Places Insights を使用すると、Google マップの豊富なプレイスデータに対して高度な統計分析を行うことができます。数百万のスポット(POI)データポイントの集計数と密度情報を提供し、強力な地理空間インテリジェンスを実現します。
主な機能:
- 地理空間インテリジェンス: 特定の地域におけるさまざまなカテゴリの POI(小売店、レストラン、サービスなど)の密度と分布を俯瞰的に把握できます。
- 安全なデータアクセス: データは、データ保護が実施された BigQuery データ エクスチェンジ リスティングを使用してデプロイされるため、データ共有と分析のための安全で保護された環境が実現します。
- Actionable Detail: Places Insights は集計された傾向に焦点を当てていますが、出力されたプレイス ID を使用して、他の Google Maps Platform API を使用して個々の場所情報をドリルダウンして取得し、統計的な分析情報から詳細なアクションに移行できます。
プレイス データについて
Google マップは、世界中の何百万もの施設の場所データをキュレートしています。Places Insights は、この包括的なプレイスデータを BigQuery で利用できるようにします。これにより、プレイスタイプ、評価、営業時間、車椅子でのアクセスなど、さまざまな属性に基づいて Google マップのプレイスデータに関する集約された分析情報を得ることができます。
Places Insights を使用するには、BigQuery でSQL クエリを記述します。このクエリは、スポットデータに関する統計分析情報を返します。これらの分析情報を使用すると、次のような質問に答えることができます。
- 新しい店舗の候補地の近くで、類似のビジネスがいくつ営業しているか。
- 最も成功している店舗の近くには、どのような種類のビジネスがよく見られますか?
- ターゲット顧客を引き付ける可能性のある補完的なビジネスが集中しているエリアはどこですか?
- マドリードで午後 8 時に営業しており、車椅子で利用できる駐車場があり、テイクアウトができる 5 つ星の寿司店は何軒ありますか?
- カリフォルニア州で EV 充電スタンドの密度が最も高い郵便番号はどこですか?
Places Insights は、次のような複数のユースケースをサポートしています。
- サイトの選択: 新しいビジネスや物理アセットの配置に最適な場所を評価して選択します。周辺の POI の密度と構成を分析することで、競合他社や補完的なビジネス環境内で、候補地が最適な位置にあることを確認できます。このデータドリブン アプローチにより、新しいロケーションへの投資に関連するリスクを軽減できます。
- 店舗のパフォーマンス評価: スーパーマーケットやイベント会場などの特定の種類の POI への近さなど、既存の店舗のパフォーマンスの高さ / 低さと相関する地理空間変数を特定します。このデータを使用すると、ユースケースに最適な地理空間特性の組み合わせを共有する候補地を特定できます。この情報を使用して、周辺の POI コンテキストに基づいて新しい場所の将来のパフォーマンスを予測する予測モデルをデプロイすることもできます。
- 地域ターゲティング マーケティング: ある地域で成功するマーケティング キャンペーンや広告の種類を特定します。Places Insights は、商取引活動を理解するために必要なコンテキストを提供します。これにより、関連するビジネスやアクティビティの集中度に基づいてメッセージを調整できます。
- 売上予測: 見込みのある場所での将来の売上を予測します。周辺の地理空間特性の影響をモデリングすることで、投資判断を促進する堅牢な予測モデルを作成できます。
- 市場調査: ビジネスやサービスを次にどの地域に拡大すべきかを判断できます。既存の市場飽和度と POI 密度を分析して、最も大きな機会を提供する、サービスが不足しているか、高度に集中しているターゲット市場を特定します。この分析は、戦略的な成長と拡大のイニシアチブを裏付ける証拠となります。
Places Insights データセットを直接クエリするか、Places Count 関数を使用できます。
ブランドデータについて
プレイス データに加えて、プレイス分析情報には、同じブランド名で複数の店舗を運営しているブランドや店舗に関するデータも含まれます。
ブランドを使用すると、次のような疑問を解決できます。
- エリア内のブランド別の店舗数を教えてください。
- このエリアの上位 3 社の競合ブランドの数は?
- このエリアにあるコーヒー ショップのうち、これらのブランド以外の店舗の数はいくつですか?
