
Giriş
Bu belgede, Places Insights veri kümesi, BigQuery'deki herkese açık coğrafi veriler ve Yer Ayrıntıları API'yi birleştirerek nasıl site seçimi çözümü oluşturulacağı açıklanmaktadır.
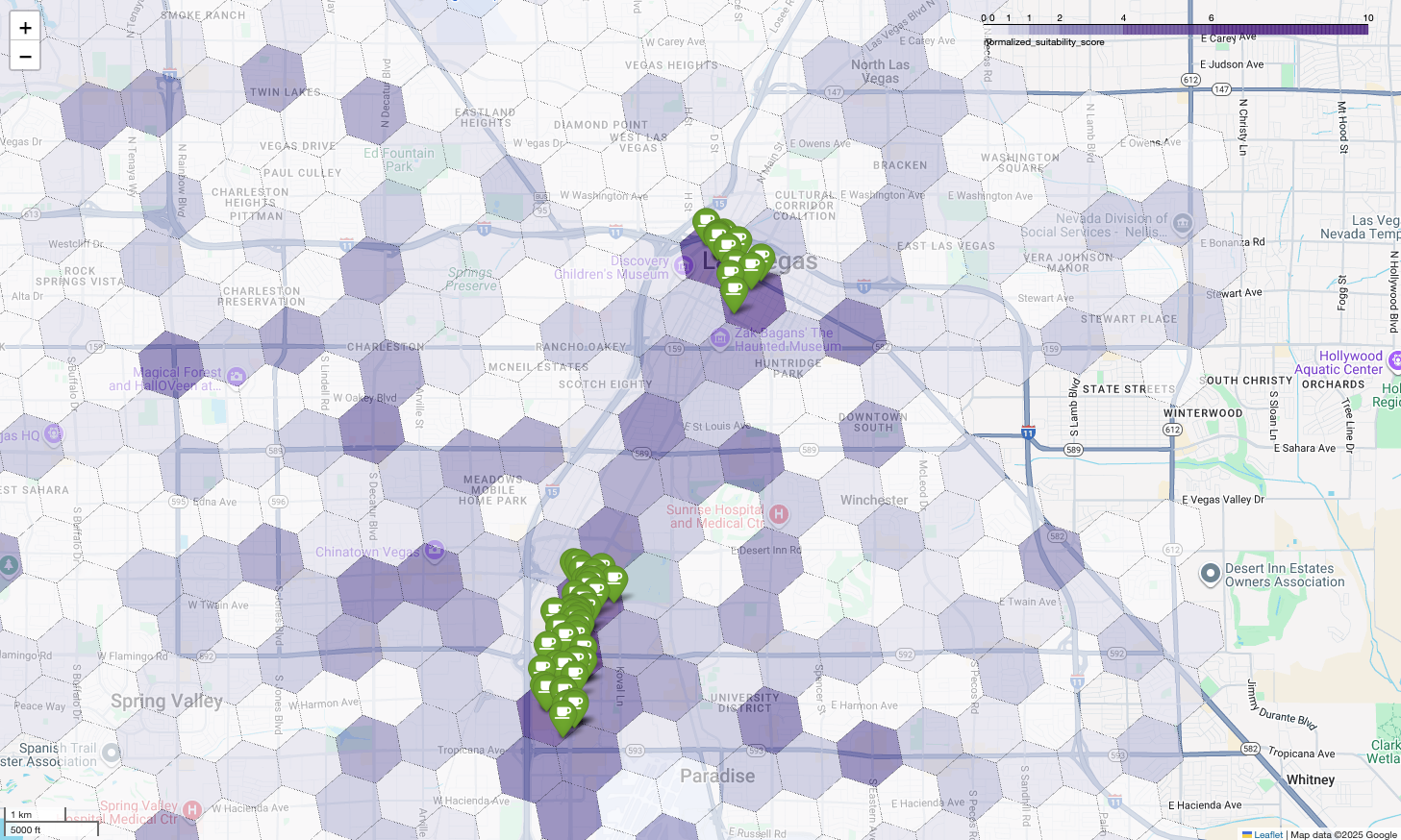
Yukarıdaki harita, Google Cloud Next 2025'te verilen bir demoda elde edilen sonucu gösterir. Bu demoyu YouTube'da izleyebilirsiniz. Bu sonuçları oluşturmak için kullanılan kodu örnek not defterini kullanarak çalıştırabilirsiniz.
