
기존의 B2B 리드 생성은 정적 디렉터리나 업계 목록을 구매하여 지역 잠재력을 정의하는 데 의존하는 경우가 많습니다. 하지만 이러한 정적 관심 장소 (POI) 데이터 세트는 거의 즉시 오래됩니다. 현장 영업팀은 최신 운영 상태 또는 세부적인 장소 유형 분류가 부족한 경우가 많기 때문에 폐업했거나, 잘못 분류되었거나, 이상적인 고객 프로필과 관련이 없는 비즈니스를 쫓느라 소중한 시간을 낭비할 위험이 있습니다.
이 가이드에서는 장소 통계 및 장소 API를 사용하여 이러한 격차를 해소하는 워크플로를 제공합니다. 현재 비즈니스 장부를 장소 ID에 매핑하면 BigQuery를 사용하여 고객 관계 관리 (CRM) 데이터베이스에 아직 없는 지역의 모든 운영 비즈니스를 격리할 수 있습니다. 이 가이드에서는 제외 엔진을 구축하여 현장 담당자에게 타겟팅이 매우 세밀하고 검증된 리드 목록을 제공하는 방법을 보여줍니다.
예제 애플리케이션
뉴욕시에서 오프라인 판매 확장을 계획하는 판매 시점 (POS) 제공업체를 생각해 보세요. 일반적으로 조직은 우편번호별 총 음식 및 음료 시설에 관한 보고서를 가져옵니다. 이 접근 방식은 영업 담당자가 영구적으로 폐쇄된 위치나 매장이 없는 개인 케이터링 주방과 같은 관련 없는 리드와 같은 오래된 데이터에 의존할 위험이 있습니다.
대신 Google 지도의 전 세계 규모와 여러 소스에서 검증된 최신 데이터를 활용하는 Places Insights를 사용하는 현대화된 접근 방식을 생각해 보세요.
Places Insights는 약 500개의 장소 카테고리와 70개가 넘는 속성을 지원하므로 특정 비즈니스 유형 (예: scandinavian_restaurant), 영업시간, 서비스 제공 (예: accepts_credit_cards)에 따라 잠재고객을 정밀하게 분류할 수 있습니다. Places Insights를 내부 CRM과 상호 참조하면 영업팀에 아직 연락하지 않은 잠재력이 높은 잠재고객의 타겟팅된 목록을 제공할 수 있습니다.
솔루션 워크플로
이 가이드에서는 현재 비즈니스 목록을 자동으로 필터링하여 영업팀이 추적할 수 있는 순 신규 운영 리드만 남기는 동적 '리드 지도'를 만드는 기술 프레임워크를 제공합니다.
4단계 아키텍처
- 타겟 장소 유형 정의: 이상적인 고객 프로필을 장소 유형에 매핑합니다.
- 잠재력이 높은 지역 식별: BigQuery에서 장소 수 함수를 실행하여 운영 타겟 비즈니스의 밀도 히트맵을 생성합니다.
- CRM 데이터를 장소 ID로 정규화: 주소 유효성 검사, 지오코딩, Places API를 활용하여 데이터 정리 파이프라인을 통해 비구조적 CRM 레코드를 처리하여 기존 고객의 장소 ID를 찾습니다.
- 공백 제외 실행: BigQuery에서 CRM 장소 ID를 장소 통계 데이터와 결합하여 기존 고객을 동적으로 필터링하고 신규 리드 목록을 출력합니다.
기본 요건
시작하기 전에 다음 사항을 확인하세요.
Google Cloud 프로젝트:
- 결제가 사용 설정된 Google Cloud 프로젝트.
데이터 액세스:
- BigQuery의 Places Insights 구독
- 제외 목록으로 사용할 기존 고객 비즈니스 이름과 주소가 포함된 자체 CRM 데이터 세트 (예: BigQuery 테이블)
Google Maps Platform:
- API 키
- 키에 사용 설정된 API는 다음과 같습니다.
