
Tổng quan
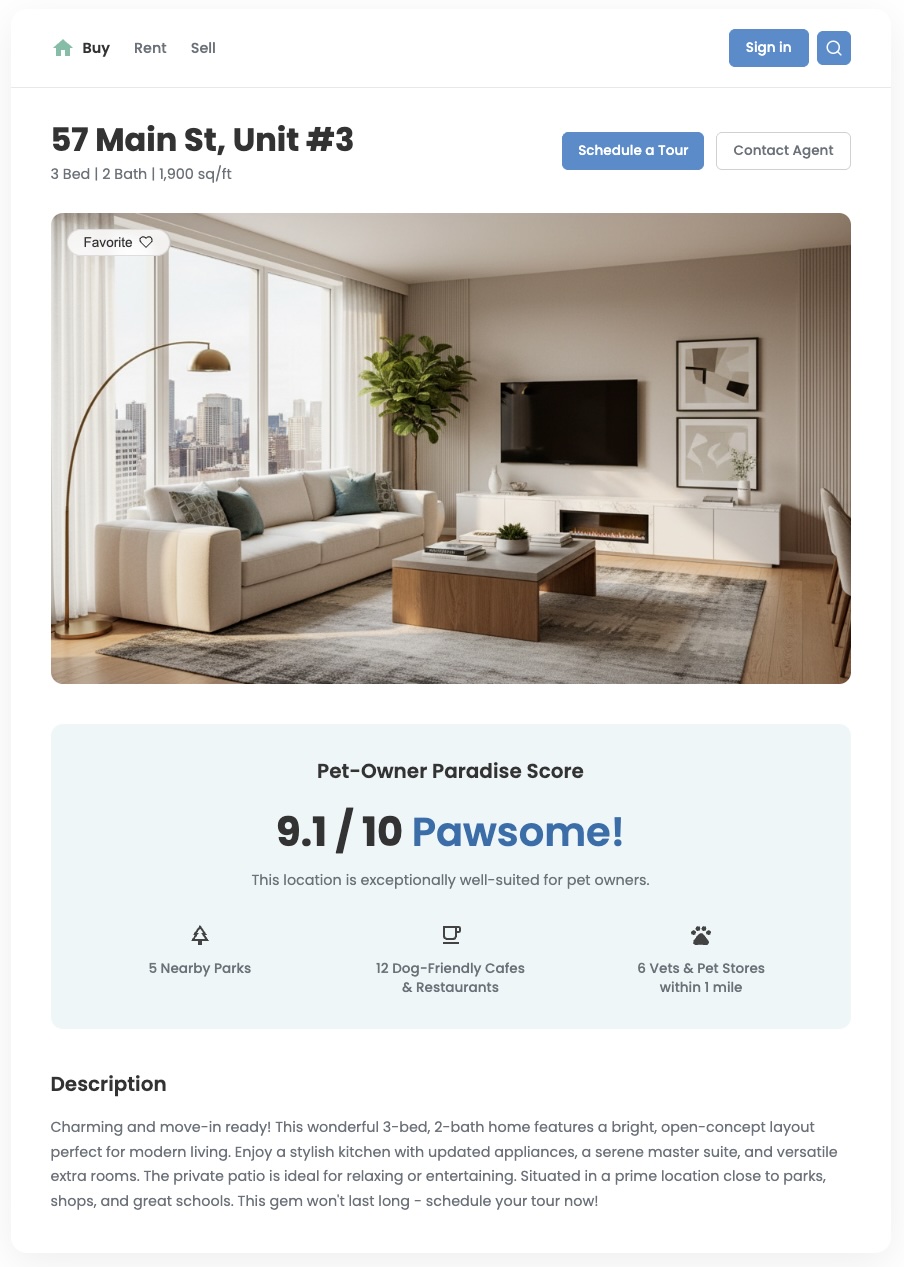
Dữ liệu vị trí tiêu chuẩn có thể cho bạn biết những gì ở gần đó, nhưng thường không trả lời được câu hỏi quan trọng hơn: "Khu vực này có phù hợp với tôi không?" Nhu cầu của người dùng rất đa dạng. Một gia đình có con nhỏ sẽ có những ưu tiên khác so với một người trẻ tuổi có chó. Để giúp họ đưa ra quyết định tự tin, bạn cần cung cấp thông tin chi tiết phản ánh những nhu cầu cụ thể này. Điểm vị trí tuỳ chỉnh là một công cụ mạnh mẽ để mang lại giá trị này và tạo ra trải nghiệm người dùng khác biệt đáng kể.