 Kaynağı GitHub'da görüntüle
Kaynağı GitHub'da görüntüle
İşletmeyle İlgili Görev
Başarılı bir kahve dükkanları zinciriniz olduğunu ve Nevada gibi hiç bulunmadığınız yeni bir eyalette işinizi büyütmek istediğinizi düşünün. Yeni bir konum açmak önemli bir yatırımdır ve başarı için veriye dayalı bir karar vermek kritik öneme sahiptir. Nereden başlayacağınızı bilemiyor musunuz?
Bu kılavuz, yeni bir kahve dükkanı için en uygun konumu belirlemek üzere çok katmanlı bir analiz sürecinde size yol gösterir. Öncelikle eyalet genelinde bir görünümle başlayıp aramayı kademeli olarak belirli bir ilçeye ve ticari bölgeye daraltacağız. Son olarak, rakipleri haritalandırarak tek tek alanları puanlamak ve pazar boşluklarını belirlemek için hiper yerel bir analiz yapacağız.
Çözüm iş akışı
Bu süreç, geniş bir alanla başlayıp arama alanını daraltmak ve nihai site seçiminde güveni artırmak için giderek daha ayrıntılı hale gelen mantıksal bir dönüşüm hunisini takip eder.
Ön koşullar ve ortam kurulumu
Analize başlamadan önce, birkaç temel özelliğe sahip bir ortamınızın olması gerekir. Bu kılavuzda SQL ve Python kullanılarak yapılan bir uygulama açıklanacak olsa da genel ilkeler diğer teknoloji yığınlarına da uygulanabilir.
Ön koşul olarak, ortamınızın şunları yapabildiğinden emin olun:
- BigQuery'de sorgu yürütme
- Places Insights'a erişme. Daha fazla bilgi için Places Insights'ı ayarlama bölümüne bakın.
bigquery-public-datave ABD Nüfus Sayım Bürosu İlçe Nüfusu Toplamları'ndan herkese açık veri kümelerine abone olma
Ayrıca, her analiz adımının sonuçlarını yorumlamak için çok önemli olan coğrafi verileri harita üzerinde görselleştirebilmeniz gerekir. Bunu sağlamanın birçok yolu vardır. Doğrudan BigQuery'ye bağlanan Looker Studio gibi BI araçlarını veya Python gibi veri bilimi dillerini kullanabilirsiniz.
Eyalet Düzeyinde Analiz: En İyi Bölgeyi Bulma
İlk adımımız, Nevada'daki en umut verici ilçeyi belirlemek için geniş kapsamlı bir analiz yapmaktır. Umut vadeden bölgeleri, yüksek nüfus ve mevcut restoranların yüksek yoğunluğu şeklinde tanımlayacağız. Bu, güçlü bir yiyecek ve içecek kültürüne işaret eder.
BigQuery sorgumuz, Places Insights veri kümesinde bulunan yerleşik adres bileşenlerinden yararlanarak bu işlemi gerçekleştirir. Sorgu, administrative_area_level_1_name alanını kullanarak verileri önce yalnızca Nevada eyaletindeki yerleri içerecek şekilde filtreleyerek restoranları sayar. Ardından, bu grubu yalnızca türler dizisinin "restaurant" içerdiği yerleri dahil edecek şekilde daha da daraltır. Son olarak, her il için bir sayı oluşturmak üzere bu sonuçları il adına (administrative_area_level_2_name) göre gruplandırır. Bu yaklaşımda, veri kümesinin yerleşik ve önceden dizine eklenmiş adres yapısı kullanılır.
