Основы поисковой оптимизации сайтов, использующих JavaScript
JavaScript играет важную роль в интернете, поскольку позволяет расширять возможности сайтов и превращать их в веб-приложения. Если у вас есть такие приложения, вы можете помочь поисковым роботам индексировать их, чтобы ваш контент появлялся в Google Поиске и помогал привлекать и удерживать пользователей. Google Поиск обрабатывает код JavaScript с помощью последней версии Chromium. В связи с этим мы можем предложить вам советы по оптимизации такого кода.
Из этого руководства вы узнаете, как мы сканируем и индексируем веб-приложения на основе JavaScript и как оптимизировать такие приложения для Google Поиска.
Как робот Googlebot обрабатывает JavaScript
Обработка веб-приложений на основе JavaScript с помощью робота Googlebot предполагает три основных этапа:
- Сканирование
- Отрисовка
- Индексирование
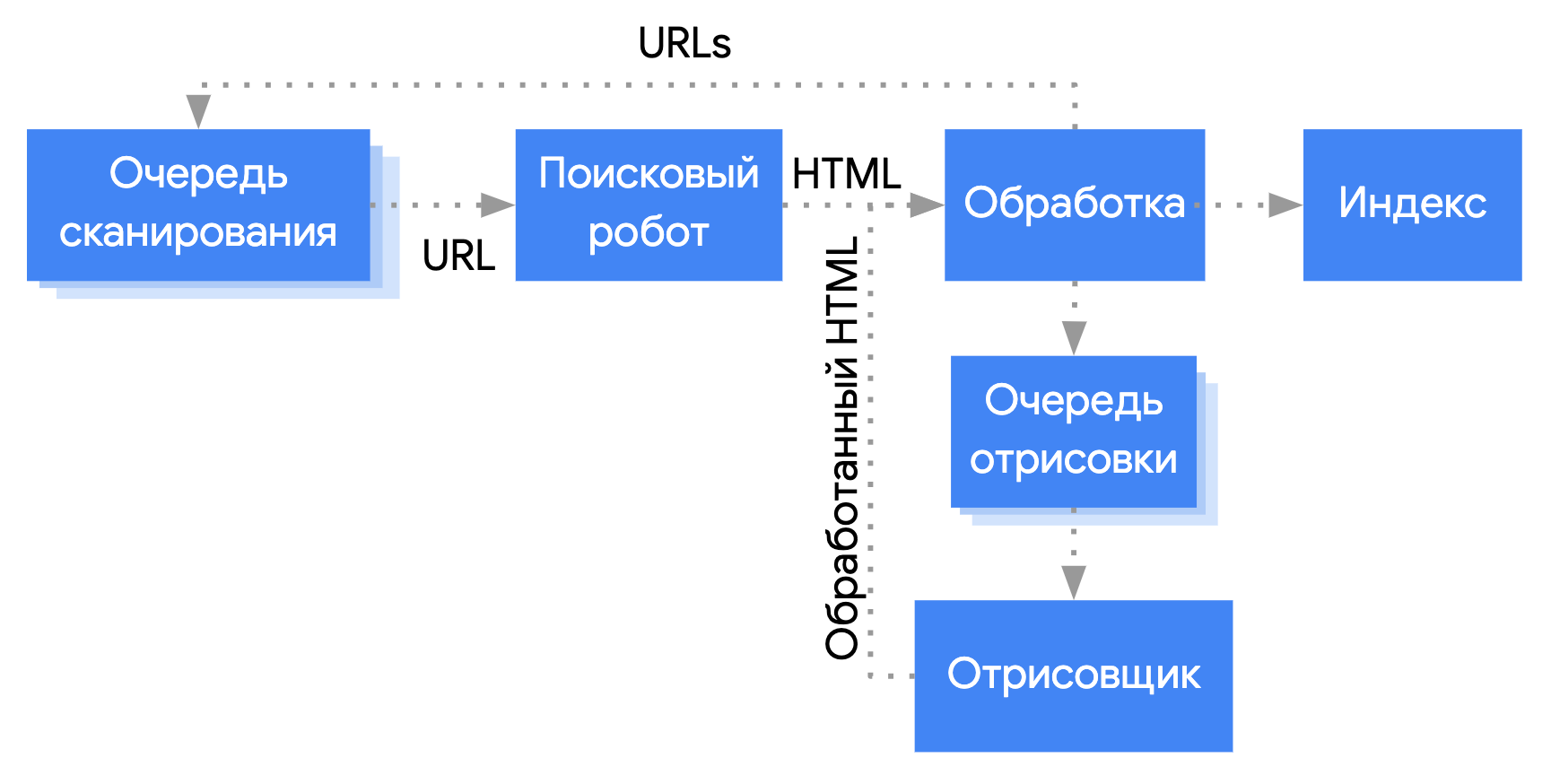
Робот Googlebot ставит страницу в отдельные очереди на сканирование и отрисовку. Нельзя точно установить, в какой из них находится страница в каждый отдельный момент. Получив URL из очереди сканирования при помощи HTTP-запроса, робот Googlebot сначала проверяет, разрешено ли сканирование страницы. Для этого он считывает файл robots.txt. Если доступ к URL запрещен, Googlebot не отправляет соответствующий HTTP-запрос и пропускает этот URL. Google Поиск не обрабатывает код JavaScript на страницах и в файлах, которые заблокированы в настройках.
