

لماذا يحقق موقع إلكتروني نجاحًا كبيرًا بينما يكون أداء موقع آخر ضعيفًا على الرغم من توفّر عدد الموظفين والمخزون والممارسات التشغيلية نفسها؟ تواجه المؤسسات التي لديها مواقع جغرافية متعددة صعوبة في تفسير هذا التباين في الأداء على مستوى محفظتها. عادةً ما يكون الجواب مخفيًا في البيئة الخارجية. من خلال الاستفادة من بيانات نقاط الاهتمام، يمكننا تجاوز التفسيرات المستندة إلى الحكايات وتحديد كيفية تأثير كثافة المنافسة المحلية وخصائص الحي بشكل دقيق على نجاح الموقع الإلكتروني.
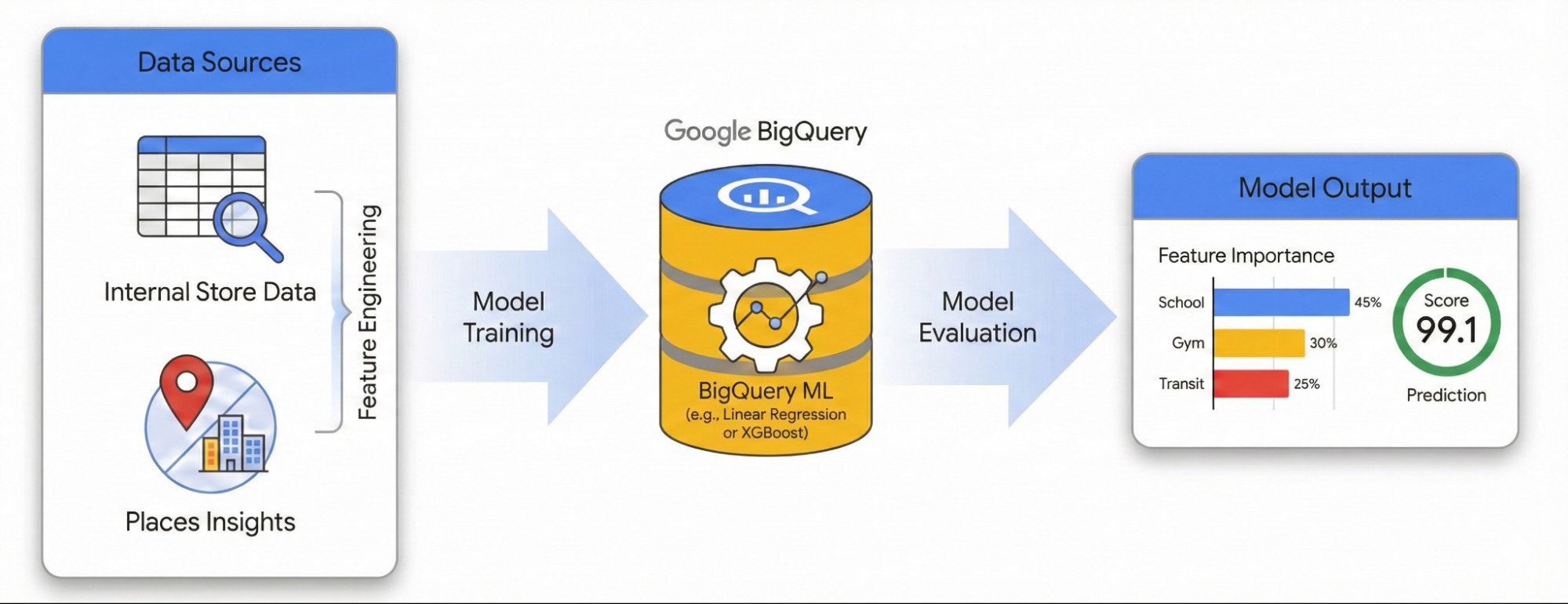
يوضّح هذا الدليل كيفية تحديد تأثير المحيط المحلي على نجاح الموقع باستخدام إحصاءات الأماكن و BigQuery ML. ستجمع بيانات أداء موقعك الإلكتروني الخاصة مع الإشارات الجغرافية المكانية الخارجية لتشخيص العوامل التي تؤثر في الأداء.
