データセット(Dataset、DataCatalog、DataDownload)の構造化データ
データセットの名前、説明、作成者、配布形式などのサポート情報を構造化データとして提供すると、データセット検索ツールでデータセットを見つけやすくなります。Google のデータセット検出アプローチでは、schema.org とその他のメタデータ規格を利用します。これらは、データセットを記述するページに追加できます。Dataset マークアップの目的は、生命科学、社会科学、機械学習、市民および政府のデータなど、各種分野のデータセットを検出しやすくすることにあります。
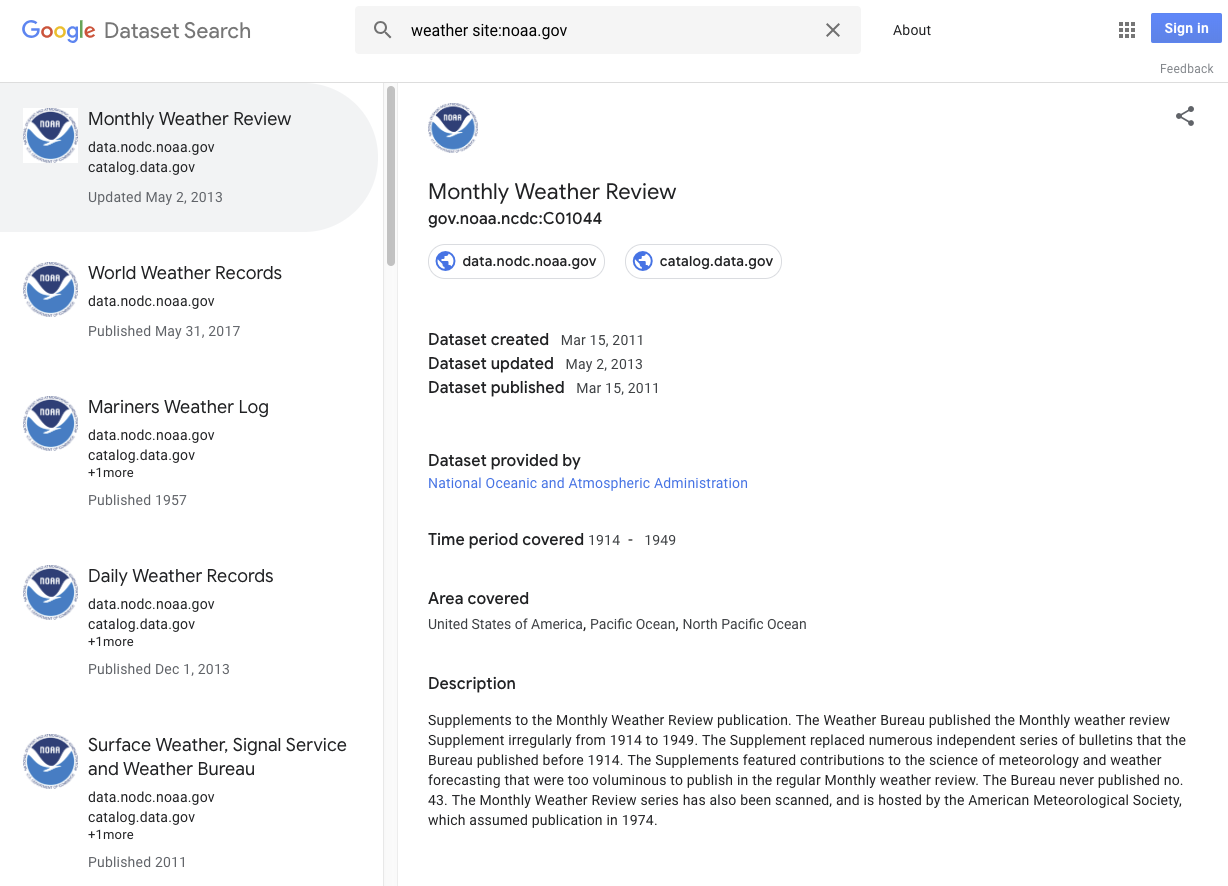
データセットと見なすことができるものには、以下があります。
- データが格納されているテーブルまたは CSV ファイル
- テーブルの組織的なコレクション
- データが格納されている固有の形式のファイル
- 意味を持つデータセットを全体として構成するファイルのコレクション
- 構造化オブジェクトと他の形式のデータの組み合わせ(処理を行うには特別なツールに読み込むことをおすすめします)
- 画像キャプチャ データ
- 機械学習に関連するファイル(学習済みパラメータやニューラル ネットワークの構造定義など)
構造化データを追加する方法
構造化データは、ページに関する情報を提供し、ページ コンテンツを分類するための標準化されたデータ形式です。構造化データを初めて使用する場合は、構造化データの仕組みについてをご覧ください。
構造化データの作成、テスト、リリースの概要は次のとおりです。
- 必須プロパティを追加します。使用している形式に基づいて、ページ上の構造化データを挿入する場所をご確認ください。
- ガイドラインに従います。
- リッチリザルト テストでコードを検証し、重大なエラーを修正します。ツールで報告される重大ではない問題の修正も検討してください。構造化データの品質向上に役立ちます(ただし、リッチリザルトの対象となるために必ずしも必要というわけではありません)。
- 構造化データが含まれているページを数ページ導入し、URL 検査ツールを使用して、Google でページがどのように表示されるかをテストします。Google がページにアクセスでき、robots.txt ファイル、
noindexタグ、ログイン要件によってページがブロックされていないことを確認します。ページが正常に表示されたら、Google に URL の再クロールを依頼できます。 - 今後の変更について Google に継続して情報を提供するために、サイトマップを送信することをおすすめします。これは、Search Console Sitemap API で自動化できます。
データセット検索結果からデータセットを削除する
データセットがデータセット検索結果に表示されないようにするには、robots meta タグを使用して、データセットのインデックス登録方法を制御します。データセット検索に変更が反映されるまでに、クロール スケジュールによっては数日または数週間かかることがあるので、ご注意ください。
Google のデータセット検出アプローチ
Google は、データセットに関するウェブページ内の構造化データを把握するため、schema.org の Dataset マークアップ、または W3C の Data Catalog Vocabulary(DCAT)形式で表現された同等の構造を使用しています。また、W3C CSVW に基づく構造化データの試験的なサポートを検討しており、データセットの記述に関する新たなベスト プラクティスとして Google のアプローチを進化、適応させることを目指しています。Google のデータセット検出アプローチについて詳しくは、データセットを検出しやすくする方法に関するブログ記事をご覧ください。
例
下記の例では、JSON-LD と schema.org 構文(推奨)で記述したデータセットに対してリッチリザルト テストを実行できます。RDFa 1.1 や microdata の構文でも、同じ schema.org のボキャブラリを使用できます。 W3C DCAT ボキャブラリを使用してメタデータを記述することもできます。次の例は、実際のデータセットの記述に基づいています。
JSON-LD でデータセットを記述する例を示します。