IAM 권한:
- 쿼리를 실행하고 데이터 세트를 관리하려면 사용자 또는 서비스 계정에 다음 IAM 역할이 있어야 합니다.
역할 ID BigQuery 데이터 편집자 roles/bigquery.dataEditorBigQuery 사용자 roles/bigquery.user
- 쿼리를 실행하고 데이터 세트를 관리하려면 사용자 또는 서비스 계정에 다음 IAM 역할이 있어야 합니다.
비용 인식:
- 이 튜토리얼에서는 비용이 청구될 수 있는 Google Cloud 구성요소를 사용합니다. 다음과 관련된 잠재적 비용을 고려하세요.
- BigQuery: 쿼리 실행 중에 사용된 컴퓨팅 슬롯 또는 처리된 데이터에 대해 요금이 청구됩니다.
- Places 통계: 쿼리 사용량에 따라 요금이 청구됩니다.
- Google Maps Platform: Address Validation API, Geocoding API, Text Search API의 요청당 요금이 청구됩니다.
- 이 튜토리얼에서는 비용이 청구될 수 있는 Google Cloud 구성요소를 사용합니다. 다음과 관련된 잠재적 비용을 고려하세요.
1단계: 타겟 장소 유형 정의
Places Insights는 약 500개의 장소 카테고리와 70개 이상의 속성(예: 영업시간, 결제 유형, 운영 상태)을 지원합니다. 전체 데이터 세트를 무차별적으로 쿼리하는 것은 비효율적이고 비용이 많이 듭니다.
기본 단계로 Gemini와 같은 LLM을 사용하여 내부 고객 프로필을 Places Insights용 쿼리를 빌드할 때 사용되는 장소 유형으로 변환합니다. 이 매크로 수준 분류 정의를 사용하면 후속 BigQuery 검색의 타겟팅이 매우 정확해져 컴퓨팅 처리 오버헤드가 줄어듭니다.
예를 들어 판매 시점 시스템의 워크플로를 설계하는 경우 Gemini에 장소 유형 목록을 제공하고 다음 프롬프트를 사용할 수 있습니다.
"시장 분석가로서 지원되는 Google 지도 장소 유형 중 판매 시점 시스템 제공업체의 기본 타겟은 무엇인가요? 결정을 정당화해 줘."
이 프롬프트에 따라 Gemini는 분류를 분석하고 BigQuery types 필터에 사용할 관련 장소 유형의 타겟팅된 하위 집합을 반환합니다.
| 기본 카테고리 | 근거 | 주요 장소 유형 |
|---|---|---|
| 식음료 | 빠른 거래 처리, 테이블 관리, 주문 티켓팅, 팁 처리가 필요합니다. | restaurant, bar, cafe, coffee_shop |
| 쇼핑 | 강력한 인벤토리 추적, 바코드 스캔, 반품 처리, 포인트 통합이 필요합니다. | clothing_store, grocery_store, supermarket, convenience_store |
| 서비스 및 건강과 웰빙 | 통합된 약속 예약, 일정 예약, 고객 프로필, 수수료 추적이 필요합니다. | hair_salon, beauty_salon, spa, massage |
| 엔터테인먼트, 레크리에이션, 스포츠 | 고객의 급한 요청에 대한 신속한 처리, 디지털 티켓 스캔, 빠른 매점 판매가 필요합니다. | movie_theater, amusement_park, bowling_alley, stadium |
이 가이드에서는 음식 및 음료 카테고리의 추천 장소 유형을 중점적으로 다룹니다.
2단계: 비즈니스 수를 추출하여 잠재력이 높은 지역 식별
기회를 포착하려면 먼저 비즈니스 밀도의 거시적 관점이 필요합니다. BigQuery에서 장소 수 함수(예: PLACES_COUNT_PER_H3 또는 PLACES_COUNT_PER_GEO)를 실행하면 이를 달성할 수 있습니다.
