
Обзор
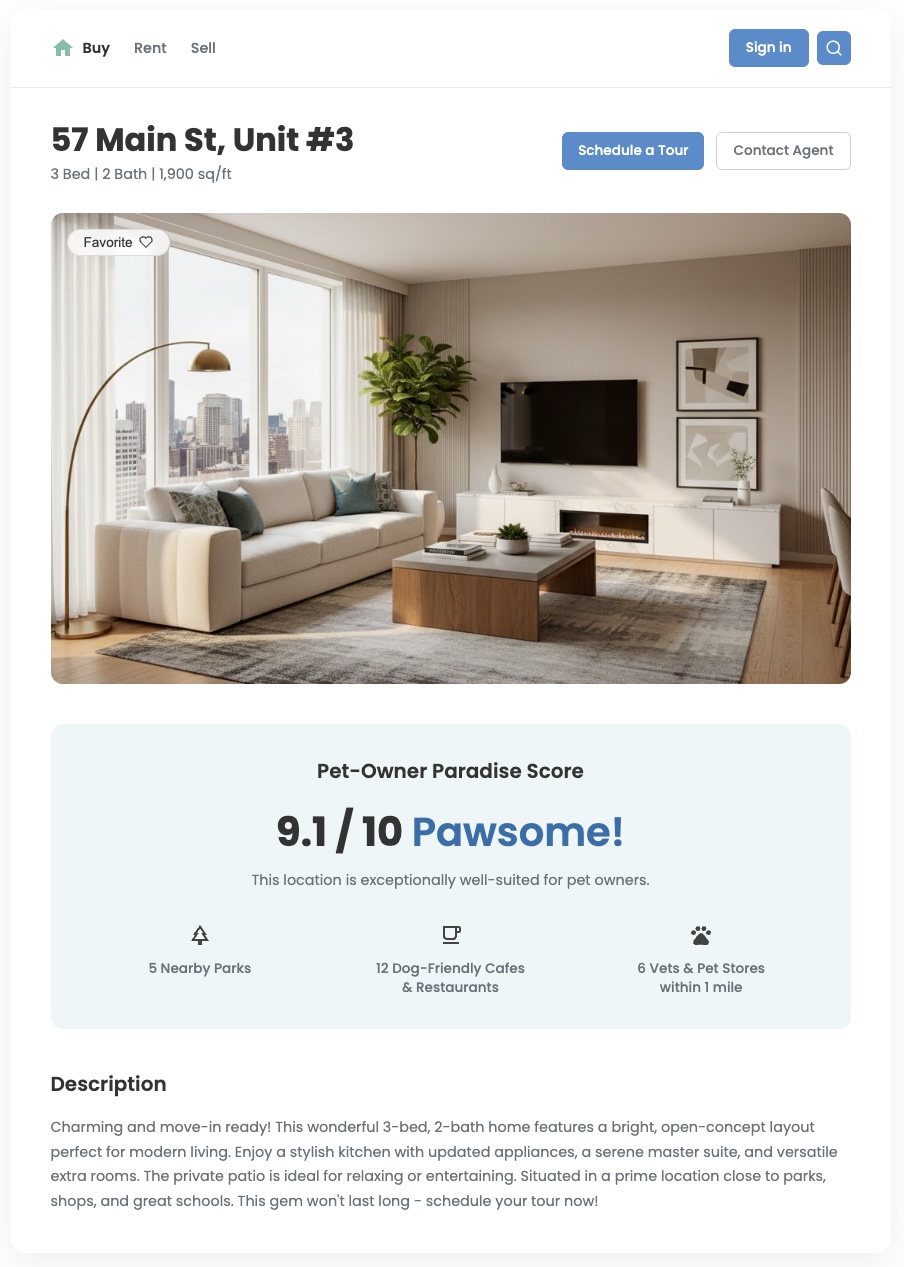
Стандартные данные о местоположении могут показать, что находится поблизости, но часто не отвечают на более важный вопрос: «Насколько этот район подходит мне ?» Потребности ваших пользователей многогранны. У семьи с маленькими детьми другие приоритеты, чем у молодого специалиста с собакой. Чтобы помочь им принимать уверенные решения, вам необходимо предоставлять информацию, отражающую эти специфические потребности. Пользовательская оценка местоположения — это мощный инструмент, позволяющий обеспечить эту ценность и создать значительно отличающийся пользовательский опыт.