Bu alıntı, ilçe geometrilerini Places Insights ile nasıl birleştirdiğimizi ve belirli bir yer türü için nasıl filtrelediğimizi gösterir, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Restoranların ham sayısı yeterli değildir. Pazar doygunluğu ve fırsatları doğru şekilde anlamak için bu sayıyı nüfus verileriyle dengelememiz gerekir. ABD Nüfus Sayımı Bürosu İlçe Nüfusu Toplamları'ndan alınan nüfus verilerini kullanacağız.
Bu iki çok farklı metriği (bir yer sayısı ile büyük bir nüfus sayısı) karşılaştırmak için min-maks normalleştirme kullanırız. Bu teknik, her iki metriği de ortak bir aralığa (0-1) göre ölçeklendirir. Ardından bunları tek bir normalized_score içinde birleştiririz ve dengeli bir karşılaştırma için her metriğe% 50 ağırlık veririz.
Bu alıntıda, puanın hesaplanmasıyla ilgili temel mantık gösterilmektedir. Bu katman, normalleştirilmiş nüfus ve restoran sayılarını birleştirir:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Tam sorgu çalıştırıldıktan sonra ilçelerin listesi, restoran sayısı, nüfus ve normalleştirilmiş puan döndürülür. normalized_score
DESC ölçütüne göre sıralama yapıldığında, en büyük rakip olarak Clark County'nin daha ayrıntılı incelenmesi gerektiği açıkça görülüyor.
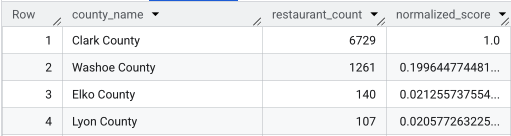
Bu ekran görüntüsünde, normalleştirilmiş puana göre ilk 4 ilçe gösterilmektedir. Bu örnekte, ham nüfus sayısı kasıtlı olarak çıkarılmıştır.
İlçe Düzeyinde Analiz: En Yoğun Ticari Bölgeleri Bulma
Clark County'yi belirlediğimize göre, bir sonraki adım ticari faaliyetin en yüksek olduğu posta kodlarını bulmak için yakınlaştırmaktır. Mevcut kahve dükkanlarımızdan elde ettiğimiz verilere göre, büyük markaların yoğun olduğu yerlerde performansın daha iyi olduğunu biliyoruz. Bu nedenle, bu bilgiyi yüksek yaya trafiği için bir vekil olarak kullanacağız.
Bu sorgu, belirli markalarla ilgili bilgileri içeren Places Insights'taki brands tablosunu kullanır. Desteklenen markaların listesini öğrenmek için bu tabloya sorgu gönderilebilir. Öncelikle hedef markalarımızın bir listesini tanımlarız. Ardından, bu listeyi ana Places Insights veri kümesiyle birleştirerek Clark County'deki her posta kodunda bu belirli mağazalardan kaç tane olduğunu sayarız.
Bunu yapmanın en etkili yolu iki adımlı bir yaklaşımdır:
- İlk olarak, her posta kodundaki markaları saymak için hızlı ve coğrafi olmayan bir toplama işlemi gerçekleştiririz.
- İkinci olarak, görselleştirme için harita sınırlarını elde etmek üzere bu sonuçları herkese açık bir veri kümesiyle birleştiririz.
postal_code_names alanını kullanarak markaları sayma
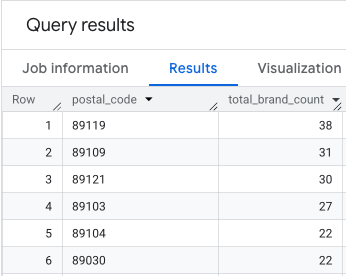
Bu ilk sorgu, temel sayma mantığını uygular. Bu işlev, Clark County'deki yerleri filtreler ve ardından marka sayılarını posta koduna göre gruplandırmak için postal_code_names dizisini ayırır.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
Çıktı, posta kodlarının ve bunlara karşılık gelen marka sayılarının yer aldığı bir tablodur.