Tài liệu này mô tả cách tạo điểm vị trí tuỳ chỉnh, đa dạng bằng cách sử dụng tập dữ liệu Thông tin chi tiết về địa điểm trong BigQuery. Bằng cách chuyển đổi dữ liệu POI thành các chỉ số có ý nghĩa, bạn có thể làm phong phú thêm các ứng dụng bất động sản, bán lẻ hoặc du lịch và cung cấp cho người dùng thông tin phù hợp mà họ cần. Chúng tôi cũng cung cấp một lựa chọn để sử dụng AI tạo sinh trong BigQuery như một cách mạnh mẽ để tính toán điểm vị trí.
Nâng cao giá trị của doanh nghiệp qua điểm số phù hợp
Các ví dụ sau đây minh hoạ cách bạn có thể chuyển đổi dữ liệu vị trí thô thành các chỉ số mạnh mẽ, lấy người dùng làm trung tâm để nâng cao ứng dụng của mình.
- Nhà phát triển bất động sản có thể tạo "Điểm thân thiện với gia đình" hoặc "Điểm lý tưởng cho người đi làm" để giúp người mua và người thuê chọn khu dân cư hoàn hảo phù hợp với lối sống của họ, dẫn đến tăng mức độ tương tác của người dùng, tăng số lượng khách hàng tiềm năng chất lượng cao và tăng tốc độ chuyển đổi.
- Kỹ sư du lịch và khách sạn có thể xây dựng "Điểm cuộc sống về đêm" hoặc "Điểm thiên đường cho người ngắm cảnh" để giúp khách du lịch chọn một khách sạn phù hợp với phong cách du lịch của họ, tăng tỷ lệ đặt phòng và sự hài lòng của khách hàng
- Nhà phân tích bán lẻ có thể tạo "Điểm thể dục và sức khoẻ" để xác định vị trí tối ưu cho một phòng tập thể dục hoặc cửa hàng thực phẩm tốt cho sức khoẻ mới dựa trên các doanh nghiệp bổ sung ở gần đó, tối đa hoá tiềm năng nhắm mục tiêu đến nhân khẩu học người dùng phù hợp.
Trong hướng dẫn này, bạn sẽ tìm hiểu một phương pháp linh hoạt gồm 3 phần để xây dựng bất kỳ loại điểm vị trí tuỳ chỉnh nào bằng dữ liệu Địa điểm trực tiếp trong BigQuery. Chúng tôi sẽ minh hoạ mẫu này bằng cách xây dựng 2 điểm ví dụ riêng biệt: Điểm thân thiện với gia đình và Điểm thiên đường cho người nuôi thú cưng. Phương pháp này cho phép bạn vượt ra ngoài số lượng địa điểm và tận dụng các thuộc tính phong phú, chi tiết trong tập dữ liệu Thông tin chi tiết về địa điểm. Bạn có thể sử dụng thông tin như giờ hoạt động, liệu một địa điểm có phù hợp với trẻ em hay không hoặc có cho phép chó hay không, để tạo các chỉ số phức tạp và có ý nghĩa cho người dùng.
Quy trình giải pháp
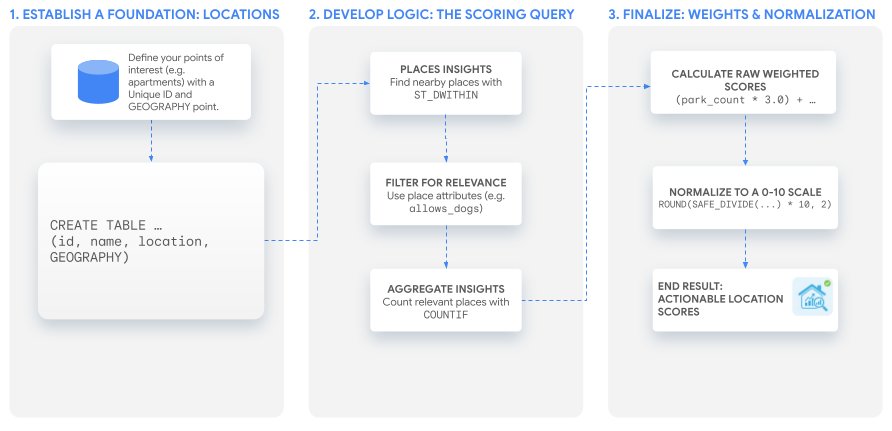
Hướng dẫn này sử dụng một truy vấn SQL mạnh mẽ để tạo điểm tuỳ chỉnh mà bạn có thể điều chỉnh cho phù hợp với mọi trường hợp sử dụng. Chúng ta sẽ đi qua quy trình này bằng cách tạo 2 điểm ví dụ cho một tập hợp danh sách căn hộ giả định.