В этом документе описывается, как создавать пользовательские многофакторные оценки местоположения с использованием набора данных Places Insights в BigQuery. Преобразуя данные о POI в значимые метрики, вы можете обогатить свои приложения для недвижимости, розничной торговли или туризма и предоставить пользователям необходимую им информацию. Мы также предлагаем возможность использования генеративного ИИ в BigQuery в качестве мощного способа вычисления оценок местоположения.
Повышайте ценность бизнеса с помощью персонализированных показателей.
Приведенные ниже примеры иллюстрируют, как можно преобразовать необработанные данные о местоположении в мощные, ориентированные на пользователя метрики для улучшения вашего приложения.
- Застройщики могут создать «Рейтинг дружелюбности к семьям» или «Рейтинг идеального места для тех, кто ездит на работу в город», чтобы помочь покупателям и арендаторам выбрать идеальный район, соответствующий их образу жизни, что приведет к повышению вовлеченности пользователей, получению более качественных лидов и ускорению конверсии.
- Специалисты в сфере туризма и гостиничного бизнеса могут создать «Рейтинг ночной жизни» или «Рейтинг туристического рая», чтобы помочь путешественникам выбрать отель, соответствующий их стилю отдыха, тем самым повышая процент бронирований и удовлетворенность клиентов.
- Аналитики розничной торговли могут сформировать «индекс фитнеса и здорового образа жизни», чтобы определить оптимальное местоположение для нового тренажерного зала или магазина здорового питания, исходя из наличия поблизости смежных предприятий, что позволит максимально эффективно ориентироваться на нужную целевую аудиторию.
В этом руководстве вы узнаете о гибкой трехэтапной методологии построения любых пользовательских оценок местоположения с использованием данных Places непосредственно в BigQuery. Мы проиллюстрируем этот подход на примере двух различных оценок: оценки «Удобство для семейного отдыха» и оценки «Рай для владельцев домашних животных» . Такой подход позволяет выйти за рамки подсчета мест и воспользоваться преимуществами богатых, подробных атрибутов набора данных Places Insights. Вы можете использовать такую информацию, как часы работы, подходит ли место для детей или разрешено ли там находиться с собаками, для создания сложных и значимых показателей для ваших пользователей.
Рабочий процесс решения
В этом руководстве используется один мощный SQL-запрос для создания пользовательской оценки, которую можно адаптировать к любому сценарию. Мы пройдемся по этому процессу, создав две примерные оценки для гипотетического набора объявлений о сдаче квартир в аренду.
Чтобы изучить этот рабочий процесс в интерактивной среде, запустите следующий блокнот. Он демонстрирует, как использовать функцию AI.GENERATE в BigQuery для создания оценки местоположения.
 Посмотреть исходный код на GitHub
Посмотреть исходный код на GitHubПредварительные требования
Прежде чем начать, выполните следующие действия для настройки Places Insights.
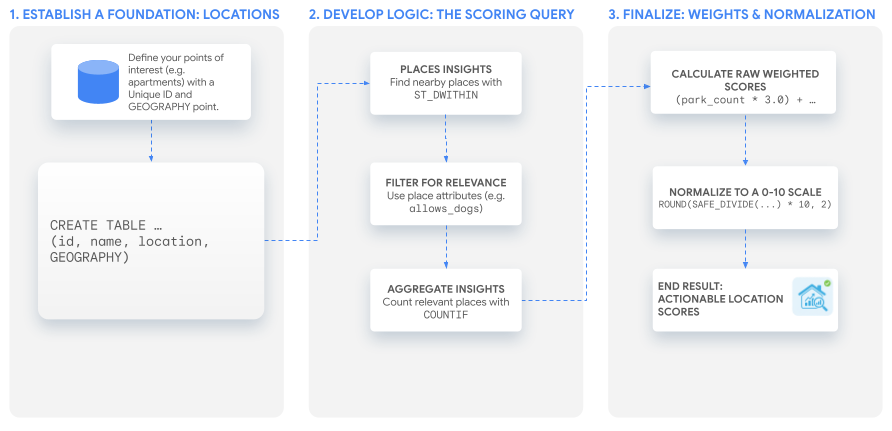
1. Создайте фонд: интересующие вас места.
