
مقدمه
این سند نحوهی ساخت یک راهکار انتخاب سایت را با ترکیب مجموعه دادههای Places Insights ، دادههای مکانی عمومی در BigQuery و API جزئیات مکان شرح میدهد.
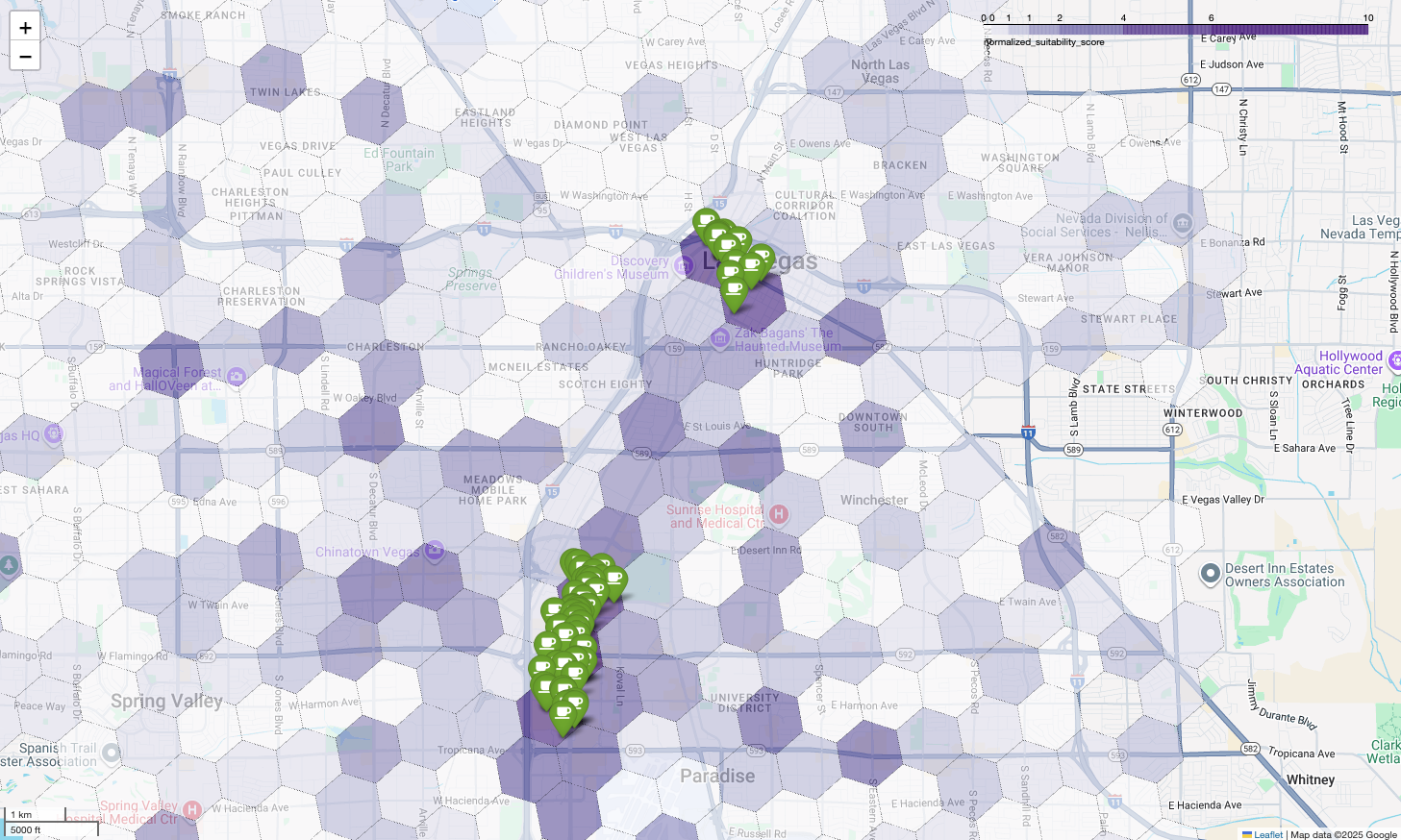
نقشه بالا خروجی یک دموی ارائه شده در Google Cloud Next 2025 را نشان میدهد که برای تماشا در یوتیوب موجود است. میتوانید کدی را که برای تولید این نتایج استفاده شده است، با استفاده از دفترچه نمونه اجرا کنید.
