

একই রকম কর্মী, মজুদ এবং পরিচালন পদ্ধতি থাকা সত্ত্বেও কেন একটি শাখা সফল হয় আর অন্যটি আশানুরূপ ফল দেয় না? একাধিক শাখা থাকা ব্যবসা প্রতিষ্ঠানগুলো প্রায়শই তাদের পোর্টফোলিও জুড়ে এই কর্মক্ষমতার ভিন্নতার কারণ ব্যাখ্যা করতে হিমশিম খায়। এর উত্তরটি সাধারণত বাহ্যিক পরিবেশের মধ্যেই লুকিয়ে থাকে। পয়েন্টস অফ ইন্টারেস্ট (POI) ডেটা ব্যবহার করে, আমরা লোকমুখে শোনা ব্যাখ্যার বাইরে গিয়ে সুনির্দিষ্টভাবে পরিমাপ করতে পারি যে কীভাবে স্থানীয় প্রতিযোগিতামূলক ঘনত্ব এবং আশেপাশের এলাকার বৈশিষ্ট্যগুলো একটি শাখার সাফল্য নির্ধারণ করে।
এই নির্দেশিকাটি প্লেসেস ইনসাইটস এবং বিগকোয়েরি এমএল ব্যবহার করে সাইটের সাফল্যে স্থানীয় পরিবেশের প্রভাব পরিমাপ করার পদ্ধতি প্রদর্শন করে। আপনি পারফরম্যান্সের চালকগুলো নির্ণয় করতে আপনার নিজস্ব সাইট পারফরম্যান্স ডেটার সাথে বাহ্যিক ভূ-স্থানিক সংকেতগুলোকে একত্রিত করবেন।
আমরা একটি লিনিয়ার রিগ্রেশন মডেল তৈরি করতে লন্ডনের বিভিন্ন সাইটের একটি ডেটাসেট ব্যবহার করব। এই কার্যপ্রক্রিয়াটি H3 স্পেশিয়াল ইনডেক্সিং ব্যবহার করে, যা শহরটিকে সুষম ষড়ভুজাকার কোষে বিভক্ত করে। এই কোষগুলিতে পরিবেশগত ডেটা একত্রিত করার মাধ্যমে, আপনি শুধুমাত্র আপনার বিদ্যমান সাইটগুলোই নয়, বরং শহরের যেকোনো এলাকার কর্মক্ষমতার সম্ভাবনা ভবিষ্যদ্বাণী করার জন্য একটি মডেলকে প্রশিক্ষণ দিতে পারেন।
আপনি শিখবেন:
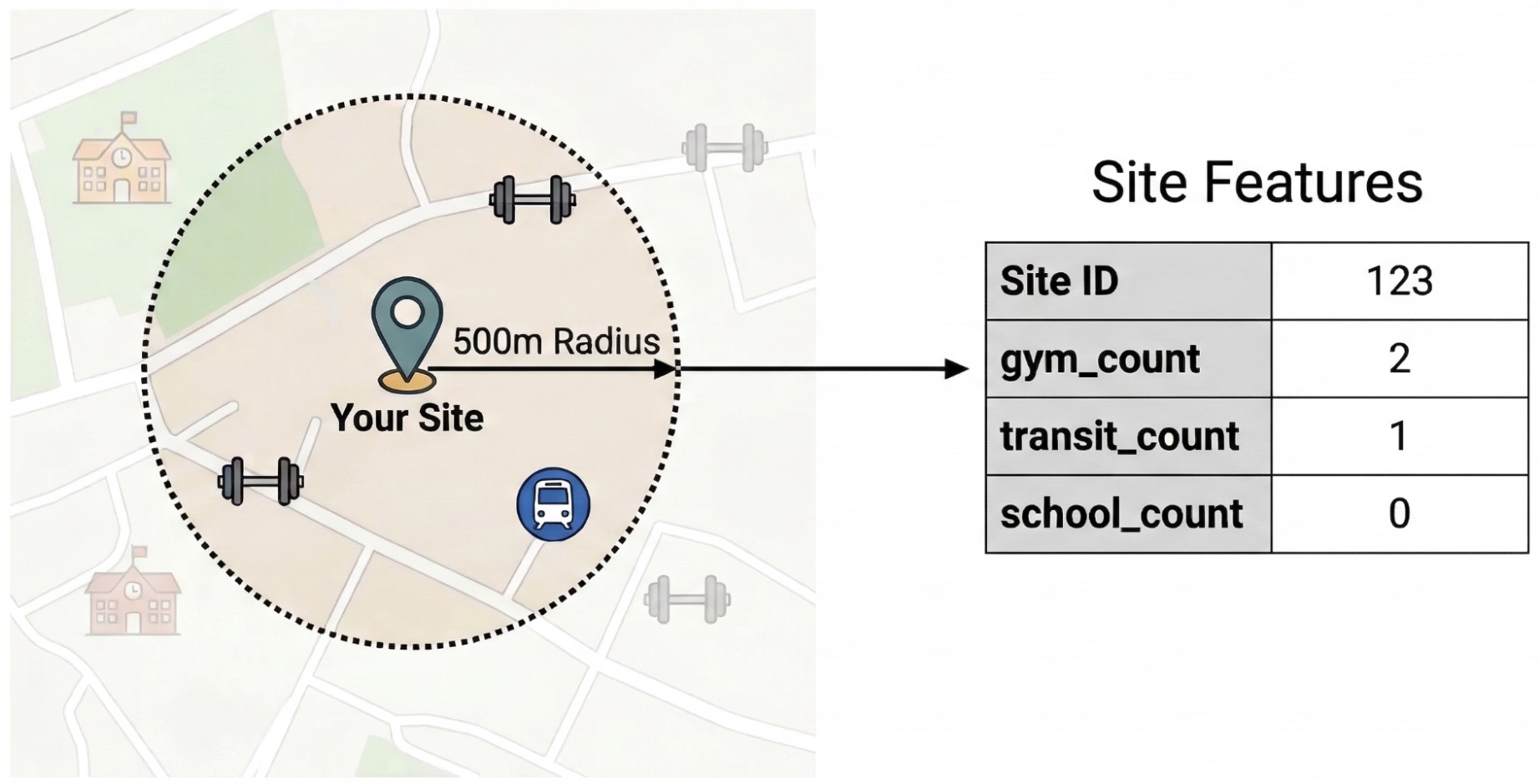
- ইঞ্জিনিয়ার ফিচার: আপনার সাইটগুলোর ৫০০-মিটার ব্যাসার্ধের মধ্যে থাকা জিম, স্কুল এবং ট্রানজিট স্টেশনের মতো আগ্রহের স্থানগুলোর (POI) মোট সংখ্যা গণনা করুন।
- একটি মডেলকে প্রশিক্ষণ দিন: BigQuery ML ব্যবহার করে একটি রিগ্রেশন মডেল তৈরি করুন যা এই পারিপার্শ্বিক বৈশিষ্ট্যগুলোকে আপনার অভ্যন্তরীণ পারফরম্যান্স মেট্রিক্সের সাথে সম্পর্কযুক্ত করে।
- শহরের মূল্যায়ন: ভবিষ্যৎ সম্প্রসারণের জন্য উচ্চ সম্ভাবনাময় হটস্পটগুলো শনাক্ত করতে লন্ডনের সমগ্র H3 গ্রিডে প্রশিক্ষিত মডেলটি প্রয়োগ করুন।