데이터 세트를 직접 쿼리할 수 있지만, 장소 수 함수는 최소 5개 장소의 표준 집계 기준을 적용하지 않는 사전 정의되고 최적화된 SQL 쿼리입니다 (표준 직접 쿼리는 비즈니스가 1~4개인 행을 생략하지만, 이러한 함수를 사용하면 단일 잠재고객이 있는 위치를 정확하게 확인할 수 있음). 중요한 점은 이러한 함수가 sample_place_ids 열을 사용하여 지리적 영역당 최대 250개의 장소 ID 배열을 반환한다는 것입니다. 이를 통해 지역 계획 담당자를 위한 통계적 히트맵과 리드 생성에 필요한 기본 식별자를 모두 제공할 수 있습니다.
다음 쿼리는 공개 데이터 세트를 사용하여 복잡한 다각형(뉴욕시 전체 경계)을 동적으로 검색한 다음 해당 지리를 장소 수 함수에 전달하는 방법을 보여줍니다. 도시 전반에서 더 넓은 해상도 (8)로 H3 공간 색인을 활용하면 매크로 수준 밀도 지도를 생성할 수 있습니다.
또한 모든 열 (SELECT *)을 선택하면 함수는 H3 셀을 나타내는 다각형인 geography 열을 반환합니다. 이를 통해 BigQuery 결과를 비즈니스 인텔리전스 도구 (예: Looker Studio)로 즉시 가져와 시장 핫스팟을 시각적으로 보여주는 채워진 지도 시각화를 만들 수 있습니다.
-- Illustrative logic: Extracting target business counts per H3 cell across New York City
DECLARE geo GEOGRAPHY;
-- Get the geography for New York City using the Overture Maps public dataset
SET geo = (SELECT geometry FROM `bigquery-public-data.overture_maps.division_area`
WHERE country = 'US' AND subtype = 'locality' AND names.primary = 'New York' LIMIT 1);
SELECT *
FROM `YOUR_PROJECT_NAME.places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', geo,
'h3_resolution', 8,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
)
ORDER BY count DESC;
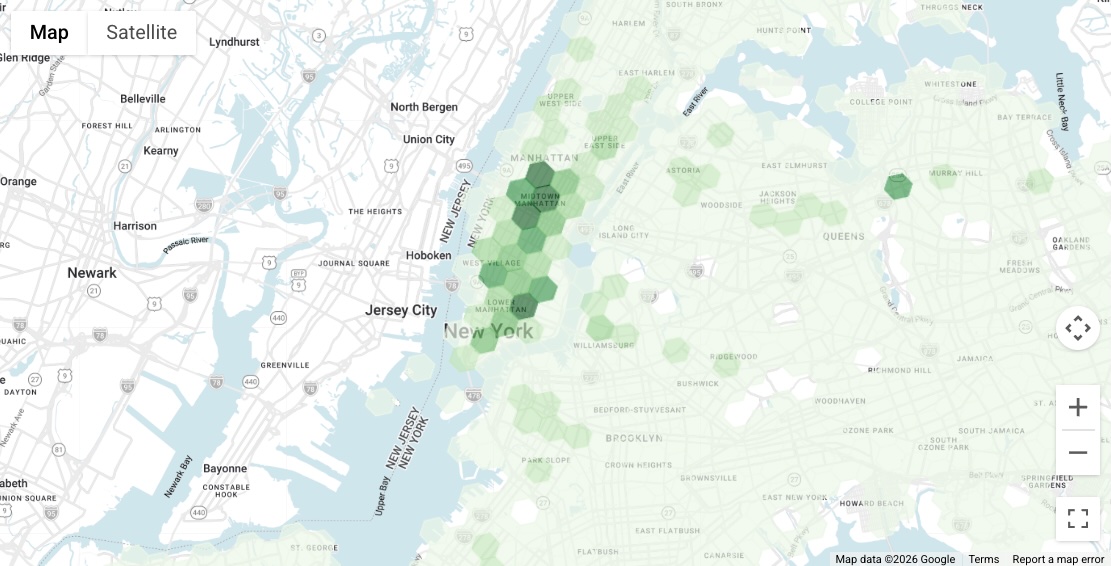
결과 시각화에서 알 수 있듯이 맨해튼 전역에 타겟 비즈니스의 밀도가 높은 영역이 명확하게 표시됩니다. 이 문서의 나머지 부분에서는 유니언 스퀘어 인근 지역과 같이 잠재력이 높은 지역 중 한 곳에 집중하여 리드 생성 노력을 기울일 것입니다.