 مشاهده منبع در گیتهاب
مشاهده منبع در گیتهابچالش کسب و کار
تصور کنید که صاحب یک کافیشاپ زنجیرهای موفق هستید و میخواهید آن را به ایالت جدیدی مانند نوادا، که در آن حضوری ندارید، گسترش دهید. افتتاح یک شعبه جدید یک سرمایهگذاری قابل توجه است و تصمیمگیری مبتنی بر داده برای موفقیت بسیار مهم است. اصلاً از کجا شروع میکنید؟
این راهنما شما را با یک تحلیل چندلایه برای تعیین مکان بهینه برای یک کافیشاپ جدید آشنا میکند. ما با یک دیدگاه در سطح ایالت شروع میکنیم، جستجوی خود را به تدریج به یک شهرستان و منطقه تجاری خاص محدود میکنیم و در نهایت یک تحلیل فرامحلی انجام میدهیم تا مناطق مختلف را امتیازدهی کنیم و با ترسیم رقبا، شکافهای بازار را شناسایی کنیم.
گردش کار راهکار
این فرآیند از یک قیف منطقی پیروی میکند، که از یک بخش گسترده شروع میشود و به تدریج جزئیات بیشتری پیدا میکند تا حوزه جستجو را اصلاح کند و اطمینان در انتخاب نهایی سایت را افزایش دهد.
پیشنیازها و تنظیمات محیطی
قبل از شروع تحلیل، به محیطی با چند قابلیت کلیدی نیاز دارید. اگرچه این راهنما پیادهسازی را با استفاده از SQL و پایتون بررسی میکند، اما اصول کلی را میتوان در مورد سایر فناوریها نیز به کار برد.
به عنوان یک پیش نیاز، اطمینان حاصل کنید که محیط شما میتواند:
- اجرای کوئریها در BigQuery
- به Places Insights دسترسی پیدا کنید، برای اطلاعات بیشتر به Setup Places Insights مراجعه کنید
- مشترک مجموعه دادههای عمومی
bigquery-public-dataو مجموع جمعیت شهرستانهای اداره سرشماری ایالات متحده شوید
همچنین باید بتوانید دادههای مکانی را روی نقشه تجسم کنید ، که برای تفسیر نتایج هر مرحله تحلیلی بسیار مهم است. روشهای زیادی برای دستیابی به این هدف وجود دارد. میتوانید از ابزارهای هوش تجاری مانند Looker Studio که مستقیماً به BigQuery متصل میشوند استفاده کنید، یا میتوانید از زبانهای علم داده مانند پایتون استفاده کنید.
تحلیل در سطح ایالت: بهترین شهرستان را پیدا کنید
اولین قدم ما، یک تحلیل گسترده برای شناسایی شهرستانهای مستعد در نوادا است. ما شهرستانهای مستعد را ترکیبی از جمعیت بالا و تراکم بالای رستورانهای موجود تعریف میکنیم که نشاندهنده فرهنگ قوی غذا و نوشیدنی است.
کوئری BigQuery ما این کار را با بهرهگیری از اجزای آدرس داخلی موجود در مجموعه داده Places Insights انجام میدهد. این کوئری ابتدا با فیلتر کردن دادهها برای شامل کردن فقط مکانهای داخل ایالت نوادا، با استفاده از فیلد administrative_area_level_1_name ، رستورانها را شمارش میکند. سپس این مجموعه را بیشتر اصلاح میکند تا فقط مکانهایی را که آرایه types شامل ' restaurant ' است، شامل شود. در نهایت، این نتایج را بر اساس نام شهرستان ( administrative_area_level_2_name ) گروهبندی میکند تا برای هر شهرستان یک شمارش ایجاد کند. این رویکرد از ساختار آدرس داخلی و از پیش اندیسگذاری شده مجموعه داده استفاده میکند.