Để khám phá quy trình này trong một môi trường tương tác, hãy chạy sổ tay sau. Sổ tay này minh hoạ cách sử dụng hàm
AI.GENERATE trong
BigQuery để tạo điểm vị trí.
 Xem nguồn trên GitHub
Xem nguồn trên GitHub
Điều kiện tiên quyết
Trước khi bắt đầu, hãy làm theo các hướng dẫn sau để thiết lập Thông tin chi tiết về địa điểm.
1. Thiết lập nền tảng: Các địa điểm bạn quan tâm
Trước khi có thể tạo điểm, bạn cần có danh sách các địa điểm mà bạn muốn phân tích. Bước đầu tiên là đảm bảo dữ liệu này tồn tại dưới dạng bảng trong BigQuery.
Điều quan trọng là phải có một giá trị nhận dạng riêng biệt cho mỗi địa điểm và một cột GEOGRAPHY lưu trữ toạ độ của địa điểm đó.
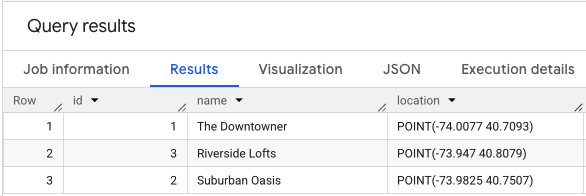
Bạn có thể tạo và điền sẵn một bảng các địa điểm để tính điểm bằng một truy vấn như sau:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
Việc thực hiện SELECT * trên dữ liệu vị trí của bạn sẽ có dạng tương tự như sau.
2. Phát triển logic cốt lõi: Truy vấn tính điểm
Sau khi thiết lập vị trí, bước tiếp theo là tìm, lọc và đếm các địa điểm ở gần có liên quan đến điểm tuỳ chỉnh của bạn. Tất cả đều được thực hiện trong một câu lệnh SELECT.
Tìm những gì ở gần bằng tính năng tìm kiếm không gian địa lý
Trước tiên, bạn cần tìm tất cả các địa điểm từ tập dữ liệu Thông tin chi tiết về địa điểm nằm trong một khoảng cách nhất định của mỗi địa điểm. Hàm ST_DWITHIN của BigQuery là lựa chọn hoàn hảo cho việc này. Chúng ta sẽ thực hiện JOIN giữa bảng apartment_listings và bảng places_insights để tìm tất cả các địa điểm trong bán kính 800 mét. LEFT JOIN đảm bảo rằng tất cả các địa điểm ban đầu của bạn đều được đưa vào kết quả, ngay cả khi không tìm thấy địa điểm nào phù hợp ở gần đó.
Lọc để có mức độ liên quan bằng các thuộc tính nâng cao
Đây là nơi bạn chuyển đổi khái niệm trừu tượng về điểm thành bộ lọc dữ liệu cụ thể. Đối với 2 điểm ví dụ, tiêu chí sẽ khác nhau:
- Đối với "Điểm thân thiện với gia đình", chúng ta quan tâm đến các công viên, bảo tàng và nhà hàng đặc biệt phù hợp với trẻ em.
- Đối với "Điểm thiên đường cho người nuôi thú cưng", chúng ta quan tâm đến các công viên, phòng khám thú y, cửa hàng thú cưng và bất kỳ nhà hàng hoặc quán cà phê nào cho phép chó.
Bạn có thể lọc các thuộc tính cụ thể này trực tiếp trong mệnh đề WHERE của truy vấn.
