
總覽
標準位置資料可以告訴您附近有什麼,但通常無法回答更重要的問題:「這個區域適合我嗎?」使用者的需求各有不同,與年輕的專業人士 (有養狗) 相比,有幼童的家庭優先考量的事項不同。為協助他們做出有把握的決定,您需要提供反映這些特定需求的洞察資料。自訂位置分數是強大的工具,可提供這項價值,並打造顯著差異化的使用者體驗。
本文說明如何使用 BigQuery 中的 Places Insights 資料集,建立自訂的多面向地點分數。將 POI 資料轉換為有意義的指標,即可豐富房地產、零售或旅遊應用程式,並為使用者提供所需的相關資訊。我們也提供在 BigQuery 中使用生成式 AI 的選項,做為計算位置分數的強大方式。
透過量身打造的分數提升業務價值
以下範例說明如何將原始位置資料轉換為以使用者為中心的強大指標,進而提升應用程式效能。
- 房地產開發人員可以建立「家庭友善分數」或「通勤族夢幻分數」,協助買家和租屋者選擇符合生活型態的完美社區,進而提高使用者參與度、優質待開發客戶和轉換速度。
- 旅遊和觀光業工程師可以建立「夜生活分數」或「觀光天堂分數」,協助旅客選擇符合度假風格的飯店,進而提高預訂率和顧客滿意度
- 零售分析師可以產生「健身與保健分數」,根據附近的互補商家找出新健身房或保健食品店的最佳地點,盡可能鎖定合適的使用者客層。
本指南將介紹靈活的三階段方法,說明如何直接在 BigQuery 中使用 Places 資料,建構任何類型的自訂地點分數。我們會建立兩個不同的範例分數,說明這個模式:家庭友善分數和寵物主人天堂分數。這種做法可讓您擺脫地點計數,並充分運用 Places Insights 資料集中的豐富詳細屬性。您可以運用營業時間、地點是否適合兒童或是否允許攜帶寵物狗等資訊,為使用者建立精細且有意義的指標。
解決方案工作流程
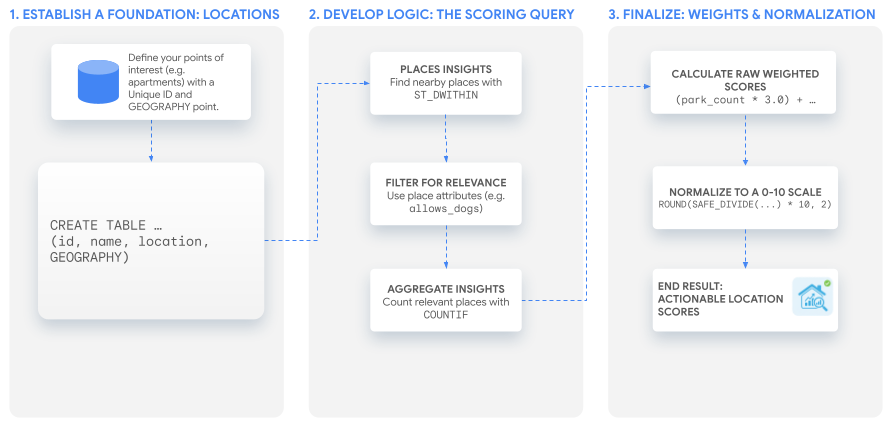
本教學課程會使用單一強大的 SQL 查詢,建立可因應任何用途的自訂分數。我們會逐步說明這個程序,並為假設的公寓房源組合建立兩個範例分數。
如要在互動式環境中探索這個工作流程,請執行下列筆記本。本教學課程示範如何在 BigQuery 中使用 AI.GENERATE 函式建立位置分數。
 在 GitHub 上查看來源
在 GitHub 上查看來源
必要條件
開始之前,請按照這些操作說明設定地點洞察。
1. 奠定基礎:感興趣的地點
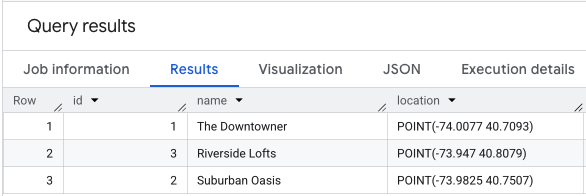
如要建立分數,您必須先列出要分析的地點。首先,請確認這項資料以資料表形式存在於 BigQuery 中。重點是為每個地點提供專屬 ID,以及儲存座標的GEOGRAPHY資料欄。
您可以建立並填入位置資料表,然後使用類似下列的查詢來評估:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
對位置資料執行 SELECT * 的結果如下。
2. 開發核心邏輯:評分查詢
