
Genel Bakış
Standart konum verileri yakındaki yerleri size söyleyebilir ancak genellikle daha önemli olan "Bu bölge benim için ne kadar uygun?" sorusunu yanıtlayamaz. Kullanıcılarınızın ihtiyaçları farklılık gösterir. Küçük çocukları olan bir aile, köpeği olan genç bir profesyonele kıyasla farklı önceliklere sahiptir. Kullanıcıların güvenle karar vermesine yardımcı olmak için bu özel ihtiyaçları yansıtan analizler sağlamanız gerekir. Özel konum puanı, bu değeri sunmak ve önemli ölçüde farklılaşan bir kullanıcı deneyimi oluşturmak için güçlü bir araçtır.
Bu belgede, BigQuery'deki Places Insights veri kümesini kullanarak özel, çok yönlü konum puanlarının nasıl oluşturulacağı açıklanmaktadır. ÖY verilerini anlamlı metriklere dönüştürerek gayrimenkul, perakende veya seyahat uygulamalarınızı zenginleştirebilir ve kullanıcılarınıza ihtiyaç duydukları alakalı bilgileri sağlayabilirsiniz. Ayrıca, konum puanlarınızı hesaplamak için güçlü bir yöntem olarak BigQuery'de üretken yapay zekayı kullanma seçeneği de sunuyoruz.
Özel Puanlarla İşletme Değerini Artırma
Aşağıdaki örneklerde, uygulamanızı geliştirmek için ham konum verilerini nasıl güçlü ve kullanıcı odaklı metriklere dönüştürebileceğiniz gösterilmektedir.
- Gayrimenkul geliştiriciler, alıcıların ve kiracıların yaşam tarzlarına uygun mükemmel mahalleyi seçmelerine yardımcı olmak için "Aile Dostu Puanı" veya "İş Yeri Yakınlığı Puanı" oluşturabilir. Bu sayede kullanıcı etkileşimi artar, daha kaliteli potansiyel müşteriler elde edilir ve dönüşümler daha hızlı gerçekleşir.
- Seyahat ve konaklama mühendisleri, gezginlerin tatil tarzlarına uygun bir otel seçmelerine yardımcı olmak için "Gece Hayatı Puanı" veya "Gezgin Cenneti Puanı" oluşturabilir. Bu sayede rezervasyon oranları ve müşteri memnuniyeti artırılabilir.
- Perakende analistleri, yakındaki tamamlayıcı işletmelere göre yeni bir spor salonu veya sağlıklı gıda mağazası için en uygun konumu belirlemek amacıyla "Fitness ve Sağlık Puanı" oluşturabilir. Bu sayede doğru kullanıcı demografisini hedefleme potansiyeli en üst düzeye çıkarılır.
Bu kılavuzda, doğrudan BigQuery'de Places verilerini kullanarak her türlü özel konum puanını oluşturmaya yönelik esnek ve üç bölümlü bir metodoloji öğreneceksiniz. Bu kalıbı, iki farklı örnek puan oluşturarak açıklayacağız: Aile Dostu Puanı ve Evcil Hayvan Sahipleri İçin Cennet Puanı. Bu yaklaşım, yer sayılarının ötesine geçmenize ve Places Insights veri kümesindeki zengin ve ayrıntılı özelliklerden yararlanmanıza olanak tanır. Kullanıcılarınız için gelişmiş ve anlamlı metrikler oluşturmak üzere çalışma saatleri, bir yerin çocuklar için uygun olup olmadığı veya köpeklerin kabul edilip edilmediği gibi bilgileri kullanabilirsiniz.