3단계: CRM 데이터를 장소 ID로 정규화
제외 분석을 실행하려면 먼저 CRM 레코드를 장소 ID로 변환해야 합니다. CRM 데이터는 비구조적인 경우가 많으므로 검색 API에 원시 텍스트를 전달하면 일치율이 낮아집니다. 이 2단계 파이프라인을 사용하여 주소를 정리하고, 지역 API 지원 범위를 고려하고, BigQuery에 대해 올바른 시설 장소 ID를 추출할 수 있습니다.
CRM에 뉴욕시에 있는 다음 5명의 레스토랑 고객이 있다고 가정해 보겠습니다.
| 장소 이름 | 주소 |
|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States |
| Gramercy Tavern | 42 E 20th St, New York, NY 10003, United States |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States |
| Union Square Cafe | 101 E 19th St, New York, NY 10003, United States |
이러한 레코드는 비정형 텍스트로 구성되어 있으므로 BigQuery의 장소 통계 데이터와 직접 조인할 수 없습니다. 대신 다음 파이프라인을 통해 각 행을 처리하여 텍스트를 표준화하고 장소 ID를 추출합니다.
3a단계: 주소 정리 및 직접 매칭
먼저 주소 데이터를 표준화하세요. 대상 국가에 따라 API를 선택합니다.
옵션 1: Address Validation API
지원되는 지역의 경우 연결된 CRM 비즈니스 이름과 주소를 API에 전달합니다. 대답의 result.geocode.placeTypes 배열을 검사합니다.
- 업체 일치:
establishment또는point_of_interest이 포함된 경우 API가 비즈니스를 성공적으로 확인했습니다. 이placeId를 데이터 세트에 추가하고 다음 CRM 레코드로 이동합니다. 이 항목에는 추가 API 호출이 필요하지 않습니다. - 비즈니스 유형이 일치하지 않음: 이러한 비즈니스 유형이 포함되어 있지 않으면 API에서 비즈니스 법인을 확실하게 확인할 수 없습니다. 반환된 장소 ID는 지리적 지형지물 (예: 건물, 거리 또는 도시)을 나타냅니다. 제외 조인이 실패하므로 BigQuery에 이 장소 ID를 사용하지 마세요. 대신
result.address.formattedAddress을 저장하고 3b단계로 진행합니다.
옵션 2: Geocoding API
Address Validation에서 지원하지 않는 지역의 경우 CRM 주소만 Geocoding API에 전달합니다. Geocoding API에서 예측할 수 없는 결과를 반환할 수 있으므로 비즈니스 이름을 포함하지 마세요. 결과로 생성된 formattedAddress을 추출하고 3b단계로 진행합니다.
고급 아키텍처: LLM으로 비정형 데이터 처리
비즈니스 이름과 주소가 하나의 자유 형식 메모 필드에 혼합되어 있는 등 CRM 데이터가 매우 부실한 경우 Gemini와 같은 LLM으로 레코드를 사전 처리합니다. 이 파이프라인에 입력하기 전에 Gemini에게 위치에서 비즈니스 이름을 깔끔하게 파싱하도록 요청할 수 있습니다.
3b단계: 비즈니스 엔티티 해결
3a단계에서 정리된 주소만 반환되는 경우 원래 CRM 비즈니스 이름과 연결하여 Text Search API에 전달합니다. 먼저 주소를 표준화하면 일치율이 크게 향상됩니다.
