JavaScript a SEO – podstawy
JavaScript jest ważnym elementem platformy internetowej, ponieważ zapewnia wiele funkcji, które zamieniają obszary internetu w zaawansowane platformy aplikacji. Dbając o wykrywalność aplikacji internetowych opartych na JavaScripcie w wyszukiwarce Google, zwiększasz szansę na znalezienie nowych użytkowników i ponowne zaangażowanie dotychczasowych, gdy szukają oni treści, których dostarczyć mogą Twoje aplikacje. Wyszukiwarka Google obsługuje JavaScript przy użyciu zawsze aktualnej wersji Chromium, ale kilka rzeczy możesz zoptymalizować.
Dzięki temu przewodnikowi dowiesz się, jak wyszukiwarka Google przetwarza JavaScript, i poznasz sprawdzone metody ulepszania aplikacji internetowych utworzonych przy użyciu tego języka pod kątem ich wyszukiwania w Google.
Jak Google przetwarza JavaScript
Przetwarzanie aplikacji internetowych opartych na JavaScripcie przez Google można podzielić na 3 główne fazy:
- Skanowanie
- Renderowanie
- Indeksowanie
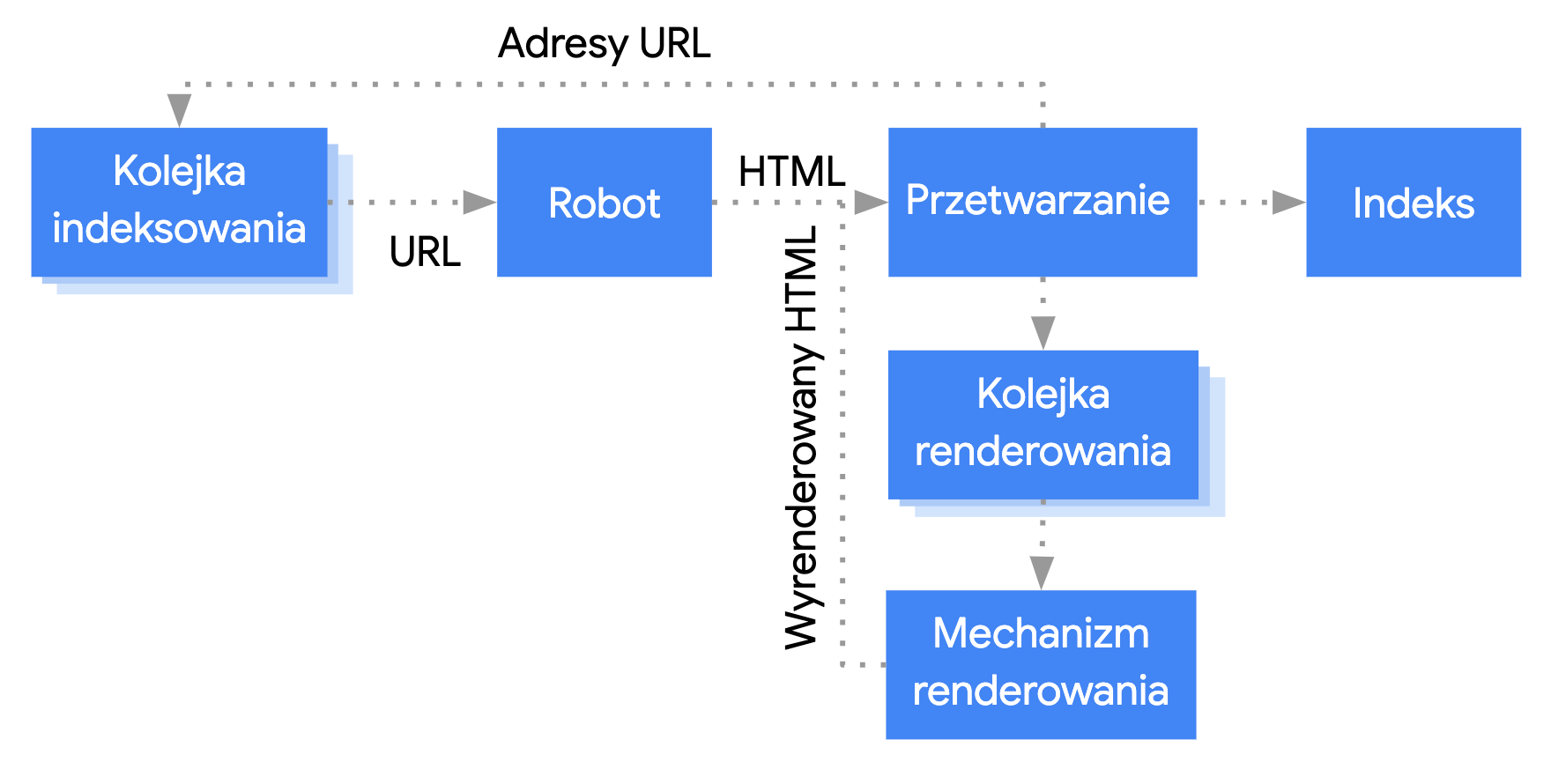
Googlebot ustala kolejkę stron do skanowania i renderowania. Trudno jest natychmiastowo ustalić, kiedy strona czeka na skanowanie, a kiedy na renderowanie. Gdy Googlebot pobiera adres URL z kolejki indeksowania, wysyłając żądanie HTTP, najpierw sprawdza, czy zezwalasz na skanowanie. W tym celu czyta plik robots.txt. Jeśli URL jest w nim oznaczony jako niedozwolony, Googlebot nie wysyła do niego żądania HTTP i w rezultacie go pomija. Wyszukiwarka Google nie renderuje kodu JavaScript z zablokowanych plików ani stron.