BigQuery について
BigQuery リスティングでデータを利用できるようにすることで、Places Insights では次のことが可能になります。
- 自社のデータと Places Insights データを安全に組み合わせます。
- 柔軟な SQL クエリを作成して、特定のビジネスニーズに対応する集計された分析情報を取得します。
- プライベート データとワークフローですでに使用している BigQuery ツールをそのまま使用できます。
- BigQuery のスケーラビリティとパフォーマンスを活用して、大規模なデータセットを簡単に分析できます。
使用例
この例では、BigQuery でデータを Places Insights データと結合して、集計情報を導出します。この例では、ニューヨーク市に複数の店舗を持つホテルオーナーであるとします。ホテル周辺の事前定義されたビジネスタイプの集中度を把握するために、ホテルの位置情報データを Places Insights データと結合したいと考えています。
前提条件
この例では、米国の Places Insights データセットをサブスクライブします。
ホテル データセットの名前は mydata で、ニューヨーク市にある 2 つのホテルの所在地を定義します。次の SQL は、このデータセットを作成します。
CREATE OR REPLACE TABLE `mydata.hotels` ( name STRING, location GEOGRAPHY ); INSERT INTO `mydata.hotels` VALUES( 'Hotel 1', ST_GEOGPOINT(-73.9933, 40.75866) ); INSERT INTO `mydata.hotels` VALUES( 'Hotel 2', ST_GEOGPOINT(-73.977713, 40.752124) );
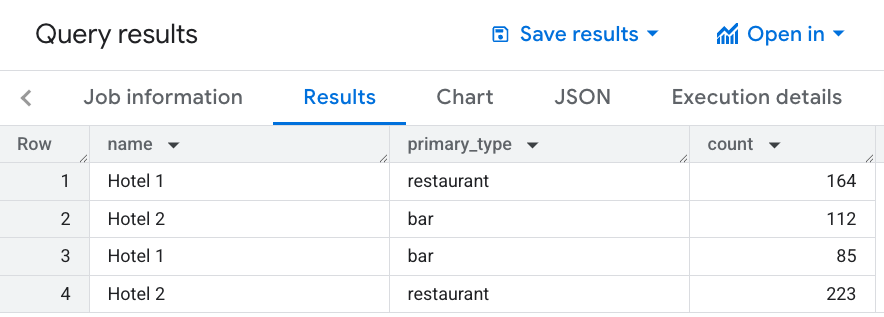
エリア内のレストランの数を取得する
ホテル周辺の営業中のレストランの密度を顧客に伝えるため、各ホテルから 1, 000 メートル以内のレストランの数を返す SQL クエリを作成します。
SELECT WITH AGGREGATION_THRESHOLD h.name, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` AS r, `mydata.hotels` AS h WHERE ST_DWITHIN(h.location, r.point, 1000) AND r.primary_type = 'restaurant' AND business_status = "OPERATIONAL" GROUP BY 1
この画像は、このクエリの出力例を示しています。
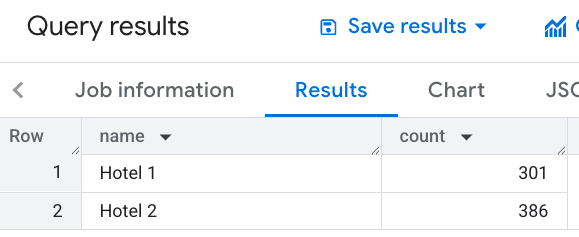
Places Count 関数を使用して、エリア内のレストランの数とプレイス ID を取得する
場所のカウント関数を使用することもできます。