建立地點後,下一個步驟是尋找、篩選及計算與自訂分數相關的附近地點。這一切都在單一 SELECT 陳述式中完成。
使用地理空間搜尋功能尋找附近地點
首先,您需要從 Places Insights 資料集找出與各個地點相距特定距離內的所有地點。BigQuery 函式 ST_DWITHIN 非常適合這項工作。我們會對 apartment_listings 資料表和 places_insights 資料表執行 JOIN,找出 800 公尺半徑內的所有地點。LEFT JOIN 可確保結果中包含所有原始位置,即使附近找不到相符地點也一樣。
使用進階屬性篩選相關性
您可以在這裡將抽象概念的分數轉換為具體的資料篩選條件。以這兩個範例分數來說,評估標準不同:
- 「家庭友善分數」方面,我們重視明確適合兒童的公園、博物館和餐廳。
- 「寵物友善天堂分數」的評估依據包括公園、獸醫診所、寵物店,以及允許攜帶狗狗進入的餐廳或咖啡廳。
您可以在查詢的 WHERE 子句中直接篩選這些特定屬性。
彙整各個地點的洞察資料
最後,請計算每個公寓找到多少個相關地點。GROUP BY 子句會匯總結果,而 COUNTIF 函式則會計算符合各項分數特定條件的地點。
下列查詢會合併這三個步驟,在單一傳遞中計算兩個分數的原始計數:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
這項查詢的結果會類似於以下內容。
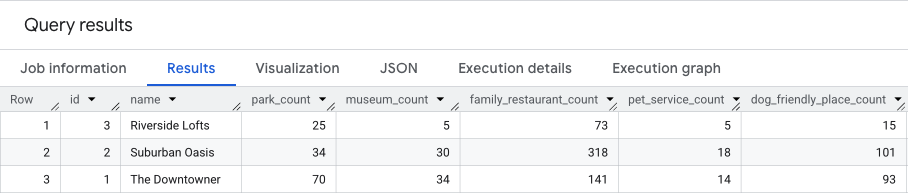
我們將在下一節中以這些結果為基礎。
3. 建立分數
現在您已取得每個地點類型在每個位置的數量和權重,可以產生自訂地點分數。本節將討論兩種做法:在 BigQuery 中使用自訂計算,或使用 BigQuery 中的生成式人工智慧 (AI) 函式。
選項 1:在 BigQuery 中使用自訂計算
上一個步驟的原始計數很有參考價值,但我們的目標是提供單一易於使用的分數。最後一個步驟是使用權重合併這些計數,然後將結果正規化為 0 到 10 的範圍。
套用自訂權重:選擇權重是一門藝術,也是一門科學。 這些目標必須反映您的業務優先事項,或是您認為對使用者最重要的事項。舉例來說,在「家庭友善」評分中,您可能會認為公園的重要性是博物館的兩倍。先從最合理的假設開始,然後根據使用者意見回饋進行疊代。
將分數正規化:下列查詢會使用兩個通用資料表運算式 (CTE):第一個會照常計算原始計數,第二個則會計算加權分數。最後的 SELECT 陳述式會對加權分數執行 min-max 正規化。輸出範例表格的 location 欄,以便在地圖上顯示資料。apartment_listings
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
查詢結果會類似下方內容。最後兩欄是經過正規化的分數。

瞭解正規化分數
瞭解最後的正規化步驟為何如此重要,是相當有幫助的。
