات بیشتر در مورد کار با دادههای Places Insights، به بخش Query the dataset directly مراجعه کنید.
اجرای کوئری مهندسی ویژگی
اسکریپت پایتون زیر را در محیط خود (مثلاً Colab Enterprise ) اجرا کنید. این اسکریپت دادههای داخلی سایت شما را به مجموعه دادههای Places Insights متصل میکند.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
پرس و جو را درک کنید
-
ST_DWITHIN: این تابع مکانی یک بافر ۵۰۰ متری در اطراف هر مکان سایت ایجاد میکند و تمام نقاط Places Insights را که در آن شعاع قرار میگیرند، شناسایی میکند. -
COUNTIF: این تابع چگالی انواع مکانهای خاص (مثلاً «باشگاه ورزشی»، «مدرسه») را برای هر مکان محاسبه میکند. این تعداد، ویژگیهای ورودی ( X ) برای مدل یادگیری ماشین میشوند. -
pandas_gbq.to_gbq: این تابع نتایج پرسوجو را در یک جدول جدید (site_features) ذخیره میکند. این جدول دائمی به عنوان مجموعه داده آموزشی تمیز برای مدل BigQuery ML عمل میکند.
برای برنامههای کاربردی پیشرفتهتر در دنیای واقعی، محاسبه ویژگیها در فواصل مختلف (مثلاً ۲۵۰ متر، ۵۰۰ متر، ۱ کیلومتر) و بررسی سایر ویژگیهای Places Insights مانند rating ، price_level یا regular_opening_hours در نظر بگیرید. برای لیست کامل ویژگیهای Places Insights، به انواع مکانهای پشتیبانی شده و مرجع طرحواره اصلی مراجعه کنید.
آموزش مدل با BigQuery ML
با ویژگیهای مهندسیشدهای که در جدول site_features ذخیره شدهاند، اکنون میتوانید یک مدل رگرسیون خطی آموزش دهید.
این مدل وزنهای بهینه ( β ) را برای هر ویژگی محیطی ( X ) یاد میگیرد تا عملکرد سایت شما ( Y ) را پیشبینی کند.
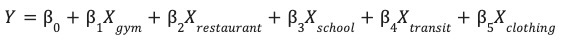
مدیریت دادههای پرت با مقیاسبندی قوی
دادههای مکانی اغلب حاوی دادههای پرت بسیار زیادی هستند که میتوانند مدلهای خطی استاندارد را تحریف کنند. به عنوان مثال، یک سایت در وست اند لندن ممکن است ۲۰۰ رستوران در شعاع ۵۰۰ متری داشته باشد، در حالی که یک سایت در حومه شهر تنها ۲ رستوران دارد. اگر از مقیاسبندی استاندارد (میانگین/انحراف معیار) استفاده کنید، داده پرت (۲۰۰) توزیع را منحرف میکند و مدل را مجبور میکند تا برازش آن مقدار بسیار زیاد را در اولویت قرار دهد.
برای حل این مشکل، ما از مقیاسبندی قوی ( ML.ROBUST_SCALER ) در تعریف مدل استفاده میکنیم. این تکنیک ویژگیها را بر اساس میانه و دامنه بین چارکی (IQR) مقیاسبندی میکند و مدل را در برابر دادههای پرت مقاوم میسازد و تضمین میکند که از توزیع معمول سایتهای شما یاد میگیرد.
مدل را ایجاد کنید
برای ایجاد و آموزش مدل، کوئری SQL زیر را در BigQuery اجرا کنید.
ما از عبارت TRANSFORM برای اعمال مقیاسبندی قوی به تمام ویژگیهای ورودی استفاده میکنیم. همچنین optimize_strategy = 'NORMAL_EQUATION' را تنظیم میکنیم زیرا این روش، کارآمدترین روش آموزش برای مجموعه دادههای نسبتاً کوچک، مانند یک نمونه کار معمولی از مکانهای فروشگاه، است. در نهایت، دادههای پرت با عملکرد بالا ( store_performance < 75 ) را فیلتر میکنیم تا مدل بر پیشبینی الگوهای رشد معمول تمرکز کند.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
ارزیابی عملکرد مدل
قبل از اینکه بتوانید به بینشهای مدل در مورد آنچه عملکرد سایت را هدایت میکند اعتماد کنید، باید صحت پیشبینیهای آن را تأیید کنید.