Çözüm iş akışı
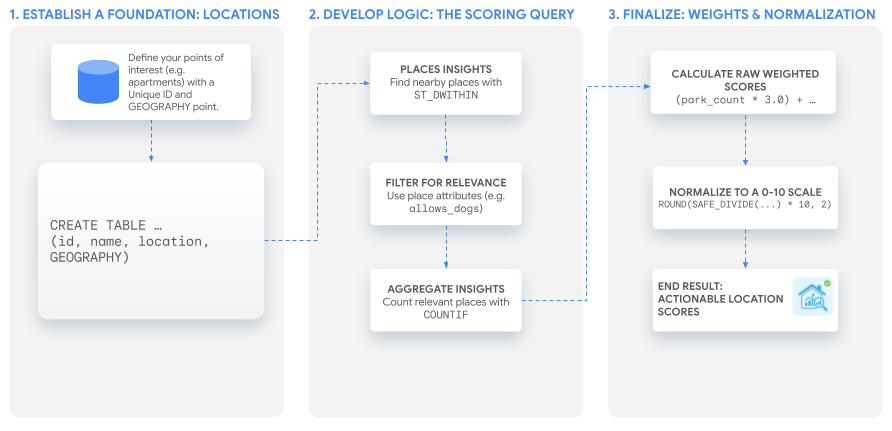
Bu eğitimde, herhangi bir kullanım alanına uyarlayabileceğiniz özel bir puan oluşturmak için tek ve güçlü bir SQL sorgusu kullanılmaktadır. Varsayımsal bir apartman listeleri grubu için iki örnek puanımızı oluşturarak bu süreci adım adım inceleyeceğiz.
Bu iş akışını etkileşimli bir ortamda keşfetmek için aşağıdaki not defterini çalıştırın. Bu videoda, konum puanı oluşturmak için BigQuery'deki AI.GENERATE işlevinin nasıl kullanılacağı gösterilmektedir.
 Kaynağı GitHub'da görüntüle
Kaynağı GitHub'da görüntüle
Ön koşullar
Başlamadan önce, Yerler Analizleri'ni ayarlamak için bu talimatları uygulayın.
1. Temel oluşturma: İlgilenilen konumlarınız
Puan oluşturabilmek için analiz etmek istediğiniz konumların listesi gerekir. İlk adım, bu verilerin BigQuery'de tablo olarak bulunduğundan emin olmaktır.
Önemli olan, her konum için benzersiz bir tanımlayıcıya ve koordinatlarını depolayan bir GEOGRAPHY
sütuna sahip olmaktır.
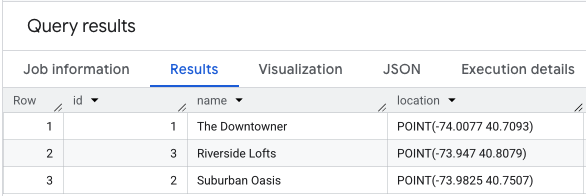
Aşağıdaki gibi bir sorguyla puanlanacak konumların tablosunu oluşturup doldurabilirsiniz:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
Konum verilerinizde SELECT * işlemi yapıldığında sonuç buna benzer görünür.
2. Temel Mantığı Geliştirme: Puanlama Sorgusu
Konumlarınız belirlendikten sonraki adım, özel puanınızla alakalı yakındaki yerleri bulmak, filtrelemek ve saymaktır. Tüm bu işlemler tek bir SELECT ifade içinde yapılır.
Coğrafi arama ile yakındaki yerleri bulma
Öncelikle, Places Insights veri kümesindeki tüm yerleri, konumlarınızın her birine belirli bir mesafede olacak şekilde bulmanız gerekir. Bu işlem için BigQuery işlevi
ST_DWITHIN idealdir. 800 metre yarıçapındaki tüm yerleri bulmak için JOIN tablomuz ile apartment_listings tablosu arasında places_insights işlemi yapacağız. LEFT JOIN, yakında eşleşen yerler bulunmasa bile tüm orijinal konumlarınızın sonuçlara dahil edilmesini sağlar.
Gelişmiş özelliklerle alaka düzeyine göre filtreleme
Puanın soyut kavramını somut veri filtrelerine dönüştürdüğünüz yer burasıdır. İki örnek puanımız için ölçütler farklıdır:
- "Aile Dostu Puanı" için çocuklara uygun parklar, müzeler ve restoranlar önemlidir.
