Dữ liệu có cấu trúc Tập dữ liệu (Dataset, DataCatalog, DataDownload)
Các tập dữ liệu sẽ dễ tìm thấy hơn trong công cụ Dataset Search khi bạn cung cấp thông tin hỗ trợ như tên, nội dung mô tả, người tạo và định dạng phân phối dưới dạng dữ liệu có cấu trúc. Phương thức khám phá tập dữ liệu của Google là dựa vào schema.org và các tiêu chuẩn khác về siêu dữ liệu có thể thêm vào các trang mô tả tập dữ liệu. Mục đích của mã đánh dấu này là để cải thiện khả năng phát hiện các tập dữ liệu thuộc các lĩnh vực như khoa học đời sống, khoa học xã hội, máy học, dữ liệu công dân và chính phủ và nhiều lĩnh vực khác.
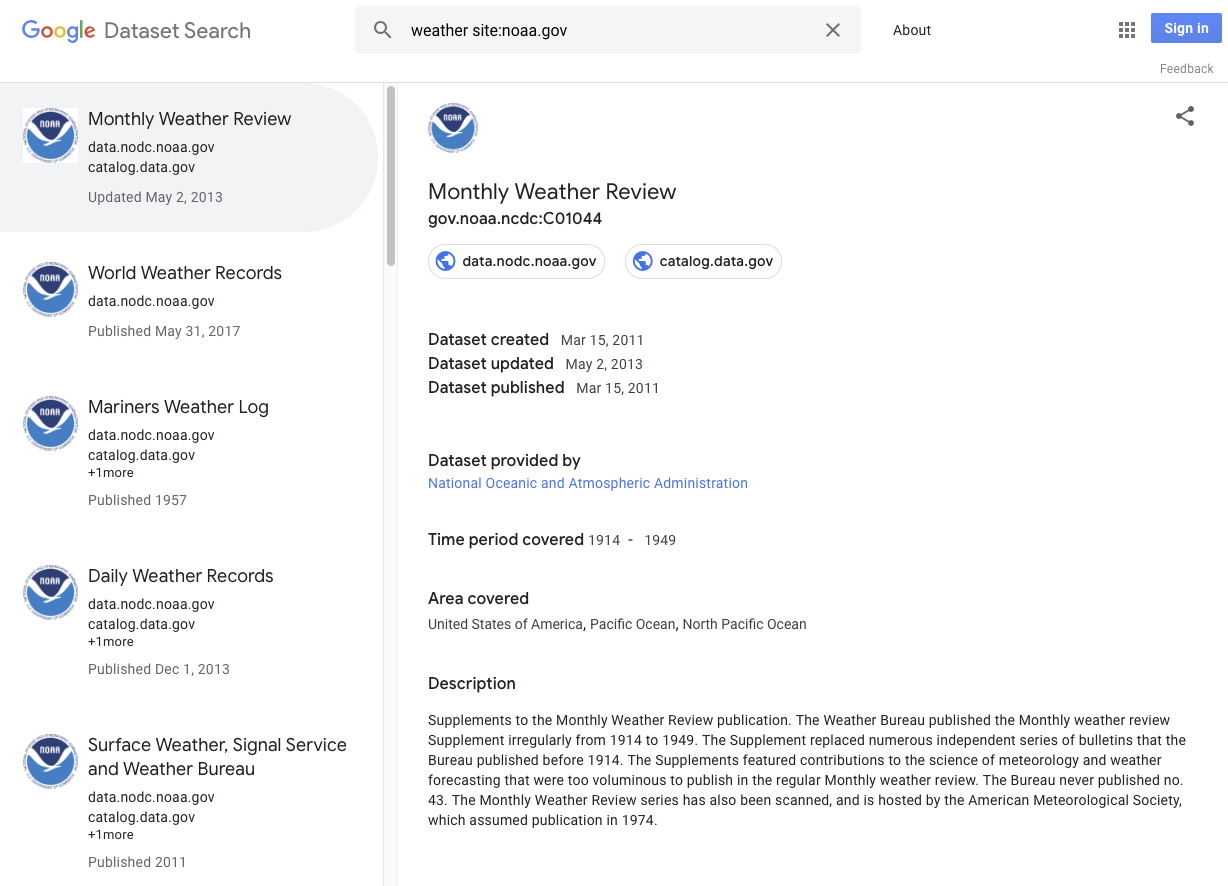
Dưới đây là một số ví dụ về những nội dung đủ điều kiện làm tập dữ liệu:
- Bảng hoặc tệp CSV có một số dữ liệu
- Tập hợp các bảng có tổ chức
- Một tệp ở định dạng độc quyền có chứa dữ liệu
- Một tập hợp các tệp cùng nhau cấu thành nên tập dữ liệu có ý nghĩa
- Một đối tượng có cấu trúc chứa dữ liệu ở một định dạng khác mà bạn có thể muốn tải vào một công cụ đặc biệt để xử lý
- Ảnh chụp dữ liệu
- Các tệp liên quan đến công nghệ máy học, chẳng hạn như các tham số được huấn luyện hoặc định nghĩa cấu trúc mạng nơ-ron
Cách thêm dữ liệu có cấu trúc
Dữ liệu có cấu trúc là một định dạng chuẩn để cung cấp thông tin về một trang và phân loại nội dung trên trang. Nếu mới làm quen với dữ liệu có cấu trúc, bạn có thể tìm hiểu thêm về cách thức hoạt động của dữ liệu có cấu trúc.
Sau đây là thông tin tổng quan về cách xây dựng, kiểm tra và phát hành dữ liệu có cấu trúc.
- Thêm các thuộc tính bắt buộc. Tùy theo định dạng bạn đang sử dụng, hãy tìm hiểu nơi chèn dữ liệu có cấu trúc trên trang.
- Tuân theo các nguyên tắc.