성능과 비용을 최적화하려면 필드 마스크 (X-Goog-FieldMask:
places.id)를 사용하고 "pageSize": 1를 설정하여 상위 일치 장소 ID만 반환되도록 합니다.
텍스트 검색 요청의 예:
curl -X POST -d '{
"textQuery" : "Gramercy Tavern 42 E 20th St, New York, NY 10003-1324, USA",
"pageSize": 1
}' \
-H 'Content-Type: application/json' -H 'X-Goog-Api-Key: YOUR_API_KEY' \
-H 'X-Goog-FieldMask: places.id' \
'https://places.googleapis.com/v1/places:searchText'
파이프라인 출력
이 2단계 파이프라인을 통해 CRM 레코드를 처리한 후 3a단계에서 ID가 성공적으로 추출되었는지 또는 3b단계에서 텍스트 검색을 사용하여 해결되었는지에 관계없이 최종 목표는 데이터 세트에 새 place_id 열을 추가하는 것입니다. 이제 이 결과 테이블을 BigQuery에 업로드하여 제외 목록으로 사용할 수 있습니다.
| 장소 이름 | 주소 | 장소 ID |
|---|---|---|
| Boucherie Union Square | 225 Park Ave S, New York, NY 10003, United States | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| Gramercy Tavern | 42 E 20th St, New York, NY 10003, United States | ChIJvSQIgqFZwokRFYQbJdzceSs |
| Barn Joo Union Square | 35 Union Square W, New York, NY 10003, United States | ChIJQ7XpyqNZwokRQpVfvGEViWM |
| LOS TACOS No.1 | 200 Park Ave S, New York, NY 10003, United States | ChIJFZh0PABZwokRVzoJu0o-mLY |
| Union Square Cafe | 101 E 19th St, New York, NY 10003, United States | ChIJxTHke6JZwokRCLWVd99eDBw |
4단계: BigQuery에서 공백 제외 분석 실행
기존 고객을 장소 ID에 매핑한 후 장소 수 함수를 사용하여 신규 리드를 찾습니다.
이 예에서는 유니언 스퀘어 (40.73595, -73.99043)에서 반경 850m 이내에 있는 운영 타겟 비즈니스(레스토랑, 바, 카페, 커피숍)를 검색합니다. 거리 수준 라우팅을 더 세부적으로 확인하기 위해 PLACES_COUNT_PER_H3 함수를 해상도 10으로 늘립니다.
이 함수는 장소 ID를 sample_place_ids 열의 배열로 반환하므로 각 잠재적 비즈니스를 자체 행에 배치하기 위해 배열을 UNNEST해야 합니다. 그런 다음 알려진 고객 장소 ID에 대해 LEFT JOIN를 실행합니다.
이 데모에서 제외 로직이 작동하는지 증명하기 위해 아래 쿼리는 결과를 완전히 필터링하는 대신 CASE 문을 사용하여 결과를 플래그합니다.
또한 기존 고객을 결과 표의 맨 위로 명시적으로 정렬하여 고객이 성공적으로 매칭되었는지 확인할 수 있습니다.