Прежде чем создавать оценки, вам нужен список мест, которые вы хотите проанализировать. Первый шаг — убедиться, что эти данные существуют в виде таблицы в BigQuery. Ключевым моментом является наличие уникального идентификатора для каждого места и столбца GEOGRAPHY , в котором хранятся его координаты.
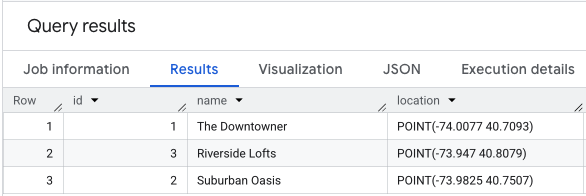
Вы можете создать и заполнить таблицу местоположений для оценки с помощью такого запроса:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
Выполнение запроса SELECT * к данным о вашем местоположении будет выглядеть примерно так.
2. Разработка основной логики: Запрос для оценки результатов.
После определения местоположений следующим шагом будет поиск, фильтрация и подсчет ближайших мест, имеющих отношение к вашему пользовательскому показателю. Все это делается в рамках одного оператора SELECT .
Найдите то, что находится поблизости, с помощью геопространственного поиска.
Для начала вам нужно найти все места из набора данных Places Insights, которые находятся в пределах определенного расстояния от каждого из ваших местоположений. Функция BigQuery ST_DWITHIN идеально подходит для этого. Мы выполним JOIN таблиц apartment_listings и places_insights , чтобы найти все места в радиусе 800 метров. LEFT JOIN гарантирует, что все ваши исходные местоположения будут включены в результаты, даже если поблизости не найдено ни одного подходящего места.
Фильтрация по релевантности с использованием расширенных атрибутов.
Здесь вы переводите абстрактное понятие оценки в конкретные фильтры данных. Для наших двух примеров оценок критерии разные:
- При расчете "Рейтинга семейной привлекательности" мы учитываем, насколько парки, музеи и рестораны подходят именно для детей.
- Для составления рейтинга "Рай для владельцев домашних животных" нас интересуют парки, ветеринарные клиники, зоомагазины, а также любые рестораны и кафе, где разрешено находиться с собаками.
Вы можете фильтровать данные по этим конкретным атрибутам непосредственно в условии WHERE вашего запроса.
Обобщите данные по каждому местоположению.
Наконец, вам нужно подсчитать, сколько подходящих вариантов вы нашли для каждой квартиры. Предложение GROUP BY агрегирует результаты, а функция COUNTIF подсчитывает места, соответствующие конкретным критериям для каждого из наших показателей.
Приведенный ниже запрос объединяет эти три шага, вычисляя исходные значения для обоих показателей за один проход:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Результат этого запроса будет примерно таким.
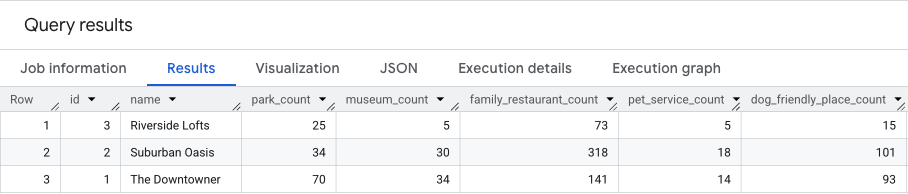
В следующем разделе мы будем развивать эти результаты.
3. Создайте партитуру
Теперь, когда у вас есть количество мест и весовые коэффициенты для каждого типа мест в каждом местоположении, вы можете сгенерировать пользовательский показатель местоположения. В этом разделе мы обсудим два варианта: использование собственного пользовательского расчета в BigQuery или использование функций генеративного искусственного интеллекта (ИИ) в BigQuery .