- Xác thực mã của bạn bằng công cụ Kiểm tra kết quả nhiều định dạng rồi sửa mọi lỗi nghiêm trọng. Bạn cũng nên cân nhắc việc khắc phục mọi vấn đề không nghiêm trọng có thể bị gắn cờ trong công cụ này, vì những vấn đề này có thể giúp cải thiện chất lượng của dữ liệu có cấu trúc của bạn (tuy nhiên, bạn không nhất thiết thực hiện việc này để nội dung đủ điều kiện xuất hiện dưới dạng kết quả nhiều định dạng).
- Triển khai một vài trang có chứa dữ liệu có cấu trúc và sử dụng Công cụ kiểm tra URL để kiểm tra xem Google nhìn thấy trang đó như thế nào. Hãy đảm bảo rằng Google có thể truy cập trang của bạn và bạn không chặn trang bằng tệp robots.txt, thẻ
noindexhoặc yêu cầu đăng nhập. Nếu có vẻ như trang không gặp vấn đề nào, bạn có thể yêu cầu Google thu thập lại dữ liệu các URL của mình. - Để thông báo cho Google về các thay đổi sau này, bạn nên gửi một sơ đồ trang web. Bạn có thể tự động hoá quy trình này bằng Search Console Sitemap API.
Xoá tập dữ liệu khỏi kết quả Dataset Search
Nếu bạn không muốn một tập dữ liệu xuất hiện trong kết quả Dataset Search, hãy sử dụng thẻ meta robots để kiểm soát cách thức Google lập chỉ mục tập dữ liệu của bạn. Hãy lưu ý rằng có thể bạn phải đợi (vài ngày hoặc vài tuần, tuỳ vào lịch thu thập thông tin) để các thay đổi này được phản ánh trên trang Tìm kiếm Tập dữ liệu.
Phương thức khám phá tập dữ liệu của chúng tôi
Chúng tôi có thể hiểu được dữ liệu có cấu trúc trong các trang web về tập dữ liệu bằng cách sử dụng mã đánh dấu Dataset của schema.org hoặc cấu trúc tương đương ở định dạng Data Catalog Vocabulary (DCAT) của W3C. Chúng tôi cũng đang thử nghiệm việc hỗ trợ dữ liệu có cấu trúc dựa trên W3C CSVW và hy vọng sẽ phát triển và điều chỉnh thêm phương thức của chúng tôi khi có thêm các phương pháp hiệu quả khác về cách định nghĩa tập dữ liệu. Để biết thêm thông tin về phương thức khám phá tập dữ liệu của chúng tôi, hãy xem phần Hỗ trợ việc khám phá các tập dữ liệu.