سنستخدم مجموعة بيانات للمواقع الإلكترونية في لندن لإنشاء نموذج انحدار خطي. تستخدم سير العمل هذا نظام H3 Spatial Indexing الذي يقسّم المدينة إلى خلايا سداسية منتظمة. من خلال تجميع البيانات البيئية في هذه الخلايا، يمكنك تدريب نموذج للتنبؤ بإمكانات الأداء لأي حي في المدينة، وليس فقط مواقعك الإلكترونية الحالية.
ستتعرّف على ما يلي:
- هندسة الخصائص: يمكنك تجميع أعداد نقاط الاهتمام (POIs)، مثل الصالات الرياضية والمدارس ومحطات النقل العام، ضمن نطاق 500 متر من مواقعك.
- تدريب نموذج: يمكنك استخدام BigQuery ML لإنشاء نموذج انحدار يربط هذه الخصائص البيئية بمقاييس الأداء الداخلية.
- تسجيل نقاط للمدينة: يمكنك تطبيق النموذج الذي تم تدريبه على شبكة H3 بالكامل في لندن لتحديد النقاط الفعّالة المحتملة للتوسّع في المستقبل.
إذا كنت مستخدمًا جديدًا لـ BigQuery ML، يمكنك الاطّلاع على مقدّمة عن BigQuery ML للتعرّف على المفاهيم الأساسية وأنواع النماذج المتوافقة.
لاستكشاف سير العمل هذا في بيئة تفاعلية، يمكنك تشغيل دفتر الملاحظات التالي. يوضّح دفتر الملاحظات كيفية إنشاء نموذج تنبؤي باستخدام BigQuery ML وعرض الفرص على مستوى المدينة باستخدام نظام H3 spatial indexing.
 عرض المصدر على GitHub
عرض المصدر على GitHub
المتطلبات الأساسية
قبل البدء، تأكَّد من توفّر ما يلي:
مشروع Google Cloud:
- مشروع Google Cloud مفعَّلة فيه الفوترة
الوصول إلى البيانات:
- الاشتراك في إحصاءات الأماكن في BigQuery.
- جدول خاص بمواقعك الإلكترونية يتضمّن مقياس أداء (مثل الإيرادات). تتوفّر مجموعة بيانات مثال في مراجع البرنامج التعليمي.
منصة خرائط Google:
- مفتاح واجهة برمجة التطبيقات.
- واجهات برمجة التطبيقات التالية مفعّلة لمفتاحك:
بيئة Python والمكتبات:
- بيئة Python، مثل Colab Enterprise في Google Cloud Console
- المكتبات التالية مثبّتة:
المكتبة الوصف pandas-gbqالتفاعل مع BigQuery geopandasالتعامل مع عمليات البيانات الجغرافية المكانية foliumإنشاء خرائط تفاعلية shapelyالتعامل مع الأشكال الهندسية
أذونات إدارة الهوية والوصول (IAM):
- تأكَّد من أنّ حساب المستخدم أو حساب الخدمة لديه الأدوار التالية في إدارة الهوية وإمكانية الوصول:
الدور رقم التعريف محرِّر بيانات BigQuery roles/bigquery.dataEditorمستخدم BigQuery roles/bigquery.user
- تأكَّد من أنّ حساب المستخدم أو حساب الخدمة لديه الأدوار التالية في إدارة الهوية وإمكانية الوصول:
معرفة التكاليف:
- يستخدم هذا البرنامج التعليمي مكوّنات Google Cloud قابلة للفوترة. يُرجى العِلم بالتكاليف المحتملة المرتبطة بما يلي:
- BigQuery ML: يتم تحصيل رسوم مقابل وحدات الحوسبة المستخدَمة. يمكنك الاطّلاع على أسعار BigQuery ML للتسعير.
- إحصاءات الأماكن: يتم تحصيل رسوم استنادًا إلى استخدام طلبات البحث.
- يستخدم هذا البرنامج التعليمي مكوّنات Google Cloud قابلة للفوترة. يُرجى العِلم بالتكاليف المحتملة المرتبطة بما يلي:
هندسة الخصائص باستخدام إحصاءات الأماكن
لعزل العوامل الخارجية التي تؤثر في أداء الموقع الإلكتروني، عليك تحويل بيانات نقاط الاهتمام الأولية إلى خصائص قابلة للقياس. ستحسب كثافة وسائل الراحة أو أنواع الأماكن المحدّدة، مثل الصالات الرياضية والمدارس ومحطات النقل العام، ضمن نطاق 500 متر من كل موقع. ستعتمد وسائل الراحة التي تختارها على ما تعتقد أنّه قد يكون الأكثر صلة بمؤسستك.