این گزیده نشان میدهد که چگونه ما هندسههای شهرستانی را با Places Insights به هم متصل میکنیم و برای یک نوع مکان خاص، restaurant ، فیلتر میکنیم:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
تعداد خام رستورانها کافی نیست؛ ما باید آن را با دادههای جمعیتی متعادل کنیم تا به درک واقعی از اشباع بازار و فرصتها دست یابیم. ما از دادههای جمعیتی از کل جمعیت شهرستانهای اداره سرشماری ایالات متحده استفاده خواهیم کرد.
برای مقایسه این دو معیار بسیار متفاوت (تعداد مکان در مقابل تعداد زیادی جمعیت)، از نرمالسازی حداقل-حداکثر استفاده میکنیم. این تکنیک هر دو معیار را در یک محدوده مشترک (0 تا 1) مقیاسبندی میکند. سپس آنها را در یک normalized_score واحد ترکیب میکنیم و به هر معیار وزن 50٪ میدهیم تا مقایسهای متعادل داشته باشیم.
این گزیده منطق اصلی محاسبه امتیاز را نشان میدهد. این بخش، جمعیت نرمالشده و تعداد رستورانها را با هم ترکیب میکند:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
پس از اجرای کامل کوئری، فهرستی از شهرستانها، تعداد رستورانها، جمعیت و امتیاز نرمالشده بازگردانده میشود. مرتبسازی بر اساس normalized_score DESC شهرستان کلارک را به عنوان برنده قطعی برای بررسی بیشتر به عنوان مدعی برتر نشان میدهد.
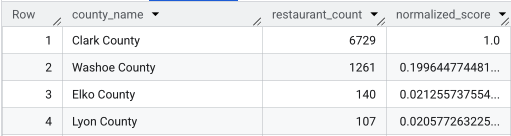
این تصویر، ۴ شهرستان برتر را بر اساس امتیاز نرمالشده نشان میدهد. تعداد خام جمعیت عمداً از این مثال حذف شده است.
تحلیل در سطح شهرستان: شلوغترین مناطق تجاری را پیدا کنید
حالا که شهرستان کلارک را شناسایی کردهایم، قدم بعدی این است که کد پستیهایی را که بیشترین فعالیت تجاری را دارند، بزرگنمایی کنیم. بر اساس دادههای کافیشاپهای موجودمان، میدانیم که وقتی در نزدیکی تراکم بالایی از برندهای اصلی قرار دارند، عملکرد بهتری دارند، بنابراین از این به عنوان معیاری برای ترافیک بالای مشتریان استفاده خواهیم کرد.
این پرسوجو از جدول brands در Places Insights استفاده میکند که حاوی اطلاعاتی در مورد برندهای خاص است. میتوان از این جدول برای کشف لیست برندهای پشتیبانیشده استفاده کرد . ابتدا لیستی از برندهای هدف خود را تعریف میکنیم و سپس آن را با مجموعه دادههای اصلی Places Insights ترکیب میکنیم تا تعداد این فروشگاههای خاص را که در هر کد پستی در شهرستان کلارک قرار دارند، بشماریم.
کارآمدترین راه برای دستیابی به این هدف، رویکردی دو مرحلهای است:
- ابتدا، یک تجمیع سریع و غیرمرتبط با مکان انجام میدهیم تا برندهای موجود در هر کد پستی را بشماریم.
- دوم، ما آن نتایج را به یک مجموعه داده عمومی متصل میکنیم تا مرزهای نقشه را برای تجسم به دست آوریم.
شمارش برندها با استفاده از فیلد postal_code_names
این کوئری اول منطق شمارش اصلی را انجام میدهد. مکانهای موجود در شهرستان کلارک را فیلتر میکند و سپس آرایه postal_code_names را از حالت تودرتو خارج میکند تا تعداد برندها را بر اساس کد پستی گروهبندی کند.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
خروجی، جدولی از کدهای پستی و تعداد برندهای مربوط به آنها است.

