

Warum läuft eine Website gut, während eine andere trotz gleichbleibender Personal-, Inventar- und Betriebspraktiken schlecht abschneidet? Unternehmen mit mehreren Standorten haben oft Schwierigkeiten, diese Leistungsvarianz in ihrem Portfolio zu erklären. Die Antwort liegt normalerweise verborgen in der externen Umgebung. Mithilfe von POI-Daten (Points of Interest) können wir über anekdotische Erklärungen hinausgehen und genau quantifizieren, wie sich die lokale Wettbewerbsdichte und die Merkmale der Nachbarschaft auf den Erfolg eines Standorts auswirken.
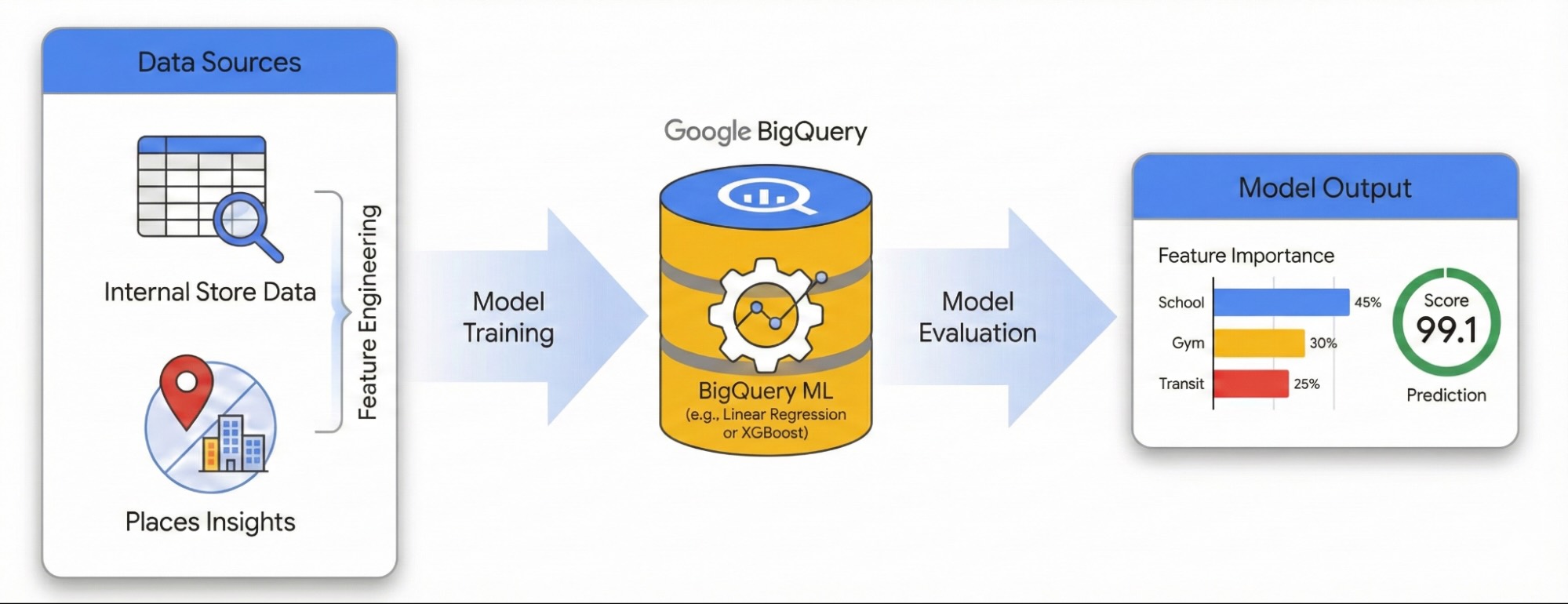
In diesem Leitfaden wird gezeigt, wie Sie die Auswirkungen der lokalen Umgebung auf den Erfolg von Standorten mithilfe von Places Insights und BigQuery ML quantifizieren können. Sie kombinieren Ihre eigenen Website-Leistungsdaten mit externen geografischen Signalen, um Leistungsfaktoren zu ermitteln.