SQL 쿼리
WITH existing_customers AS (
-- 1. Simulate the uploaded CRM table
SELECT * FROM UNNEST([
'ChIJc1Vf7KFZwokR1YL2Rn9oxi8', -- Boucherie Union Square
'ChIJvSQIgqFZwokRFYQbJdzceSs', -- Gramercy Tavern
'ChIJQ7XpyqNZwokRQpVfvGEViWM', -- Barn Joo Union Square
'ChIJFZh0PABZwokRVzoJu0o-mLY', -- LOS TACOS No.1
'ChIJxTHke6JZwokRCLWVd99eDBw' -- Union Square Cafe
]) AS place_id
),
target_area_businesses AS (
-- 2. Query Places Insights for target businesses in the radius
SELECT
h3_cell_index,
place_id
FROM `places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', ST_GEOGPOINT(-73.99043, 40.73595),
'geography_radius', 850,
'h3_resolution', 10,
'types',['restaurant', 'bar', 'cafe', 'coffee_shop'],
'business_status', ['OPERATIONAL']
)
),
UNNEST(sample_place_ids) AS place_id
)
-- 3. The "Proof" Output: Flag them instead of filtering them out
SELECT
t.h3_cell_index,
t.place_id,
-- Flag whether the LEFT JOIN found a match in the CRM table
CASE
WHEN e.place_id IS NOT NULL THEN 'Existing Customer (To Be Excluded)'
ELSE 'Net-New Lead'
END AS lead_status,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
ORDER BY
-- Explicitly sort the existing customers to the top (0 comes before 1)
CASE WHEN e.place_id IS NOT NULL THEN 0 ELSE 1 END ASC;
쿼리 결과
다음은 쿼리 출력의 발췌로, 기존 고객이 동일한 세부 H3 셀 내에서 신규 리드와 성공적으로 식별되고 분리되는 방식을 보여줍니다.
쿼리에서 place_id을 사용하여 CONCAT 문으로 크로스 플랫폼 지도 URL을 구성하는 방법을 확인하세요. 이렇게 하면 actionable_maps_url 열이 자동으로 생성되어 영업팀에 Google 지도 모바일 앱이나 브라우저에서 정확한 비즈니스를 로드할 수 있는 클릭 가능한 링크가 즉시 제공됩니다.
h3_cell_index |
place_id |
lead_status |
actionable_maps_url |
|---|---|---|---|
| 8a2a100d2767fff | ChIJQ7XpyqNZwokRQpVfvGEViWM | 기존 고객 (제외됨) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJQ7XpyqNZwokRQpVfvGEViWM |
| 8a2a100d20effff | ChIJvSQIgqFZwokRFYQbJdzceSs | 기존 고객 (제외됨) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJvSQIgqFZwokRFYQbJdzceSs |
| 8a2a100d2397fff | ChIJc1Vf7KFZwokR1YL2Rn9oxi8 | 기존 고객 (제외됨) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJc1Vf7KFZwokR1YL2Rn9oxi8 |
| 8a2a100d2397fff | ChIJFZh0PABZwokRVzoJu0o-mLY | 기존 고객 (제외됨) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJFZh0PABZwokRVzoJu0o-mLY |
| 8a2a100d23b7fff | ChIJxTHke6JZwokRCLWVd99eDBw | 기존 고객 (제외됨) | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJxTHke6JZwokRCLWVd99eDBw |
| 8a2a1072c96ffff | ChIJ6atD-WRZwokRULgcZ4TWin8 | 순 신규 리드 | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ6atD-WRZwokRULgcZ4TWin8 |
| 8a2a1072c96ffff | ChIJ09yg-llZwokRKAgp0jg6TCU | 순 신규 리드 | https://www.google.com/maps/search/?api=1&query=Place&query_place_id=ChIJ09yg-llZwokRKAgp0jg6TCU |
장소 UI 키트로 리드 시각화
원시 지도 URL을 제공하는 대신 place_ids를 장소 UI 키트에 직접 전달하여 영업팀을 위한 풍부한 내부 리드 생성 대시보드를 빌드할 수 있습니다.
다양한 플랫폼에서 사용할 수 있으며 웹, Android, iOS용 사전 빌드된 구성요소를 삽입할 수 있습니다.
이러한 구성요소는 프런트엔드 UI 코드를 작성하거나 API 응답을 수동으로 처리하지 않아도 사진, 평점, 영업시간과 같은 풍부한 관심 장소 데이터를 자동으로 표시합니다.
데이터 한도
장소 수 함수는 sample_place_ids 배열의 지리적 셀당 최대 250개의 장소 ID를 반환합니다. 영역이 매우 밀집된 경우 해당 특정 셀에 대해 생성된 리드 목록이 250개로 제한됩니다. 밀도가 높은 시장에서 모든 리드를 확보하려면 다음 전략을 고려하세요.
