
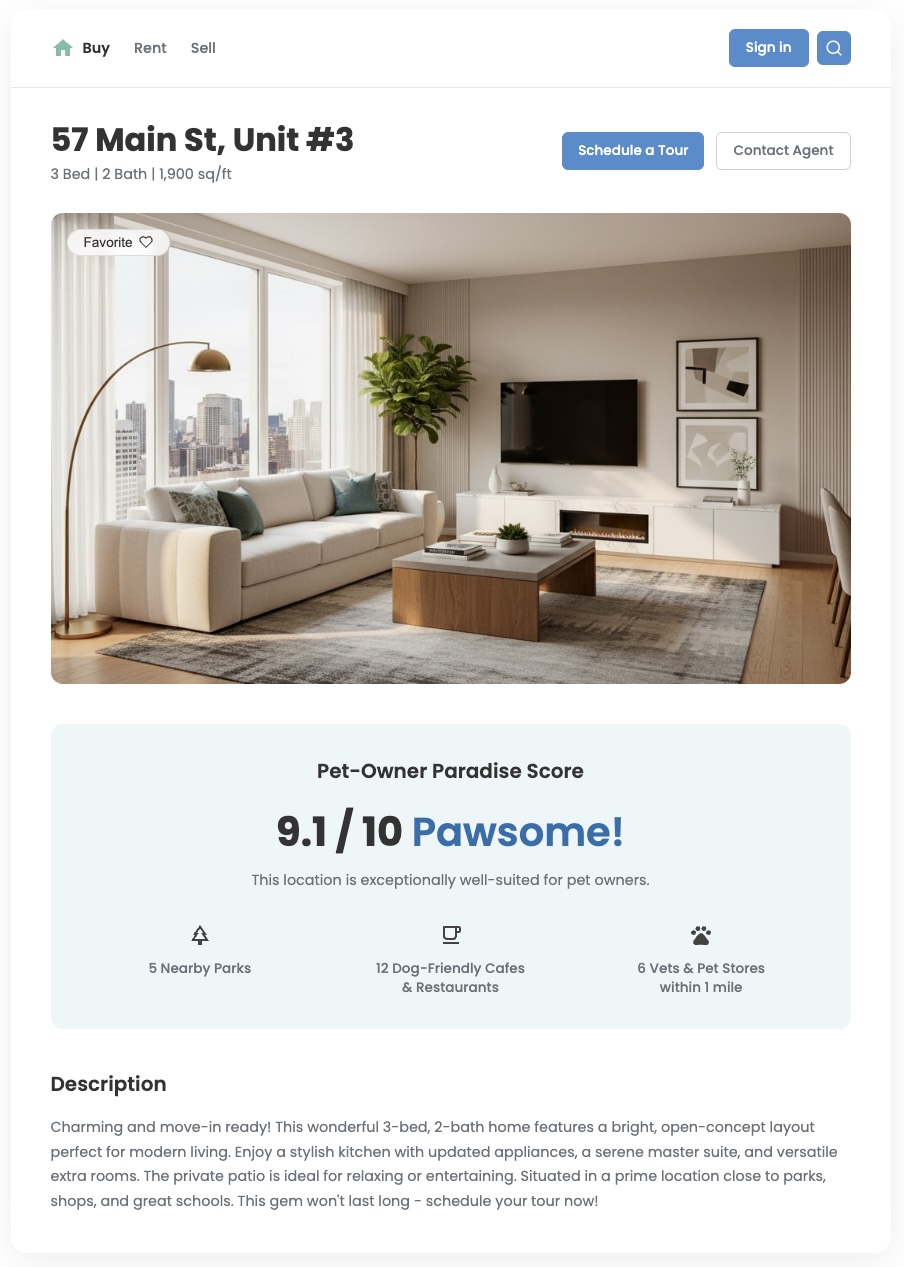
Visão geral
Os dados de localização padrão podem informar o que está por perto, mas geralmente não conseguem responder à pergunta mais importante: "Quão bom é esse lugar para mim?" As necessidades dos usuários são complexas. Uma família com crianças pequenas tem prioridades diferentes de um jovem profissional com um cachorro. Para ajudar os usuários a tomar decisões confiantes, você precisa fornecer insights que reflitam essas necessidades específicas. Um índice de localização personalizado é uma ferramenta poderosa para oferecer esse valor e criar uma experiência do usuário diferenciada.
Neste documento, descrevemos como criar índices de localização personalizados e multifacetados usando o conjunto de dados do Insights de Lugares no BigQuery. Ao transformar os dados de PDI em métricas significativas, você pode enriquecer seus aplicativos de imóveis, varejo ou viagens e fornecer aos usuários as informações relevantes de que eles precisam. Também oferecemos uma opção para usar IA generativa no BigQuery como uma maneira eficaz de calcular seus índices de localização.