پس از آموزش، از تابع ML.EVALUATE برای ارزیابی پیشبینیهای مدل در برابر مجموعهای از دادههای «محدود» که در طول آموزش استفاده نشدهاند، استفاده کنید.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
برای تعیین اینکه آیا مدل شما آماده تولید است یا خیر، امتیاز R2 ( r2_score ) و میانگین خطای مطلق ( mean_absolute_error ) را بررسی کنید:
- نمره R2 نشان میدهد که چه مقدار از واریانس عملکرد در واقع توسط عوامل محیطی خارجی (نقاط مورد توجه نزدیک) توضیح داده میشود. نمره R2 برابر با 0.70 به این معنی است که 70٪ از موفقیت یک سایت به محیط محلی گره خورده است. هرچه به 1.0 نزدیکتر باشد، همبستگی بین امکانات محیطی و عملکرد سایت قویتر است.
- MAE میانگین خطا را بر حسب امتیاز به شما میگوید. برای مثال، MAE برابر با ۱.۵ به این معنی است که پیشبینیهای مدل معمولاً در محدوده +/- ۱.۵ امتیاز از امتیاز عملکرد واقعی قرار دارند.
عیبیابی نمرات پایین
اگر امتیاز R2 شما پایین است، موارد زیر را در نظر بگیرید:
- انواع ویژگیها را گسترش دهید: انواع مکانهای مختلف را به پرسوجوی خود اضافه کنید (مثلاً
tourist_attraction،subway_station). - تنظیم شعاع پوشش: فاصله
ST_DWITHINرا تغییر دهید. شعاع ۵۰۰ متری ممکن است برای یک کافیشاپ خیلی وسیع و برای یک فروشگاه مبلمان خیلی کوچک باشد. - افزایش اندازه دادهها: اطمینان حاصل کنید که در حال آموزش مکانهای فروشگاه کافی هستید تا یک الگوی آماری معنادار پیدا کنید.
امتیازدهی به شهر با استفاده از شاخصگذاری مکانی H3
ما از شاخصگذاری مکانی H3 برای تقسیم شهر لندن به یک شبکه یکنواخت از سلولهای ششضلعی (با وضوح ۸، تقریباً ۰.۷ کیلومتر مربع) استفاده میکنیم. با تجمیع دادههای Places Insights در این سلولها، میتوانیم مدل آموزشدیده خود را در هر محله اعمال کنیم و مناطق با پتانسیل بالا را که با مشخصات محیطی سایتهای برتر شما مطابقت دارند، شناسایی کنیم.
اجرای پرسوجوی اکتشافی
برای تولید این شبکه، از تابع PLACES_COUNT_PER_H3 ارائه شده توسط مجموعه داده Places Insights استفاده میکنیم (درباره پرسوجوی Places Insights با استفاده از توابع Places Count بیشتر بدانید). این تابع تعداد POIها را برای سلولهای شبکه H3 در یک عملیات واحد محاسبه میکند.
کوئری SQL زیر را اجرا کنید تا سه مرحله را در یک اجرا انجام دهید:
- فهرستبندی و شمارش H3: ما با استفاده از یک شیء پیکربندی JSON، تابع
PLACES_COUNT_PER_H3را فراخوانی میکنیم تا تمام مکانهای عملیاتی را در شعاع ۲۵ کیلومتری مرکز لندن پیدا کنیم. ما این را به صورت جداگانه برای هر نوع امکانات رفاهی (باشگاههای ورزشی، مدارس و غیره) پرسوجو میکنیم و آنها را با استفاده ازUNION ALLترکیب میکنیم. - چرخش (مهندسی ویژگی): از آنجا که مدل یادگیری ماشین ما انتظار ستونهای ویژگی متمایزی (مانند
gym_countوrestaurant_count) را دارد، سلولها را گروهبندی میکنیم و از تجمیع شرطی(SUM(IF(...)))برای چرخش دادهها به طرحواره صحیح استفاده میکنیم. - پیشبینی: ما این ویژگیهای شبکه محوری را مستقیماً به تابع
ML.PREDICTوارد میکنیم تا برای هر محله یک امتیاز عملکرد ایجاد کنیم.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
نتایج را تفسیر کنید
این پرسوجو جدولی را برمیگرداند که هر سطر آن نشاندهنده یک ناحیه ششضلعی در لندن است.