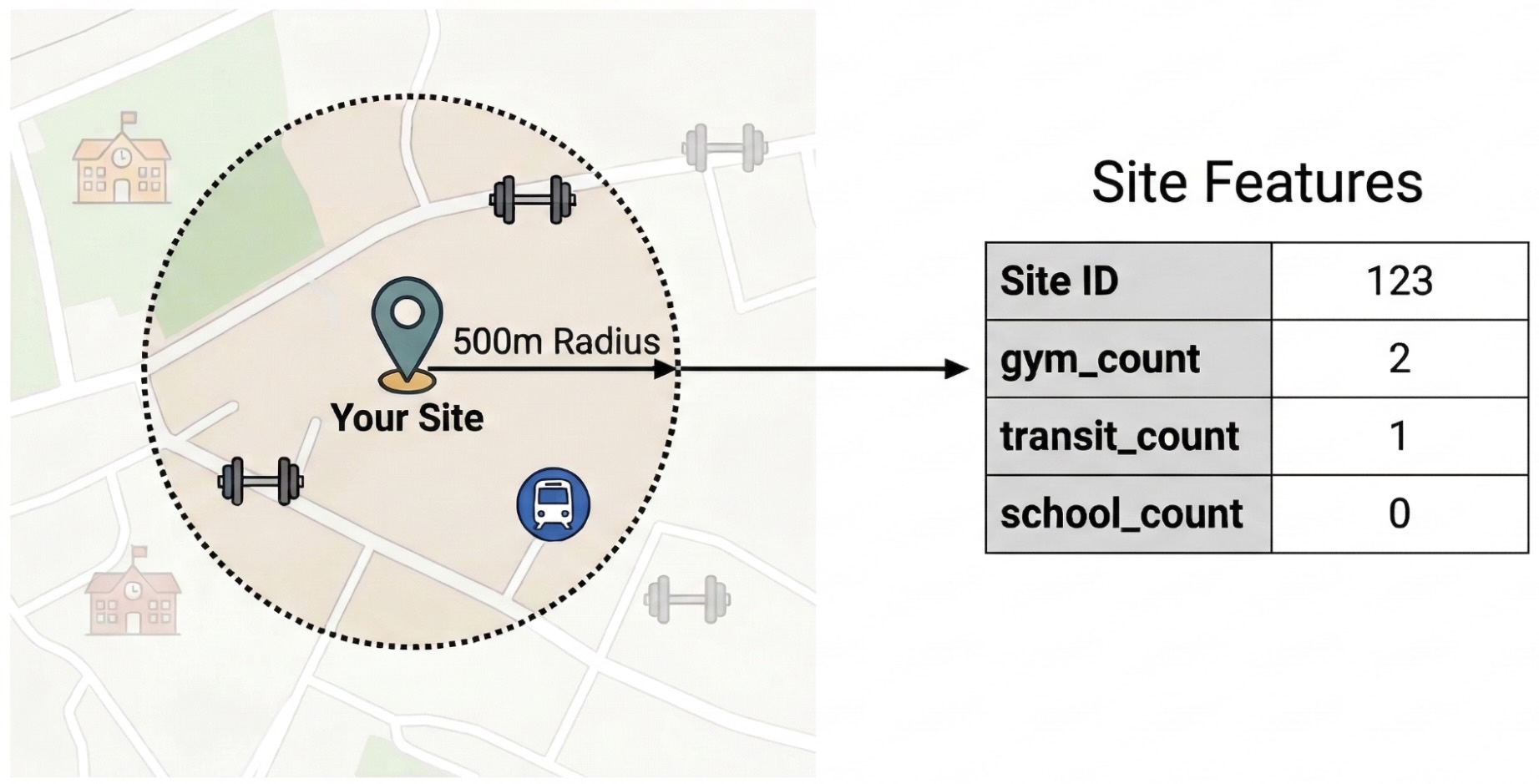
نستخدم Python ومكتبة pandas-gbq لهذه الخطوة. يتيح لك هذا النهج تنفيذ طلب البحث SELECT WITH AGGREGATION_THRESHOLD، وهو مطلوب للوصول إلى مجموعة بيانات Places Insights، وحفظ النتائج في جدول جديد في مشروعك. لمزيد من المعلومات عن استخدام بيانات إحصاءات الأماكن، يمكنك الاطّلاع على مقالة الاستعلام عن مجموعة البيانات
مباشرةً.