Tổng hợp thông tin chi tiết cho từng địa điểm
Cuối cùng, bạn cần đếm số địa điểm có liên quan mà bạn tìm thấy cho mỗi căn hộ. Mệnh đề GROUP BY tổng hợp kết quả và hàm COUNTIF đếm các địa điểm khớp với tiêu chí cụ thể cho từng điểm của chúng ta.
Truy vấn bên dưới kết hợp 3 bước này, tính toán số lượng thô cho cả 2 điểm trong một lần truyền:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Kết quả của truy vấn này sẽ tương tự như sau.
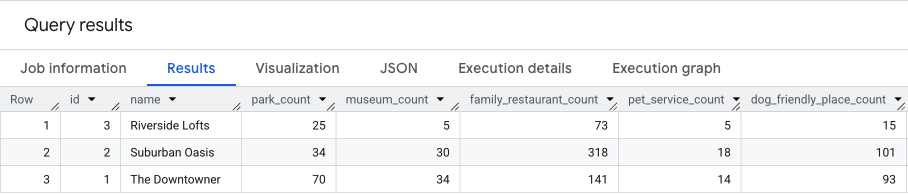
Chúng ta sẽ xây dựng dựa trên những kết quả này trong phần tiếp theo.
3. Tạo điểm số
Bây giờ, bạn đã có số lượng địa điểm và trọng số cho từng loại địa điểm cho mỗi địa điểm, bạn có thể tạo điểm vị trí tuỳ chỉnh. Chúng ta sẽ thảo luận về 2 lựa chọn trong phần này: sử dụng phép tính tuỳ chỉnh của riêng bạn trong BigQuery hoặc sử dụng các hàm trí tuệ nhân tạo (AI) tạo sinh trong BigQuery.
Lựa chọn 1: Sử dụng phép tính tuỳ chỉnh của riêng bạn trong BigQuery
Số lượng thô từ bước trước rất hữu ích, nhưng mục tiêu là một điểm duy nhất, thân thiện với người dùng. Bước cuối cùng là kết hợp các số lượng này bằng cách sử dụng trọng số, sau đó chuẩn hoá kết quả theo thang điểm từ 0 đến 10.
Áp dụng trọng số tuỳ chỉnh Việc chọn trọng số vừa là nghệ thuật vừa là khoa học. Chúng cần phản ánh các ưu tiên kinh doanh của bạn hoặc những gì bạn tin là quan trọng nhất đối với người dùng. Đối với Điểm "Thân thiện với gia đình", bạn có thể quyết định rằng một công viên quan trọng gấp đôi một bảo tàng. Bắt đầu với những giả định tốt nhất và lặp lại dựa trên ý kiến phản hồi của người dùng.
Chuẩn hoá điểm Truy vấn bên dưới sử dụng 2 Biểu thức bảng chung (CTE): biểu thức đầu tiên tính toán số lượng thô như trước và biểu thức thứ hai tính toán điểm có trọng số. Sau đó, câu lệnh SELECT cuối cùng thực hiện chuẩn hoá tối thiểu-tối đa trên điểm có trọng số. Cột location của bảng apartment_listings ví dụ được xuất ra để cho phép trực quan hoá dữ liệu trên bản đồ.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Kết quả của truy vấn sẽ tương tự như bên dưới. Hai cột cuối cùng là điểm đã chuẩn hoá.

Tìm hiểu về điểm đã chuẩn hoá
Điều quan trọng là phải hiểu lý do tại sao bước chuẩn hoá cuối cùng này lại có giá trị như vậy.
Điểm có trọng số thô có thể dao động từ 0 đến một số rất lớn tuỳ thuộc vào mật độ đô thị của các địa điểm. Điểm 500 không có ý nghĩa gì đối với người dùng nếu không có bối cảnh.
Quá trình chuẩn hoá chuyển đổi các số trừu tượng này thành thứ hạng tương đối. Bằng cách chuyển tỉ lệ kết quả từ 0 đến 10, điểm số cho biết rõ ràng cách so sánh từng địa điểm với các địa điểm khác trong tập dữ liệu cụ thể của bạn:
- Điểm 10 được gán cho vị trí có điểm thô cao nhất, đánh dấu vị trí đó là lựa chọn tốt nhất trong tập hợp hiện tại.