Ví dụ
Sau đây là ví dụ về tập dữ liệu sử dụng cú pháp JSON-LD và schema.org (ưu tiên) trong công cụ Kiểm tra kết quả nhiều định dạng. Từ vựng schema.org tương tự cũng có thể được sử dụng trong cú pháp RDFa 1.1 hoặc Microdata. Bạn cũng có thể sử dụng từ vựng DCAT của W3C để mô tả siêu dữ liệu. Ví dụ sau được dựa trên nội dung mô tả tập dữ liệu trong thực tế.
Dưới đây là một ví dụ về tập dữ liệu trong JSON-LD:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Sau đây là ví dụ về tập dữ liệu trong RDFa có sử dụng từ vựng DCAT (không được hỗ trợ trong công cụ Kiểm tra kết quả nhiều định dạng):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Nguyên tắc
Các trang web phải tuân theo nguyên tắc về dữ liệu có cấu trúc. Bên cạnh nguyên tắc về dữ liệu có cấu trúc, bạn cũng nên làm theo các phương pháp hay nhất về sơ đồ trang web và nguồn gốc dữ liệu như dưới đây.
Các phương pháp hay nhất đối với sơ đồ trang web
Hãy dùng tệp sơ đồ trang web để giúp
Google tìm thấy các URL của bạn. Khi dùng các tệp sơ đồ trang web và mã đánh dấu sameAs, bạn có thể ghi lại cách
nội dung mô tả tập dữ liệu được xuất bản trên toàn bộ trang web của bạn.
Nếu bạn có kho lưu trữ tập dữ liệu, thì có khả năng bạn có ít nhất hai loại trang: trang chính tắc ("đích") cho mỗi tập dữ liệu và trang liệt kê nhiều tập dữ liệu (ví dụ: kết quả tìm kiếm hoặc một số nhóm tập dữ liệu). Bạn nên thêm dữ liệu có cấu trúc về tập dữ liệu vào các trang chuẩn. Hãy sử dụng thuộc tính sameAs để liên kết đến trang chính tắc nếu bạn thêm dữ liệu có cấu trúc vào nhiều bản sao của tập dữ liệu, chẳng hạn như trang thông tin trong các trang kết quả tìm kiếm.
Các phương pháp hay nhất về nguồn
Thông thường các tập dữ liệu mở sẽ được xuất bản lại, tổng hợp và dựa trên các bộ dữ liệu khác. Đây là đề cương ban đầu về phương thức xử lý của chúng tôi trong những tình huống mà một tập dữ liệu là bản sao trùng lặp của (hoặc dựa trên) một tập dữ liệu khác.
- Sử dụng thuộc tính
sameAsđể chỉ ra các URL chính tắc cho bản gốc trong trường hợp tập dữ liệu hoặc đoạn mô tả chỉ là một bản sao trùng lặp của nội dung đã xuất bản ở nơi khác. Giá trị củasameAscần thể hiện rõ ràng đặc điểm của tập dữ liệu – nói cách khác là đừng dùng cùng một giá trịsameAscho hai tập dữ liệu riêng biệt. - Sử dụng thuộc tính
isBasedOntrong trường hợp tập dữ liệu xuất bản lại (bao gồm cả siêu dữ liệu của tập dữ liệu đó) đã thay đổi đáng kể. - Khi một tập dữ liệu được lấy từ hoặc là bản tổng hợp của một số tập dữ liệu gốc, hãy sử dụng thuộc tính
isBasedOn. - Sử dụng thuộc tính
identifierđể đính kèm Giá trị nhận dạng đối tượng kỹ thuật số (DOI) hoặc Giá trị nhận dạng rút gọn có liên quan bất kỳ. Nếu tập dữ liệu có nhiều hơn một giá trị nhận dạng, hãy sử dụng lại thuộc tínhidentifier. Nếu bạn sử dụng JSON-LD, thì thuộc tính này được biểu thị bằng cú pháp danh sách JSON.