تشغيل طلب البحث عن هندسة الخصائص
يمكنك تشغيل النص البرمجي التالي بلغة Python في بيئتك (مثل Colab Enterprise). يربط هذا النص البرمجي بيانات موقعك الإلكتروني الداخلية بمجموعة بيانات إحصاءات الأماكن.
from google.cloud import bigquery
import pandas_gbq
# Configuration
project_id = 'your_project_id'
dataset_id = 'your_dataset_id'
features_table_id = f'{dataset_id}.site_features'
client = bigquery.Client(project=project_id)
# Define the Feature Engineering Query
# We count specific amenities within 500m of each site in London.
sql = f"""
SELECT WITH AGGREGATION_THRESHOLD
internal.store_id,
internal.store_performance,
-- Feature Engineering: count nearby POIs by type
COUNTIF('gym' IN UNNEST(places.types)) AS gym_count,
COUNTIF('restaurant' IN UNNEST(places.types)) AS restaurant_count,
COUNTIF('school' IN UNNEST(places.types)) AS school_count,
COUNTIF('transit_station' IN UNNEST(places.types)) AS transit_count,
COUNTIF('clothing_store' IN UNNEST(places.types)) AS clothing_store_count
FROM
`{dataset_id}.site_performance` AS internal
JOIN
`places_insights___gb.places` AS places
ON ST_DWITHIN(internal.location, places.point, 500)
WHERE
places.business_status = 'OPERATIONAL'
GROUP BY
internal.store_id, internal.store_performance
"""
print("1. Running Feature Engineering Query...")
# Execute the query and download results to a Pandas DataFrame
df_features = client.query(sql).to_dataframe()
print(f"2. Saving features to: {features_table_id}...")
# Upload the engineered features to a permanent BigQuery table
pandas_gbq.to_gbq(
dataframe=df_features,
destination_table=features_table_id,
project_id=project_id,
if_exists='replace'
)
print(" Success! Training data ready.")
فهم طلب البحث
ST_DWITHIN: تنشئ هذه الدالة الجغرافية المكانية نطاقًا جغرافيًا حول كل موقع يبلغ 500 متر وتحدّد جميع نقاط إحصاءات الأماكن التي تقع ضمن هذا النطاق.COUNTIF: تحسب هذه الدالة كثافة أنواع الأماكن المحدّدة (مثل "صالة رياضية" و"مدرسة") لكل موقع إلكتروني. تصبح هذه الأعداد خصائص الإدخال (X) لنموذج تعلُّم الآلة.pandas_gbq.to_gbq: تحفظ هذه الدالة نتائج طلب البحث في جدول جديد (site_features). يعمل هذا الجدول الدائم كمجموعة بيانات التدريب النظيفة لنموذج BigQuery ML.
للحصول على تطبيقات أكثر تقدّمًا في العالم الحقيقي، يمكنك حساب الخصائص على مسافات متعددة (مثل 250 مترًا و500 متر و1 كيلومتر) واستكشاف سمات إحصاءات الأماكن الأخرى، مثل rating أو price_level أو regular_opening_hours. للاطّلاع على القائمة الكاملة بسمات إحصاءات الأماكن، يمكنك مراجعة
أنواع الأماكن المتوافقة و
مرجع المخطط الأساسي.
تدريب النموذج باستخدام BigQuery ML
بعد حفظ الخصائص التي تم تصميمها في جدول site_features، يمكنك الآن
تدريب نموذج انحدار
خطي.
يتعلّم هذا النموذج الأوزان المثالية (β) لكل خاصية بيئية (X) للتنبؤ بأداء موقعك الإلكتروني (Y).