هندسههای کد پستی را برای نقشهبرداری ضمیمه کنید
حالا که شمارشها را داریم، میتوانیم اشکال چندضلعی مورد نیاز برای تجسم را بدست آوریم. این پرسوجوی دوم، پرسوجوی اول ما را میگیرد، آن را در یک عبارت جدول مشترک (CTE) به نام brand_counts_by_zip قرار میدهد و نتایج آن را به geo_us_boundaries.zip_codes table متصل میکند. این کار هندسه را به طور موثر به شمارشهای از پیش محاسبه شده ما متصل میکند.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
خروجی، جدولی از کدهای پستی، تعداد برندهای مربوط به آنها و هندسه کد پستی است.
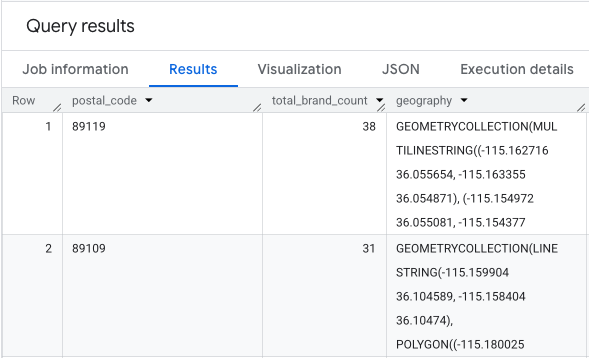
میتوانیم این دادهها را به صورت یک نقشه حرارتی تجسم کنیم . مناطق قرمز تیرهتر نشاندهنده تمرکز بیشتر برندهای هدف ما هستند و ما را به سمت مناطق پرتراکم تجاری در لاس وگاس هدایت میکنند.
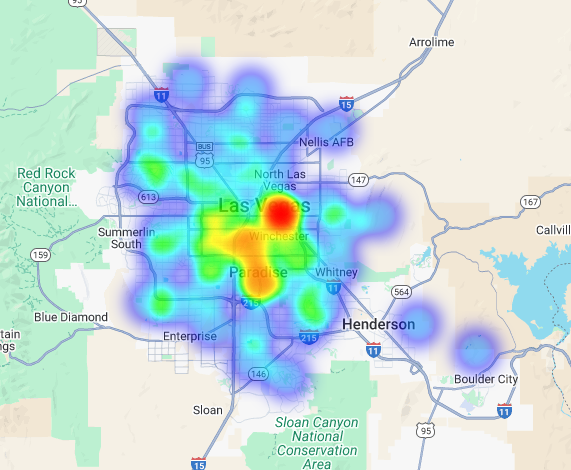
تحلیل فرامحلی: امتیازدهی به نواحی شبکهای مجزا
پس از شناسایی منطقه عمومی لاس وگاس، زمان تجزیه و تحلیل جزئی فرا رسیده است. اینجاست که ما دانش خاص تجاری خود را لایه بندی میکنیم. ما میدانیم که یک کافیشاپ عالی در نزدیکی مشاغل دیگری که در ساعات اوج ما، مانند اواخر صبح و ناهار، شلوغ هستند، رونق دارد.
پرسش بعدی ما واقعاً خاص میشود. این پرسش با ایجاد یک شبکه شش ضلعی ریزدانه بر روی منطقه شهری لاس وگاس با استفاده از شاخص جغرافیایی استاندارد H3 (با وضوح 8) برای تجزیه و تحلیل منطقه در سطح خرد آغاز میشود. این پرسش ابتدا تمام مشاغل مکملی را که در طول دوره اوج فعالیت ما (دوشنبه، 10 صبح تا 2 بعد از ظهر) باز هستند، شناسایی میکند.
سپس برای هر نوع مکان، یک امتیاز وزنی اعمال میکنیم. یک رستوران نزدیک برای ما ارزشمندتر از یک فروشگاه رفاه است، بنابراین ضریب بالاتری میگیرد. این به ما یک suitability_score سفارشی برای هر منطقه کوچک میدهد.