Haritalama için Posta Kodu Geometrileri Ekleme
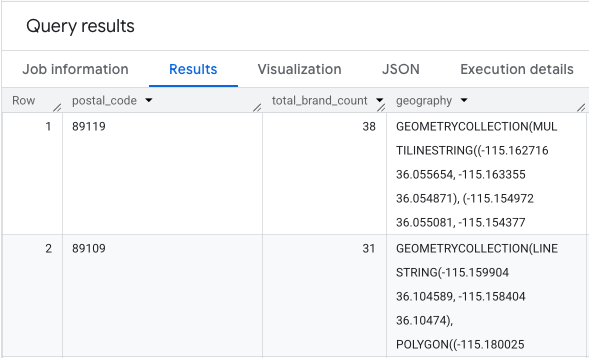
Artık sayıları bildiğimize göre görselleştirme için gereken poligon şekillerini elde edebiliriz. Bu ikinci sorgu, ilk sorgumuzu alır, brand_counts_by_zip adlı bir Ortak Tablo İfadesi (CTE) içine sarar ve sonuçlarını herkese açık geo_us_boundaries.zip_codes table ile birleştirir. Bu sayede, önceden hesaplanmış sayılarımıza geometriyi verimli bir şekilde ekleyebiliriz.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
Çıktı, posta kodlarının, ilgili marka sayılarının ve posta kodu geometrisinin yer aldığı bir tablodur.
Bu verileri ısı haritası olarak görselleştirebiliriz. Daha koyu kırmızı alanlar, hedef markalarımızın daha yoğun olduğu yerleri göstererek bizi Las Vegas'taki ticari açıdan en yoğun bölgelere yönlendiriyor.
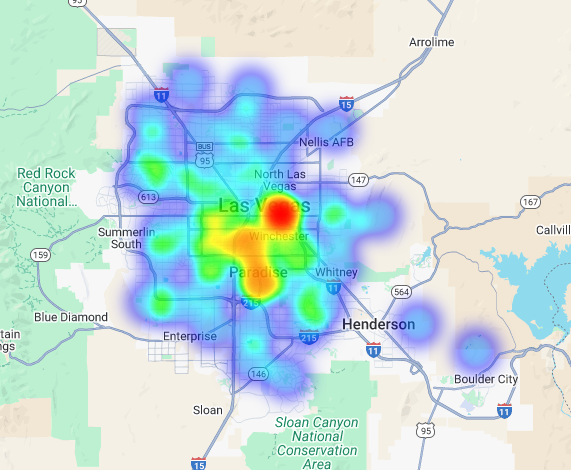
Hiper Yerel Analiz: Ayrı Ayrı Izgara Alanlarını Puanlama
Las Vegas'ın genel alanını belirledikten sonra ayrıntılı bir analiz yapmanın zamanı geldi. Bu noktada, özel işletme bilgilerimizi ekliyoruz. Harika bir kafenin, yoğun saatlerimizde (ör. öğleden önce ve öğle yemeği saatleri) kalabalık olan diğer işletmelerin yakınında başarılı olduğunu biliyoruz.
Bir sonraki sorgumuzda çok daha ayrıntılı bilgiler istiyoruz. Bu işlem, alanı mikro düzeyde analiz etmek için standart H3 coğrafi uzamsal dizini (8. çözünürlükte) kullanarak Las Vegas metropol alanı üzerinde ayrıntılı bir altıgen ızgara oluşturarak başlar. Sorgu, önce en yoğun olduğumuz saatlerde (Pazartesi, 10:00-14:00) açık olan tüm tamamlayıcı işletmeleri tanımlar.
Ardından, her yer türüne ağırlıklı bir puan uygularız. Yakındaki bir restoran, marketten daha değerli olduğundan daha yüksek bir çarpan alır. Bu sayede her küçük alan için özel bir suitability_score elde ederiz.