আপনি যদি BigQuery ML-এ নতুন হন, তাহলে এর মূল ধারণা এবং সমর্থিত মডেলের প্রকারভেদ সম্পর্কে জানতে "Introduction to BigQuery ML" দেখুন।
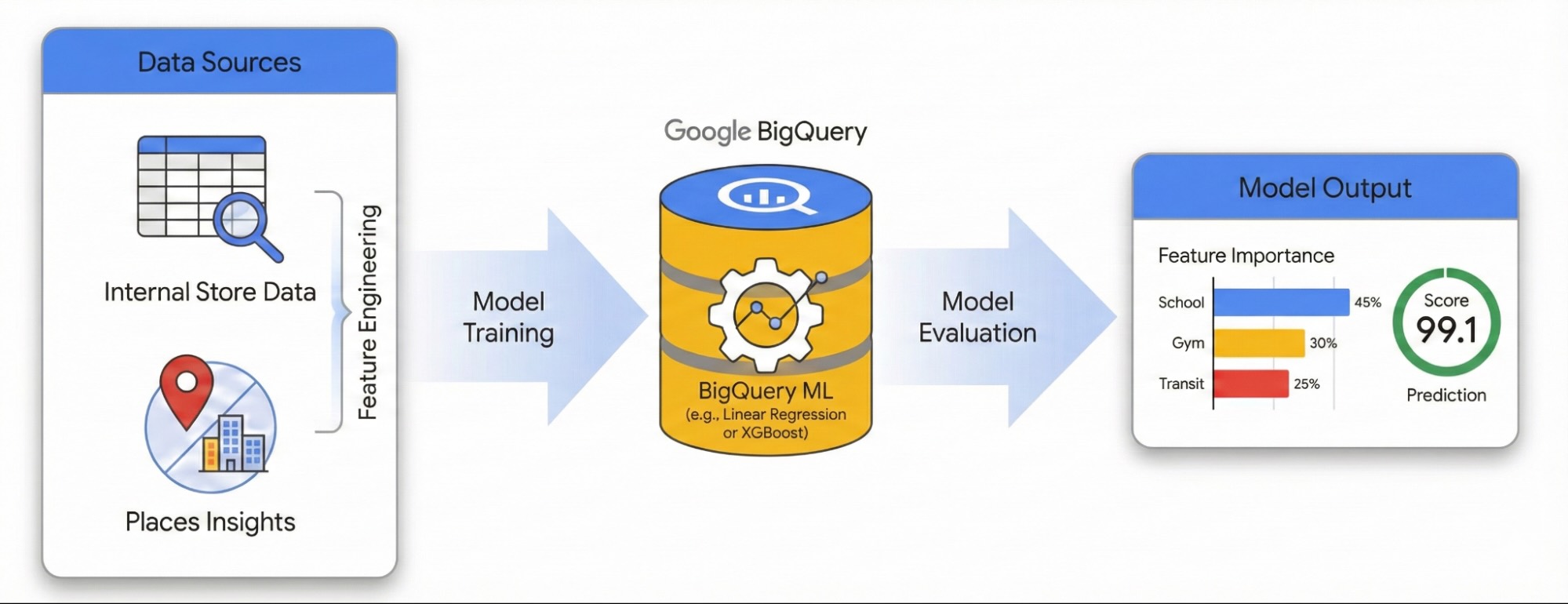
একটি ইন্টারেক্টিভ পরিবেশে এই ওয়ার্কফ্লোটি অন্বেষণ করতে, নিম্নলিখিত নোটবুকটি চালান। এতে দেখানো হয়েছে কীভাবে BigQuery ML ব্যবহার করে একটি প্রেডিক্টিভ মডেল তৈরি করতে হয় এবং H3 স্পেশিয়াল ইনডেক্সিং ব্যবহার করে শহরব্যাপী সুযোগগুলোকে ভিজ্যুয়ালাইজ করতে হয়।
 গিটহাবে উৎস দেখুন
গিটহাবে উৎস দেখুনপূর্বশর্ত
শুরু করার আগে, নিশ্চিত করুন যে আপনার কাছে নিম্নলিখিত জিনিসগুলো আছে:
গুগল ক্লাউড প্রজেক্ট:
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
ডেটা অ্যাক্সেস:
- BigQuery-তে Places Insights সাবস্ক্রিপশন ।
- পারফরম্যান্স মেট্রিক (যেমন, রাজস্ব) সহ আপনার নিজস্ব সাইটের অবস্থানের একটি টেবিল। টিউটোরিয়াল রিসোর্সে একটি উদাহরণ ডেটাসেট রয়েছে।
গুগল ম্যাপস প্ল্যাটফর্ম:
- একটি এপিআই কী ।
- আপনার কী-এর জন্য নিম্নলিখিত API গুলি সক্রিয় করা হয়েছে:
পাইথন পরিবেশ ও লাইব্রেরিসমূহ:
- গুগল ক্লাউড কনসোলে কোলাব এন্টারপ্রাইজের মতো একটি পাইথন পরিবেশ।
- নিম্নলিখিত লাইব্রেরিগুলি ইনস্টল করা হয়েছে:
লাইব্রেরি বর্ণনা pandas-gbqBigQuery-এর সাথে মিথস্ক্রিয়া। geopandasভূ-স্থানিক ডেটা কার্যক্রম পরিচালনা করা। foliumইন্টারেক্টিভ মানচিত্র তৈরি করা। shapelyজ্যামিতিক কারসাজি।
আইএএম অনুমতিসমূহ:
- নিশ্চিত করুন যে আপনার ব্যবহারকারী বা পরিষেবা অ্যাকাউন্টে নিম্নলিখিত IAM রোলগুলি রয়েছে:
ভূমিকা আইডি বিগকোয়েরি ডেটা এডিটর roles/bigquery.dataEditorবিগকোয়েরি ব্যবহারকারী roles/bigquery.user
- নিশ্চিত করুন যে আপনার ব্যবহারকারী বা পরিষেবা অ্যাকাউন্টে নিম্নলিখিত IAM রোলগুলি রয়েছে:
ব্যয় সচেতনতা:
- এই টিউটোরিয়ালে বিলযোগ্য গুগল ক্লাউড উপাদানসমূহ ব্যবহার করা হয়েছে। নিম্নলিখিত বিষয় সম্পর্কিত সম্ভাব্য খরচ সম্পর্কে সচেতন থাকুন:
- BigQuery ML: ব্যবহৃত কম্পিউট স্লটের জন্য চার্জ প্রযোজ্য। BigQuery ML-এর মূল্যতালিকা দেখুন।
- প্লেসেস ইনসাইটস: কোয়েরি ব্যবহারের উপর ভিত্তি করে চার্জ প্রযোজ্য।
- এই টিউটোরিয়ালে বিলযোগ্য গুগল ক্লাউড উপাদানসমূহ ব্যবহার করা হয়েছে। নিম্নলিখিত বিষয় সম্পর্কিত সম্ভাব্য খরচ সম্পর্কে সচেতন থাকুন:
প্লেসেস ইনসাইটস-এর সাথে ফিচার ইঞ্জিনিয়ারিং
সাইটের পারফরম্যান্সকে প্রভাবিতকারী বাহ্যিক কারণগুলোকে আলাদা করতে, আপনাকে অবশ্যই POI-এর কাঁচা ডেটাকে পরিমাপযোগ্য বৈশিষ্ট্যে রূপান্তর করতে হবে। আপনি প্রতিটি সাইটের ৫০০-মিটার ব্যাসার্ধের মধ্যে জিম, স্কুল এবং ট্রানজিট স্টেশনের মতো নির্দিষ্ট সুযোগ-সুবিধা বা স্থানের ঘনত্ব গণনা করবেন। আপনার ব্যবসার জন্য কোনটি সবচেয়ে প্রাসঙ্গিক হতে পারে বলে আপনি মনে করেন, তার উপর ভিত্তি করেই আপনি সুযোগ -সুবিধাগুলো নির্বাচন করবেন।
এই ধাপের জন্য আমরা পাইথন এবং pandas-gbq লাইব্রেরি ব্যবহার করি। এই পদ্ধতিটি আপনাকে SELECT WITH AGGREGATION_THRESHOLD কোয়েরিটি এক্সিকিউট করতে দেয়, যা Places Insights ডেটাসেট অ্যাক্সেস করার জন্য প্রয়োজন, এবং এর ফলাফল আপনার প্রোজেক্টের একটি নতুন টেবিলে সেভ করে। Places Insights ডেটা নিয়ে কাজ করার বিষয়ে আরও তথ্যের জন্য "সরাসরি ডেটাসেট কোয়েরি করুন" দেখুন।
ফিচার ইঞ্জিনিয়ারিং কোয়েরিটি চালান
আপনার পরিবেশে (যেমন, কোলাব এন্টারপ্রাইজ ) নিম্নলিখিত পাইথন স্ক্রিপ্টটি চালান। এই স্ক্রিপ্টটি আপনার অভ্যন্তরীণ সাইটের ডেটাকে প্লেসেস ইনসাইটস ডেটাসেটের সাথে সংযুক্ত করে।
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
প্রশ্নটি বুঝুন
-
ST_DWITHIN: এই ভূ-স্থানিক ফাংশনটি প্রতিটি সাইট অবস্থানের চারপাশে একটি ৫০০-মিটার বাফার তৈরি করে এবং সেই ব্যাসার্ধের মধ্যে থাকা সমস্ত প্লেসেস ইনসাইটস পয়েন্ট শনাক্ত করে। -