Затем Googlebot находит в полученном ответе другие URL, задаваемые через атрибут href HTML-ссылок, и добавляет их в очередь сканирования. Если вы не хотите, чтобы робот Googlebot переходил по ссылкам, укажите для них атрибут nofollow.
Сканирование URL и анализ HTML-ответа эффективны в случае обычных сайтов и страниц, которые отрисовываются на стороне сервера, когда весь контент содержится в коде HTML из HTTP-ответа. Однако на некоторых сайтах применяется модель оболочки, при которой фактический контент страницы не содержится в исходном коде HTML, и чтобы получить его, роботу Googlebot необходимо выполнить код JavaScript.
Если в заголовке или теге meta с атрибутом robots нет запрета на индексирование страницы с кодом статуса HTTP 200, Googlebot ставит ее в очередь на отрисовку.
Страница может задержаться в очереди на несколько секунд (в некоторых случаях на более длительное время). Когда у робота Googlebot достаточно ресурсов для обработки, он получает от консольного браузера Chromium отрисованную страницу с выполненным кодом JavaScript.
Googlebot анализирует полученный HTML-код, индексирует его контент и ставит все обнаруженные в нем URL в очередь на сканирование.
Мы рекомендуем по возможности использовать отрисовку на стороне сервера или предварительную отрисовку, поскольку в этом случае сайт будет загружаться быстрее. Кроме того, не все роботы могут выполнять код JavaScript.
Используйте уникальные заголовки и краткие описания страниц
Уникальные информативные элементы <title> и метаописания помогают пользователям быстрее находить нужные результаты поиска.
Задавать и изменять элементы <title> и метаописания можно с помощью JavaScript.
Задайте канонический URL
Тег link с атрибутом rel="canonical" помогает Google находить каноническую версию страницы.
Задать канонический URL можно с помощью JavaScript. Однако мы не рекомендуем использовать JavaScript, чтобы менять такой URL.
Лучше всего задавать канонический URL с помощью HTML, но если вам нужно использовать JavaScript, убедитесь, что этот URL совпадает с тем, который указан в исходном HTML-коде.
Если вы не можете задать канонический URL с помощью HTML, не включайте его в исходный код. Тогда можно будет использовать JavaScript.
Используйте языки и функции, которые поддерживаются роботом Googlebot
Современные браузеры поддерживают различные API, а язык JavaScript быстро развивается. Робот Googlebot может не поддерживать некоторые API и функции JavaScript. Чтобы ваш код был совместим с роботом Googlebot, следуйте нашим рекомендациям по устранению проблем с JavaScript.
Если браузер не поддерживает нужные вам API, рекомендуем использовать дифференциальный показ и полифилы. Поскольку полифилы доступны не для всех функций браузеров, рекомендуем изучить сведения об ограничениях в документации по полифилам.
Используйте корректные коды статусов HTTP
Для получения информации о проблемах, возникших при сканировании страницы, робот Googlebot анализирует коды статусов HTTP.
Чтобы робот Googlebot мог определить, разрешено ли ему сканировать или индексировать страницу, используйте понятные коды статусов. Например, если страница не найдена, возвращайте код 404, а если для доступа к странице нужно войти в аккаунт – код 401.
Также с помощью кодов статусов HTTP можно сообщить роботу Googlebot о переносе страницы на новый URL, чтобы мы обновили индекс.