Następnie Googlebot analizuje odpowiedzi z innych adresów URL w atrybucie href linków HTML i dodaje te adresy do kolejki indeksowania. Aby zapobiec wykrywaniu linków, użyj mechanizmu nofollow.
Skanowanie adresu URL i analizowanie odpowiedzi HTML sprawdza się w przypadku klasycznych witryn lub stron renderowanych po stronie serwera, gdy kod HTML w odpowiedzi HTTP zawiera wszystkie treści. Niektóre witryny korzystające z JavaScriptu mogą używać modelu powłoki aplikacji. W takim przypadku początkowy kod HTML nie zawiera rzeczywistych treści generowanych przez JavaScript, więc w celu ich podejrzenia Google musi wykonać kod JavaScript.
Googlebot umieszcza w kolejce wszystkie strony z kodem stanu HTTP 200 do renderowania, chyba że tag meta lub nagłówek w pliku robots wskazuje, żeby nie indeksować strony.
Strona może znajdować się w kolejce przez kilka sekund albo dłużej. Gdy zezwolą na to zasoby Google, Chromium bez interfejsu graficznego renderuje stronę i wykonuje kod JavaScript.
Googlebot ponownie analizuje wyrenderowany kod HTML pod kątem linków i dodaje znalezione adresy URL do kolejki. Google używa również wyrenderowanego kodu HTML do zindeksowania strony.
Pamiętaj, że renderowanie po stronie serwera lub wstępne renderowanie nadal jest bardzo użyteczne, bo sprawia, że witryna działa szybciej dla użytkowników i robotów, a poza tym nie wszystkie boty potrafią wykonywać kod JavaScript.
Opisywanie strony przy użyciu unikalnych tytułów i fragmentów
Unikalne, opisowe elementy <title> i metaopisy pomagają użytkownikom szybko zidentyfikować najlepszy wynik.
Do określenia lub zmiany metaopisu bądź elementu <title> możesz użyć JavaScriptu.
Ustawianie kanonicznego adresu URL
Tag linku rel="canonical" pomaga Google znaleźć wersję kanoniczną strony.
Do ustawienia kanonicznego adresu URL możesz użyć JavaScriptu, ale pamiętaj, że nie należy używać JavaScriptu do zmiany kanonicznego adresu URL na inny niż ten, który został określony jako kanoniczny w oryginalnym kodzie HTML.
Najlepszym sposobem na ustawienie kanonicznego adresu URL jest użycie kodu HTML, ale jeśli musisz użyć JavaScriptu, zawsze ustawiaj kanoniczny adres URL na tę samą wartość co oryginalny kod HTML.
Jeśli nie możesz ustawić kanonicznego adresu URL w HTML-u, możesz użyć JavaScriptu, aby ustawić kanoniczny adres URL i pominąć go w oryginalnym kodzie HTML.
Pisanie zgodnego kodu
Przeglądarki oferują wiele interfejsów API, a JavaScript jest językiem, który szybko się rozwija. Z kolei Google obsługuje ograniczoną liczbę interfejsów API i funkcji JavaScriptu. Aby sprawdzić, czy Twój kod jest zgodny z Google, postępuj według naszych wskazówek dotyczących rozwiązywania problemów z obsługą JavaScriptu.
Jeśli wykryjesz brakujący interfejs API, zalecamy użycie zróżnicowanego wyświetlania i kodu polyfill. Niektórych funkcji przeglądarek nie da się obsłużyć kodem polyfill. Informacje o potencjalnych ograniczeniach znajdziesz w jego dokumentacji.
Używanie znaczących kodów stanu HTTP
Googlebot używa kodów stanu HTTP, żeby wykrywać, czy podczas skanowania strony coś poszło nie tak.
Jeśli chcesz przekazać Googlebotowi, żeby nie skanował ani nie indeksował strony, używaj znaczących kodów stanu – na przykład kodu 404 w przypadku strony, której nie można znaleźć, lub kodu 401 w przypadku stron, na które trzeba się zalogować.
Tych kodów stanu HTTP możesz też używać, aby informować Googlebota o przeniesieniu strony pod nowy adres URL. Dzięki temu będzie można odpowiednio zaktualizować indeks.
Oto lista kodów stanu HTTP wraz z informacjami o ich wpływie na wyszukiwarkę Google.
Unikaj błędów soft 404 w aplikacjach na jednej stronie
W przypadku aplikacji na jednej stronie renderowanych po stronie klienta kierowanie ruchu jest często implementowane jako kierowanie ruchu po stronie klienta.