COUNTIF: এই ফাংশনটি প্রতিটি সাইটের জন্য নির্দিষ্ট স্থানের প্রকারের (যেমন, 'জিম', 'স্কুল') ঘনত্ব গণনা করে। এই গণনাগুলো মেশিন লার্নিং মডেলের জন্য ইনপুট বৈশিষ্ট্য ( X ) হয়ে ওঠে। -
pandas_gbq.to_gbq: এই ফাংশনটি কোয়েরির ফলাফল একটি নতুন টেবিলে (site_features) সংরক্ষণ করে। এই স্থায়ী টেবিলটি BigQuery ML মডেলের জন্য একটি পরিষ্কার প্রশিক্ষণ ডেটাসেট হিসেবে কাজ করে।
আরও উন্নত বাস্তব-জগতের অ্যাপ্লিকেশনের জন্য, একাধিক দূরত্বে (যেমন, ২৫০মি, ৫০০মি, ১কিমি) ফিচার গণনা করার কথা বিবেচনা করুন এবং rating , price_level বা regular_opening_hours এর মতো অন্যান্য প্লেসেস ইনসাইটস অ্যাট্রিবিউটগুলো অন্বেষণ করুন। প্লেসেস ইনসাইটস অ্যাট্রিবিউটগুলোর সম্পূর্ণ তালিকার জন্য সমর্থিত স্থানের প্রকার এবং কোর স্কিমা রেফারেন্স দেখুন।
BigQuery ML দিয়ে মডেলটিকে প্রশিক্ষণ দিন
আপনার site_features টেবিলে সংরক্ষিত পরিকল্পিত বৈশিষ্ট্যগুলো দিয়ে, আপনি এখন একটি লিনিয়ার রিগ্রেশন মডেলকে প্রশিক্ষণ দিতে পারেন।
এই মডেলটি আপনার সাইটের পারফরম্যান্স ( Y ) ভবিষ্যদ্বাণী করার জন্য প্রতিটি পরিবেশগত বৈশিষ্ট্য ( X )-এর সর্বোত্তম ওয়েট ( β ) শেখে।
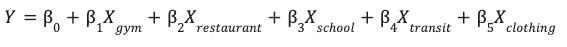
রোবাস্ট স্কেলিং ব্যবহার করে আউটলায়ারগুলি পরিচালনা করুন
ভূ-স্থানিক ডেটাতে প্রায়শই চরম আউটলায়ার থাকে যা সাধারণ লিনিয়ার মডেলকে বিকৃত করতে পারে। উদাহরণস্বরূপ, লন্ডনের ওয়েস্ট এন্ডের একটি সাইটে ৫০০ মিটারের মধ্যে ২০০টি রেস্তোরাঁ থাকতে পারে, যেখানে একটি শহরতলির সাইটে মাত্র ২টি আছে। আপনি যদি স্ট্যান্ডার্ড স্কেলিং (গড়/স্ট্যান্ডার্ড ডেভিয়েশন) ব্যবহার করেন, তাহলে আউটলায়ারটি (২০০) ডেটার বিন্যাসকে প্রভাবিত করে এবং মডেলটিকে ঐ চরম মানটিকে মডেল হিসেবে ফিট করার জন্য অগ্রাধিকার দিতে বাধ্য করে।
