
در این سند، شما یاد خواهید گرفت که چگونه از دادههای نمونهی شناسههای مکان از Places Insights ، با استفاده از توابع شمارش مکان ، در کنار جستجوی هدفمند جزئیات مکان، برای ایجاد اطمینان در نتایج خود استفاده کنید.
برای پیادهسازی دقیق این الگو به این دفترچه توضیحی مراجعه کنید:
 مشاهده منبع در گیتهاب
مشاهده منبع در گیتهاب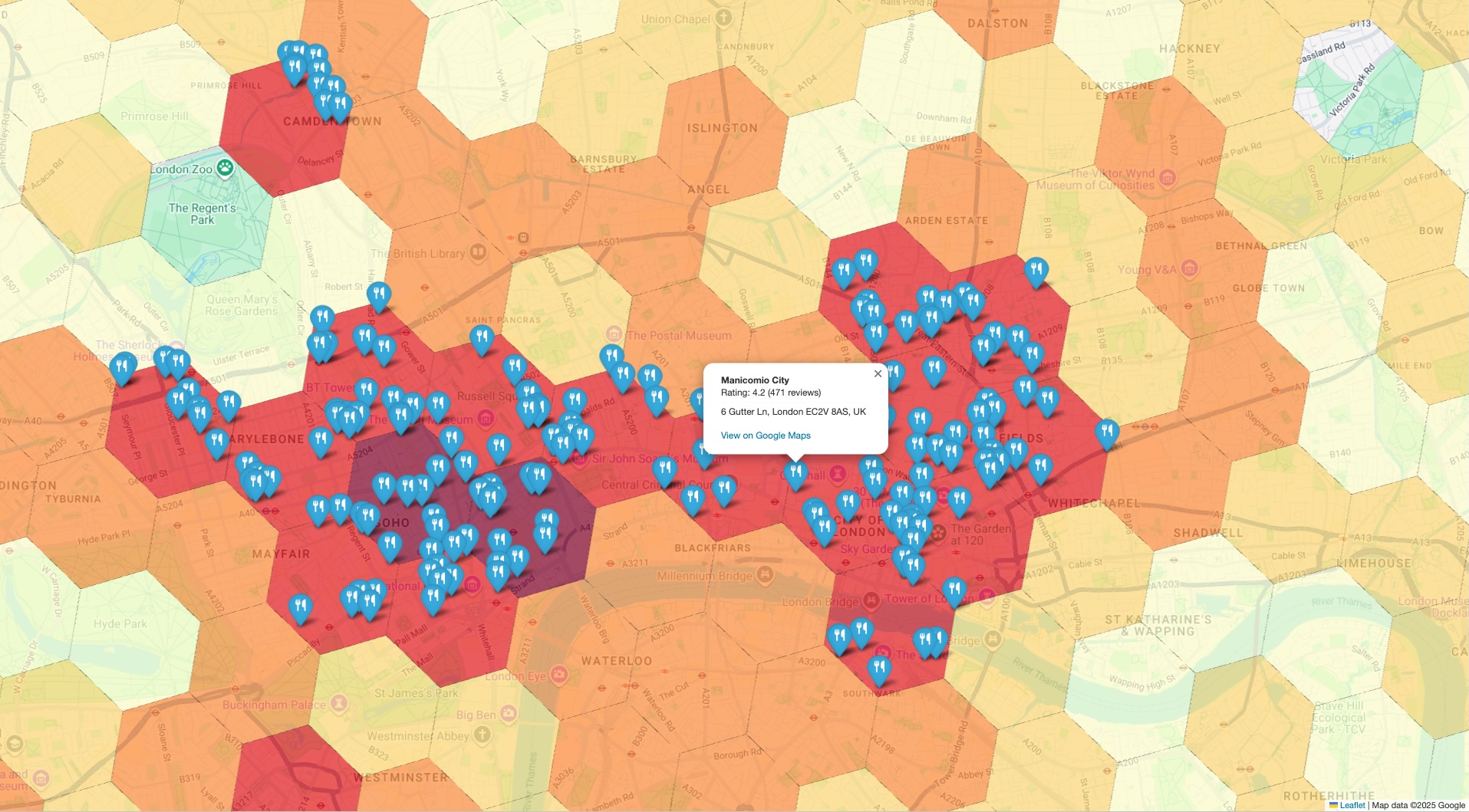
الگوی معماری
این الگوی معماری، یک گردش کار تکرارپذیر را برای پر کردن شکاف بین تحلیل آماری سطح بالا و تأیید صحت دادهها در اختیار شما قرار میدهد. با ترکیب مقیاس BigQuery با دقت Places API ، میتوانید با اطمینان یافتههای تحلیلی خود را اعتبارسنجی کنید. این امر به ویژه برای انتخاب سایت، تحلیل رقبا و تحقیقات بازار که در آنها اعتماد به دادهها از اهمیت بالایی برخوردار است، مفید است.