- 구체적인 쿼리 필터 사용: 여러 유형을 하나의 쿼리로 그룹화하는 대신 (위 예시 참고) 각 개별 장소 유형에 대해 별도의 쿼리를 실행합니다.
- 공간 범위 줄이기: 더 작은
geography_radius를 사용하여 전체 검색 영역을 줄이거나 H3 해상도를 높여 (최대 해상도 11) 영역을 더 세분화된 작은 버킷으로 나눕니다. - 밀도별 해상도 조정: 인구 밀도가 다양한 지역을 분석할 때는 250개 장소 ID 제한에 도달하지 않도록 검색 크기를 동적으로 조정하세요. 비즈니스가 분산되어 있는 시골 지역에서는 더 넓은 H3 해상도 (예: 6 또는 7) 또는 더 큰
geography_radius를 사용하세요. 반대로, 목록이 잘리지 않고 모든 잠재 고객을 포착하려면 밀집된 도시 지역에서 매우 세분화된 해상도 (예: 10 또는 11)를 사용하세요.
프로덕션 쿼리
기존 고객이 성공적으로 식별되는지 확인한 후 쿼리의 프로덕션 버전으로 되돌릴 수 있습니다. 기존 비즈니스 장부를 영구적으로 필터링하려면 최종 SELECT 블록을 다음 WHERE 절로 바꿉니다.
SELECT
t.h3_cell_index,
t.place_id,
CONCAT('https://www.google.com/maps/search/?api=1&query=Place&query_place_id=', t.place_id) AS actionable_maps_url
FROM target_area_businesses t
LEFT JOIN existing_customers e
ON t.place_id = e.place_id
WHERE e.place_id IS NULL; -- Filters out the CRM matches
아키텍처 거버넌스 및 규정 준수
고성능의 규정 준수 시스템을 유지하려면 다음 표준을 준수하세요.
- 영구 식별자로 장소 ID 사용: 장소 ID 외에도 Google 지도 서비스 약관에 따라 Places API에서 반환된 개별 관심 장소 데이터 (예: 전화번호 및 연락처 세부정보)를 저장하거나 캐시하는 것이 금지됩니다. 반복되는 공백 분석을 위해 장소 ID를 영구 식별자로 사용하세요.
- 실시간 API 호출로 속성 최신 상태 유지: 장소 ID를 사용하여 Place Details API를 '적시' 호출하여 영업사원이 장소에 대한 최신 비즈니스 및 연락처 정보를 보유하도록 합니다. 또는 쿼리 출력에 표시된 대로 Google 지도 URL을 동적으로 구성하여 영업팀에 Google 지도의 비즈니스 프로필로 연결되는 직접 링크를 제공할 수 있습니다.
결론
장소 ID를 기본 키로 표준화하면 고급 시장 분석과 실행 가능한 현장 수준 판매 운영 간의 격차를 성공적으로 해소할 수 있습니다. 이 아키텍처는 기존의 인구 기반 타겟팅의 부정확성을 우회하고, 대규모 컴퓨팅 조인을 위해 서버리스 데이터 웨어하우스를 활용하며, API 레이어에서 비용 관리 및 규정 준수 권장사항을 엄격하게 준수합니다.
다음 작업
- Places Insights 샘플 데이터 세트에 대한 액세스를 요청합니다.
- BigQuery 데이터 교환 등록정보를 사용하여 Places Insights 데이터 세트를 구독하여 샘플 또는 전체 국가 데이터에 액세스합니다.
- 필터 매개변수 참조를 검토하여 비즈니스 속성 및 유형에 따라 BigQuery SQL 쿼리를 미세 조정합니다.
- CRM 또는 영업 라우팅 애플리케이션에서 동적 Places API 조회를 구현하여 생성된 신규 리드에 대한 최신 규정 준수 연락처 세부정보를 표시합니다.
참여자
- Henrik Valve | DevX 엔지니어