এর সমাধানে, আমরা মডেল ডেফিনিশনের মধ্যে রোবাস্ট স্কেলিং ( ML.ROBUST_SCALER ) ব্যবহার করি। এই কৌশলটি মিডিয়ান এবং ইন্টারকোয়ার্টাইল রেঞ্জ (IQR)-এর উপর ভিত্তি করে ফিচারগুলোকে স্কেল করে, যা মডেলটিকে আউটলায়ারের বিরুদ্ধে সহনশীল করে তোলে এবং এটি আপনার সাইটগুলোর সাধারণ ডিস্ট্রিবিউশন থেকে শিখতে পারে তা নিশ্চিত করে।
মডেলটি তৈরি করুন
মডেলটি তৈরি ও প্রশিক্ষণ দিতে BigQuery-তে নিম্নলিখিত SQL কোয়েরিটি চালান।
আমরা সমস্ত ইনপুট ফিচারে রোবাস্ট স্কেলিং প্রয়োগ করতে TRANSFORM ক্লজটি ব্যবহার করি। আমরা optimize_strategy = 'NORMAL_EQUATION' সেট করি, কারণ এটি তুলনামূলকভাবে ছোট ডেটাসেটের জন্য সবচেয়ে কার্যকর প্রশিক্ষণ পদ্ধতি, যেমন দোকানের অবস্থানের একটি সাধারণ পোর্টফোলিও। পরিশেষে, মডেলটিকে সাধারণ বৃদ্ধির ধরণ ভবিষ্যদ্বাণী করার দিকে মনোনিবেশ করাতে আমরা উচ্চ-কার্যক্ষমতাসম্পন্ন আউটলায়ারগুলিকে ( store_performance < 75 ) ফিল্টার করে বাদ দিই।
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
মডেলের কর্মক্ষমতা মূল্যায়ন করুন
সাইটের পারফরম্যান্সের চালিকাশক্তি সম্পর্কে মডেলের অন্তর্দৃষ্টি বিশ্বাস করার আগে, আপনাকে অবশ্যই এর পূর্বাভাসগুলো নির্ভুল কিনা তা যাচাই করতে হবে।
প্রশিক্ষণের পরে, প্রশিক্ষণের সময় ব্যবহৃত হয়নি এমন একটি 'হোল্ডআউট' ডেটা সেটের সাথে মডেলের পূর্বাভাসগুলো মূল্যায়ন করতে ML.EVALUATE ফাংশনটি ব্যবহার করুন।
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
আপনার মডেলটি প্রোডাকশনের জন্য প্রস্তুত কিনা তা নির্ধারণ করতে R2 স্কোর ( r2_score ) এবং গড় পরম ত্রুটি ( mean_absolute_error ) পরীক্ষা করুন:
- একটি R2 স্কোর পরিমাপ করে যে, কর্মক্ষমতার তারতম্যের কতটুকু প্রকৃতপক্ষে বাহ্যিক পরিবেশগত কারণসমূহ (নিকটবর্তী দর্শনীয় স্থান) দ্বারা ব্যাখ্যা করা যায়। ০.৭০-এর একটি R2 স্কোরের অর্থ হলো, একটি স্থানের সাফল্যের ৭০% স্থানীয় পরিবেশের সাথে সম্পর্কিত। এর মান ১.০-এর যত কাছাকাছি হবে, পরিবেশগত সুযোগ-সুবিধা এবং স্থানের কর্মক্ষমতার মধ্যে পারস্পরিক সম্পর্ক তত শক্তিশালী হবে।