Wir verwenden ein Dataset mit Standorten in London, um ein lineares Regressionsmodell zu erstellen. In diesem Workflow wird die H3-Raumindexierung verwendet. Bei diesem System wird die Stadt in einheitliche sechseckige Zellen unterteilt. Wenn Sie Umweltdaten in diesen Zellen zusammenfassen, können Sie ein Modell trainieren, um das Leistungspotenzial eines beliebigen Stadtteils vorherzusagen, nicht nur das Ihrer bestehenden Standorte.
Sie lernen:
- Engineer Features:Aggregierte Anzahl von POIs (Points of Interest) wie Fitnessstudios, Schulen und Haltestellen im Umkreis von 500 Metern um Ihre Standorte.
- Modell trainieren:Erstellen Sie mit BigQuery ML ein Regressionsmodell, das diese Umgebungsmerkmale mit Ihren internen Leistungsmesswerten in Beziehung setzt.
- Stadt bewerten:Wenden Sie das trainierte Modell auf das gesamte H3-Raster von London an, um Hotspots mit hohem Potenzial für die zukünftige Expansion zu ermitteln.
Wenn Sie noch nicht mit BigQuery ML vertraut sind, lesen Sie die Einführung in BigQuery ML, um mehr über die wichtigsten Konzepte und unterstützten Modelltypen zu erfahren.
Wenn Sie diesen Workflow in einer interaktiven Umgebung ausprobieren möchten, führen Sie das folgende Notebook aus. Darin wird gezeigt, wie Sie mit BigQuery ML ein Vorhersagemodell erstellen und mit der räumlichen H3-Indexierung Chancen auf Stadtebene visualisieren.
 Quelle auf GitHub ansehen
Quelle auf GitHub ansehen
Vorbereitung
Bevor Sie beginnen, benötigen Sie Folgendes:
Google Cloud-Projekt:
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
Datenzugriff:
- Places Insights-Abo in BigQuery.
- Eine eigene Tabelle mit Website-Standorten und einem Leistungsmesswert (z.B. Umsatz). Ein Beispiel-Dataset finden Sie in den Tutorial-Ressourcen.
Google Maps Platform:
- Ein API-Schlüssel.
- Die folgenden APIs sind für Ihren Schlüssel aktiviert:
Python-Umgebung und -Bibliotheken:
- Eine Python-Umgebung wie Colab Enterprise in der Google Cloud Console.
- Die folgenden Bibliotheken sind installiert:
Bibliothek Beschreibung pandas-gbqMit BigQuery interagieren geopandasVerarbeitung von Vorgängen mit raumbezogenen Daten. foliumInteraktive Karten erstellen. shapelyGeometrische Manipulationen.
IAM-Berechtigungen:
- Ihr Nutzer- oder Dienstkonto muss die folgenden IAM-Rollen haben:
Rolle ID BigQuery-Dateneditor roles/bigquery.dataEditorBigQuery-Nutzer roles/bigquery.user
- Ihr Nutzer- oder Dienstkonto muss die folgenden IAM-Rollen haben:
Kostenbewusstsein:
- In dieser Anleitung werden kostenpflichtige Google Cloud-Komponenten verwendet. Beachten Sie die potenziellen Kosten im Zusammenhang mit:
- BigQuery ML:Die Abrechnung erfolgt für die verwendeten Compute-Slots. BigQuery ML – Preise
- Places Insights:Die Abrechnung erfolgt basierend auf der Abfragenutzung.
- In dieser Anleitung werden kostenpflichtige Google Cloud-Komponenten verwendet. Beachten Sie die potenziellen Kosten im Zusammenhang mit:
Feature Engineering mit Places Insights
Um die externen Faktoren zu isolieren, die die Websiteleistung beeinflussen, müssen Sie Rohdaten zu POIs in quantifizierbare Features umwandeln. Sie berechnen die Dichte bestimmter Einrichtungen oder Arten von Orten wie Fitnessstudios, Schulen und Haltestellen im Umkreis von 500 Metern um jeden Standort. Die von Ihnen ausgewählten Ausstattungsmerkmale hängen davon ab, was Sie für Ihr Unternehmen als am relevantesten erachten.