Aumentar o valor comercial com índices personalizados
Os exemplos a seguir ilustram como você pode traduzir dados de localização brutos em métricas eficazes e centradas no usuário para melhorar seu aplicativo.
- Os incorporadores imobiliários podem criar um "Índice de adequação para famílias" ou um "Índice de sonho do viajante" para ajudar compradores e locatários a escolher o bairro perfeito que corresponda ao estilo de vida deles, levando a maior engajamento do usuário, leads de maior qualidade e conversões mais rápidas.
- Os engenheiros de viagens e hotelaria podem criar um "Índice de vida noturna" ou um "Índice de paraíso do turista" para ajudar os viajantes a escolher um hotel que corresponda ao estilo de férias deles, aumentando as taxas de reserva e a satisfação do cliente.
- Os analistas de varejo podem gerar um "Índice de condicionamento físico e bem-estar" para identificar o local ideal para uma nova academia ou loja de alimentos saudáveis com base em empresas complementares próximas, maximizando o potencial de segmentar o público-alvo certo.
Neste guia, você vai aprender uma metodologia flexível de três partes para criar qualquer tipo de índice de localização personalizado usando os dados do Places diretamente no BigQuery. Vamos ilustrar esse padrão criando dois exemplos de índices distintos: um Índice de adequação para famílias e um Índice de paraíso para donos de animais de estimação. Essa abordagem permite que você vá além das contagens de lugares e aproveite os atributos detalhados e avançados no conjunto de dados do Insights de Lugares. Você pode usar informações como horário de funcionamento, se um lugar é bom para crianças ou se permite cães, para criar métricas sofisticadas e significativas para seus usuários.
Fluxo de trabalho da solução
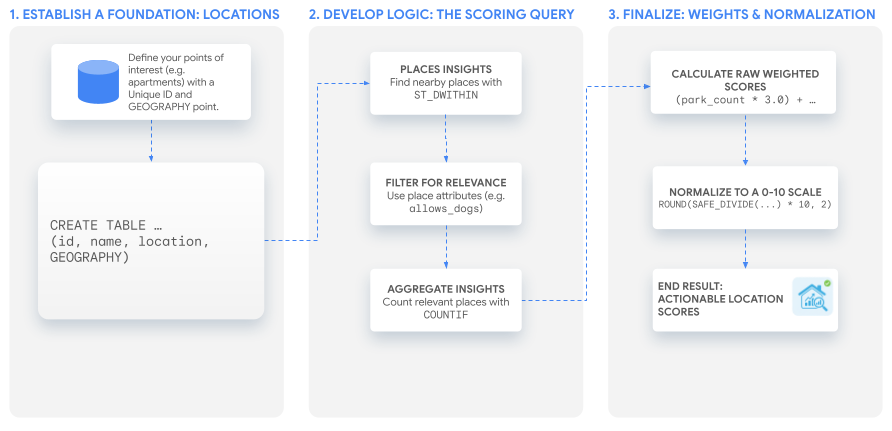
Este tutorial usa uma única consulta SQL eficaz para criar um índice personalizado que pode ser adaptado a qualquer caso de uso. Vamos explicar esse processo criando nossos dois exemplos de índices para um conjunto hipotético de anúncios de apartamentos.
Para conferir esse fluxo de trabalho em um ambiente interativo, execute o notebook a seguir. Ele demonstra como usar a
AI.GENERATE função no
BigQuery para criar um índice de localização.
 Ver código-fonte no GitHub
Ver código-fonte no GitHub
Pré-requisitos
Antes de começar, siga estas instruções para configurar o Places Insights.
1. Estabelecer uma base: seus locais de interesse
Antes de criar índices, você precisa de uma lista dos locais que quer analisar. A primeira etapa é garantir que esses dados existam como uma tabela no BigQuery.
A chave é ter um identificador exclusivo para cada local e uma coluna GEOGRAPHY que armazene as coordenadas.
Você pode criar e preencher uma tabela de locais para pontuar com uma consulta como esta:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
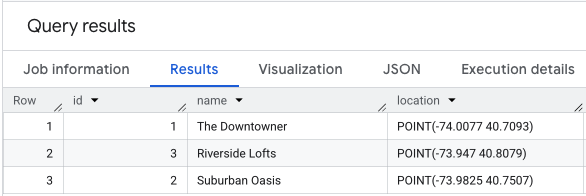
A execução de um SELECT * nos dados de localização seria semelhante a esta.