Вариант 1: Используйте собственные вычисления в BigQuery.
Исходные данные, полученные на предыдущем этапе, весьма информативны, но цель состоит в том, чтобы получить единый, удобный для пользователя показатель. Последний шаг – объединение этих данных с использованием весовых коэффициентов и последующая нормализация результата по шкале от 0 до 10.
Применение пользовательских весовых коэффициентов. Выбор весовых коэффициентов — это одновременно искусство и наука. Они должны отражать приоритеты вашего бизнеса или то, что вы считаете наиболее важным для ваших пользователей. Например, для оценки «Удобство для семейного отдыха» вы можете решить, что парк вдвое важнее музея. Начните с ваших лучших предположений и корректируйте их на основе отзывов пользователей.
Нормализация оценок. В приведенном ниже запросе используются два общих табличных выражения (CTE): первое вычисляет исходные значения, как и прежде, а второе вычисляет взвешенные оценки. Затем заключительное выражение SELECT выполняет нормализацию взвешенных оценок по принципу min-max. Выводится столбец location из таблицы apartment_listings , что позволяет визуализировать данные на карте.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Результаты запроса будут выглядеть примерно так, как показано ниже. Последние два столбца содержат нормализованные значения.

Разберитесь в нормализованном показателе.
Важно понимать, почему этот заключительный этап нормализации так важен. Исходные взвешенные оценки могут варьироваться от 0 до потенциально очень больших чисел в зависимости от плотности городской застройки в ваших районах. Оценка в 500 бессмысленна для пользователя без контекста.
Нормализация преобразует эти абстрактные числа в относительный рейтинг. Масштабируя результаты от 0 до 10, оценка наглядно показывает, как каждое местоположение соотносится с другими в вашем конкретном наборе данных:
- Местоположение с наивысшим исходным баллом получает оценку 10 , что означает, что оно является лучшим вариантом в текущем наборе.
- Местам с наименьшим исходным баллом присваивается оценка 0 , что делает их базовыми для сравнения. Это не означает, что в данном месте нет никаких удобств, а скорее, что оно наименее подходит по сравнению с другими оцениваемыми вариантами.
- Все остальные показатели находятся пропорционально в промежуточном диапазоне, предоставляя пользователям понятный и интуитивно понятный способ быстро сравнить доступные варианты.
Вариант 2: Используйте функцию AI.GENERATE (Gemini)
В качестве альтернативы использованию фиксированной математической формулы вы можете использовать функцию BigQuery AI.GENERATE для вычисления пользовательских оценок местоположения непосредственно в вашем рабочем процессе SQL.
Хотя Вариант 1 отлично подходит для чисто количественной оценки на основе количества удобств, он не может легко учитывать качественные данные. Функция AI.GENERATE позволяет объединить данные из вашего запроса Places Insights с неструктурированными данными, такими как текстовое описание квартиры (например, «Это место подходит для семей, и ночью здесь тихо») или конкретные предпочтения пользователя (например, «Этот пользователь бронирует жилье для семьи и предпочитает тихий район в центре города»). Это позволяет получить более точную оценку, которая выявляет нюансы, которые может упустить строгий подсчет, например, место с высокой плотностью удобств, но также описанное как «слишком шумное для детей».
Составьте подсказку
Для использования этой функции результаты агрегации (из шага 2) форматируются в текстовый формат на естественном языке. Это можно сделать динамически в SQL путем объединения столбцов данных с инструкциями для модели.
В приведенном ниже запросе insight_counts объединяются с текстовым описанием квартиры для создания запроса для каждой строки. Также определен целевой профиль пользователя для определения критериев оценки.
Сгенерируйте результат с помощью SQL.
Следующий запрос выполняет всю операцию в BigQuery. Он:
- Обобщает данные о количестве посещенных мест (как описано в шаге 2).
- Создает подсказку для каждого местоположения.
- Вызывает функцию
AI.GENERATEдля анализа запроса с использованием модели Gemini. - Преобразует результат в структурированный формат, готовый для использования в вашем приложении.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Разберитесь в конфигурации.