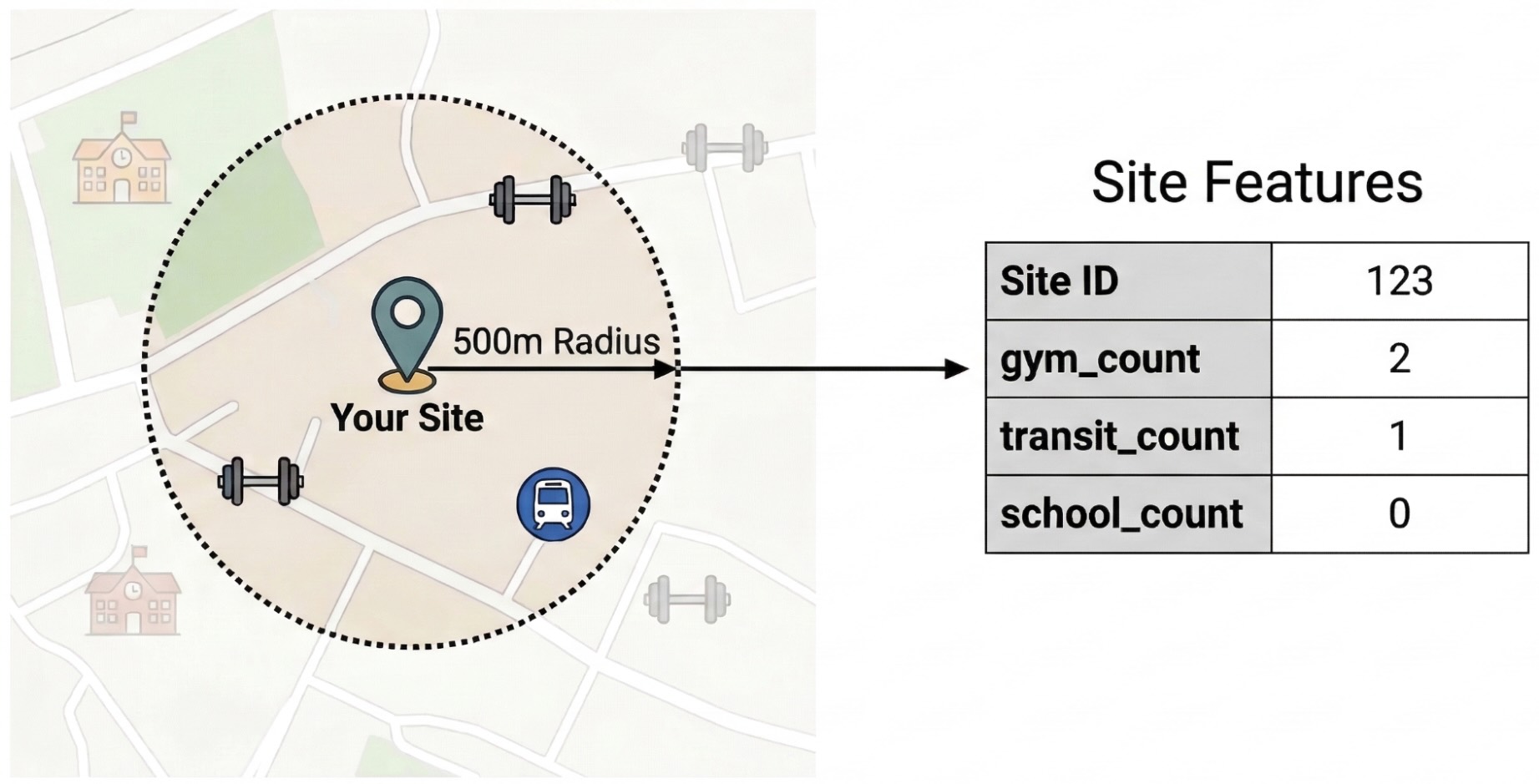
Für diesen Schritt verwenden wir Python und die pandas-gbq-Bibliothek. Mit diesem Ansatz können Sie die SELECT WITH AGGREGATION_THRESHOLD-Abfrage ausführen, die für den Zugriff auf das Places Insights-Dataset erforderlich ist, und die Ergebnisse in einer neuen Tabelle in Ihrem Projekt speichern. Weitere Informationen zum Arbeiten mit Places Insights-Daten finden Sie unter Dataset direkt abfragen.