Chúng tôi hy vọng sẽ cải thiện các mục đề xuất của chúng tôi dựa trên phản hồi, đặc biệt là phản hồi về cách mô tả nguồn, phiên bản và ngày xuất bản trong một chuỗi theo thời gian. Hãy tham gia các cuộc thảo luận trong cộng đồng.
Các thuộc tính văn bản nên có
Chúng tôi khuyên bạn nên giới hạn tất cả các thuộc tính văn bản ở mức 5000 ký tự trở xuống. Google Tìm kiếm Tập dữ liệu chỉ sử dụng 5000 ký tự đầu tiên của bất kỳ thuộc tính văn bản nào. Tên và tiêu đề thường là một vài từ hoặc một câu ngắn.
Lỗi và cảnh báo đã biết
Bạn có thể gặp lỗi hoặc cảnh báo trong công cụ Kiểm tra kết quả nhiều định dạng của Google và các hệ thống xác thực khác. Cụ thể, các hệ thống xác thực có thể đề xuất rằng các tổ chức phải cung cấp thông tin liên hệ bao gồm cả contactType; có những giá trị hữu ích như customer service, emergency, journalist, newsroom và public engagement.
Bạn cũng có thể bỏ qua các lỗi về csvw:Table vì đây là một giá trị ngoài dự kiến cho thuộc tính mainEntity.
Định nghĩa kiểu dữ liệu có cấu trúc
Bạn phải thêm các thuộc tính bắt buộc để nội dung của mình đủ điều kiện xuất hiện dưới dạng kết quả nhiều định dạng. Bạn cũng có thể sử dụng các thuộc tính mà chúng tôi khuyên dùng để cung cấp thêm thông tin về nội dung của bạn, qua đó mang lại trải nghiệm tốt hơn cho người dùng.
Bạn có thể sử dụng công cụ Kiểm tra kết quả nhiều định dạng để xác thực mã đánh dấu của mình.
Trọng tâm ở đây là mô tả thông tin về một tập dữ liệu (siêu dữ liệu) và thể hiện nội dung tương ứng. Ví dụ: siêu dữ liệu về một tập dữ liệu cho biết tập dữ liệu có nội dung gì, các biến số mà tập đó đo lường, người tạo tập dữ liệu, v.v. Tuy nhiên, siêu dữ liệu không chứa giá trị cụ thể cho các biến số và nhiều thông tin khác.
Dataset
Bạn có thể xem định nghĩa đầy đủ của Dataset tại
schema.org/Dataset.
Bạn có thể mô tả thông tin bổ sung về quá trình xuất bản tập dữ liệu, chẳng hạn như giấy phép, thời gian xuất bản, DOI của tập dữ liệu đó hoặc thuộc tính sameAs trỏ đến phiên bản chuẩn của tập dữ liệu trong một kho lưu trữ khác. Hãy thêm identifier, license và sameAs cho các tập dữ liệu có cung cấp thông tin giấy phép và nguồn.
Sau đây là các thuộc tính được Google hỗ trợ:
| Thuộc tính bắt buộc | |
|---|---|
description
|
Text
Một phần tóm tắt ngắn mô tả một tập dữ liệu. Nguyên tắc
|
name
|
Text
Tên mô tả của tập dữ liệu. Ví dụ: "Độ sâu của tuyết ở Bắc bán cầu". Nguyên tắc
Nên: Không nên: |
| Thuộc tính nên có | |
|---|---|
alternateName
|
Text
Tên thay thế đã dùng để tham chiếu đến tập dữ liệu này, chẳng hạn như bí danh hoặc từ viết tắt. Ví dụ (ở định dạng JSON-LD): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person hoặc OrganizationTác giả hoặc người tạo tập dữ liệu này. Để xác định riêng từng cá nhân, hãy dùng ID ORCID làm giá trị của thuộc tính "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text hoặc CreativeWorkXác định các bài báo học thuật mà nhà cung cấp dữ liệu đề xuất trích dẫn ngoài tập dữ liệu. Cung cấp thông tin trích dẫn cho chính tập dữ liệu bằng các thuộc tính khác, chẳng hạn như các thuộc tính "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Nguyên tắc bổ sung