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>以下は、RDFa で DCAT ボキャブラリを使用して記述したデータセットの例です(リッチリザルト テストではサポートされていません)。
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>ガイドライン
サイトでは、構造化データのガイドラインを遵守する必要があります。さらに、サイトマップおよびソースと来歴に関するおすすめの方法を遵守することをおすすめします。
サイトマップに関するおすすめの方法
サイトマップ ファイルを使用すると、Google が URL を見つけやすくなります。また、サイトマップ ファイルと sameAs マークアップを使用すると、データセットの記述がサイト全体でどのように公開されているかを文書化できます。
データセット リポジトリを使用している場合は、少なくとも 2 種類のページが存在する可能性があります。つまり、各データセットの正規(「ランディング」)ページと、複数のデータセット(例: 検索結果、データセットの一部を含むサブセット)がリストされているページです。データセットに関する構造化データは正規ページに追加することをおすすめします。構造化データをデータセットの複数のコピー(検索結果ページ内のリストなど)に追加する場合は、sameAs プロパティを使用して正規ページにリンクします。
ソースと来歴に関するおすすめの方法
オープン データセットを再公開、集約したり、他のデータセットに基づくよう変更したりすることはよくあります。これは、データセットが別のデータセットのコピーであること(または別のデータセットに基づくものであること)を示すためのアプローチの初期段階です。
- データセットや記述が他のどこかで公開された素材を単に再公開したものである場合は、
sameAsプロパティを使用して、オリジナルのほとんどの正規 URL を指定します。sameAsの値は、データセットの ID を明確に示す必要があります。つまり、2 つの異なるデータセットで同じsameAs値を使用しないでください。 - 再公開されたデータセット(そのメタデータを含む)が大幅に変更された場合は、
isBasedOnプロパティを使用します。 - データセットが複数のオリジナルから派生したものである場合、または複数のオリジナルを集約したものである場合は、
isBasedOnプロパティを使用します。 identifierプロパティを使用して、関連性のあるデジタル オブジェクト識別子(DOI)またはコンパクト識別子をすべて付加します。データセットに識別子が複数ある場合は、identifierプロパティを繰り返し指定します。JSON-LD を使用している場合、これは JSON リスト構文によって表されます。
Google は、フィードバックに基づいて推奨事項(特に来歴の記述、バージョニング、および時系列公開に関連付けられている日付に関するもの)を改善したいと考えています。コミュニティのディスカッションにぜひご参加ください。
テキスト プロパティの推奨事項
すべてのテキスト プロパティは半角 5,000 文字(全角 2,500 文字)以下に制限することをおすすめします。Google データセット検索では、テキスト プロパティの最初の半角 5,000 文字(全角 2,500 文字)のみが使用されます。名前とタイトルは通常、数語または短い文にします。
既知のエラーと警告
Google のリッチリザルト テストとその他の検証システムで、エラーまたは警告が発生する場合があります。特に、組織で連絡先情報(contactType など)を使用するように検証システムが提案する場合があります。有用な値には、customer service、emergency、journalist、newsroom、public engagement などがあります。csvw:Table が mainEntity プロパティの予期しない値に設定されるエラーも無視して構いません。
構造化データタイプの定義
コンテンツがリッチリザルトとして表示されるようにするには、必須プロパティを含める必要があります。また、推奨プロパティを使用することでコンテンツに関する詳細情報を追加でき、ユーザー エクスペリエンスの向上につながります。
リッチリザルト テストを使用して、マークアップを検証できます。