- Учет затрат: Эта функция передает ваши входные данные модели Gemini и влечет за собой расходы в Vertex AI при каждом вызове. Если анализируется большое количество местоположений (например, тысячи объявлений о продаже квартир), рекомендуется сначала отфильтровать набор данных, оставив наиболее подходящие варианты. Для получения более подробной информации о минимизации затрат см. раздел «Рекомендации» .
- В этом примере указана
endpoint:gemini-flash-latestчтобы отдать приоритет скорости и экономичности. Однако вы можете выбрать модель, которая лучше всего соответствует вашим потребностям. См. документацию по моделям Gemini , чтобы поэкспериментировать с различными версиями (например, Gemini Pro для более сложных задач логического вывода) и найти оптимальный вариант для вашего случая. -
output_schema: Вместо анализа необработанного текста используется схема (FLOAT64для оценки иSTRINGдля обоснования). Это гарантирует, что выходные данные будут сразу же пригодны для использования в вашем приложении или инструментах визуализации без постобработки.
Пример выходных данных
Запрос возвращает стандартную таблицу BigQuery с пользовательской оценкой и рассуждениями модели.
| идентификатор | имя | оценка дружелюбности к семьям | рассуждения |
|---|---|---|---|
| 1 | Житель центра города | 5.5 | Отличная инфраструктура (парки, рестораны), соответствующая количественным показателям. Однако качественные данные указывают на чрезмерный уровень шума в выходные дни и сильную ориентацию на ночную жизнь, что напрямую противоречит потребности целевой аудитории в тишине. |
| 2 | Пригородный оазис | 9.8 | Превосходные количественные данные в сочетании с описанием («тихая, обсаженная деревьями улица») идеально соответствуют профилю целевой семьи. Высокие положительные модификаторы приводят к почти идеальному результату. |
Эта процедура позволяет предоставлять высоко персонализированные оценки, понятные и адаптированные к потребностям каждого пользователя, и все это в рамках одного SQL-запроса.
4. Визуализируйте свои результаты на карте.
В BigQuery Studio интегрирована визуализация карты для любого результата запроса, содержащего столбец GEOGRAPHY . Поскольку наш запрос выводит столбец location , вы можете сразу же визуализировать свои результаты.