特定の場所の近くにあるレストランの数を取得します。Places Count 関数を使用すると、個々の場所の詳細を検索するために使用できるプレイス ID のリストを取得できます。
DECLARE geo GEOGRAPHY; SET geo = ST_GEOGPOINT(-73.9933, 40.75866); -- Location of hotel 1 SELECT * FROM `PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_TYPE`( JSON_OBJECT( 'types', ["restaurant", "cafe", "bar"], 'geography', geo, 'geography_radius', 1000 -- Radius in meters ) );
この画像は、このクエリの出力例を示しています。
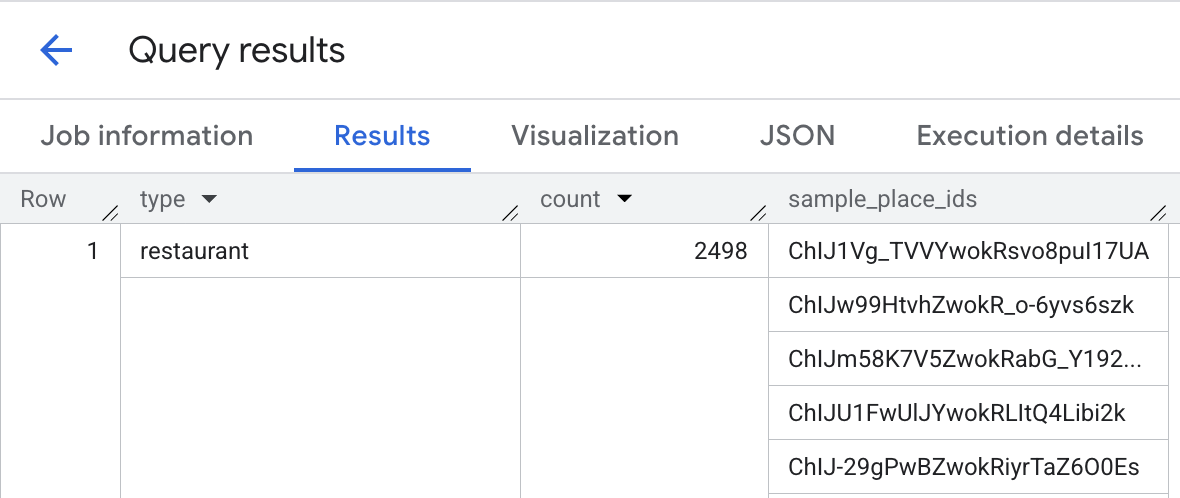
エリア内のレストランとバーの数を取得する
各ホテルから 1,000 メートル以内のレストランに加えてバーも含むようにクエリを変更します。
SELECT WITH AGGREGATION_THRESHOLD h.name, r.primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` AS r, `mydata.hotels` AS h WHERE ST_DWITHIN(h.location, r.point, 1000) AND r.primary_type IN UNNEST(['restaurant','bar']) AND business_status = "OPERATIONAL" GROUP BY 1, 2
この画像は、このクエリの出力例を示しています。
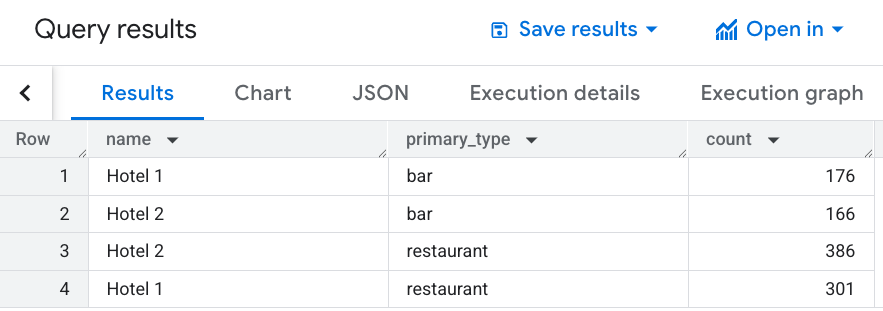
エリア内の中価格帯のレストランとバーの数を取得する
次に、バーやレストランがどの顧客層にサービスを提供しているかを確認します。ホテルは中価格帯をターゲットにしているため、その価格帯で評価の高い近隣の施設のみを宣伝したい。
価格帯が PRICE_LEVEL_MODERATE で、評価が 4 つ星以上のバーとレストランのみを返すようにクエリを制限します。このクエリでは、各ホテルの半径を 1,500 メートルに拡大しています。
SELECT WITH AGGREGATION_THRESHOLD h.name, r.primary_type, COUNT(*) AS count FROM `PROJECT_NAME.places_insights___us.places` AS r, `mydata.hotels` AS h WHERE ST_DWITHIN(h.location, r.point, 1500) AND r.primary_type IN UNNEST(['restaurant', 'bar']) AND rating >= 4 AND business_status = "OPERATIONAL" AND price_level = 'PRICE_LEVEL_MODERATE' GROUP BY 1, 2
この画像は、このクエリの出力例を示しています。