データセット(データセットのメタデータ)に関する情報を記述し、データセットのコンテンツを表現することに焦点を当てます。たとえば、データセットのメタデータでは、データセットの内容、データセットで測定する変数、データセットの作成者などを記述します。変数の特定の値などは含めません。
Dataset
Dataset の定義の全文は schema.org/Dataset で確認できます。
データセットの公開に関する詳細情報(ライセンス、公開日、DOI、別のリポジトリに格納されているデータセットの正規バージョンを指している sameAs など)を記述できます。来歴やライセンスの情報を提供するデータセット用に identifier、license、sameAs を追加します。
Google がサポートするプロパティは、次のとおりです。
| 必須プロパティ | |
|---|---|
description
|
Text
データセットの要約文。 ガイドライン
|
name
|
Text
データセットのわかりやすい名前。例: "北半球の積雪量" ガイドライン
推奨: 2 つの異なるデータセットに対して 非推奨: 2 つの異なるデータセットに対して |
| 推奨プロパティ | |
|---|---|
alternateName
|
Text
エイリアスや略語など、データセットを示すために使用されている代替名。JSON-LD 形式の例を以下に示します。 "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person または Organization
このデータセットの作成者。個人を一意に識別するには、 "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text または CreativeWork
データセットに加えて引用されている、データ プロバイダが推奨する学術記事を識別します。データセット自体の引用は、 "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" その他のガイドライン
|
funder
|
Person または Organization
このデータセットの資金提供を行う個人または組織。個人を一意に識別するには、 "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart または isPartOf
|
URL または Dataset
データセットが小さなデータセットのコレクションである場合、 "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL、Text、または PropertyValue
DOI やコンパクト識別子などの識別子。データセットに識別子が複数ある場合は、 |
isAccessibleForFree
|
Boolean
支払いなしでデータセットにアクセスできるかどうかを指定します。 |
keywords
|
Text
データセットの概要を示すキーワード。 |
license
|
URL または CreativeWork
データセットの配布ライセンス。次に例を示します。 "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } その他のガイドライン
|
measurementTechnique
|
Text または URL
データセットで使用される手法、テクノロジー、または方法。 |
sameAs
|
URL
データセットの ID を明確に示す参照ウェブページの URL。 |
spatialCoverage |
Text または Place
データセットの空間様相を記述する単一のポイントを指定できます。このプロパティは、データセットに空間ディメンションが含まれている場合にのみ追加します。たとえば、すべての測定結果が収集された単一のポイントや、ある領域の境界ボックスの座標などを指定します。 ポイント "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } 図形
"spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } }
名前のついた場所 "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