- MAE আপনাকে পয়েন্টে গড় ত্রুটি বলে দেয়। উদাহরণস্বরূপ, ১.৫ এর একটি MAE মানে হলো মডেলের পূর্বাভাসগুলো সাধারণত প্রকৃত পারফরম্যান্স স্কোরের +/- ১.৫ পয়েন্টের মধ্যে থাকে।
কম স্কোরের সমস্যা সমাধান
আপনার R2 স্কোর কম হলে, নিম্নলিখিত উন্নতিগুলো বিবেচনা করুন:
- বৈশিষ্ট্যের প্রকারভেদ প্রসারিত করুন: আপনার কোয়েরিতে বিভিন্ন স্থানের প্রকারভেদ যোগ করুন (যেমন,
tourist_attraction,subway_station)। - ক্যাচমেন্ট ব্যাসার্ধ সমন্বয় করুন:
ST_DWITHINদূরত্ব পরিবর্তন করুন। একটি ৫০০-মিটার ব্যাসার্ধ একটি কফি শপের জন্য খুব প্রশস্ত হতে পারে, কিন্তু একটি আসবাবপত্রের দোকানের জন্য খুব ছোট হতে পারে। - ডেটার পরিমাণ বাড়ান: পরিসংখ্যানগতভাবে তাৎপর্যপূর্ণ একটি প্যাটার্ন খুঁজে পেতে পর্যাপ্ত সংখ্যক স্টোরের অবস্থানের উপর প্রশিক্ষণ নিশ্চিত করুন।
H3 স্পেশাল ইনডেক্সিং ব্যবহার করে শহরটির স্কোর নির্ধারণ করুন
আমরা H3 স্পেশাল ইনডেক্সিং ব্যবহার করে লন্ডন শহরকে ষড়ভুজাকার কোষের (রেজোলিউশন ৮, প্রায় ০.৭ বর্গ কিমি) একটি সুষম গ্রিডে বিভক্ত করি। এই কোষগুলিতে প্লেসেস ইনসাইটস ডেটা একত্রিত করার মাধ্যমে, আমরা প্রতিটি পাড়ায় আমাদের প্রশিক্ষিত মডেলটি প্রয়োগ করতে পারি এবং আপনার সেরা পারফর্মিং সাইটগুলির পরিবেশগত প্রোফাইলের সাথে মেলে এমন উচ্চ-সম্ভাবনাময় এলাকাগুলি শনাক্ত করতে পারি।
প্রোস্পেক্টিং কোয়েরিটি চালান
এই গ্রিডটি তৈরি করতে, আমরা প্লেসেস ইনসাইটস ডেটাসেট দ্বারা প্রদত্ত PLACES_COUNT_PER_H3 ফাংশনটি ব্যবহার করি ( প্লেসেস কাউন্ট ফাংশন ব্যবহার করে প্লেসেস ইনসাইটস কোয়েরি করার বিষয়ে আরও জানুন)। এই ফাংশনটি একটি একক অপারেশনে H3 গ্রিড সেলগুলির জন্য POI গণনা করে।
একবারে তিনটি ধাপ সম্পন্ন করতে নিম্নলিখিত SQL কোয়েরিটি চালান:
- H3 ইন্ডেক্সিং ও গণনা: সেন্ট্রাল লন্ডনের ২৫ কিমি ব্যাসার্ধের মধ্যে অবস্থিত সমস্ত চালু স্থান খুঁজে বের করার জন্য আমরা একটি JSON কনফিগারেশন অবজেক্ট ব্যবহার করে