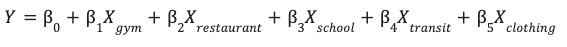
التعامل مع القيم الشاذة باستخدام ميزة "التحجيم القوي"
غالبًا ما تحتوي البيانات الجغرافية المكانية على قيم شاذة قصوى يمكن أن تشوّه النماذج الخطية العادية. على سبيل المثال، قد يحتوي موقع إلكتروني في West End في لندن على 200 مطعم ضمن نطاق 500 متر، بينما يحتوي موقع إلكتروني في الضواحي على مطعمَين فقط. إذا كنت تستخدم التحجيم العادي (المتوسط/الانحراف المعياري)، فإنّ القيمة الشاذة (200) تشوّه التوزيع وتجبر النموذج على منح الأولوية لمطابقة هذه القيمة القصوى.
لحلّ هذه المشكلة، نستخدم ميزة "التحجيم
القوي
(ML.ROBUST_SCALER)" ضمن تعريف النموذج. تُحجِّم هذه التقنية الخصائص استنادًا إلى الوسيط والمدى الربيعي (IQR)، ما يجعل النموذج مقاومًا للقيم الشاذة ويضمن تعلّمه من التوزيع العادي لمواقعك الإلكترونية.
إنشاء النموذج
يمكنك تشغيل طلب SQL التالي في BigQuery لإنشاء النموذج وتدريبه.
نستخدم عبارة
TRANSFORM
لتطبيق ميزة "التحجيم القوي" على جميع خصائص الإدخال. نضبط أيضًا
optimize_strategy = 'NORMAL_EQUATION' لأنّها طريقة التدريب الأكثر فعالية
لمجموعات البيانات الصغيرة نسبيًا، مثل محفظة عادية لمواقع المتاجر. أخيرًا، نزيل القيم الشاذة ذات الأداء العالي (store_performance <
75) لتركيز النموذج على التنبؤ بأنماط النمو العادية.
CREATE OR REPLACE MODEL `your_project.your_dataset.site_performance_model`
TRANSFORM(
store_performance,
-- Feature Engineering inside the model artifact
-- These stats are calculated on the TRAINING split only
ML.ROBUST_SCALER(gym_count) OVER() AS scaled_gym_count,
ML.ROBUST_SCALER(restaurant_count) OVER() AS scaled_restaurant_count,
ML.ROBUST_SCALER(school_count) OVER() AS scaled_school_count,
ML.ROBUST_SCALER(transit_count) OVER() AS scaled_transit_count,
ML.ROBUST_SCALER(clothing_store_count) OVER() AS scaled_clothing_store_count
)
OPTIONS(
model_type = 'LINEAR_REG',
input_label_cols = ['store_performance'],
-- OPTIMIZATION PARAMETERS
optimize_strategy = 'NORMAL_EQUATION', -- Exact mathematical solution (fast for small data)
data_split_method = 'AUTO_SPLIT', -- Automatically reserves ~20% for evaluation
-- DIAGNOSTICS
enable_global_explain = TRUE -- Essential to see feature importance
)
AS
SELECT
gym_count,
restaurant_count,
school_count,
transit_count,
clothing_store_count,
store_performance
FROM
`your_project.your_dataset.site_features`
WHERE
store_performance < 75;
تقييم أداء النموذج
قبل أن تتمكّن من الوثوق بالإحصاءات التي يقدّمها النموذج حول العوامل التي تؤثر في أداء الموقع الإلكتروني، عليك التأكّد من دقة تنبؤاته.
بعد التدريب، يمكنك استخدام الدالة ML.EVALUATE لتقييم تنبؤات النموذج مقارنةً بمجموعة بيانات "محتجَزة" لم يتم استخدامها أثناء التدريب.
SELECT
*
FROM
ML.EVALUATE(MODEL `your_project.your_dataset.site_performance_model`);
يمكنك التحقّق من نتيجة R2
Score
(r2_score) ومتوسط الخطأ المطلق Mean Absolute
Error
(mean_absolute_error) لتحديد ما إذا كان نموذجك جاهزًا للنشر:
- تقيس نتيجة R2 مقدار التباين في الأداء الذي تفسّره العوامل البيئية الخارجية (نقاط الاهتمام القريبة). تعني نتيجة R2 البالغة 0.70 أنّ% 70 من نجاح الموقع الإلكتروني مرتبط بالبيئة المحلية. كلّما اقتربت النتيجة من 1.0، كانت العلاقة أقوى بين وسائل الراحة البيئية وأداء الموقع الإلكتروني.