|
funder
|
Person hoặc OrganizationMột cá nhân hoặc tổ chức hỗ trợ tài chính cho tập dữ liệu này. Để xác định riêng từng cá nhân, hãy dùng ID ORCID làm giá trị của thuộc tính "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart hoặc isPartOf
|
URL hoặc Dataset
Nếu tập dữ liệu là một tập hợp gồm các tập dữ liệu nhỏ hơn, hãy sử dụng thuộc tính "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text hoặc PropertyValue
Giá trị nhận dạng, chẳng hạn như DOI hoặc Compact Identifier. Nếu tập dữ liệu có nhiều hơn một giá trị nhận dạng, hãy sử dụng lại thuộc tính |
isAccessibleForFree
|
Boolean
Tập dữ liệu có cho phép truy cập mà không cần thanh toán hay không. |
keywords
|
Text
Từ khoá tóm tắt tập dữ liệu. |
license
|
URL hoặc CreativeWork
Giấy phép cho việc phân phối tập dữ liệu. Ví dụ: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Nguyên tắc bổ sung
|
measurementTechnique
|
Text hoặc URL
Kỹ thuật, công nghệ hoặc phương pháp được dùng trong một tập dữ liệu, có thể tương ứng với (các) biến được mô tả trong |
sameAs
|
URL
URL của một trang web tham khảo nêu rõ đặc điểm của tập dữ liệu này. |
spatialCoverage |
Text hoặc PlaceBạn có thể cung cấp một điểm duy nhất mô tả thuộc tính về không gian của tập dữ liệu. Bạn chỉ nên cung cấp thuộc tính này nếu tập dữ liệu có đặc tính không gian. Ví dụ: một điểm duy nhất mà tại đó tất cả số đo được lấy hoặc toạ độ của một vùng xung quanh một khu vực. Points "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Shapes Sử dụng "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } Các điểm bên trong các thuộc tính Địa điểm có tên "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
Dữ liệu trong tập dữ liệu về một khoảng thời gian cụ thể. Bạn chỉ nên cung cấp thuộc tính này nếu tập dữ liệu có đặc tính thời gian. Schema.org sử dụng tiêu chuẩn ISO 8601 để mô tả các khoảng thời gian và thời điểm. Bạn có thể mô tả ngày tháng theo cách khác nhau tuỳ thuộc vào khoảng thời gian trong tập dữ liệu. Hãy xác định các khoảng thời gian mở bằng hai dấu thập phân ( Một ngày cụ thể "temporalCoverage" : "2008" Khoảng thời gian "temporalCoverage" : "1950-01-01/2013-12-18" Khoảng thời gian mở "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text hoặc PropertyValue
Các biến mà tập dữ liệu này đo lường. Ví dụ: nhiệt độ hoặc áp suất. |
version
|
Text hoặc Number
Số phiên bản của tập dữ liệu. |
url
|
URL
Vị trí của một trang mô tả tập dữ liệu. |
DataCatalog
Bạn có thể xem định nghĩa đầy đủ của DataCatalog tại
schema.org/DataCatalog.
Các tập dữ liệu thường được xuất bản trong các kho lưu trữ có chứa nhiều tập dữ liệu khác. Một tập dữ liệu có thể nằm trong nhiều kho lưu trữ. Bạn có thể tham chiếu đến một danh mục dữ liệu có chứa tập dữ liệu này bằng cách trực tiếp tham chiếu đến danh mục đó bằng cách sử dụng các thuộc tính sau:
| Thuộc tính nên có | |
|---|---|
includedInDataCatalog
|
DataCatalog
Danh mục chứa tập dữ liệu.
|
DataDownload
Bạn có thể xem định nghĩa đầy đủ của DataDownload tại
schema.org/DataDownload. Ngoài các thuộc tính Dataset, hãy thêm các thuộc tính sau cho các tập dữ liệu cho phép chọn chế độ tải xuống.