Bu alıntıda, çalışma saatleri kontrolü için önceden hesaplanmış bir işarete (is_open_monday_window) referans veren ağırlıklı puanlama mantığı vurgulanmaktadır:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Tam sorgu için genişletin
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
Bu puanların harita üzerinde görselleştirilmesi, kazanan konumları net bir şekilde gösterir. En koyu mor renkli kutular (özellikle Las Vegas Strip ve Downtown'ın yakınında) yeni kafemiz için en yüksek potansiyele sahip bölgelerdir.
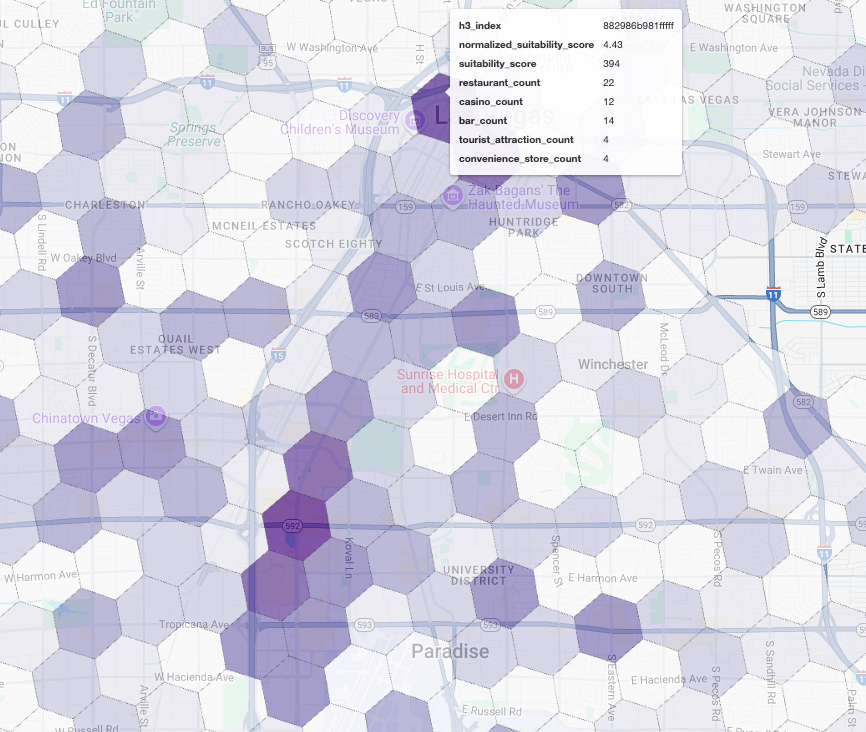
Rakip Analizi: Mevcut Kahve Dükkanlarını Belirleme
Uygunluk modelimiz en umut verici bölgeleri başarıyla belirledi ancak yüksek bir puan tek başına başarıyı garanti etmez. Şimdi bu verileri rakip verileriyle çakıştırmamız gerekiyor. Net bir pazar açığı aradığımız için ideal konum, mevcut kafelerin yoğunluğunun düşük olduğu, yüksek potansiyelli bir bölgedir.
Bunu başarmak için PLACES_COUNT_PER_H3 işlevini kullanırız. Bu işlev, H3 hücresine göre belirli bir coğrafyadaki Yer sayımlarını verimli bir şekilde döndürmek için tasarlanmıştır.
İlk olarak, tüm Las Vegas metropol alanı için coğrafi bölgeyi dinamik olarak tanımlarız.
Tek bir yere güvenmek yerine, Las Vegas ve çevresindeki önemli yerleşim yerlerinin sınırlarını almak için herkese açık Overture Haritalar veri kümesini sorguluyoruz ve bunları ST_UNION_AGG ile tek bir poligon içinde birleştiriyoruz. Ardından, bu alanı işleve aktararak tüm faal kahve dükkanlarını saymasını isteriz.