Feature-Engineering-Abfrage ausführen
Führen Sie das folgende Python-Skript in Ihrer Umgebung aus, z.B. in Colab Enterprise. Mit diesem Skript werden Ihre internen Websitedaten mit dem Places Insights-Dataset verknüpft.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
Suchanfrage verstehen
ST_DWITHIN: Mit dieser geospatialen Funktion wird ein 500‑Meter-Puffer um jeden Standort erstellt und alle Places Insights-Punkte ermittelt, die in diesen Radius fallen.COUNTIF: Mit dieser Funktion wird die Dichte bestimmter Ortstypen (z.B. „Fitnessstudio“, „Schule“) für jede Website berechnet. Diese Anzahl wird zu den Eingabe-Features (X) für das Modell für maschinelles Lernen.pandas_gbq.to_gbq: Mit dieser Funktion werden die Abfrageergebnisse in einer neuen Tabelle (site_features) gespeichert. Diese permanente Tabelle dient als bereinigter Trainingsdatensatz für das BigQuery ML-Modell.
Für komplexere Anwendungen in der realen Welt sollten Sie Attribute in mehreren Entfernungen (z.B. 250 m, 500 m, 1 km) berechnen und andere Places Insights-Attribute wie rating, price_level oder regular_opening_hours verwenden. Eine vollständige Liste der Places Insights-Attribute finden Sie unter unterstützte Ortstypen und in der Referenz zum Kernschema.
Modell mit BigQuery ML trainieren
Nachdem die Engineered Features in der Tabelle site_features gespeichert wurden, können Sie jetzt ein lineares Regressionsmodell trainieren.
In diesem Modell werden die optimalen Gewichte (β) für jedes Umgebungsmerkmal (X) ermittelt, um die Leistung Ihrer Website (Y) vorherzusagen.
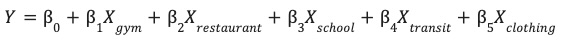
Umgang mit Ausreißern durch robustes Skalieren
Geografische Daten enthalten oft extreme Ausreißer, die Standard-Linearmodelle verzerren können. So gibt es beispielsweise in einem Stadtteil im West End von London möglicherweise 200 Restaurants im Umkreis von 500 Metern, während es in einem Vorort nur 2 Restaurants gibt. Wenn Sie die Standardskalierung (Mittelwert/Standardabweichung) verwenden, verzerrt der Ausreißer (200) die Verteilung und zwingt das Modell, die Anpassung an diesen Extremwert zu priorisieren.
Um dieses Problem zu beheben, verwenden wir in der Modelldefinition Robust Scaling (ML.ROBUST_SCALER). Bei dieser Methode werden die Merkmale auf Grundlage des Medians und des Interquartilbereichs (IQR) skaliert. So ist das Modell weniger anfällig für Ausreißer und lernt aus der typischen Verteilung Ihrer Websites.
Modell erstellen
Führen Sie die folgende SQL-Abfrage in BigQuery aus, um das Modell zu erstellen und zu trainieren.