Thuộc tính distribution mô tả cách tải tập dữ liệu vì URL thường trỏ đến trang đích mô tả tập dữ liệu. Thuộc tính distribution mô tả nơi tải dữ liệu và định dạng tải xuống. Thuộc tính này có thể có một số giá trị, ví dụ như phiên bản CSV nằm tại một URL và phiên bản Excel nằm tại một URL khác.
| Thuộc tính bắt buộc | |
|---|---|
distribution.contentUrl
|
URL
Đường liên kết để tải xuống. |
| Thuộc tính nên có | |
|---|---|
distribution
|
DataDownload
Thuộc tính mô tả vị trí để tải tập dữ liệu xuống và định dạng tải xuống.
|
distribution.encodingFormat
|
Text hoặc URL
Định dạng phân phối của tệp.
|
Tập dữ liệu dạng bảng
Một tập dữ liệu dạng bảng chủ yếu được sắp xếp thành các hàng và cột. Đối với các trang nhúng tập dữ liệu dạng bảng, bạn cũng có thể tạo mã đánh dấu rõ ràng hơn dựa trên phương thức cơ bản. Tại thời điểm này, chúng tôi hiểu được một biến thể của CSVW ("CSV trên Web", xem thêm tại W3C), biến thể này được cung cấp kèm theo nội dung dạng bảng dành cho người dùng trên trang HTML.
Sau đây là ví dụ cho thấy một bảng nhỏ được mã hoá theo định dạng JSON-LD của CSVW. Công cụ Kiểm tra kết quả nhiều định dạng có nêu một số lỗi đã biết.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Theo dõi kết quả nhiều định dạng bằng Search Console
Search Console là công cụ giúp bạn theo dõi hiệu quả hoạt động của các trang web trong Google Tìm kiếm. Bạn không cần đăng ký sử dụng Search Console để đưa trang web vào Google Tìm kiếm, nhưng việc làm vậy có thể giúp bạn hiểu và cải thiện cách Google nhìn thấy trang web của bạn. Bạn nên kiểm tra Search Console trong những trường hợp sau:
- Sau lần đầu triển khai dữ liệu có cấu trúc
- Sau khi phát hành mẫu mới hoặc cập nhật mã của bạn
- Phân tích lưu lượng truy cập định kỳ
Sau lần đầu triển khai dữ liệu có cấu trúc
Sau khi Google lập chỉ mục các trang của bạn, hãy tìm vấn đề bằng cách sử dụng Báo cáo trạng thái kết quả nhiều định dạng có liên quan. Lý tưởng nhất là số mục hợp lệ tăng lên và số mục không hợp lệ không tăng. Nếu bạn tìm thấy vấn đề trong dữ liệu có cấu trúc:
- Sửa các mục không hợp lệ.
- Kiểm tra URL đang hoạt động để xem vấn đề còn tồn tại không.
- Yêu cầu xác thực bằng cách sử dụng báo cáo trạng thái.
Sau khi phát hành các mẫu mới hoặc cập nhật mã
Khi bạn thực hiện những thay đổi đáng kể trên trang web của mình, hãy theo dõi xem số lượng mục dữ liệu có cấu trúc không hợp lệ có tăng lên hay không.- Nếu bạn thấy số mục không hợp lệ gia tăng, thì có lẽ bạn đã triển khai một mẫu mới không hoạt động được hoặc trang web của bạn tương tác với mẫu hiện có theo cách mới và không hợp lệ.
- Nếu bạn thấy số mục hợp lệ giảm (nhưng số mục không hợp lệ không tăng), thì có thể bạn không còn nhúng dữ liệu có cấu trúc trên các trang của mình nữa. Hãy sử dụng Công cụ kiểm tra URL để tìm hiểu nguyên nhân gây ra vấn đề.
Phân tích lưu lượng truy cập định kỳ
Phân tích lưu lượng truy cập bạn nhận được qua Google Tìm kiếm bằng cách sử dụng Báo cáo hiệu suất. Dữ liệu báo cáo sẽ cho bạn biết bạn tần suất trang web xuất hiện dưới dạng kết quả nhiều định dạng trong Tìm kiếm, tần suất người dùng nhấp vào trang và vị trí trung bình của trang trong kết quả tìm kiếm. Bạn cũng có thể tự động lấy các kết quả này bằng Search Console API.Khắc phục sự cố
Nếu gặp sự cố khi triển khai hoặc gỡ lỗi dữ liệu có cấu trúc, thì bạn có thể tham khảo một số tài nguyên trợ giúp sau đây.