- يخبرك متوسط الخطأ المطلق عن متوسط الخطأ بالنقاط. على سبيل المثال، يعني متوسط الخطأ المطلق البالغ 1.5 أنّ تنبؤات النموذج تكون عادةً ضمن +/- 1.5 نقطة من نتيجة الأداء الفعلية.
تحديد مشاكل النتائج المنخفضة وحلّها
إذا كانت نتيجة R2 منخفضة، يمكنك إجراء التحسينات التالية:
- توسيع أنواع الخصائص: يمكنك إضافة أنواع أماكن
مختلفة إلى طلب البحث (مثل
tourist_attractionوsubway_station). - تعديل نطاق التغطية: يمكنك تغيير مسافة
ST_DWITHIN. قد يكون النطاق الجغرافي البالغ 500 متر واسعًا جدًا لمقهى ولكنه صغير جدًا لمتجر أثاث. - زيادة حجم البيانات: تأكَّد من أنّك تُجري التدريب على عدد كافٍ من مواقع المتاجر للعثور على نمط ذي دلالة إحصائية.
تسجيل نقاط للمدينة باستخدام نظام H3 Spatial Indexing
نستخدم نظام H3 Spatial Indexing لتقسيم مدينة لندن إلى شبكة منتظمة من الخلايا السداسية (الدقة 8، حوالي 0.7 كيلومتر مربّع). من خلال تجميع بيانات إحصاءات الأماكن في هذه الخلايا، يمكننا تطبيق النموذج الذي تم تدريبه على كل حي، وتحديد المناطق المحتملة التي تتطابق مع الملف البيئي لمواقعك الأفضل أداءً.
تشغيل طلب البحث عن العملاء المحتملين
لإنشاء هذه الشبكة، نستخدم الدالة
PLACES_COUNT_PER_H3
التي توفّرها مجموعة بيانات إحصاءات الأماكن (مزيد من المعلومات عن الاستعلام عن
إحصاءات الأماكن باستخدام دوال "عدد الأماكن").
تحسب هذه الدالة أعداد نقاط الاهتمام لخلايا شبكة H3 في عملية واحدة.
يمكنك تشغيل طلب SQL التالي لتنفيذ ثلاث خطوات في عملية تنفيذ واحدة:
- الفهرسة والعدّ باستخدام نظام H3: نستدعي الدالة
PLACES_COUNT_PER_H3باستخدام كائن إعداد بتنسيق JSON للعثور على جميع الأماكن التشغيلية ضمن نطاق 25 كيلومترًا من وسط لندن. نستعلم عن ذلك بشكل منفصل لكل نوع من وسائل الراحة (الصالات الرياضية والمدارس وما إلى ذلك) ونجمعها باستخدامUNION ALL. - التجميع المحوري (هندسة الخصائص): بما أنّ نموذج تعلُّم الآلة يتوقّع أعمدة خصائص منفصلة (مثل
gym_countوrestaurant_count)، نُجمِّع الخلايا ونستخدم التجميع الشرطي(SUM(IF(...)))لتغيير شكل البيانات إلى المخطط الصحيح. - التوقّع: نُدخِل خصائص الشبكة التي تم تغيير شكلها مباشرةً إلى الدالة
ML.PREDICTلإنشاء نتيجة أداء لكل حي.
WITH combined_counts AS (
-- Gyms
SELECT h3_cell_index, geography, count, 'gym' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000), -- 25km radius around London
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['gym']
)
)
UNION ALL
-- Restaurants
SELECT h3_cell_index, geography, count, 'restaurant' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['restaurant']
)
)
UNION ALL
-- Schools
SELECT h3_cell_index, geography, count, 'school' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['school']
)
)
UNION ALL
-- Transit Stations
SELECT h3_cell_index, geography, count, 'transit_station' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['transit_station']
)
)
UNION ALL
-- Clothing Stores
SELECT h3_cell_index, geography, count, 'clothing_store' AS type
FROM `places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_BUFFER(ST_GEOGPOINT(-0.1278, 51.5074), 25000),
'h3_resolution', 8,
'business_status', ['OPERATIONAL'],
'types', ['clothing_store']
)
)
),
aggregated_features AS (
-- Pivot the stacked rows back into standard feature columns for the ML Model
SELECT
h3_cell_index AS h3_index,
ANY_VALUE(geography) AS h3_geography,
SUM(IF(type = 'gym', count, 0)) AS gym_count,
SUM(IF(type = 'restaurant', count, 0)) AS restaurant_count,
SUM(IF(type = 'school', count, 0)) AS school_count,
SUM(IF(type = 'transit_station', count, 0)) AS transit_count,
SUM(IF(type = 'clothing_store', count, 0)) AS clothing_store_count
FROM
combined_counts
GROUP BY
h3_cell_index
)
-- Feed the pivoted features into the model
SELECT
h3_index,
predicted_store_performance,
h3_geography,
gym_count,
restaurant_count
FROM
ML.PREDICT(MODEL `your_project.your_dataset.site_performance_model`,
(SELECT * FROM aggregated_features)
)
ORDER BY
predicted_store_performance DESC;
تفسير النتائج
يعرض طلب البحث جدولاً يمثّل كل صف فيه منطقة سداسية في لندن.