هسته اصلی این الگو شامل چهار مرحله کلیدی است:
- انجام تحلیل در مقیاس بزرگ: از تابع شمارش مکان از Places Insights در BigQuery برای تحلیل دادههای مکانی در یک جغرافیای بزرگ، مانند کل یک شهر یا منطقه، استفاده کنید.
- جداسازی و استخراج نمونهها: مناطق مورد نظر (مثلاً «نقاط داغ» با چگالی بالا) را از نتایج تجمیعشده شناسایی کرده و
sample_place_idsارائه شده توسط تابع را استخراج کنید. - بازیابی جزئیات واقعی: از شناسههای مکان استخراجشده برای برقراری تماسهای هدفمند با API جزئیات مکان استفاده کنید تا جزئیات غنی و واقعی هر مکان را دریافت کنید.
- ایجاد یک تجسم ترکیبی: دادههای دقیق مکان را روی نقشه آماری اولیه سطح بالا لایهبندی کنید تا از نظر بصری تأیید شود که شمارشهای جمعآوریشده منعکسکننده واقعیت روی زمین هستند.
گردش کار راهکار
این گردش کار به شما امکان میدهد شکاف بین روندهای سطح کلان و حقایق سطح خرد را پر کنید. شما با یک دیدگاه آماری گسترده شروع میکنید و به صورت استراتژیک به بررسی دقیقتر دادهها با مثالهای خاص و واقعی میپردازید.
با Places Insights، تراکم مکان را در مقیاس مورد نظر تجزیه و تحلیل کنید
اولین قدم شما این است که چشمانداز را در سطح بالایی درک کنید. به جای واکشی هزاران نقطه مورد علاقه (POI) مجزا، میتوانید یک پرسوجوی واحد را اجرا کنید تا خلاصهای آماری به دست آورید.
تابع PLACES_COUNT_PER_H3 در Places Insights برای این کار ایدهآل است. این تابع تعداد نقاط مورد علاقه (POI) را در یک سیستم شبکهای ششضلعی (H3) تجمیع میکند و به شما امکان میدهد بر اساس معیارهای خاص خود (مثلاً رستورانهایی با امتیاز بالا که فعال هستند) به سرعت مناطقی با تراکم بالا یا پایین را شناسایی کنید.
یک نمونه پرسوجو به شرح زیر است. توجه داشته باشید که از شما خواسته میشود جغرافیای منطقه جستجوی خود را ارائه دهید. یک مجموعه داده باز، مانند مجموعه داده عمومی Overture Maps Data BigQuery میتواند برای بازیابی دادههای مرز جغرافیایی استفاده شود.
برای مرزهای مجموعه دادههای باز که اغلب استفاده میشوند، توصیه میکنیم آنها را در یک جدول در پروژه خود پیادهسازی کنید. این کار به طور قابل توجهی هزینههای BigQuery را کاهش داده و عملکرد پرسوجو را بهبود میبخشد.
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
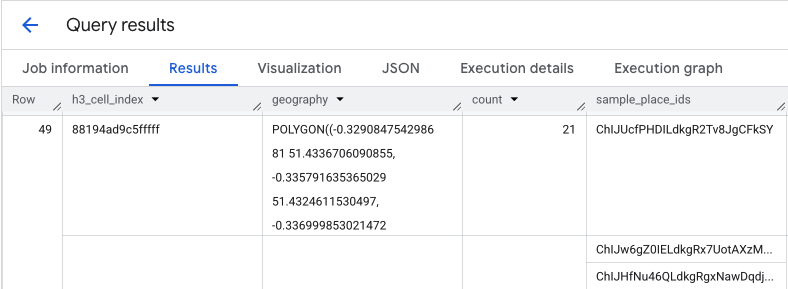
خروجی این کوئری جدولی از سلولهای H3 و تعداد مکانهای درون هر کدام را به شما میدهد که مبنایی برای نقشه حرارتی چگالی است.
نقاط مهم را جدا کرده و شناسههای مکان نمونه را استخراج کنید
نتیجه تابع PLACES_COUNT_PER_H3 همچنین آرایهای از sample_place_ids را برمیگرداند که تا ۲۵۰ شناسه مکان برای هر عنصر از پاسخ را شامل میشود. این شناسهها، پیوندی از آمار تجمیعشده به مکانهای منفردی هستند که در آن مشارکت دارند.
سیستم شما میتواند ابتدا مرتبطترین سلولها را از پرسوجوی اولیه شناسایی کند. برای مثال، ممکن است 20 سلول برتر با بیشترین تعداد را انتخاب کنید. سپس، از این نقاط مهم، sample_place_ids را در یک لیست واحد تجمیع میکنید. این لیست نشاندهنده یک نمونه انتخابشده از جالبترین POIها از مرتبطترین مناطق است و شما را برای تأیید هدفمند آماده میکند.