原始加權分數範圍可能從 0 到非常大的數字,具體取決於您所在位置的都市密度。如果使用者不瞭解背景資訊,500 分數就沒有意義。
正規化會將這些抽象數字轉換為相對排名。將結果縮放至 0 到 10 分,即可清楚看出每個地點在特定資料集中與其他地點的比較結果:
- 原始分數最高的地點會獲得 10 分,標示為目前設定中的最佳選項。
- 原始分數最低的地點會獲得 0 分,做為比較基準。這不代表該地點完全沒有設施,而是相較於其他評估選項,該地點最不適合。
- 所有其他分數都會按比例落在中間,讓使用者一目瞭然地比較各種選項。
選項 2:使用 AI.GENERATE 函式 (Gemini)
除了使用固定的數學公式,您也可以使用 BigQuery AI.GENERATE 函式,直接在 SQL 工作流程中計算自訂位置分數。
方法 1 非常適合根據設施數量進行純粹的量化評分,但無法輕鬆納入質性資料。AI.GENERATE 函式可讓您將 Places Insights 查詢中的數字與非結構化資料合併,例如公寓房源的文字說明 (例如「這個地點適合家庭入住,晚上很安靜」) 或特定使用者個人資料偏好設定 (例如「這位使用者要為家庭預訂住宿,偏好位於市中心且安靜的區域」)。這樣一來,系統就能產生更細緻的分數,偵測嚴格計數可能錯過的細微差異,例如某個地點的設施密度很高,但也被描述為「對兒童來說太吵」。
建構提示
如要使用這項函式,請將匯總結果 (步驟 2) 格式化為自然語言提示。您可以在 SQL 中動態執行這項操作,方法是將資料欄與模型指令串連。
在下列查詢中,insight_counts 會與公寓的文字說明合併,為每個資料列建立提示。此外,系統也會定義目標使用者設定檔,做為評分依據。
使用 SQL 生成分數
下列查詢會在 BigQuery 中執行整個作業。其中包括:
- 匯總地點數量 (如步驟 2 所述)。
- 建構每個位置的提示。
- 呼叫
AI.GENERATE函式,使用 Gemini 模型分析提示。 - 剖析結果,並轉換為結構化格式,方便在應用程式中使用。
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
瞭解設定
- 費用提醒:這項功能會將輸入內容傳遞至 Gemini 模型,且每次呼叫時,Vertex AI 都會產生費用。如果要分析大量地點 (例如數千筆公寓房源),建議先篩選資料集,找出最相關的候選地點。如要進一步瞭解如何盡量降低費用,請參閱「最佳做法」。
endpoint:本範例指定gemini-flash-latest,以優先考量速度和成本效益。不過,您可以選擇最符合需求的模型。請參閱 Gemini 模型說明文件,嘗試使用不同版本 (例如 Gemini Pro 適用於較複雜的推論工作),找出最適合您用途的模型。output_schema:系統會強制執行結構定義 (FLOAT64代表分數,STRING代表原因),而非剖析原始文字。這樣一來,您就能在應用程式或視覺化工具中直接使用輸出內容,不必進行後續處理。
輸出範例
查詢會傳回標準 BigQuery 資料表,其中包含自訂分數和模型推論。