این گزیده، منطق امتیازدهی وزنی را برجسته میکند که به یک پرچم از پیش محاسبهشده ( is_open_monday_window ) برای بررسی ساعات کاری اشاره دارد:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
برای جستجوی کامل، گسترش دهید
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
تجسم این امتیازات روی نقشه، مکانهای برنده را به وضوح نشان میدهد. تیرهترین کاشیهای بنفش، عمدتاً نزدیک نوار لاس وگاس و مرکز شهر، مناطقی با بالاترین پتانسیل برای کافیشاپ جدید ما هستند.
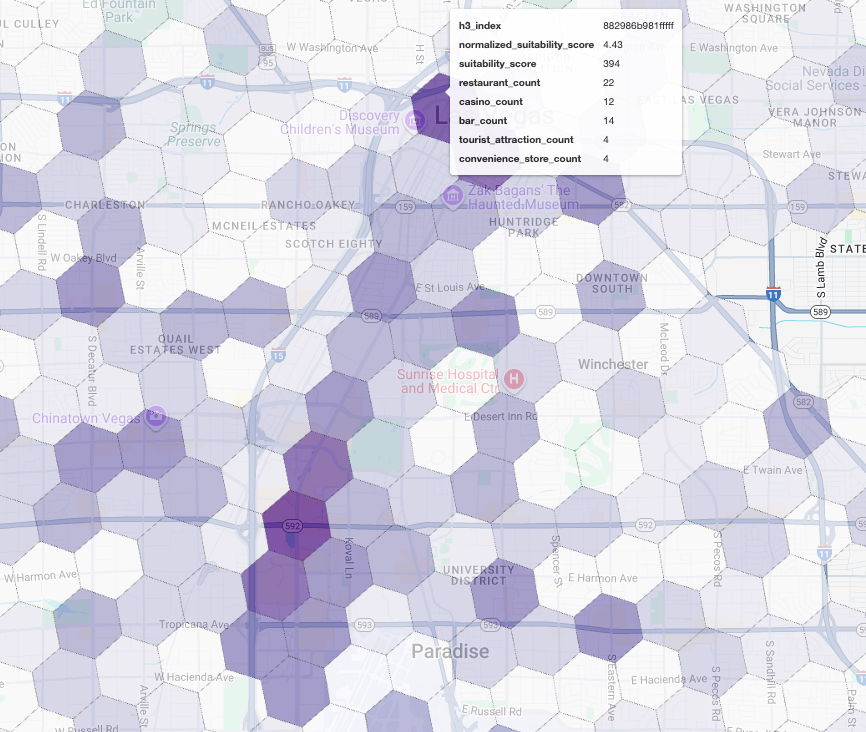
تحلیل رقبا: کافیشاپهای موجود را شناسایی کنید
مدل شایستگی ما با موفقیت مناطق امیدوارکننده را شناسایی کرده است، اما امتیاز بالا به تنهایی موفقیت را تضمین نمیکند. اکنون باید این را با دادههای رقبا پوشش دهیم. مکان ایدهآل، منطقهای با پتانسیل بالا و تراکم کم کافیشاپهای موجود است، زیرا ما به دنبال یک شکاف واضح در بازار هستیم.
برای رسیدن به این هدف، از تابع PLACES_COUNT_PER_H3 استفاده میکنیم. این تابع برای بازگرداندن کارآمد تعداد مکانها در یک جغرافیای مشخص، بر اساس سلول H3 طراحی شده است.
ابتدا، ما به صورت پویا جغرافیای کل منطقه شهری لاس وگاس را تعریف میکنیم. به جای تکیه بر یک مکان واحد، از مجموعه دادههای عمومی Overture Maps برای دریافت مرزهای لاس وگاس و مکانهای کلیدی اطراف آن پرس و جو میکنیم و آنها را با ST_UNION_AGG در یک چندضلعی واحد ادغام میکنیم. سپس این منطقه را به تابع ارسال میکنیم و از آن میخواهیم که تمام کافیشاپهای فعال را بشمارد.