Mit der Klausel TRANSFORM wird eine robuste Skalierung auf alle Eingabefeatures angewendet. Außerdem haben wir optimize_strategy = 'NORMAL_EQUATION' festgelegt, da dies die effizienteste Trainingsmethode für relativ kleine Datasets wie ein typisches Portfolio von Filialstandorten ist. Schließlich filtern wir leistungsstarke Ausreißer (store_performance <
75) heraus, damit sich das Modell auf die Vorhersage typischer Wachstumsmuster konzentriert.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
Modellleistung bewerten
Bevor Sie den Erkenntnissen des Modells zur Steigerung der Websiteleistung vertrauen können, müssen Sie prüfen, ob die Vorhersagen zutreffend sind.
Verwenden Sie nach dem Training die Funktion ML.EVALUATE, um die Vorhersagen des Modells anhand eines Holdout-Datasets zu bewerten, das während des Trainings nicht verwendet wurde.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
Prüfen Sie den R2-Score (r2_score) und den mittleren absoluten Fehler (mean_absolute_error), um festzustellen, ob Ihr Modell für die Produktion bereit ist:
- Mit dem R2-Wert wird gemessen, wie viel der Leistungsvarianz tatsächlich durch die externen Umgebungsfaktoren (POIs in der Nähe) erklärt wird. Ein R2-Wert von 0,70 bedeutet, dass 70% des Erfolgs einer Website mit der lokalen Umgebung zusammenhängen. Je näher der Wert an 1,0 liegt, desto stärker ist die Korrelation zwischen den Umweltfaktoren und der Standortleistung.
- Der MAE gibt den durchschnittlichen Fehler in Punkten an. Ein MAE von 1,5 bedeutet beispielsweise, dass die Vorhersagen des Modells in der Regel innerhalb von +/- 1,5 Punkten des tatsächlichen Leistungswerts liegen.
Fehlerbehebung bei niedrigen Werten
Wenn Ihr R2-Wert niedrig ist, sollten Sie die folgenden Verbesserungen in Betracht ziehen:
- Elementtypen erweitern:Fügen Sie Ihrer Anfrage verschiedene Ortsarten hinzu, z.B.
tourist_attractionundsubway_station. - Einzugsgebietradius anpassen:Ändern Sie den
ST_DWITHIN-Abstand. Ein Radius von 500 Metern ist für ein Café möglicherweise zu groß, für ein Möbelgeschäft aber zu klein. - Datengröße erhöhen:Achten Sie darauf, dass Sie das Modell mit genügend Geschäftsstandorten trainieren, um ein statistisch signifikantes Muster zu finden.
Bewertung der Stadt mit H3-Raumindexierung
Wir verwenden den H3-Raumindex, um die Stadt London in ein einheitliches Raster aus sechseckigen Zellen (Auflösung 8, ca.0,7 km²) zu unterteilen. Indem wir Places Insights-Daten in diesen Zellen zusammenfassen, können wir unser trainiertes Modell auf jedes Viertel anwenden und Gebiete mit hohem Potenzial identifizieren, die dem Umweltprofil Ihrer leistungsstärksten Standorte entsprechen.
Prospecting-Abfrage ausführen
Für dieses Raster verwenden wir die Funktion PLACES_COUNT_PER_H3 aus dem Places Insights-Dataset. Weitere Informationen zum Abfragen von Places Insights mit Places Count-Funktionen
Mit dieser Funktion wird die Anzahl der POIs für H3-Zellen in einem einzigen Vorgang berechnet.
Führen Sie die folgende SQL-Abfrage aus, um drei Schritte in einem einzigen Vorgang auszuführen:
- H3-Indexierung und ‑Zählung:Wir rufen
PLACES_COUNT_PER_H3mit einem JSON-Konfigurationsobjekt auf, um alle betriebsbereiten Orte im Umkreis von 25 km um das Zentrum von London zu finden. Wir fragen diese Informationen separat für jeden Annehmlichkeitstyp (Fitnessstudios, Schulen usw.) ab und kombinieren sie mitUNION ALL. - Pivotierung (Feature Engineering): Da unser Modell für maschinelles Lernen separate Spalten für Features (z. B.