-
h3_index: شناسه منحصر به فرد برای سلول شش ضلعی. -
predicted_store_performance: امتیاز تخمینی مدل برای مکانی که در این سلول قرار دارد، صرفاً بر اساس محیط اطراف. -
h3_geography: هندسه چندضلعی سلول که در مرحله بعدی برای تجسم از آن استفاده خواهیم کرد.
مقادیر بالا نشاندهنده مناطقی است که تراکم مدارس، سالنهای ورزشی و حمل و نقل عمومی با الگوهای موجود در موفقترین مکانهای موجود شما مطابقت دارد.
نقشه اکتشاف را تجسم کنید
برای اینکه دادهها کاربردی باشند، نتایج را روی نقشه تجسم کنید. در حالی که خروجی جدولی نمرات خام را ارائه میدهد، نقشه خوشههای مکانی و مسیرهای با پتانسیل بالا را که در یک لیست مشخص نیستند، آشکار میکند.
در دفترچه یادداشت همراه، ما از کتابخانه geopandas برای تجزیه هندسه چندضلعی H3 و folium برای ارائه یک نقشه تعاملی استفاده میکنیم.
نتیجه یک نقشه کروپلت است که در آن هر سلول شش ضلعی بر اساس امتیاز پیشبینیشدهاش رنگآمیزی شده است.
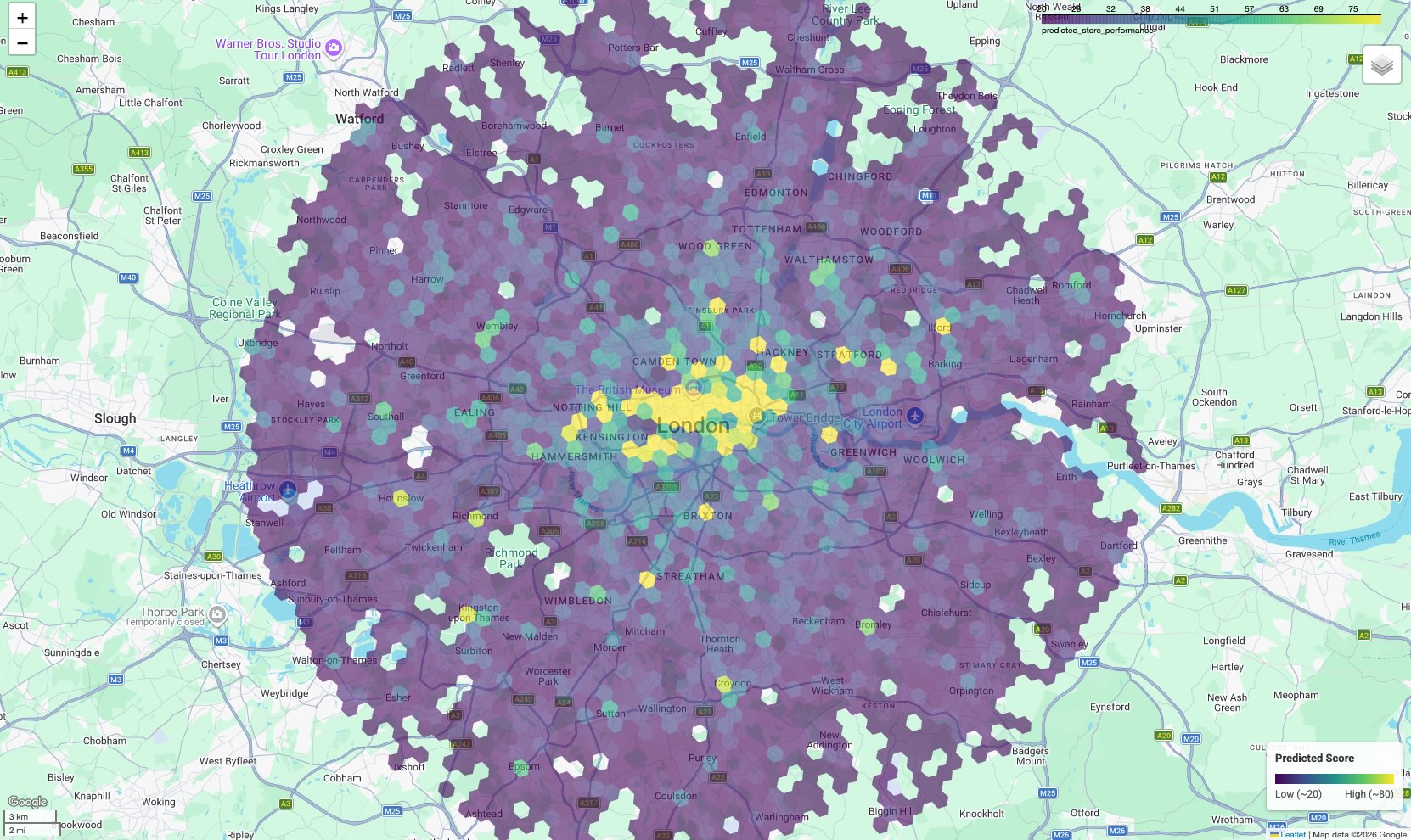
تفسیر نقشه:
- نقاط مهم (زرد/سبز): این مناطق امتیاز عملکرد پیشبینیشده بالایی دارند. آنها دارای تراکم بهینه مدارس، سالنهای ورزشی و حملونقل عمومی هستند که با مکانهای موفق شما مرتبط است. اینها کاندیداهای اصلی برای انتخاب مکان جدید هستند.