Bu sorgu, metropol alanını tanımlar ve H3 hücrelerindeki kahve dükkanı sayısını almak için işlevi çağırır:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
İşlev, H3 hücresi dizinini, geometrisini, toplam kahve dükkanı sayısını ve yer kimliklerinin bir örneğini içeren bir tablo döndürür:
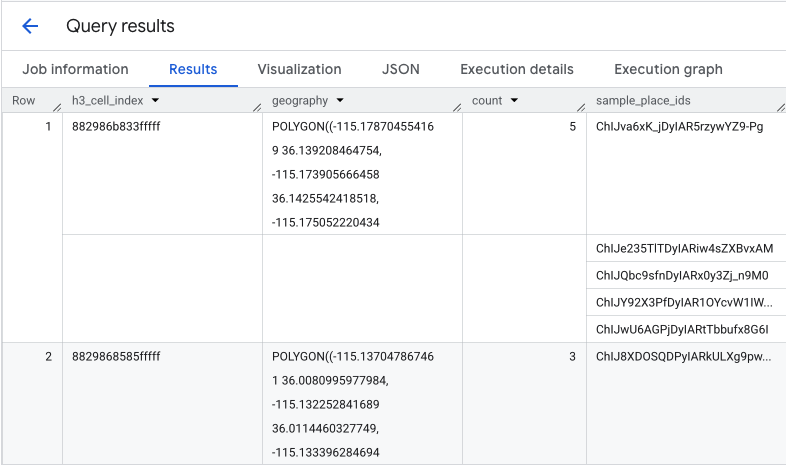
Toplam sayı faydalı olsa da gerçek rakipleri görmek önemlidir.
Bu aşamada, Places Insights veri kümesinden Places API'ye geçiş yapıyoruz. En yüksek normalleştirilmiş uygunluk puanına sahip hücrelerden sample_place_ids çıkararak her rakip için ad, adres, puan ve konum gibi zengin ayrıntıları almak üzere Yer Ayrıntıları API'sini çağırabiliriz.
Bunun için uygunluk puanının oluşturulduğu önceki sorgunun sonuçları ile PLACES_COUNT_PER_H3 sorgusunun sonuçlarının karşılaştırılması gerekir. H3 hücre dizini, en yüksek normalleştirilmiş uygunluk puanına sahip hücrelerdeki kahve dükkanı sayılarını ve kimliklerini almak için kullanılabilir.
Bu Python kodu, karşılaştırmanın nasıl yapılabileceğini gösterir.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Artık en yüksek uygunluk puanına sahip H3 hücrelerinde bulunan kahve dükkanlarının yer kimliklerinin listesi elimizde. Her yerle ilgili daha fazla ayrıntı istenebilir.
Bu işlem, her bir yer kimliği için doğrudan Yer Ayrıntıları API'sine istek göndererek veya aramayı gerçekleştirmek için istemci kitaplığı kullanılarak yapılabilir. Yalnızca ihtiyacınız olan verileri istemek için FieldMask parametresini ayarlamayı unutmayın.
Son olarak, her şeyi tek bir güçlü görselleştirmede birleştiririz. Mor uygunluk renk tonlu haritamızı temel katman olarak çizip Places API'sinden alınan her bir kahve dükkanı için raptiyeler ekliyoruz. Bu son harita, tüm analizimizi özetleyen bir bakışta görünüm sunar: Koyu mor alanlar potansiyeli, yeşil işaretler ise mevcut pazarın gerçekliğini gösterir.