2. Desenvolver a lógica principal: a consulta de pontuação
Com os locais estabelecidos, a próxima etapa é encontrar, filtrar e contar os lugares por perto que são relevantes para o índice personalizado. Tudo isso é feito em uma única instrução SELECT.
Encontrar o que está por perto com uma pesquisa geoespacial
Primeiro, você precisa encontrar todos os lugares do conjunto de dados do Insights de Lugares que estão a uma determinada distância de cada um dos seus locais. A função ST_DWITHIN do BigQuery é perfeita para isso. Vamos executar um JOIN entre a tabela apartment_listings e a tabela places_insights para encontrar todos os lugares em um raio de 800 metros. Um LEFT JOIN garante que todos os locais originais sejam incluídos nos resultados, mesmo que nenhum lugar correspondente seja encontrado por perto.
Filtrar por relevância com atributos avançados
É aqui que você traduz o conceito abstrato de uma pontuação em filtros de dados concretos. Para nossos dois exemplos de índices, os critérios são diferentes:
- Para o "Índice de adequação para famílias" , consideramos parques, museus e restaurantes que são explicitamente bons para crianças.
- Para o "Índice de paraíso para donos de animais de estimação" , consideramos parques, clínicas veterinárias, pet shops e qualquer restaurante ou café que permita cães.
Você pode filtrar esses atributos específicos diretamente na cláusula WHERE da consulta.
Agregar os insights de cada local
Por fim, você precisa contar quantos lugares relevantes encontrou para cada apartamento. A cláusula GROUP BY agrega os resultados, e a função COUNTIF conta os lugares que correspondem aos critérios específicos de cada um dos nossos índices.
A consulta abaixo combina essas três etapas, calculando as contagens brutas para os dois índices em uma única passagem:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
O resultado dessa consulta será semelhante a este.
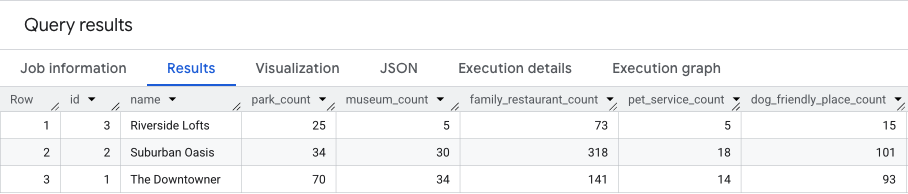
Vamos criar esses resultados na próxima seção.
3. Criar a pontuação
Agora você tem a contagem de lugares e a ponderação de cada tipo de lugar para cada local. É possível gerar o índice de localização personalizado. Vamos discutir duas opções nesta seção: usar seu próprio cálculo personalizado no BigQuery ou usar funções de inteligência artificial (IA) generativa no BigQuery.
Opção 1: usar seu próprio cálculo personalizado no BigQuery
As contagens brutas da etapa anterior são úteis, mas o objetivo é ter um único índice fácil de usar. A etapa final é combinar essas contagens usando ponderações e normalizar o resultado para uma escala de 0 a 10.
Aplicar ponderações personalizadas : escolher as ponderações é uma arte e uma ciência. Elas precisam refletir as prioridades da sua empresa ou o que você acredita ser mais importante para os usuários. Para um índice de adequação para famílias, você pode decidir que um parque é duas vezes mais importante que um museu. Comece com suas melhores suposições e itere com base no feedback do usuário.
Normalizar a pontuação : a consulta abaixo usa duas expressões de tabela comum (CTEs, na sigla em inglês): a primeira calcula as contagens brutas como antes, e a segunda calcula as pontuações ponderadas. A instrução SELECT final executa uma normalização min-max nos índices ponderados. A coluna location da tabela apartment_listings de exemplo é gerada para permitir a visualização de dados em um mapa.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Os resultados da consulta serão semelhantes aos abaixo. As duas últimas colunas são os índices normalizados.

Entender a pontuação normalizada
É importante entender por que essa etapa final de normalização é tão valiosa.
Os índices ponderados brutos podem variar de 0 a um número potencialmente muito grande, dependendo da densidade urbana dos locais. Um índice de 500 não tem significado para um usuário sem contexto.
A normalização transforma esses números abstratos em uma classificação relativa. Ao dimensionar os resultados de 0 a 10, a pontuação comunica claramente como cada local se compara aos outros no conjunto de dados específico:
- Um índice de 10 é atribuído ao local com a maior pontuação bruta, marcando-o como a melhor opção no conjunto atual.