h3_index: المعرّف الفريد للخلية السداسيةpredicted_store_performance: النتيجة المقدَّرة التي يقدّمها النموذج لموقع إلكتروني يقع في هذه الخلية، استنادًا إلى البيئة المحيطة فقطh3_geography: هندسة المضلّع للخلية، والتي سنستخدمها للعرض المرئي في الخطوة التالية
تشير القيم المرتفعة إلى المناطق التي تتطابق فيها كثافة المدارس والصالات الرياضية ووسائل النقل مع الأنماط التي تم العثور عليها حول مواقعك الإلكترونية الحالية الأكثر نجاحًا.
عرض خريطة العملاء المحتملين
لجعل البيانات قابلة للتنفيذ، يمكنك عرض النتائج على خريطة. في حين أنّ الناتج الجدولي يقدّم النتائج الأولية، تكشف الخريطة عن مجموعات مكانية وممرات ذات إمكانات عالية لا تكون واضحة في القائمة.
في دفتر الملاحظات المصاحب، نستخدم مكتبة geopandas لتحليل هندسة مضلّع H3 ومكتبة folium لعرض خريطة تفاعلية.
النتيجة هي خريطة تظليل نسبي يتم فيها تلوين كل خلية سداسية وفقًا للنتيجة المتوقّعة.
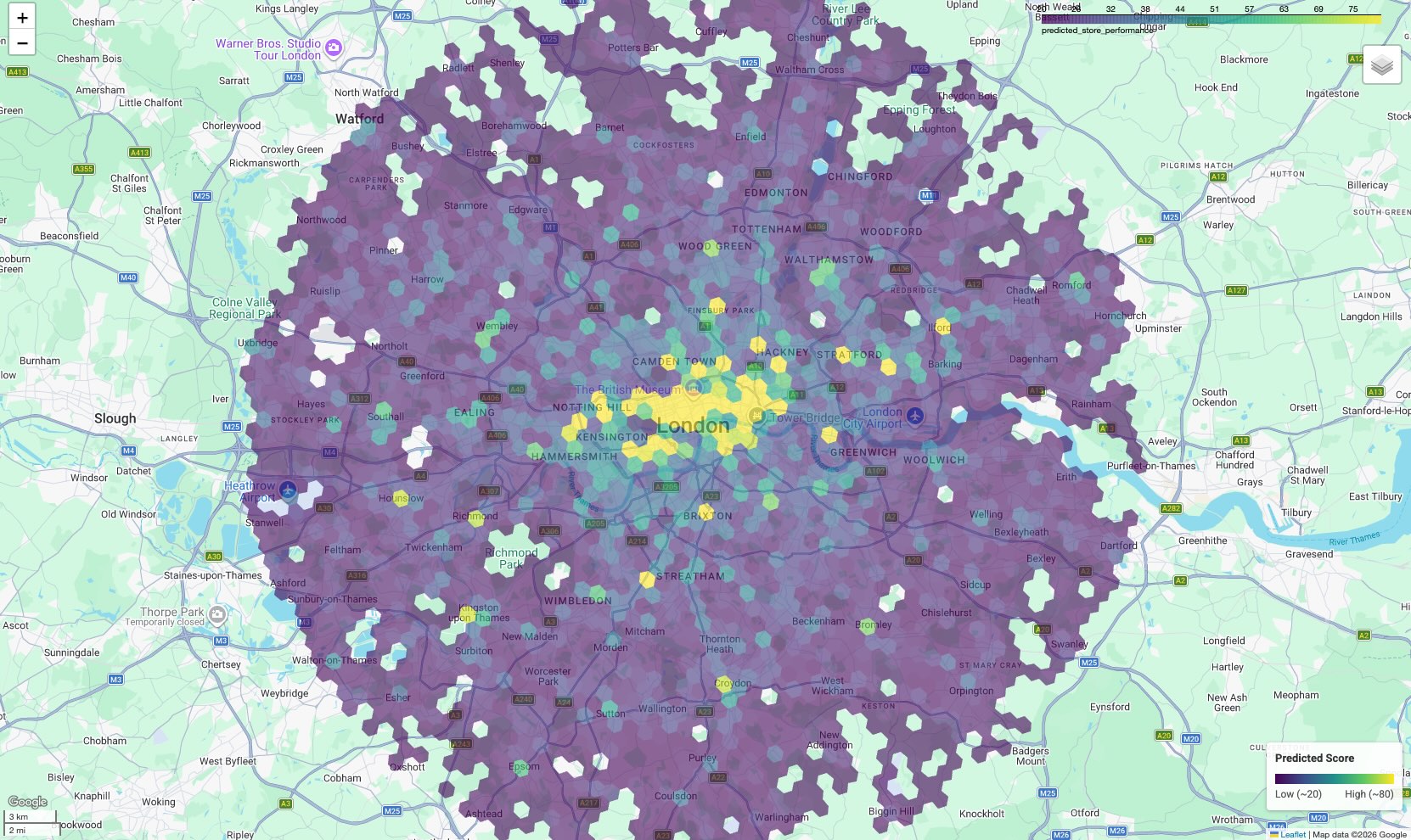
تفسير الخريطة:
- النقاط الفعّالة (الأصفر/الأخضر): تحقّق هذه المناطق نتائج أداء متوقّعة عالية. وتتضمّن الكثافة المثالية للمدارس والصالات الرياضية ووسائل النقل التي ترتبط بمواقعك الإلكترونية الناجحة. وهي خيارات أساسية لاختيار موقع إلكتروني جديد.