- Nếu bạn đang sử dụng một hệ thống quản lý nội dung (CMS) hoặc có ai đó đang quản lý trang web của bạn, hãy đề nghị họ trợ giúp. Đừng quên chuyển tiếp mọi thông báo trong Search Console để nêu rõ vấn đề cho họ.
- Google không đảm bảo rằng các tính năng sử dụng dữ liệu có cấu trúc sẽ xuất hiện trong kết quả tìm kiếm. Để xem danh sách các lý do phổ biến khiến Google không thể hiển thị nội dung của bạn trong kết quả nhiều định dạng, hãy xem Nguyên tắc chung về dữ liệu có cấu trúc.
- Có thể có lỗi trong dữ liệu có cấu trúc của bạn. Vui lòng tham khảo danh sách lỗi liên quan đến dữ liệu có cấu trúc và Báo cáo về dữ liệu có cấu trúc không thể phân tích cú pháp.
- Nếu trang của bạn bị áp dụng hình phạt thủ công, thì dữ liệu có cấu trúc trên trang sẽ bị bỏ qua (mặc dù trang vẫn có thể xuất hiện trong các kết quả trên Google Tìm kiếm). Để khắc phục các vấn đề về dữ liệu có cấu trúc, hãy dùng báo cáo Hình phạt thủ công.
- Xem lại các nguyên tắc để xác định xem nội dung của bạn có tuân thủ nguyên tắc hay không. Nguyên nhân gây lỗi có thể là do bạn sử dụng nội dung không hợp lệ hoặc thẻ đánh dấu không hợp lệ. Tuy nhiên, vấn đề có thể không phải là lỗi cú pháp và do đó, Công cụ kiểm tra kết quả nhiều định dạng sẽ không thể xác định được những vấn đề như vậy.
- Khắc phục vấn đề thiếu kết quả nhiều định dạng/giảm tổng số kết quả nhiều định dạng
- Chờ một thời gian để Google thu thập dữ liệu và lập chỉ mục lại. Xin lưu ý rằng có thể mất nhiều ngày sau khi bạn xuất bản một trang thì Google mới tìm được và thu thập dữ liệu trên trang đó. Đối với các câu hỏi chung về hoạt động thu thập dữ liệu và lập chỉ mục, hãy tham khảo nội dung Câu hỏi thường gặp về việc thu thập dữ liệu và lập chỉ mục trên Google Tìm kiếm.
- Đăng câu hỏi trong diễn đàn của Trung tâm Google Tìm kiếm.
Một tập dữ liệu cụ thể không xuất hiện trong kết quả Tìm kiếm Tập dữ liệu
error Nguyên nhân: Trang web của bạn chưa có dữ liệu có cấu trúc trên trang mô tả tập dữ liệu hoặc trang này chưa được thu thập dữ liệu.
done Khắc phục vấn đề
- Hãy sao chép đường liên kết đến trang mà bạn mong nhìn thấy trong kết quả Tìm kiếm Tập dữ liệu và đưa đường liên kết này vào công cụ Kiểm tra kết quả nhiều định dạng. Nếu xuất hiện thông báo "Trang không đủ điều kiện cho các kết quả nhiều định dạng mà quy trình kiểm tra này xác định được", hoặc "Không phải mã đánh dấu nào cũng đủ điều kiện cho các kết quả nhiều định dạng", thì có nghĩa là trang đó chưa có mã đánh dấu loại Tập dữ liệu hoặc mã đánh dấu bị sai. Bạn có thể tham khảo phần Cách thêm dữ liệu có cấu trúc để khắc phục vấn đề này.
- Nếu trang đã có mã đánh dấu, thì vấn đề có thể là do trang chưa được thu thập dữ liệu. Bạn có thể kiểm tra trạng thái thu thập thông tin bằng Search Console.
Biểu trưng công ty bị thiếu hoặc không hiển thị chính xác trong phần kết quả
error Nguyên nhân: Trang của bạn có thể thiếu mã đánh dấu schema.org dành cho biểu trưng của tổ chức hoặc Google chưa nhận dạng doanh nghiệp của bạn.
done Khắc phục vấn đề
- Thêm dữ liệu có cấu trúc cho biểu trưng vào trang của bạn.
- Thiết lập thông tin doanh nghiệp của bạn trên Google