این کوئری منطقه شهری را تعریف میکند و تابع را برای دریافت تعداد کافیشاپها در سلولهای H3 فراخوانی میکند:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
این تابع جدولی را برمیگرداند که شامل اندیس سلول H3، هندسه آن، تعداد کل کافیشاپها و نمونهای از شناسههای مکان آنها است:
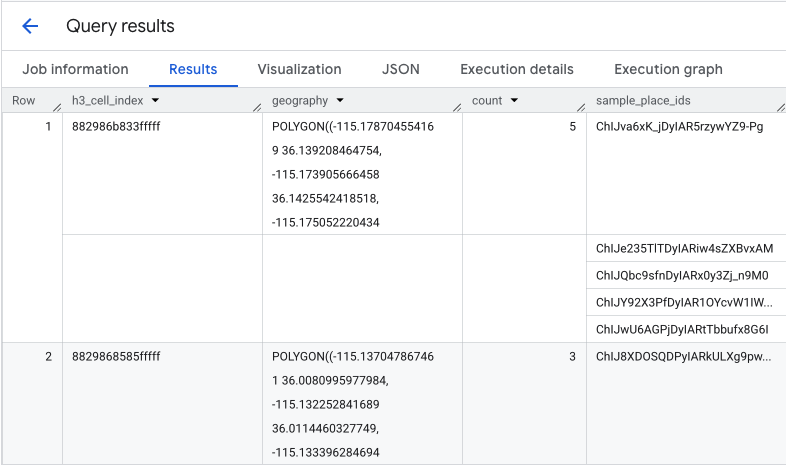
اگرچه شمارش کلی مفید است، اما دیدن رقبای واقعی ضروری است. اینجاست که ما از مجموعه دادههای Places Insights به Places API منتقل میشویم. با استخراج sample_place_ids از سلولهایی با بالاترین امتیاز تناسب نرمالشده، میتوانیم Place Details API را برای بازیابی جزئیات غنی برای هر رقیب، مانند نام، آدرس، رتبهبندی و موقعیت مکانی آنها، فراخوانی کنیم.
این امر مستلزم مقایسه نتایج پرسوجوی قبلی، که در آن امتیاز مناسب بودن ایجاد شده است، و پرسوجوی PLACES_COUNT_PER_H3 است. از شاخص سلول H3 میتوان برای دریافت تعداد و شناسههای کافیشاپ از سلولهایی با بالاترین امتیاز مناسب بودن نرمالشده استفاده کرد.
این کد پایتون نحوه انجام این مقایسه را نشان میدهد.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
اکنون فهرست شناسههای مکان برای کافیشاپهایی که از قبل در سلولهای H3 با بالاترین امتیاز مناسب بودن وجود دارند را داریم، میتوان جزئیات بیشتری در مورد هر مکان درخواست کرد.
این کار را میتوان با ارسال مستقیم درخواست به API جزئیات مکان برای هر شناسه مکان یا با استفاده از یک کتابخانه کلاینت برای انجام فراخوانی انجام داد. به یاد داشته باشید که پارامتر FieldMask را طوری تنظیم کنید که فقط دادههای مورد نیاز شما را درخواست کند.
در نهایت، همه چیز را در یک تجسم واحد و قدرتمند ترکیب میکنیم. نقشه کروپلت بنفش مناسب بودن خود را به عنوان لایه پایه ترسیم میکنیم و سپس پینهایی را برای هر کافیشاپ جداگانه که از Places API بازیابی شده است، اضافه میکنیم. این نقشه نهایی، یک نمای کلی ارائه میدهد که کل تحلیل ما را ترکیب میکند: مناطق بنفش تیره پتانسیل را نشان میدهند و پینهای سبز واقعیت بازار فعلی را نشان میدهند.