gym_countundrestaurant_count) erwartet, gruppieren wir die Zellen und verwenden die bedingte Aggregation(SUM(IF(...))), um die Daten in das richtige Schema zu pivotieren. - Vorhersage:Wir geben diese gedrehten Rasterfunktionen direkt in die
ML.PREDICT-Funktion ein, um für jedes Viertel eine Leistungsbewertung zu generieren.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
Ergebnisse interpretieren
Die Abfrage gibt eine Tabelle zurück, in der jede Zeile einen sechseckigen Bereich in London darstellt.
h3_index: Die eindeutige Kennung für die sechseckige Zelle.predicted_store_performance: Die geschätzte Punktzahl des Modells für einen Standort in dieser Zelle, die ausschließlich auf der Umgebung basiert.h3_geography: Die Polygongeometrie der Zelle, die wir im nächsten Schritt zur Visualisierung verwenden.
Hohe Werte weisen auf Gebiete hin, in denen die Dichte von Schulen, Fitnessstudios und öffentlichen Verkehrsmitteln den Mustern entspricht, die in der Umgebung Ihrer erfolgreichsten bestehenden Standorte zu finden sind.
Karte für die Neukundengewinnung visualisieren
Um die Daten nutzbar zu machen, visualisieren Sie die Ergebnisse auf einer Karte. Die tabellarische Ausgabe enthält zwar Rohwerte, aber eine Karte zeigt räumliche Cluster und Korridore mit hohem Potenzial, die in einer Liste nicht offensichtlich sind.
Im zugehörigen Notebook verwenden wir die geopandas-Bibliothek, um die H3-Polygongeometrie zu parsen, und folium, um eine interaktive Karte zu rendern.
Das Ergebnis ist eine Choroplethenkarte, auf der jede sechseckige Zelle entsprechend ihrem vorhergesagten Wert eingefärbt ist.
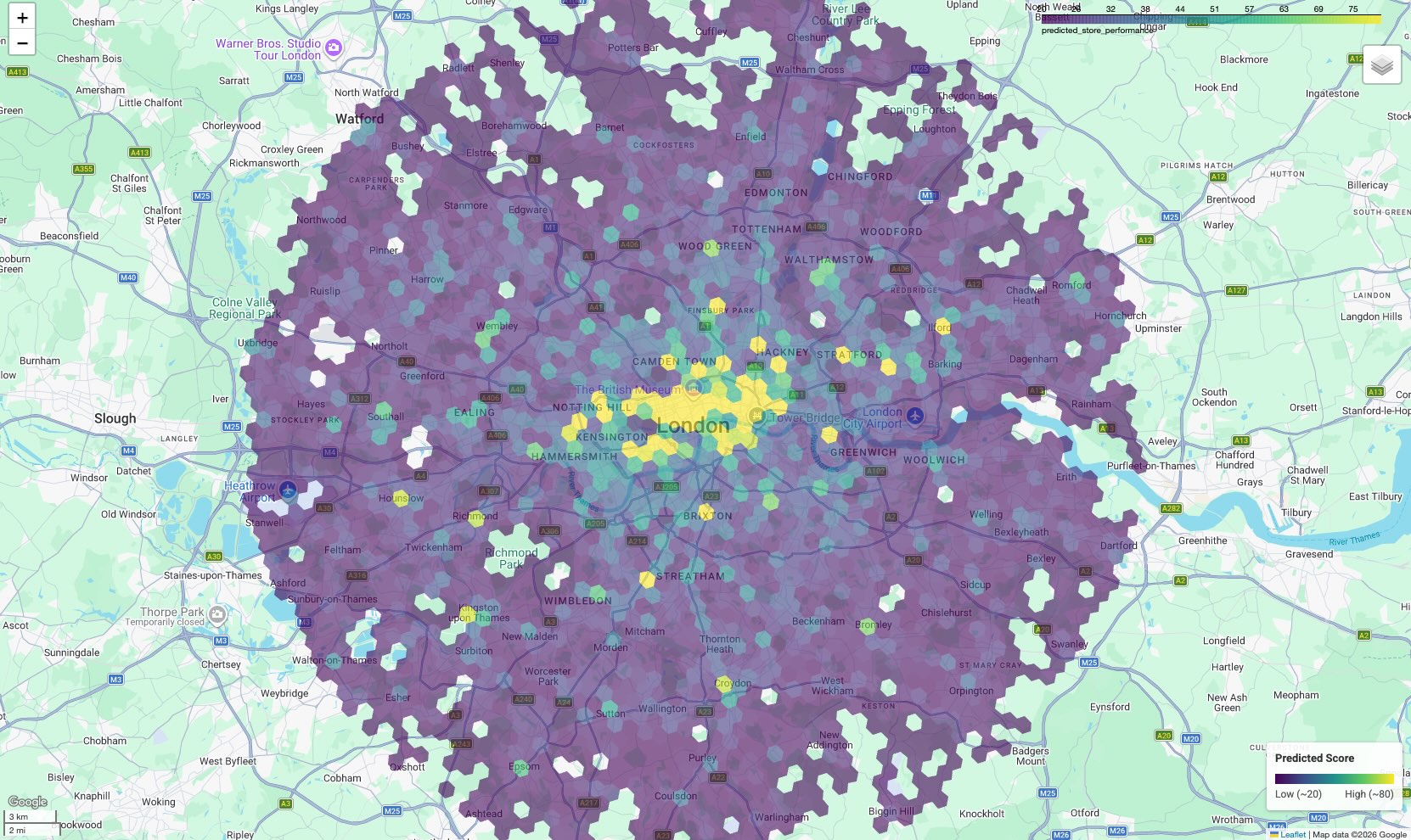
Karte interpretieren:
- Hotspots (Gelb/Grün): Diese Bereiche haben hohe vorhergesagte Leistungswerte. Sie haben die optimale Dichte an Schulen, Fitnessstudios und öffentlichen Verkehrsmitteln, die mit Ihren erfolgreichen Standorten korreliert. Diese sind ideale Kandidaten für die Auswahl neuer Standorte.
- Kältezonen (lila): In diesen Bereichen fehlen die unterstützenden Umgebungsmerkmale, die in der Nähe Ihrer leistungsstärksten Standorte zu finden sind.
- Interaktive Analyse:In der Notebook-Umgebung können Sie den Mauszeiger auf eine beliebige Zelle bewegen, um die genaue Anzahl der Annehmlichkeiten (z.B. „Fitnessstudios: 12“) zu sehen, die zu dieser bestimmten Punktzahl beigetragen haben.
Fazit
Sie haben erfolgreich interne Betriebsdaten mit Places-Statistiken kombiniert, um die Leistung von Standorten zu analysieren. Durch die Analyse der Modellgewichte haben Sie die spezifischen Stadtteileigenschaften ermittelt, die mit Ihren vorhandenen Messwerten korrelieren. Mithilfe der H3-Raumindexierung konnten Sie diese Analyse von einigen Hundert Standorten auf Tausende potenzieller Stadtteile in London ausweiten.
Nächste Aktionen
- Feature Engineering erweitern:Fügen Sie Ihrer Anfrage spezifischere Standorttypen hinzu, um Nischenfaktoren für Ladenbesuche zu erfassen.
- Erweiterte Modelle ausprobieren:Die lineare Regression bietet zwar eine klare Erklärbarkeit, aber Sie sollten auch mit
BOOSTED_TREE_REGRESSORin BigQuery ML in Kombination mit einer geeigneten Kreuzvalidierungsstrategie experimentieren, um nicht lineare Beziehungen zu erfassen. - Karte operationalisieren:Exportieren Sie die H3-Rasterergebnisse in ein benutzerdefiniertes Dashboard mit der Maps JavaScript API, um diese Statistiken mit Ihrem Team zu teilen.
Beitragende
- Henrik Valve | DevX Engineer
- Gennadii Donchyts | Staff Customer Engineer