- "Evcil hayvan sahipleri için cennet puanı" için parklar, veteriner klinikleri, evcil hayvan mağazaları ve köpeklere izin veren restoran veya kafeler önemlidir.
Bu özellikleri doğrudan sorgunuzun WHERE ifadesinde filtreleyebilirsiniz.
Her Konum İçin Analizleri Toplama
Son olarak, her apartman dairesi için kaç tane alakalı Yer bulduğunuzu saymanız gerekir. GROUP BY ifadesi sonuçları toplar ve COUNTIF işlevi, puanlarımızın her biri için belirli ölçütlerle eşleşen yerleri sayar.
Aşağıdaki sorgu bu üç adımı birleştirerek her iki puanın ham sayılarını tek bir geçişte hesaplar:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Bu sorgunun sonucu aşağıdaki gibi olur.
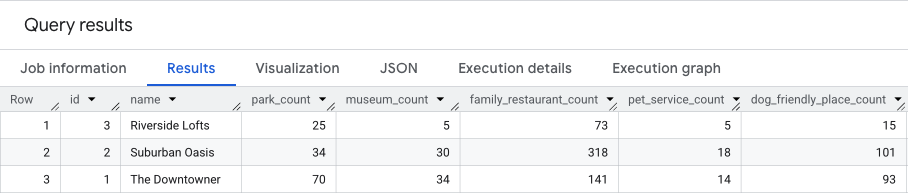
Bu sonuçları bir sonraki bölümde kullanacağız.
3. Puanı oluşturma
Artık her konum için yer sayısını ve her yer türü için ağırlıklandırmayı bildiğinize göre özel konum puanını oluşturabilirsiniz. Bu bölümde iki seçeneği ele alacağız: BigQuery'de kendi özel hesaplamanızı kullanma veya BigQuery'de üretken yapay zeka işlevlerini kullanma.
1. seçenek: BigQuery'de kendi özel hesaplamanızı kullanma
Önceki adımdaki ham sayılar faydalı bilgiler sunar ancak hedef, tek bir kullanıcı dostu puan elde etmektir. Son adım, bu sayıları ağırlıklar kullanarak birleştirmek ve ardından sonucu 0-10 ölçeğinde normalleştirmektir.
Özel Ağırlıklar Uygulama Ağırlıklarınızı seçmek hem sanat hem de bilimdir. Bu hedefler, işletme önceliklerinizi veya kullanıcılarınız için en önemli olduğunu düşündüğünüz şeyleri yansıtmalıdır. "Aile dostu" puanı için bir parkın müzeye kıyasla iki kat daha önemli olduğuna karar verebilirsiniz. En iyi varsayımlarınızla başlayın ve kullanıcı geri bildirimlerimize göre yineleyin.
Puanı Normalleştirme Aşağıdaki sorguda iki Ortak Tablo İfadesi (CTE) kullanılmaktadır: Birincisi, ham sayıları daha önce olduğu gibi hesaplar, ikincisi ise ağırlıklı puanları hesaplar. Son SELECT ifadesi, ağırlıklı puanlarda minimum-maksimum normalleştirme gerçekleştirir. Haritada veri görselleştirmeyi etkinleştirmek için örnek location tablosunun apartment_listings sütunu çıkış olarak verilir.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Sorgunun sonuçları aşağıdakine benzer olacaktır. Son iki sütun, normalleştirilmiş puanlardır.

Normalleştirilmiş puanı anlama
Bu son normalleştirme adımının neden bu kadar değerli olduğunu anlamak önemlidir.
Ağırlıklı ham puanlar, konumlarınızın kentsel yoğunluğuna bağlı olarak 0 ile çok büyük bir sayı arasında değişebilir. 500 puanı, bağlamı olmayan bir kullanıcı için anlamsızdır.