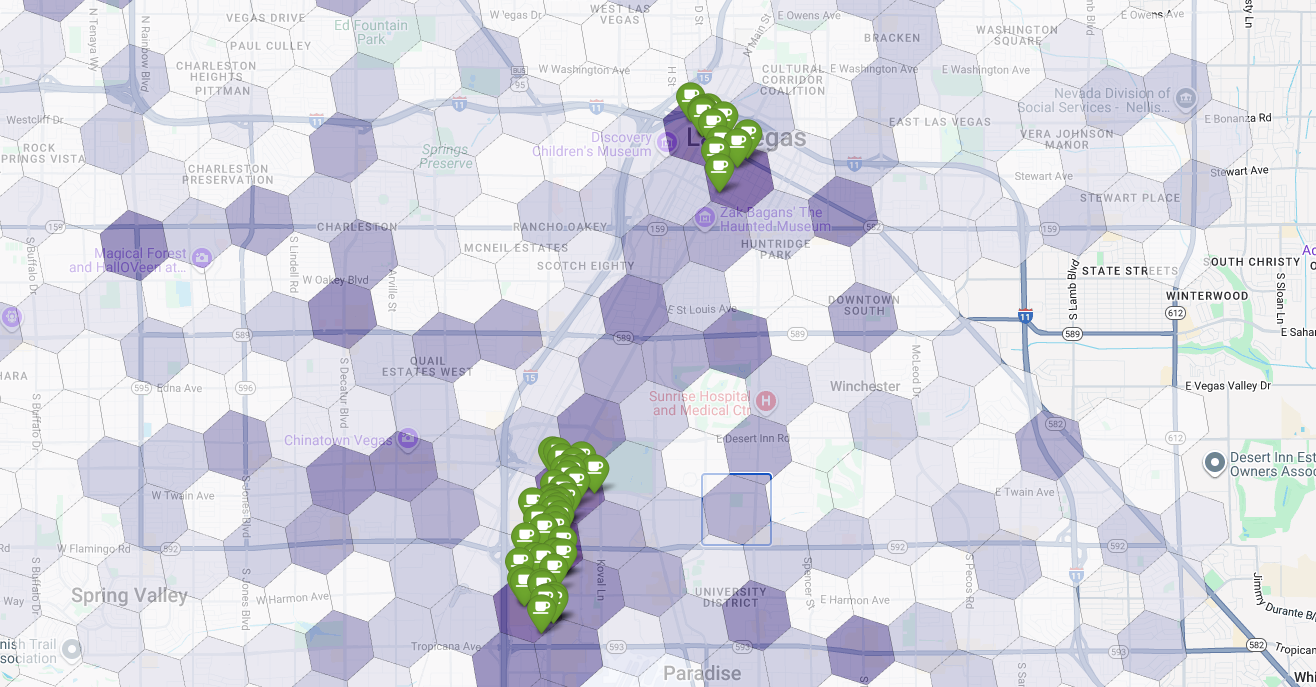
با جستجوی سلولهای بنفش تیره با تعداد کم یا بدون پین، میتوانیم با اطمینان مناطق دقیقی را که بهترین فرصت را برای مکان جدید ما نشان میدهند، مشخص کنیم.
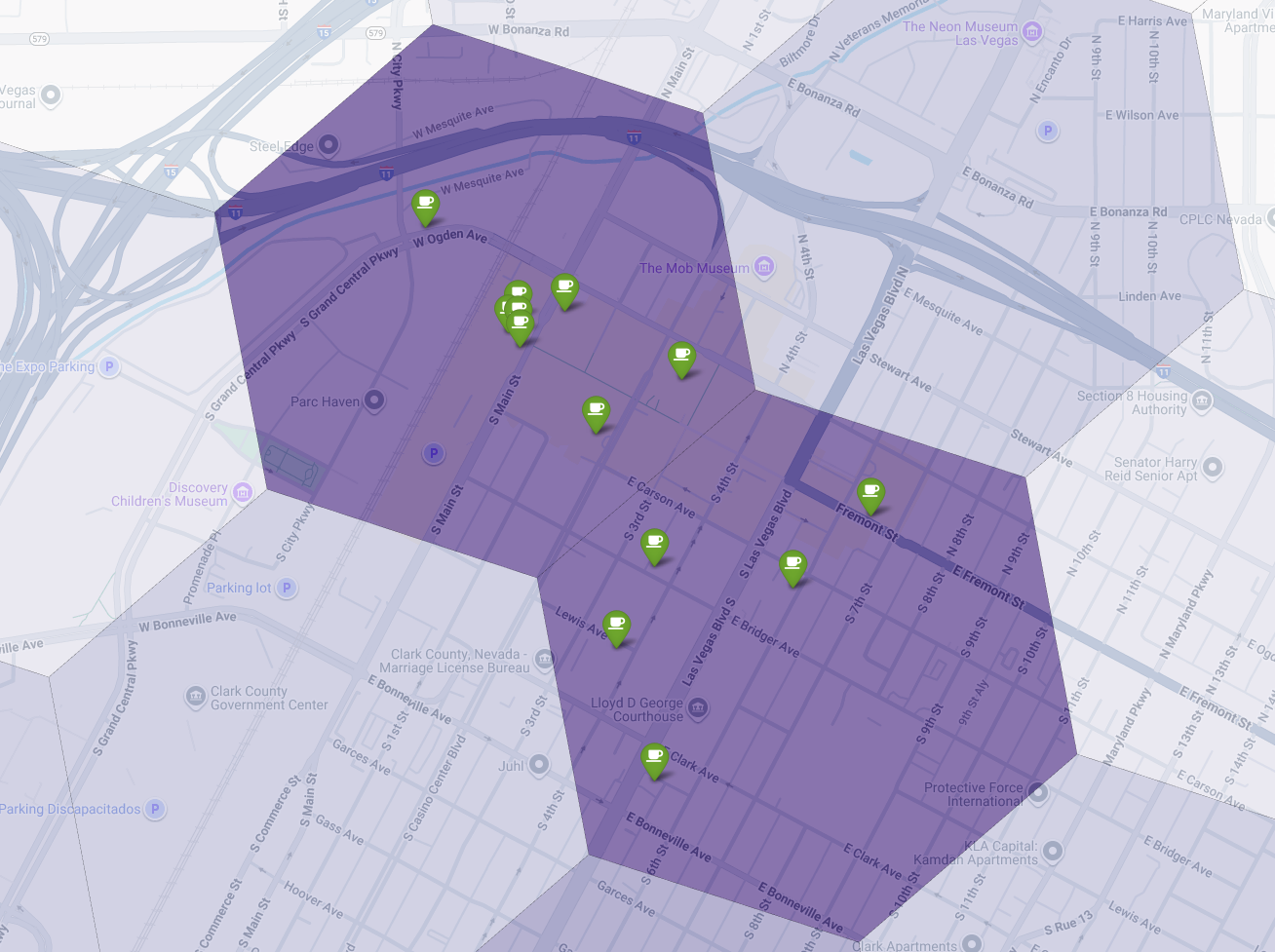
دو سلول بالا امتیاز مناسب بودن بالایی دارند، اما جای خالیهای مشخصی دارند که میتوانند مکانهای بالقوهای برای کافیشاپ جدید ما باشند.
نتیجهگیری
در این سند، ما از یک سوال سراسری در مورد اینکه کجا باید گسترش یابد؟ به یک پاسخ محلی مبتنی بر داده تغییر جهت دادیم. با لایهبندی مجموعه دادههای مختلف و اعمال منطق تجاری سفارشی، میتوانید به طور سیستماتیک ریسک مرتبط با یک تصمیم تجاری بزرگ را کاهش دهید. این گردش کار، با ترکیب مقیاس BigQuery، غنای Places Insights و جزئیات بلادرنگ Places API، الگویی قدرتمند برای هر سازمانی که به دنبال استفاده از هوش مکانی برای رشد استراتژیک است، ارائه میدهد.
مراحل بعدی
- این گردش کار را با منطق کسبوکار، جغرافیای هدف و مجموعه دادههای اختصاصی خود تطبیق دهید.
- برای غنیتر کردن مدل خود، سایر فیلدهای داده در مجموعه دادههای Places Insights، مانند تعداد نظرات، سطح قیمت و رتبهبندی کاربران را بررسی کنید.
- این فرآیند را خودکار کنید تا یک داشبورد انتخاب سایت داخلی ایجاد شود که بتوان از آن برای ارزیابی پویای بازارهای جدید استفاده کرد.
عمیقتر به مستندات نگاه کنید:
مشارکتکنندگان
هنریک والو | مهندس DevX