- Điểm 0 được gán cho địa điểm có điểm thô thấp nhất, tạo thành đường cơ sở để so sánh. Điều này không có nghĩa là địa điểm không có tiện nghi, mà là địa điểm đó ít phù hợp nhất so với các lựa chọn khác đang được đánh giá.
- Tất cả các điểm khác đều nằm ở giữa theo tỷ lệ, mang đến cho người dùng cách rõ ràng và trực quan để so sánh các lựa chọn của họ trong nháy mắt.
Lựa chọn 2: Sử dụng hàm AI.GENERATE (Gemini)
Ngoài việc sử dụng công thức toán học cố định, bạn có thể sử dụng hàm
BigQuery AI.GENERATE
để tính toán điểm vị trí tuỳ chỉnh trực tiếp trong quy trình làm việc SQL.
Mặc dù Lựa chọn 1 rất phù hợp để tính điểm hoàn toàn định lượng dựa trên số lượng tiện nghi, nhưng không dễ dàng tính đến dữ liệu định tính. Hàm AI.GENERATE cho phép bạn kết hợp các số từ truy vấn Thông tin chi tiết về địa điểm với dữ liệu không có cấu trúc, chẳng hạn như nội dung mô tả bằng văn bản của danh sách căn hộ (ví dụ: "Địa điểm này phù hợp với gia đình và khu vực này yên tĩnh vào ban đêm") hoặc các lựa chọn ưu tiên cụ thể trong hồ sơ người dùng (ví dụ: "Người dùng này đang đặt chỗ cho gia đình và thích một khu vực yên tĩnh ở vị trí trung tâm"). Điều này cho phép bạn tạo điểm số chi tiết hơn, phát hiện những điểm tinh tế mà số lượng nghiêm ngặt có thể bỏ lỡ, chẳng hạn như một địa điểm có mật độ tiện nghi cao nhưng cũng được mô tả là "quá ồn ào đối với trẻ em".
Xây dựng câu lệnh
Để sử dụng hàm này, kết quả của quá trình tổng hợp (từ Bước 2) được định dạng thành một câu lệnh bằng ngôn ngữ tự nhiên. Bạn có thể thực hiện việc này một cách linh hoạt trong SQL bằng cách nối các cột dữ liệu với hướng dẫn cho mô hình.
Trong truy vấn bên dưới, insight_counts được kết hợp với nội dung mô tả bằng văn bản của căn hộ để tạo một câu lệnh cho mỗi hàng. Hồ sơ người dùng mục tiêu cũng được xác định để hướng dẫn việc tính điểm.
Tạo điểm bằng SQL
Truy vấn sau đây thực hiện toàn bộ thao tác trong BigQuery. Tính năng tự động gắn thẻ:
- Tổng hợp số lượng Địa điểm (như mô tả trong Bước 2).
- Xây dựng một câu lệnh cho mỗi địa điểm.
- Gọi hàm
AI.GENERATEđể phân tích câu lệnh bằng mô hình Gemini. - Phân tích cú pháp kết quả thành một định dạng có cấu trúc sẵn sàng để sử dụng trong ứng dụng của bạn.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Tìm hiểu về cấu hình
- Nhận biết chi phí: Hàm này truyền thông tin đầu vào của bạn đến một mô hình Gemini và phát sinh chi phí trong Vertex AI mỗi khi được gọi. Nếu một số lượng lớn địa điểm đang được phân tích (ví dụ: hàng nghìn danh sách căn hộ), bạn nên lọc tập dữ liệu thành các ứng viên phù hợp nhất trước. Để biết thêm thông tin chi tiết về cách giảm thiểu chi phí, hãy xem phần Các phương pháp hay nhất.
endpoint:gemini-flash-latestđược chỉ định cho ví dụ này để ưu tiên tốc độ và hiệu quả chi phí. Tuy nhiên, bạn có thể chọn mô hình phù hợp nhất với nhu cầu của mình. Hãy xem tài liệu về các mô hình Gemini để thử nghiệm các phiên bản khác nhau (ví dụ: Gemini Pro cho các tác vụ suy luận phức tạp hơn) và tìm ra phiên bản phù hợp nhất cho trường hợp sử dụng của bạn.output_schema: Thay vì phân tích cú pháp văn bản thô, một lược đồ sẽ được thực thi (FLOAT64cho điểm vàSTRINGcho suy luận). Điều này đảm bảo rằng kết quả đầu ra có thể sử dụng ngay trong ứng dụng hoặc công cụ trực quan hoá mà không cần xử lý hậu kỳ.