Normalleştirme, bu soyut sayıları göreceli bir sıralamaya dönüştürür. Sonuçları 0 ile 10 arasında ölçeklendirerek puan, her konumun belirli veri kümenizdeki diğer konumlarla nasıl karşılaştırıldığını net bir şekilde gösterir:
- En yüksek ham puana sahip konuma 10 puan atanır ve bu konum, mevcut gruptaki en iyi seçenek olarak işaretlenir.
- En düşük ham puana sahip konuma 0 puan atanır. Bu konum, karşılaştırma için temel alınır. Bu, konumda hiç imkan olmadığı anlamına gelmez. Diğer seçeneklere kıyasla en az uygun olan seçenektir.
- Diğer tüm puanlar orantılı olarak bu iki puan arasında yer alır. Böylece kullanıcılarınız, seçeneklerini bir bakışta karşılaştırabilir.
2. seçenek: AI.GENERATE işlevini kullanma (Gemini)
Sabit bir matematiksel formül kullanmak yerine, özel konum puanlarını doğrudan SQL iş akışınızda hesaplamak için BigQuery AI.GENERATE işlevini kullanabilirsiniz.
1. seçenek, tamamen olanak sayısına dayalı nicel puanlama için mükemmel olsa da nitel verileri kolayca hesaba katamaz. AI.GENERATE işlevi, Places Insights sorgunuzdaki sayıları, yapılandırılmamış verilerle (ör. daire listelemesinin metin açıklaması ("Bu konum aileler için uygundur ve gece sessizdir") veya belirli kullanıcı profili tercihleri ("Bu kullanıcı ailesi için rezervasyon yapıyor ve merkezi bir konumda sessiz bir bölgeyi tercih ediyor")) birleştirmenize olanak tanır. Bu sayede, katı bir sayımın gözden kaçırabileceği ayrıntıları (ör. yüksek imkan yoğunluğuna sahip ancak "çocuklar için çok gürültülü" olarak da tanımlanan bir konum) tespit eden daha ayrıntılı bir puan oluşturabilirsiniz.
İstemi oluşturma
Bu işlevi kullanmak için toplama sonuçları (2. adımda) doğal dil istemine dönüştürülür. Bu, SQL'de veri sütunlarını modelle ilgili talimatlarla birleştirerek dinamik olarak yapılabilir.
Aşağıdaki sorguda, her satır için bir istem oluşturmak üzere insight_counts ile dairenin metin açıklaması birleştirilir. Puanlamaya rehberlik etmek için hedef kullanıcı profili de tanımlanır.
Puanı SQL ile oluşturma
Aşağıdaki sorgu, işlemin tamamını BigQuery'de gerçekleştirir. Otomatik etiketleme:
- Yer sayılarını toplar (2. adımda açıklandığı gibi).
- Her konum için bir istem oluşturur.
- Gemini modelini kullanarak istemi analiz etmek için
AI.GENERATEişlevini çağırır. - Sonucu, uygulamanızda kullanıma hazır yapılandırılmış bir biçime ayrıştırır.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Yapılandırmayı anlama
- Maliyet Bilinci: Bu işlev, girişinizi bir Gemini modeline iletir ve her çağrıldığında Vertex AI'da ücretlendirilir. Çok sayıda konum analiz ediliyorsa (ör. binlerce daire listelemesi), veri kümesini önce en alakalı adaylara göre filtrelemeniz önerilir. Maliyetleri en aza indirme hakkında daha fazla bilgi için En İyi Uygulamalar başlıklı makaleyi inceleyin.
endpoint: Bu örnekte hız ve maliyet verimliliğine öncelik vermek içingemini-flash-latestbelirtilmiştir. Ancak ihtiyaçlarınıza en uygun modeli seçebilirsiniz. Farklı sürümleri (ör. daha karmaşık muhakeme görevleri için Gemini Pro) denemek ve kullanım alanınıza en uygun olanı bulmak için Gemini modelleri dokümanlarına bakın.output_schema: Ham metni ayrıştırmak yerine bir şema uygulanır (puan içinFLOAT64, gerekçe içinSTRING). Bu sayede, çıktı, uygulamanızda veya görselleştirme araçlarınızda sonradan işleme gerek kalmadan hemen kullanılabilir.