Нажав на вкладку Visualization , вы откроете карту, а в раскрывающемся списке « Data Column вы сможете выбрать показатель местоположения для визуализации. В этом примере визуализируется показатель normalized_pet_score из примера «Вариант 1» . Обратите внимание, что для этого примера в таблицу apartment_listings были добавлены дополнительные местоположения.
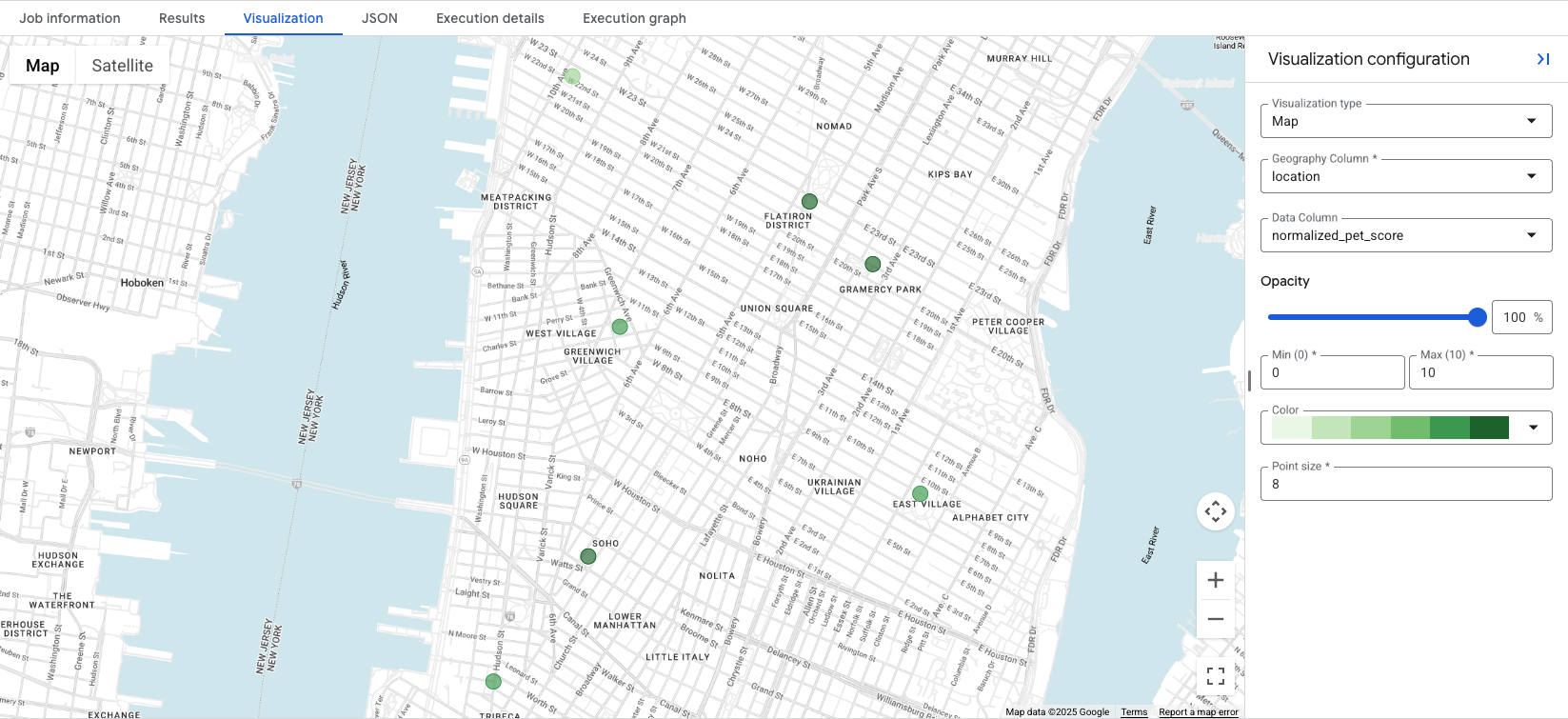
Визуализация данных позволяет с первого взгляда определить наиболее подходящие места для созданного показателя, при этом более темные зеленые круги обозначают места с более высоким значением normalized_pet_score . Дополнительные параметры визуализации данных Places Insights см. в разделе «Визуализация результатов запроса» .
Заключение
Теперь у вас есть мощная и воспроизводимая методология для создания детализированных оценок местоположения. Начав с ваших местоположений, вы создали единый SQL-запрос в BigQuery, который находит ближайшие места с помощью ST_DWITHIN , фильтрует их по расширенным атрибутам, таким как good_for_children и allows_dogs , и агрегирует результаты с помощью COUNTIF . Применив пользовательские веса и нормализовав результат, вы получили единую, удобную для пользователя оценку, которая предоставляет глубокую и полезную информацию для принятия решений. Вы можете напрямую применить этот шаблон для преобразования необработанных данных о местоположении в значительное конкурентное преимущество.
Следующие действия
Теперь ваша очередь создавать. В этом руководстве представлен шаблон. Вы можете использовать обширные данные, доступные в схеме Places Insights, для создания оценок, наиболее необходимых для вашего конкретного случая. Рассмотрите другие варианты оценок, которые вы могли бы создать:
- "Оценка ночной жизни": Комбинируйте фильтры по
primary_type(bar,night_club),price_levelи времени работы в ночное время, чтобы найти самые оживленные районы после наступления темноты. - "Оценка фитнеса и здоровья": Подсчитайте количество расположенных поблизости
gyms,parksиhealth_food_stores, а также отфильтруйте рестораны по наличиюserves_vegetarian_food, чтобы оценить их привлекательность для пользователей, заботящихся о своем здоровье. - "Идеальный показатель для пассажиров общественного транспорта": Найдите места с высокой плотностью расположенных поблизости
transit_stationиparkingмест, чтобы помочь пользователям, которые ценят доступность транспорта.
Авторы
Хенрик Вэлв | Инженер DevX