اگر نتایج BigQuery خود را در پایتون با استفاده از یک DataFrame از Pandas پردازش میکنید، منطق استخراج این شناسهها ساده است:
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
منطق مشابهی را میتوان در صورت استفاده از زبانهای برنامهنویسی دیگر نیز به کار برد.
بازیابی جزئیات واقعیت زمینی با Places API
با فهرست تجمیعشدهی شناسههای مکان، اکنون از تجزیه و تحلیل در مقیاس بزرگ به بازیابی دادههای خاص منتقل میشوید. شما از این شناسهها برای پرسوجو از API جزئیات مکان برای اطلاعات دقیق در مورد هر مکان نمونه استفاده خواهید کرد.
این یک مرحلهی اعتبارسنجی حیاتی است. در حالی که Places Insights به شما میگفت چند رستوران در یک منطقه وجود دارد، Places API به شما میگوید که کدام رستورانها هستند و نام، آدرس دقیق، عرض/طول جغرافیایی، امتیاز کاربر و حتی لینک مستقیمی به مکان آنها در نقشههای گوگل را ارائه میدهد. این کار دادههای نمونهی شما را غنی میکند و شناسههای انتزاعی را به مکانهای ملموس و قابل تأیید تبدیل میکند.
برای مشاهده لیست کامل دادههای موجود از API جزئیات مکان و هزینه مربوط به بازیابی، مستندات API را بررسی کنید .
یک درخواست به Places API برای یک شناسه خاص با استفاده از کتابخانه کلاینت پایتون به این شکل خواهد بود. برای جزئیات بیشتر به مثالهای کتابخانه کلاینت Places API (جدید) مراجعه کنید.
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
توجه داشته باشید که فیلدهای این درخواست، دادهها را از دو SKU صورتحساب مختلف دریافت میکنند.
- آدرس و
locationformattedAddressبخشی از SKU جزئیات مکان ضروری هستند. -
displayNameوgoogleMapsUriبخشی از SKU مربوط به Place Details Pro هستند.
وقتی یک درخواست جزئیات مکان شامل فیلدهایی از چندین SKU باشد، کل درخواست با نرخ SKU بالاترین سطح محاسبه میشود. بنابراین، این درخواست خاص به عنوان یک درخواست جزئیات مکان حرفهای محاسبه خواهد شد.
برای کنترل هزینههایتان، همیشه از FieldMask برای درخواست فقط فیلدهایی که برنامهتان نیاز دارد استفاده کنید.
ایجاد یک تجسم ترکیبی برای اعتبارسنجی
مرحله آخر، گرد هم آوردن هر دو مجموعه داده در یک نمای واحد است. این یک روش فوری و شهودی برای بررسی دقیق تحلیل اولیه شما فراهم میکند. تجسم شما باید دو لایه داشته باشد:
- لایه پایه: یک نمودار خوشهبندی یا نقشه حرارتی تولید شده از نتایج اولیه
PLACES_COUNT_PER_H3که تراکم کلی مکانها را در سراسر جغرافیای شما نشان میدهد. - لایه بالایی: مجموعهای از نشانگرهای مجزا برای هر نقطه مورد توجه نمونه، که با استفاده از مختصات دقیق بازیابی شده از API مکانها در مرحله قبل، ترسیم شدهاند.
منطق ساخت این نمای ترکیبی در این مثال شبه کد بیان شده است:
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
با روی هم قرار دادن نشانگرهای خاص و واقعی روی نقشه تراکم سطح بالا، میتوانید فوراً تأیید کنید که مناطقی که به عنوان نقاط حساس شناسایی شدهاند، در واقع شامل تمرکز بالایی از مکانهایی هستند که شما در حال تجزیه و تحلیل آنها هستید. این تأیید بصری، اعتماد قابل توجهی به نتیجهگیریهای مبتنی بر داده شما ایجاد میکند.
نتیجهگیری
این الگوی معماری، روشی قوی و کارآمد برای اعتبارسنجی بینشهای مکانی در مقیاس بزرگ ارائه میدهد. با بهرهگیری از Places Insights برای تجزیه و تحلیل گسترده و مقیاسپذیر و Place Details API برای تأیید هدفمند و مبتنی بر واقعیت، شما یک حلقه بازخورد قدرتمند ایجاد میکنید. این امر تضمین میکند که تصمیمات استراتژیک شما، چه در انتخاب سایت خردهفروشی و چه در برنامهریزی لجستیک، بر اساس دادههایی باشد که نه تنها از نظر آماری معنادار هستند، بلکه به طور قابل تأییدی دقیق نیز میباشند.
مراحل بعدی
- توابع شمارش مکان دیگر را بررسی کنید تا ببینید چگونه میتوانند به سوالات تحلیلی مختلف پاسخ دهند.
- برای کشف فیلدهای دیگری که میتوانید برای غنیسازی بیشتر تحلیل خود درخواست کنید، مستندات Places API را مرور کنید.
مشارکتکنندگان
هنریک والو | مهندس DevX