| id | 名稱 | family_friendliness_score | 推論 |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | 設施數量 (公園、餐廳) 充足,符合量化指標。不過,質性資料顯示週末噪音過多,且夜生活活動頻繁,這與目標使用者對安靜環境的需求直接衝突。 |
| 2 | Suburban Oasis | 9.8 | 優異的量化資料,加上與目標家庭簡介完全相符的說明 (「綠樹成蔭的寧靜街道」)。正向修飾符越高,分數就越接近完美。 |
這項程序可讓您提供高度個人化的評分,讓每位使用者都能瞭解並量身打造,而且全都在單一 SQL 查詢中完成。
4. 在地圖上查看分數
如果查詢結果包含 GEOGRAPHY 資料欄,BigQuery Studio 會提供整合式地圖視覺化功能。由於查詢會輸出 location 欄,因此您可以立即以視覺化方式呈現分數。
按一下「Visualization」分頁標籤會顯示地圖,而「Data Column」下拉式選單則可控制要顯示的位置分數。在本例中,normalized_pet_score 是從選項 1 範例視覺化而來。請注意,在此範例中,apartment_listings 資料表已新增更多位置。
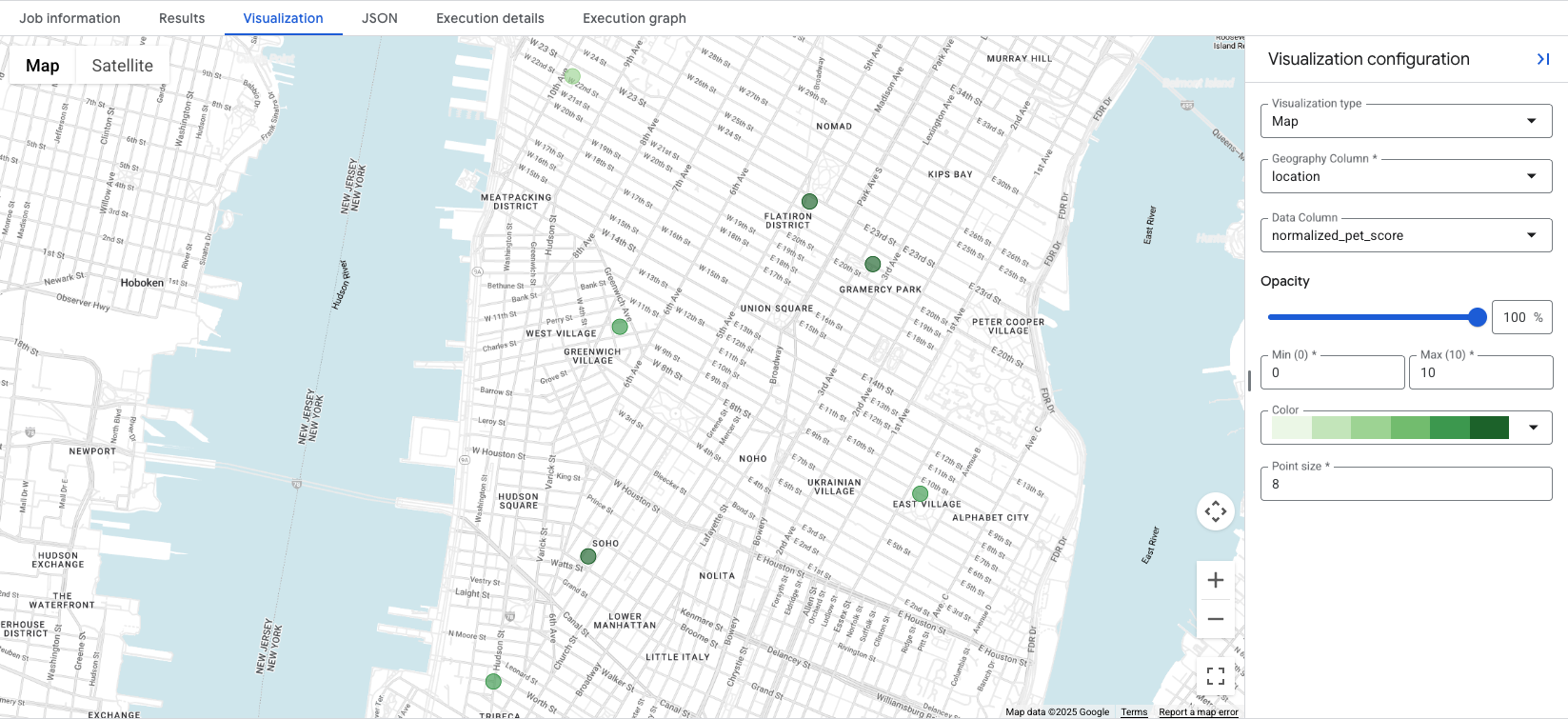
資料視覺化結果會顯示最適合建立分數的地點,深綠色圓圈代表 normalized_pet_score 較高的地點。如需更多 Places Insights 資料的視覺化選項,請參閱「將查詢結果視覺化」。
結論
您現在已掌握強大且可重複使用的方法,可建立細緻的店面分數。您從位置資訊開始,在 BigQuery 中建立單一 SQL 查詢,找出附近的地點 (使用 ST_DWITHIN),並依 good_for_children 和 allows_dogs 等進階屬性篩選地點,然後使用 COUNTIF 彙整結果。套用自訂權重並將結果正規化後,您就能產生單一易懂的分數,提供深入且可執行的洞察資料。您可以直接套用此模式,將原始位置資料轉換為重要的競爭優勢。
後續動作
現在輪到您大展身手了。本教學課程提供範本。您可以使用 Places Insights 結構定義中提供的豐富資料,建立最符合您用途的分數。您可以建立的其他分數包括:
- 「夜生活分數」:結合
primary_type(bar、night_club)、price_level和深夜營業時間的篩選條件,找出夜間最熱鬧的區域。 - 「健身與養生分數」:計算附近的
gyms、parks和health_food_stores,並篩選出有serves_vegetarian_food的餐廳,為注重健康的消費者提供地點評分。 - 「通勤族夢幻指數」:找出附近有大量
transit_station和parking地點的位置,協助重視交通便利性的使用者。
貢獻者
Henrik Valve | DevX 工程師