PLACES_COUNT_PER_H3কল করি। আমরা প্রতিটি সুবিধার ধরনের (যেমন জিম, স্কুল ইত্যাদি) জন্য আলাদাভাবে কোয়েরি করি এবংUNION ALLব্যবহার করে সেগুলোকে একত্রিত করি। - পিভোটিং (ফিচার ইঞ্জিনিয়ারিং): যেহেতু আমাদের মেশিন লার্নিং মডেলটি স্বতন্ত্র ফিচার কলাম (যেমন
gym_countএবংrestaurant_count) প্রত্যাশা করে, তাই আমরা সেলগুলোকে গ্রুপ করি এবং ডেটাকে সঠিক স্কিমাতে পিভট করার জন্য কন্ডিশনাল অ্যাগ্রিগেশন(SUM(IF(...)))ব্যবহার করি। - পূর্বাভাস: প্রতিটি নেইবারহুডের জন্য একটি পারফরম্যান্স স্কোর তৈরি করতে আমরা এই পিভট করা গ্রিড ফিচারগুলোকে সরাসরি
ML.PREDICTফাংশনে ইনপুট হিসেবে দিই।
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
ফলাফল ব্যাখ্যা করুন
কোয়েরিটি একটি টেবিল ফেরত দেয়, যেখানে প্রতিটি সারি লন্ডনের একটি ষড়ভুজাকার এলাকাকে প্রতিনিধিত্ব করে।
-
h3_index: ষড়ভুজাকার সেলটির অনন্য শনাক্তকারী। -
predicted_store_performance: শুধুমাত্র পারিপার্শ্বিক পরিবেশের উপর ভিত্তি করে, এই সেলে অবস্থিত একটি সাইটের জন্য মডেলের আনুমানিক স্কোর। -
h3_geography: সেলটির বহুভুজ জ্যামিতি, যা আমরা পরবর্তী ধাপে ভিজ্যুয়ালাইজেশনের জন্য ব্যবহার করব।
উচ্চ মান এমন এলাকা নির্দেশ করে যেখানে স্কুল, জিম এবং গণপরিবহনের ঘনত্ব আপনার সবচেয়ে সফল বিদ্যমান সাইটগুলোর আশেপাশের বিন্যাসের সাথে মিলে যায়।
অনুসন্ধান মানচিত্রটি কল্পনা করুন
ডেটাকে কার্যকর করে তোলার জন্য, ফলাফলগুলো একটি মানচিত্রে প্রদর্শন করুন। সারণি আকারে প্রাপ্ত ফলাফল যেখানে প্রাথমিক স্কোর প্রদান করে, সেখানে একটি মানচিত্র উচ্চ সম্ভাবনাময় স্থানিক গুচ্ছ ও করিডোরগুলো উন্মোচন করে, যা কোনো তালিকায় সহজে চোখে পড়ে না।
সংযুক্ত নোটবুকে, আমরা H3 পলিগন জ্যামিতি পার্স করতে geopandas লাইব্রেরি এবং একটি ইন্টারেক্টিভ মানচিত্র রেন্ডার করতে folium ব্যবহার করেছি।
এর ফলে একটি কোরোপ্লেথ মানচিত্র তৈরি হয়, যেখানে প্রতিটি ষড়ভুজাকার ঘর তার পূর্বাভাসিত স্কোর অনুযায়ী রঙিন করা থাকে।