- نقاط سرد (بنفش): این مناطق فاقد ویژگیهای محیطی حمایتی هستند که در نزدیکی مناطق با عملکرد بالا یافت میشوند.
- بازرسی تعاملی: در محیط دفترچه یادداشت، میتوانید ماوس را روی هر سلول نگه دارید تا تعداد دقیق امکانات رفاهی (مثلاً «باشگاههای ورزشی: ۱۲») که در آن امتیاز خاص نقش داشتهاند را ببینید.
نتیجهگیری
شما با موفقیت دادههای عملیاتی داخلی را با Places Insights برای تشخیص عملکرد سایت ترکیب کردهاید. با تجزیه و تحلیل وزنهای مدل، ویژگیهای خاص محله را که با معیارهای موجود شما همبستگی دارند، شناسایی کردهاید. با استفاده از شاخصگذاری مکانی H3، این تجزیه و تحلیل را از چند صد مکان به هزاران محله بالقوه در سراسر لندن گسترش دادهاید.
اقدامات بعدی
- مهندسی ویژگی را گسترش دهید: انواع مکانهای خاصتری را به جستجوی خود اضافه کنید تا محرکهای خاص ترافیک پیاده را در نظر بگیرید.
- مدلهای پیشرفته را بررسی کنید: در حالی که رگرسیون خطی توضیحپذیری روشنی را ارائه میدهد،
BOOSTED_TREE_REGRESSORرا در BigQuery ML همراه با یک استراتژی اعتبارسنجی متقابل مناسب برای ثبت روابط غیرخطی آزمایش کنید. - عملیاتی کردن نقشه: نتایج شبکه H3 را با استفاده از API جاوا اسکریپت Maps به یک داشبورد سفارشی صادر کنید تا این بینشها را با تیم خود به اشتراک بگذارید.
مشارکتکنندگان
- هنریک والو | مهندس DevX
- گنادی دونچیتس | مهندس مشتری