Örnek Çıkış
Sorgu, özel puan ve modelin gerekçesini içeren standart bir BigQuery tablosu döndürür.
| id | ad | family_friendliness_score | akıl yürütme |
|---|---|---|---|
| 1 | Şehir Merkezi Sakini | 5.5 | Mükemmel olanak sayısı (parklar, restoranlar) ve nicel metrikleri karşılıyor. Ancak nitel veriler, hafta sonu gürültüsünün fazla olduğunu ve gece hayatına odaklanıldığını gösteriyor. Bu durum, hedef kullanıcının sessizlik ihtiyacıyla doğrudan çelişiyor. |
| 2 | Suburban Oasis | 9,8 | Hedef aile profiliyle mükemmel şekilde uyumlu bir açıklamayla ("sakin, ağaçlıklı sokak") birlikte sunulan olağanüstü nicel veriler. Yüksek pozitif değiştiriciler, neredeyse mükemmel bir puanla sonuçlanır. |
Bu prosedür, tek bir SQL sorgusu içinde her bir kullanıcıya göre anlaşılır ve kişiye özel olacak şekilde son derece kişiselleştirilmiş puanlama sunmanıza olanak tanır.
4. Puanlarınızı haritada görselleştirme
BigQuery Studio, GEOGRAPHY sütunu içeren tüm sorgu sonuçları için entegre bir harita görselleştirmesi içerir. Sorgumuz location sütununu çıkardığı için puanlarınızı hemen görselleştirebilirsiniz.
Visualization sekmesini tıkladığınızda harita açılır ve Data Column
açılır listesi, görselleştirilecek konum puanını kontrol eder. Bu örnekte, 1. Seçenek örneğindeki
normalized_pet_score görselleştirilmiştir. Bu örnekte apartment_listings tablosuna daha fazla konum eklendiğini unutmayın.
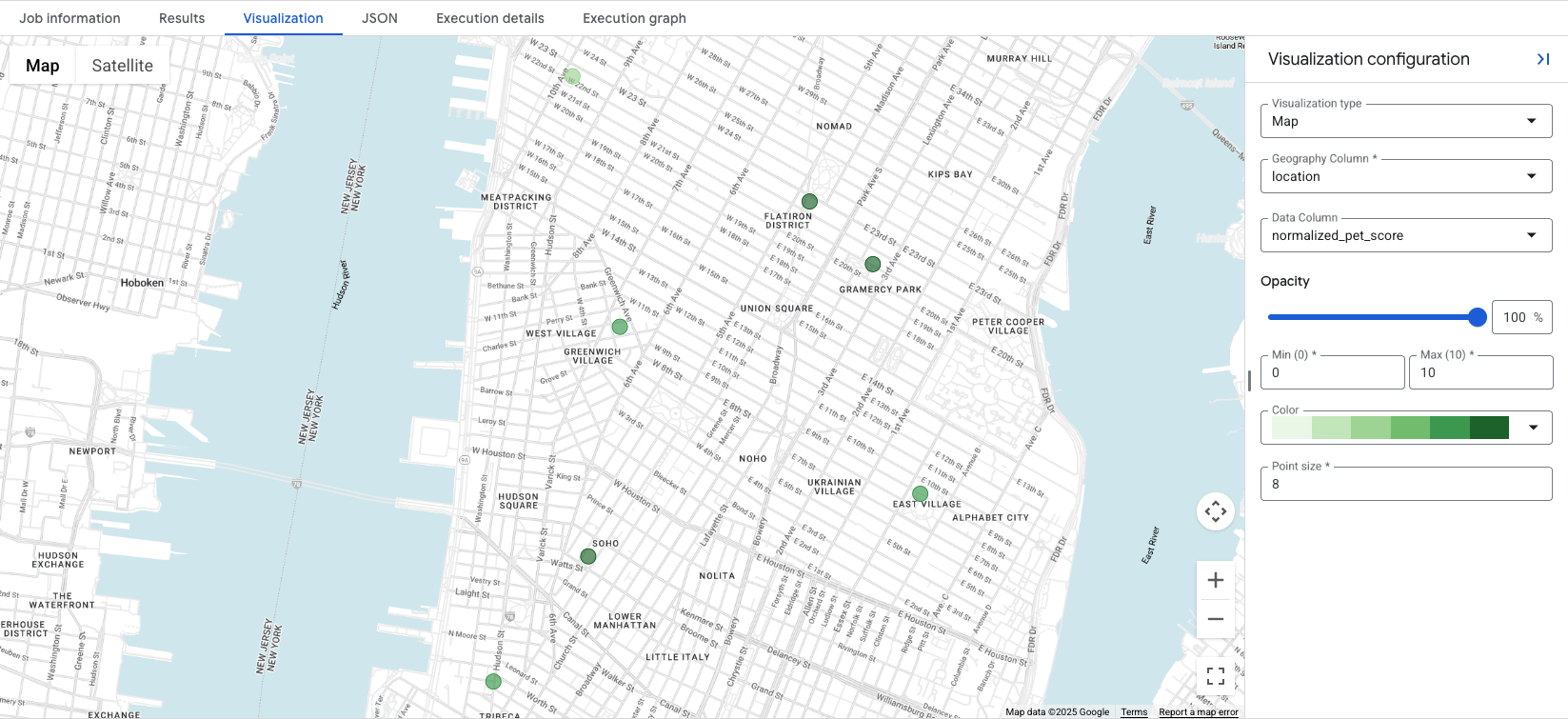
Verilerin görselleştirilmesi, oluşturulan puan için en uygun konumları bir bakışta gösterir. Daha koyu yeşil daireler, bu durumda daha yüksek bir normalized_pet_score değerine sahip konumları temsil eder. Daha fazla Places Insights verisi görselleştirme seçeneği için Sorgu sonuçlarını görselleştirme başlıklı makaleyi inceleyin.