Ví dụ về dữ liệu đầu ra
Truy vấn trả về một bảng BigQuery tiêu chuẩn có điểm tuỳ chỉnh và suy luận của mô hình.
| id | tên | family_friendliness_score | suy luận |
|---|---|---|---|
| 1 | The Downtowner | 5,5 | Số lượng tiện nghi tuyệt vời (công viên, nhà hàng), đáp ứng các chỉ số định lượng. Tuy nhiên, dữ liệu định tính cho thấy tiếng ồn quá mức vào cuối tuần và tập trung mạnh vào cuộc sống về đêm, mâu thuẫn trực tiếp với nhu cầu yên tĩnh của người dùng mục tiêu. |
| 2 | Suburban Oasis | 9,8 | Dữ liệu định lượng vượt trội kết hợp với nội dung mô tả ("đường phố yên tĩnh, rợp bóng cây") hoàn toàn phù hợp với hồ sơ gia đình mục tiêu. Các đối tượng sửa đổi tích cực cao dẫn đến điểm gần như hoàn hảo. |
Quy trình này cho phép bạn cung cấp điểm được cá nhân hoá cao, dễ hiểu và phù hợp với từng người dùng, tất cả trong một truy vấn SQL.
4. Trực quan hoá điểm của bạn trên bản đồ
BigQuery Studio bao gồm tính năng trực quan hoá bản đồ tích hợp cho mọi kết quả truy vấn có chứa cột GEOGRAPHY. Vì truy vấn của chúng ta xuất ra cột location, nên bạn có thể trực quan hoá điểm của mình ngay lập tức.
Việc nhấp vào thẻ Visualization sẽ hiển thị bản đồ và trình đơn thả xuống Data Column kiểm soát điểm vị trí để trực quan hoá. Trong ví dụ này, normalized_pet_score được trực quan hoá từ ví dụ Lựa chọn 1. Xin lưu ý rằng nhiều địa điểm đã được thêm vào bảng apartment_listings cho ví dụ này.
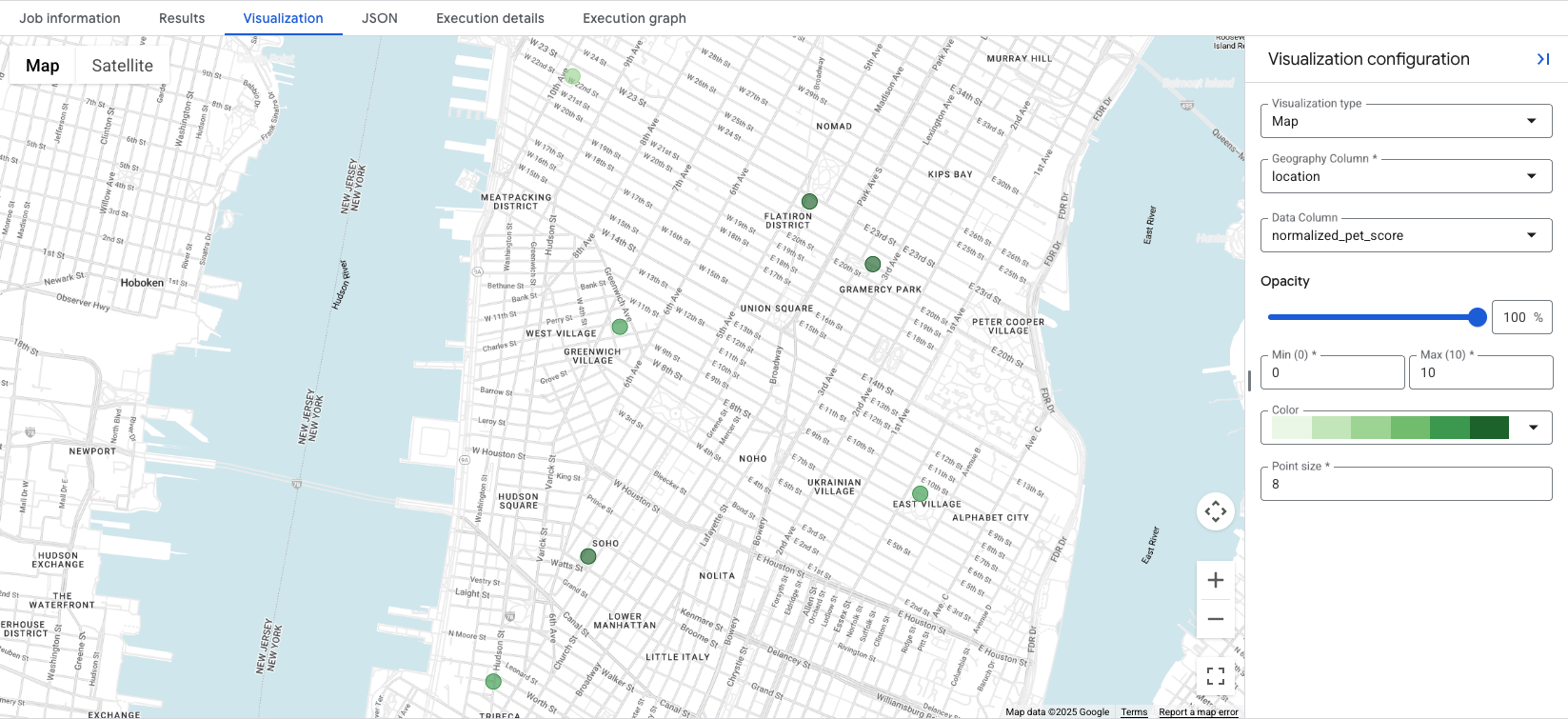
Việc trực quan hoá dữ liệu cho thấy trong nháy mắt các địa điểm phù hợp nhất cho điểm đã tạo, với các vòng tròn màu xanh lục đậm hơn đại diện cho các địa điểm có normalized_pet_score cao hơn trong trường hợp này. Để biết thêm các lựa chọn trực quan hoá dữ liệu Thông tin chi tiết về địa điểm, hãy xem phần Trực quan hoá kết quả truy vấn.