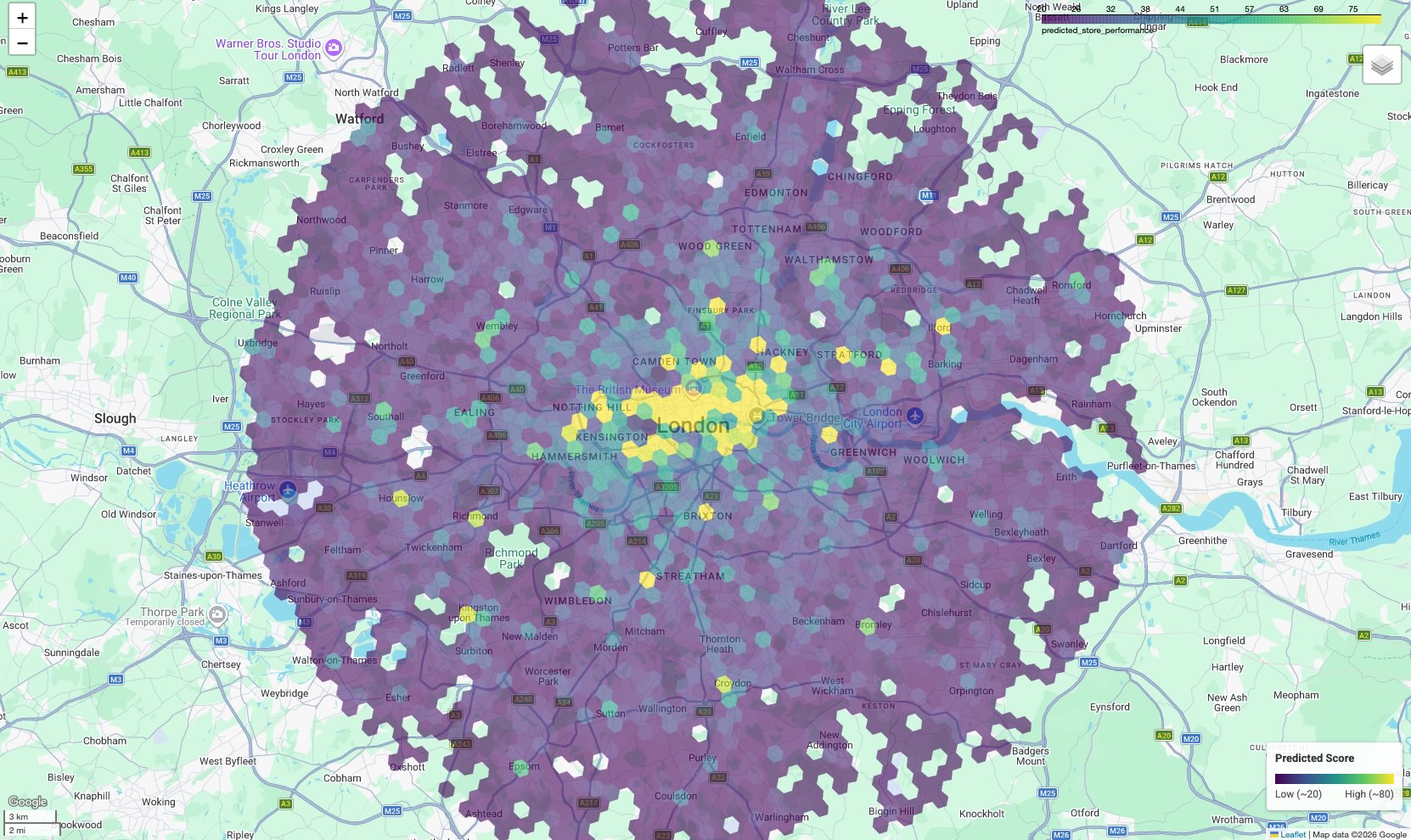
মানচিত্রটি ব্যাখ্যা করুন:
- হটস্পট (হলুদ/সবুজ): এই এলাকাগুলোর প্রত্যাশিত পারফরম্যান্স স্কোর উচ্চ। এগুলোতে স্কুল, জিম এবং গণপরিবহনের সর্বোত্তম ঘনত্ব রয়েছে, যা আপনার সফল সাইটগুলোর সাথে সামঞ্জস্যপূর্ণ। নতুন সাইট নির্বাচনের জন্য এগুলোই প্রধান প্রার্থী।
- শীতল স্থান (বেগুনি): এই এলাকাগুলিতে আপনার সেরা ফলনশীল স্থানগুলির কাছাকাছি থাকা সহায়ক পরিবেশগত বৈশিষ্ট্যগুলির অভাব রয়েছে।
- ইন্টারেক্টিভ পরিদর্শন: নোটবুক পরিবেশে, আপনি যেকোনো সেলের উপর মাউস রাখলে সেই নির্দিষ্ট স্কোরে অবদান রাখা সুযোগ-সুবিধাগুলোর (যেমন, "জিম: ১২") সুনির্দিষ্ট সংখ্যা দেখতে পাবেন।
উপসংহার
আপনি সাইটের পারফরম্যান্স নির্ণয় করতে অভ্যন্তরীণ অপারেশনাল ডেটার সাথে প্লেসেস ইনসাইটস সফলভাবে একত্রিত করেছেন। মডেলের ওয়েটগুলো বিশ্লেষণ করে, আপনি এলাকার সেই নির্দিষ্ট বৈশিষ্ট্যগুলো শনাক্ত করেছেন যা আপনার বিদ্যমান মেট্রিকগুলোর সাথে সম্পর্কযুক্ত। H3 স্পেশিয়াল ইনডেক্সিং ব্যবহার করে, আপনি এই বিশ্লেষণটিকে কয়েকশ সাইট থেকে লন্ডনের হাজার হাজার সম্ভাব্য এলাকায় বিস্তৃত করেছেন।
পরবর্তী পদক্ষেপ
- ফিচার ইঞ্জিনিয়ারিং প্রসারিত করুন: পদচারণার বিশেষ চালকগুলোকে শনাক্ত করতে আপনার কোয়েরিতে আরও সুনির্দিষ্ট স্থানের ধরন যোগ করুন।
- উন্নত মডেলগুলো অন্বেষণ করুন: যদিও লিনিয়ার রিগ্রেশন সুস্পষ্ট ব্যাখ্যাযোগ্যতা প্রদান করে, অরৈখিক সম্পর্কগুলো অনুধাবন করতে BigQuery ML-এ
BOOSTED_TREE_REGRESSORকে একটি উপযুক্ত ক্রস-ভ্যালিডেশন কৌশলের সাথে মিলিয়ে পরীক্ষা করুন। - ম্যাপটি কার্যকর করুন: আপনার দলের সাথে এই অন্তর্দৃষ্টিগুলো ভাগ করে নিতে, ম্যাপস জাভাস্ক্রিপ্ট এপিআই ব্যবহার করে H3 গ্রিডের ফলাফল একটি কাস্টম ড্যাশবোর্ডে এক্সপোর্ট করুন।
অবদানকারীরা
- হেনরিক ভালভ | ডেভএক্স ইঞ্জিনিয়ার
- গেন্নাদি ডনচিটস | স্টাফ কাস্টমার ইঞ্জিনিয়ার