Ознакомьтесь с кодами статусов HTTP и узнайте, в каких случаях их нужно использовать.
Старайтесь не допускать ошибок soft 404 в одностраничных приложениях
В клиентских приложениях, состоящих из одной страницы, маршрутизация зачастую выполняется на стороне клиента.
В этом случае использовать коды статусов HTTP может быть невозможно или неудобно.
Чтобы при отрисовке и маршрутизации на стороне клиента не происходила ошибка soft 404, сделайте следующее:
- Настройте переадресацию JavaScript на URL, для которого сервер возвращает код статуса HTTP
404. Пример:/not-found. - Добавьте на страницы с ошибками тег
<meta name="robots" content="noindex">, используя JavaScript.
Образец кода с переадресацией
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Образец кода с тегом noindex
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Применяйте History API вместо фрагментов
Googlebot обнаруживает ссылки, только если они заданы в элементе HTML <a> с атрибутом href.
Если у вас одностраничное приложение с клиентской маршрутизацией, для переходов между разными видами приложения используйте History API. Чтобы робот Googlebot мог находить, обрабатывать и извлекать URL, не используйте фрагменты для загрузки разного контента страницы. Ниже приведен пример кода, нарушающего наши рекомендации, так как при его использовании робот Googlebot не сможет корректно распознать URL:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Чтобы у робота Googlebot был доступ к URL, рекомендуем реализовать URL с помощью History API:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Правильно внедряйте теги link с атрибутом rel="canonical"
Тег link с атрибутом rel="canonical" можно внедрить с помощью кода JavaScript, хотя мы не рекомендуем этого делать.
Google Поиск обработает внедренный канонический URL при отрисовке страницы. Пример внедрения тега link с атрибутом rel="canonical" с помощью кода JavaScript приведен ниже:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Соблюдайте осторожность при работе с тегами meta robots
С помощью тега meta с атрибутом robots вы можете запретить Google индексировать определенную страницу или переходить по ссылкам.
Например, Googlebot не будет обрабатывать страницу, если в ее верхней части есть следующий тег meta:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Чтобы добавить на страницу тег meta с атрибутом robots или изменить его, можно использовать JavaScript.
В примере ниже показано, как изменить тег meta с атрибутом robots в коде JavaScript, чтобы запретить индексирование страницы в случаях, когда запрос API не возвращает контент.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Применяйте длительное кеширование
Чтобы сократить число сетевых запросов и потребление ресурсов, робот Googlebot активно использует кешированный контент. Поскольку WRS может игнорировать заголовки кеширования, это иногда приводит к использованию устаревших ресурсов JavaScript или CSS.
Чтобы избежать этой проблемы, можно включать в название файла цифровой отпечаток контента, например так: main.2bb85551.js.
Цифровой отпечаток зависит от содержания файла, поэтому при каждом изменении файла для него создается новое название.
Ознакомьтесь с руководством по стратегиям долгосрочного кеширования от web.dev.
Используйте структурированные данные
Если на вашем сайте есть структурированные данные, вы можете создавать код JSON-LD и внедрять его на страницы с помощью JavaScript. Обязательно проверяйте результаты своей работы на наличие ошибок.
Следуйте рекомендациям по работе с веб-компонентами
Робот Googlebot поддерживает веб-компоненты. Когда он выполняет отрисовку страницы, то не учитывает содержимое Shadow DOM и Light DOM, т. е. ему доступен только контент, который становится видимым после отрисовки HTML. Узнать, как робот Googlebot интерпретирует контент после его отрисовки, можно с помощью проверки расширенных результатов или инструмента проверки URL в Search Console.
Если контент не виден после того, как выполнена отрисовка HTML-кода, Googlebot не сможет включить его в индекс.
В примере ниже создается веб-компонент, который отрисовывает свой контент Light DOM внутри контента Shadow DOM. Проверить, виден ли контент обоих этих типов после процедуры отрисовки HTML, можно с помощью элемента Slot.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Googlebot проиндексирует этот контент после его отрисовки:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Применяйте отложенную загрузку для изображений
Изображения могут требовать высокой пропускной способности и замедлять загрузку ресурсов. Советуем применять отложенную загрузку, чтобы графические файлы скачивались, только если их должен увидеть пользователь. Чтобы оптимизировать отложенную загрузку для поисковых систем, следуйте специальным рекомендациям.