Kết luận
Giờ đây, bạn đã có một phương pháp mạnh mẽ và có thể lặp lại để tạo điểm vị trí chi tiết. Bắt đầu với các địa điểm, bạn đã tạo một truy vấn SQL duy nhất trong BigQuery để tìm các địa điểm ở gần bằng ST_DWITHIN, lọc các địa điểm đó theo các thuộc tính nâng cao như good_for_children và allows_dogs, đồng thời tổng hợp kết quả bằng COUNTIF. Bằng cách áp dụng trọng số tuỳ chỉnh và chuẩn hoá kết quả, bạn đã tạo ra một điểm duy nhất, thân thiện với người dùng, mang lại thông tin chi tiết sâu sắc, có thể hành động. Bạn có thể áp dụng trực tiếp mẫu này để chuyển đổi dữ liệu vị trí thô thành một lợi thế cạnh tranh đáng kể.
Hành động tiếp theo
Giờ đến lượt bạn xây dựng. Hướng dẫn này cung cấp một mẫu. Bạn có thể sử dụng dữ liệu đa dạng thức có trong giản đồ Thông tin chi tiết về địa điểm để tạo các điểm số cần thiết nhất cho trường hợp sử dụng của mình. Hãy cân nhắc các điểm khác mà bạn có thể tạo:
- "Điểm cuộc sống về đêm": Kết hợp các bộ lọc cho
primary_type(bar,night_club),price_levelvà giờ mở cửa muộn để tìm những khu vực sôi động nhất sau khi trời tối. - "Điểm thể dục và sức khoẻ": Đếm
gyms,parksvàhealth_food_storesở gần đó, đồng thời lọc các nhà hàng cóserves_vegetarian_foodđể tính điểm cho các địa điểm dành cho người dùng quan tâm đến sức khoẻ. - "Điểm lý tưởng cho người đi làm": Tìm các địa điểm có mật độ cao các địa điểm ở gần đó để giúp những người dùng coi trọng khả năng tiếp cận phương tiện giao thông.
transit_stationparking
Người đóng góp
Henrik Valve | DevX Kỹ sư