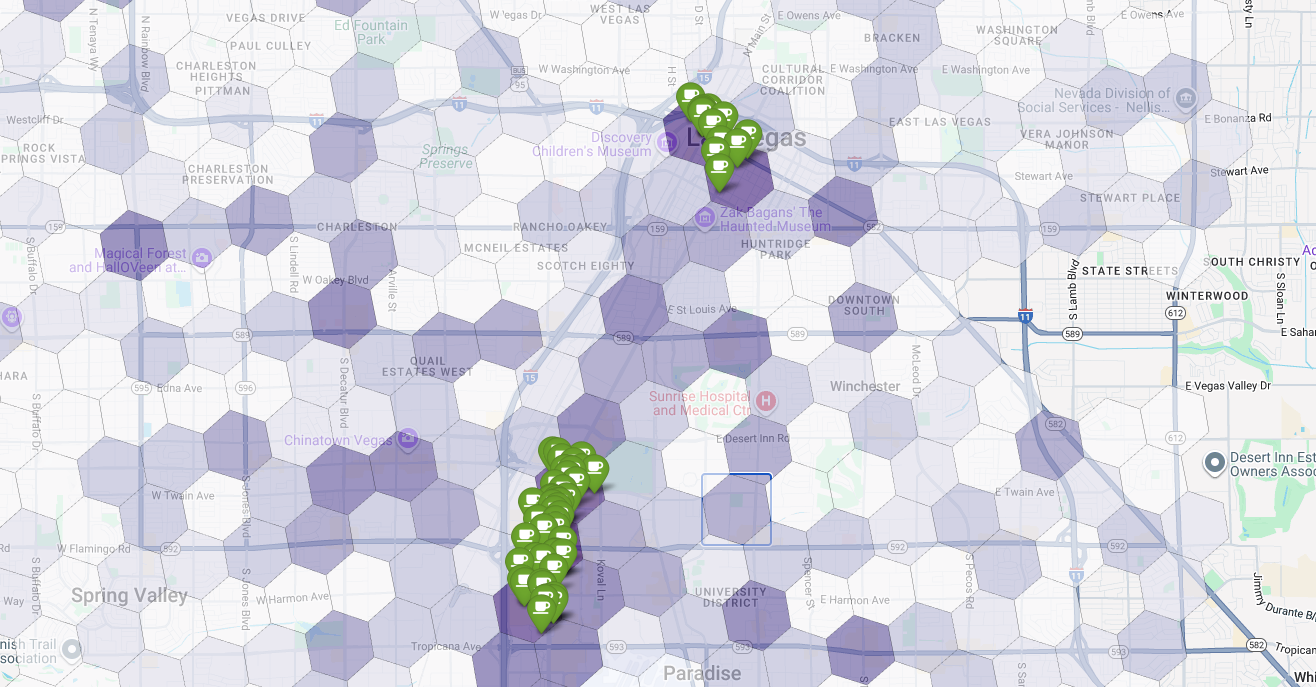
Az sayıda raptiye içeren veya hiç raptiye içermeyen koyu mor hücreleri arayarak yeni konumumuz için en iyi fırsatı sunan alanları kesin olarak belirleyebiliriz.
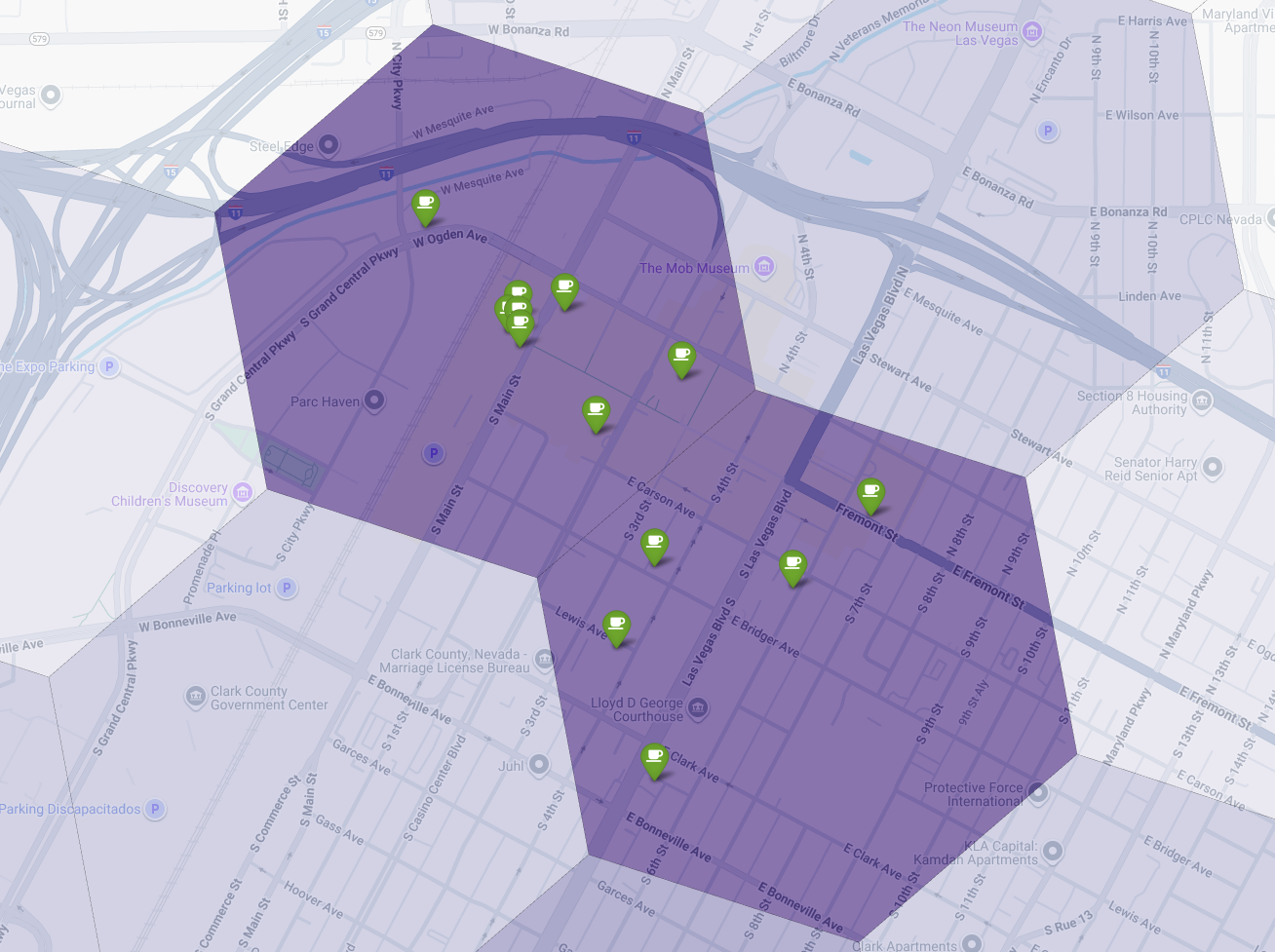
Yukarıdaki iki hücrenin uygunluk puanı yüksek ancak yeni kahve dükkanımız için potansiyel konumlar olabilecek bazı belirgin boşluklar var.
Sonuç
Bu belgede, nerede genişlemeli? sorusuna eyalet genelinde verilen yanıttan, verilerle desteklenen yerel bir yanıta geçtik. Farklı veri kümelerini katmanlayarak ve özel iş mantığı uygulayarak büyük bir iş kararıyla ilişkili riski sistematik olarak azaltabilirsiniz. BigQuery'nin ölçeğini, Places Insights'ın zenginliğini ve Places API'nin gerçek zamanlı ayrıntılarını bir araya getiren bu iş akışı, stratejik büyüme için konum bazlı bilgiden yararlanmak isteyen tüm kuruluşlara yönelik güçlü bir şablon sunar.
Sonraki adımlar
- Bu iş akışını kendi iş mantığınıza, hedef coğrafi bölgelerinize ve tescilli veri kümelerinize göre uyarlayın.
- Modelinizi daha da zenginleştirmek için Places Insights veri kümesindeki diğer veri alanlarını (ör. yorum sayıları, fiyat düzeyleri ve kullanıcı puanları) inceleyin.
- Yeni pazarları dinamik olarak değerlendirmek için kullanılabilecek bir dahili site seçimi kontrol paneli oluşturmak üzere bu süreci otomatikleştirin.
Belgeleri daha ayrıntılı inceleyin:
Katkıda bulunanlar
Henrik Valve | DevX Engineer