Sonuç
Artık ayrıntılı konum puanları oluşturmak için güçlü ve tekrarlanabilir bir metodolojiye sahipsiniz. Konumlarınızdan başlayarak BigQuery'de ST_DWITHIN ile yakındaki yerleri bulan, good_for_children ve allows_dogs gibi gelişmiş özelliklere göre filtreleyen ve sonuçları COUNTIF ile toplayan tek bir SQL sorgusu oluşturdunuz. Özel ağırlıklar uygulayarak ve sonucu normalleştirerek, derin ve uygulanabilir analizler sunan tek bir kullanıcı dostu puan elde ettiniz. Bu kalıbı doğrudan uygulayarak ham konum verilerini önemli bir rekabet avantajına dönüştürebilirsiniz.
Sonraki İşlemler
Şimdi geliştirme sırası sizde. Bu eğitimde bir şablon sunulmaktadır. Kullanım alanınız için en gerekli puanları oluşturmak üzere Places Insights şemasında bulunan zengin verilerden yararlanabilirsiniz. Oluşturabileceğiniz diğer puanlar:
- "Gece Hayatı Puanı":
primary_type(bar,night_club),price_levelve gece geç saatlere kadar açık olma filtrelerini birleştirerek karanlık çöktükten sonra en hareketli bölgeleri bulun. - "Fitness ve Sağlıklı Yaşam Puanı": Yakındaki
gyms,parksvehealth_food_storescihazlarını sayın ve sağlıklı yaşam konusunda bilinçli kullanıcılar için konumları puanlamak üzere restoranlarıserves_vegetarian_foodolanlara göre filtreleyin. - "İşe Gidiş Geliş Hayali Puanı": Ulaşım erişimine önem veren kullanıcılara yardımcı olmak için yakındaki
transit_stationveparkingyerlerin yoğun olduğu konumları bulun.
Katkıda bulunanlar
Henrik Valve | DevX Engineer