データセットのデータは、特定の期間を対象として含みます。このプロパティは、データセットに時間ディメンションが含まれている場合にのみ追加します。schema.org では、期間や時点を記述するために ISO 8601 規格を使用しています。データセットの期間に応じて日付を別々に記述できます。無期限の期間は、小数点 2 つ( 単一の日付 "temporalCoverage" : "2008" 期間 "temporalCoverage" : "1950-01-01/2013-12-18" 無期限の期間 "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text または PropertyValue
データセットが測定する変数(温度や圧力など)。 |
version
|
Text または Number
データセットのバージョン番号。 |
url
|
URL
データセットを記述するページの場所。 |
DataCatalog
DataCatalog の定義の全文は schema.org/DataCatalog で確認できます。
多くの場合、データセットは他の多くのデータセットが格納されているリポジトリで公開されます。同じデータセットをそのような複数のリポジトリに含めることができます。データセットが属しているデータカタログを参照するには、次のプロパティを使用して直接参照します。
| 推奨プロパティ | |
|---|---|
includedInDataCatalog
|
DataCatalog
データセットが含まれているカタログ。
|
DataDownload
DataDownload の定義の全文は schema.org/DataDownload で確認できます。Dataset プロパティに加え、ダウンロード オプションを提供する、以下のデータセット用のプロパティを追加します。
distribution プロパティでは、データセット自体を取得する方法を記述します。これは、URL がデータセットを記述するランディング ページを指していることが多いためです。distribution プロパティでは、データをどこでどの形式で取得するかを記述します。このプロパティでは複数の値を使用できます。たとえば、CSV バージョンで 1 つの URL を使用し、Excel バージョンを別の URL で使用できます。
| 必須プロパティ | |
|---|---|
distribution.contentUrl
|
URL
ダウンロードのリンク。 |
| 推奨プロパティ | |
|---|---|
distribution
|
DataDownload
データセットのダウンロードの場所と、ダウンロードのファイル形式の記述。
|
distribution.encodingFormat
|
Text または URL
配布のファイル形式。
|
表形式のデータセット
表形式のデータセットは、主に行と列のグリッドで構成されたデータセットです。表形式のデータセットが埋め込まれているページでは、基本的なアプローチを基に、より明示的なマークアップを作成することもできます。現時点では、HTML ページでユーザー指向の表形式コンテンツと並行して提供される、CSVW(「CSV on the Web」、W3C をご覧ください)のバリエーションと解釈しています。
次の例は、CSVW JSON-LD 形式でエンコードされた小規模なテーブルを示しています。リッチリザルト テストには既知のエラーがいくつかあります。
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Search Console でリッチリザルトを監視する
Search Console は、Google 検索におけるページのパフォーマンスを監視できるツールです。Search Console に登録していなくても Google 検索結果に表示されますが、登録することにより、Google がサイトをどのように認識しているかを把握して改善できるようになります。次の場合は Search Console を確認することをおすすめします。
構造化データを初めてデプロイした後
ページがインデックスに登録されたら、関連するリッチリザルトのステータス レポートを使用して、問題がないかどうかを確認します。有効な項目が増え、無効な項目が増えていない状態が理想的です。構造化データに問題が見つかった場合の手順は次のとおりです。