- النقاط غير الفعّالة (الأرجواني): تفتقر هذه المناطق إلى الخصائص البيئية الداعمة التي تم العثور عليها بالقرب من مواقعك الإلكترونية الأفضل أداءً.
- الفحص التفاعلي: في بيئة دفتر الملاحظات، يمكنك تمرير مؤشر الماوس فوق أي خلية للاطّلاع على الأعداد المحدّدة لوسائل الراحة (مثل "الصالات الرياضية: 12") التي ساهمت في هذه النتيجة المحدّدة.
الخاتمة
لقد جمعت بنجاح بيانات التشغيل الداخلية مع إحصاءات الأماكن لتشخيص أداء الموقع الإلكتروني. من خلال تحليل أوزان النموذج، حدّدت الخصائص المحدّدة للحي التي ترتبط بمقاييسك الحالية. باستخدام نظام H3 spatial indexing، يمكنك توسيع نطاق هذا التحليل من بضع مئات من المواقع الإلكترونية إلى آلاف الأحياء المحتملة في جميع أنحاء لندن.
الإجراءات التالية
- توسيع نطاق هندسة الخصائص: يمكنك إضافة أنواع أماكن أكثر تحديدًا إلى طلب البحث، وذلك لالتقاط العوامل المتخصّصة التي تؤثر في عدد الزيارات إلى المتجر.
- استكشاف النماذج المتقدّمة: في حين أنّ الانحدار الخطي يوفّر إمكانية تفسير واضحة، يمكنك تجربة
BOOSTED_TREE_REGRESSORفي BigQuery ML مع استراتيجية مناسبة للتحقق من الصحة المتبادلة لالتقاط العلاقات غير الخطية. - تشغيل الخريطة: يمكنك تصدير نتائج شبكة H3 إلى لوحة بيانات مخصّصة باستخدام Maps JavaScript API لمشاركة هذه الإحصاءات مع فريقك.
المساهمون
- هنريك فالف | مهندس تجربة المطوّرين
- جينادي دونشيتس | مهندس إرشاد العملاء المتعاقدين