W tym przypadku używanie znaczących kodów stanu HTTP może się okazać niemożliwe lub niepraktyczne.
Aby uniknąć błędów soft 404 podczas korzystania z kierowania ruchu i renderowania po stronie klienta, użyj jednej z tych strategii:
- Użyj przekierowania JavaScript na adres URL, na który serwer wysyła kod stanu HTTP
404(na przykład/not-found). - Dodaj kod
<meta name="robots" content="noindex">do stron błędów za pomocą JavaScriptu.
Oto przykładowy kod przekierowania:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Oto przykładowy kod z tagiem noindex:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Używanie interfejsu History API zamiast adresów URL zawierających fragment z krzyżykiem
Google może wykrywać Twoje linki tylko wtedy, gdy są to elementy HTML <a> z atrybutem href.
W przypadku aplikacji jednostronicowych z kierowaniem ruchu po stronie klienta użyj interfejsu History API, aby zaimplementować kierowanie ruchu między różnymi widokami aplikacji internetowej. Aby umożliwić Googlebotowi analizowanie i wyodrębnianie adresów URL, nie używaj fragmentów do wczytywania innej treści strony. Poniżej znajdziesz przykład niezalecanego działania, ponieważ Googlebot nie jest w stanie w prawidłowy sposób rozpoznać adresów URL:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Adresy URL będą dostępne dla Googlebota, jeśli zamiast tego zaimplementujesz interfejs History API:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Prawidłowe wstrzykiwanie tagu link rel="canonical"
Choć nie zalecamy do używania w tym celu JavaScriptu, wstrzyknięcie tagu link rel="canonical" za jego pomocą jest możliwe.
Wyszukiwarka Google pobierze wstrzyknięty kanoniczny URL podczas renderowania strony. Oto przykład wstawienia tagu link rel="canonical" za pomocą kodu JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Rozważne używanie tagów meta robots
Aby uniemożliwić robotowi Google indeksowanie strony lub otwieranie linków, możesz użyć tagu meta robots.
Na przykład dodanie tego tagu meta w górnej części strony blokuje Google możliwość indeksowania tej strony:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
Możesz użyć JavaScriptu, aby dodać tag meta robots do strony lub zmień jej zawartość.
Poniższy przykładowy kod pokazuje, jak zmienić tag meta robots za pomocą JavaScriptu, aby zapobiec indeksowaniu bieżącej strony, jeśli wywołanie interfejsu API nie zwróci treści.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Używanie długiego buforowania
Googlebot intensywnie korzysta z pamięci podręcznej, aby zmniejszać liczbę żądań sieciowych i obciążenie zasobów. WRS może ignorować nagłówki zapisu w pamięci podręcznej. Może to prowadzić do korzystania przez WRS z nieaktualnych zasobów JavaScriptu lub CSS-u.
Uniknąć tego problemu pozwala odcisk cyfrowy treści umieszczany we fragmencie nazwy pliku odnoszącym się do treści, np. main.2bb85551.js.
Odcisk cyfrowy zależy od zawartości pliku, więc jej aktualizacje powodują każdorazowe utworzenie innej nazwy pliku.
Więcej informacji znajdziesz w przewodniku web.dev po strategiach długiego buforowania.
Używanie uporządkowanych danych
Jeśli na swoich stronach stosujesz uporządkowane dane, możesz używać JavaScriptu do generowania wymaganego kodu JSON-LD i umieszczania go na stronie. Aby uniknąć problemów, przetestuj swoją implementację.
Trzymanie się sprawdzonych metod korzystania z komponentów internetowych
Google obsługuje komponenty internetowe. Renderując stronę, Google spłaszcza treści Shadow DOM i Light DOM. Oznacza to, że Google może wyświetlać tylko treści, które są widoczne w renderowanym kodzie HTML. Aby sprawdzić, czy Google nadal widzi Twoje treści po ich wyrenderowaniu, przeprowadź test wyników z elementami rozszerzonymi lub użyj narzędzia do sprawdzania adresów URL i przyjrzyj się wyrenderowanemu kodowi HTML.
Jeśli treść nie jest widoczna w wyrenderowanym kodzie HTML, robot Google nie będzie mógł jej zindeksować.
W poniższym przykładzie tworzony jest komponent internetowy, który wyświetla treść Light DOM w modelu Shadow DOM. Jednym ze sposobów zagwarantowania, że w wyświetlonym kodzie HTML będzie wyświetlana zarówno treść Light DOM, jak i Shadow DOM, jest użycie elementu Przedział.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>Po wyrenderowaniu Google może zindeksować te treści:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Rozwiązywanie problemów z obrazami i leniwym ładowaniem treści
Obsługa obrazów może znacznie obciążać przepustowość i wymagać sporej mocy obliczeniowej. Dlatego dobrym podejściem jest stosowanie leniwego ładowania, aby wczytywane były tylko te obrazy, które użytkownik za chwilę zobaczy. Aby sprawdzić, czy używasz leniwego ładowania tak, by nie utrudniało działania wyszukiwarek, postępuj według naszych wskazówek.