- 無効な項目を修正します。
- 一般公開 URL の検査を行い、問題が解決したかどうかを確認します。
- ステータス レポートを使用して検証をリクエストします。
新しいテンプレートをリリースした後やコードを更新した後
ウェブサイトに大幅な変更を加えた場合は、構造化データの無効な項目が増加しないかどうか監視します。- 無効な項目が増加した場合は、新しく公開したテンプレートが正常に機能していないか、既存のテンプレートの新しい操作方法に問題があると考えられます。
- 有効な項目が減少している(無効な項目の増加と一致しない)場合は、ページに構造化データが埋め込まれていない可能性があります。URL 検査ツールを使用して問題の原因を特定します。
トラフィックを定期的に分析する場合
パフォーマンス レポートを使用して Google 検索のトラフィックを分析します。このデータから、検索でページがリッチリザルトとして表示される頻度、ユーザーがページをクリックする頻度、検索結果におけるページの平均掲載順位がわかります。この結果は、Search Console API を使用して自動的に取得することもできます。トラブルシューティング
構造化データの実装またはデバッグで問題が発生した場合は、以下のリソースが参考になります。
- コンテンツ管理システム(CMS)を使用している場合や、別の人がサイトを管理している場合は、担当者にサポートを依頼してください。その際は、問題の詳細を含む Search Console のメッセージを必ず転送してください。
- 構造化データを使用するコンテンツが必ず検索結果に表示されるとは限りません。コンテンツがリッチリザルトに表示されないときのよくある原因については、構造化データに関する一般的なガイドラインをご覧ください。
- 構造化データにエラーがある可能性があります。構造化データエラーの一覧と解析不能な構造化データに関するレポートを確認してください。
- 構造化データへの手動による対策がページに対して行われると、ページ上の構造化データが考慮されなくなります(ただし、Google 検索結果にはページは引き続き表示されます)。構造化データの問題を修正するには、手動による対策レポートを使用します。
- コンテンツにガイドライン違反がないか、ガイドラインを再度確認してください。スパム コンテンツまたはスパム マークアップの使用が原因で、問題が発生することがありますが、これは構文の問題ではない可能性があり、リッチリザルト テストでは特定できません。
- リッチリザルトが見つからない場合やリッチリザルトの総数が減少している場合のトラブルシューティングを行ってください。
- 再クロールとインデックスの再登録にかかる時間を考慮してください。ページを公開した後、Google がそのページを検出してクロールするまで数日かかる場合があることにご注意ください。クロールとインデックス登録に関する一般的な質問については、Google 検索のクロールとインデックス登録に関するよくある質問をご覧ください。
- Google 検索セントラル フォーラムでも質問を受け付けています。
特定のデータセットがデータセット検索結果に表示されない
error 問題の原因: サイトのデータセットを記述しているページに構造化データがないか、またはページがまだクロールされていません。
done 問題の修正方法
- データセット検索結果に表示したいページのリンクをコピーして、リッチリザルト テストに貼り付けます。「このテストによって判明したリッチリザルトの対象外のページ」または「一部のマークアップがリッチリザルトの対象ではありません」というメッセージが表示される場合は、ページにデータセットのマークアップがないか、マークアップが間違っています。この問題の修正方法については、構造化データを追加する方法のセクションをご覧ください。
- ページにマークアップがある場合は、まだクロールされていない可能性があります。Search Console でクロール ステータスを確認できます。
検索結果に会社のロゴが表示されない、または正しく表示されない
error 問題の原因: 会社のロゴに対応する schema.org マークアップがないか、またはビジネスに関して Google の機能が活用されていません。
done 問題の修正方法
- ロゴの構造化データをページに追加します。
- Google でビジネスの詳細を際立たせるための手段を講じます。