- Um índice de 0 é atribuído ao local com a menor pontuação bruta, tornando-o a linha de base para comparação. Isso não significa que o local não tenha comodidades, mas sim que ele é o menos adequado em relação às outras opções que estão sendo avaliadas.
- Todos os outros índices ficam proporcionalmente entre eles, oferecendo aos usuários uma maneira clara e intuitiva de comparar as opções de relance.
Opção 2: usar a função AI.GENERATE (Gemini)
Como alternativa ao uso de uma fórmula matemática fixa, você pode usar a
função AI.GENERATE
BigQuery
para calcular índices de localização personalizados diretamente no fluxo de trabalho do SQL.
Embora a opção 1 seja excelente para pontuação puramente quantitativa com base em contagens de comodidades, ela não pode considerar facilmente dados qualitativos. A função AI.GENERATE permite combinar os números da consulta do Insights de Lugares com dados não estruturados, como a descrição de texto das informações do apartamento (por exemplo, "Este local é adequado para famílias e a área é tranquila à noite") ou preferências específicas do perfil de usuário (por exemplo, "Este usuário está reservando para uma família e prefere uma área tranquila em um local central"). Isso permite gerar uma pontuação mais detalhada que detecta sutilezas que uma contagem estrita pode perder, como um local com alta densidade de comodidades, mas também descrito como "muito barulhento para crianças".
Criar o comando
Para usar essa função, os resultados da agregação (da etapa 2) são formatados em um comando de linguagem natural. Isso pode ser feito dinamicamente no SQL concatenando colunas de dados com instruções para o modelo.
Na consulta abaixo, insight_counts são combinados com a descrição de texto do apartamento para criar um comando para cada linha. Um perfil de usuário de destino também é definido para orientar a pontuação.
Gerar o índice com SQL
A consulta a seguir executa toda a operação no BigQuery. Ele:
- Agrega as contagens de lugares (conforme descrito na etapa 2).
- Cria um comando para cada local.
- Chama a função
AI.GENERATEpara analisar o comando usando o modelo do Gemini. - Analisa o resultado em um formato estruturado pronto para uso no aplicativo.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Entender a configuração
- Conscientização de custos:essa função transmite sua entrada para um modelo do Gemini e gera cobranças na Vertex AI sempre que é chamada. Se um grande número de locais estiver sendo analisado (por exemplo, milhares de anúncios de apartamentos), é recomendável filtrar o conjunto de dados para os candidatos mais relevantes primeiro. Para mais detalhes sobre como minimizar custos, consulte Práticas recomendadas.
endpoint:gemini-flash-latesté especificado para este exemplo para priorizar velocidade e custo-benefício. No entanto, você pode escolher o modelo que melhor atende às suas necessidades. Consulte a documentação dos modelos do Gemini para testar diferentes versões (por exemplo, o Gemini Pro para tarefas de raciocínio mais complexas) e encontrar a melhor opção para seu caso de uso.output_schema: em vez de analisar texto bruto, um esquema é aplicado (FLOAT64para a pontuação eSTRINGpara o raciocínio). Isso garante que a saída possa ser usada imediatamente no aplicativo ou nas ferramentas de visualização sem pós-processamento.
Exemplo de resposta
A consulta retorna uma tabela padrão do BigQuery com o índice personalizado e o raciocínio do modelo.
| ID | nome | family_friendliness_score | raciocínio |
|---|---|---|---|
| 1 | The Downtowner | 5,5 | Excelente contagem de comodidades (parques, restaurantes), atendendo a métricas quantitativas. No entanto, os dados qualitativos indicam ruído excessivo de fim de semana e um forte foco na vida noturna, o que entra em conflito diretamente com a necessidade de silêncio do usuário-alvo. |
| 2 | Suburban Oasis | 9,8 | Dados quantitativos excelentes combinados com uma descrição ("rua tranquila e arborizada") que se alinha perfeitamente ao perfil familiar de destino. Modificadores positivos altos resultam em um índice quase perfeito. |
Esse procedimento permite oferecer uma pontuação altamente personalizada, inteligível e adaptada a cada usuário individual, tudo em uma única consulta SQL.
4. Visualizar seus índices em um mapa
O BigQuery Studio inclui uma visualização de mapa integrada
para qualquer resultado de consulta que contenha uma coluna GEOGRAPHY. Como nossa consulta gera a coluna location, você pode visualizar seus índices imediatamente.
Clicar na guia Visualization vai mostrar o mapa, e o menu suspenso Data Column controla o índice de localização a ser visualizado. Neste exemplo, o
normalized_pet_score é visualizado no exemplo da opção 1. Observe que mais locais foram adicionados à tabela apartment_listings para este exemplo.
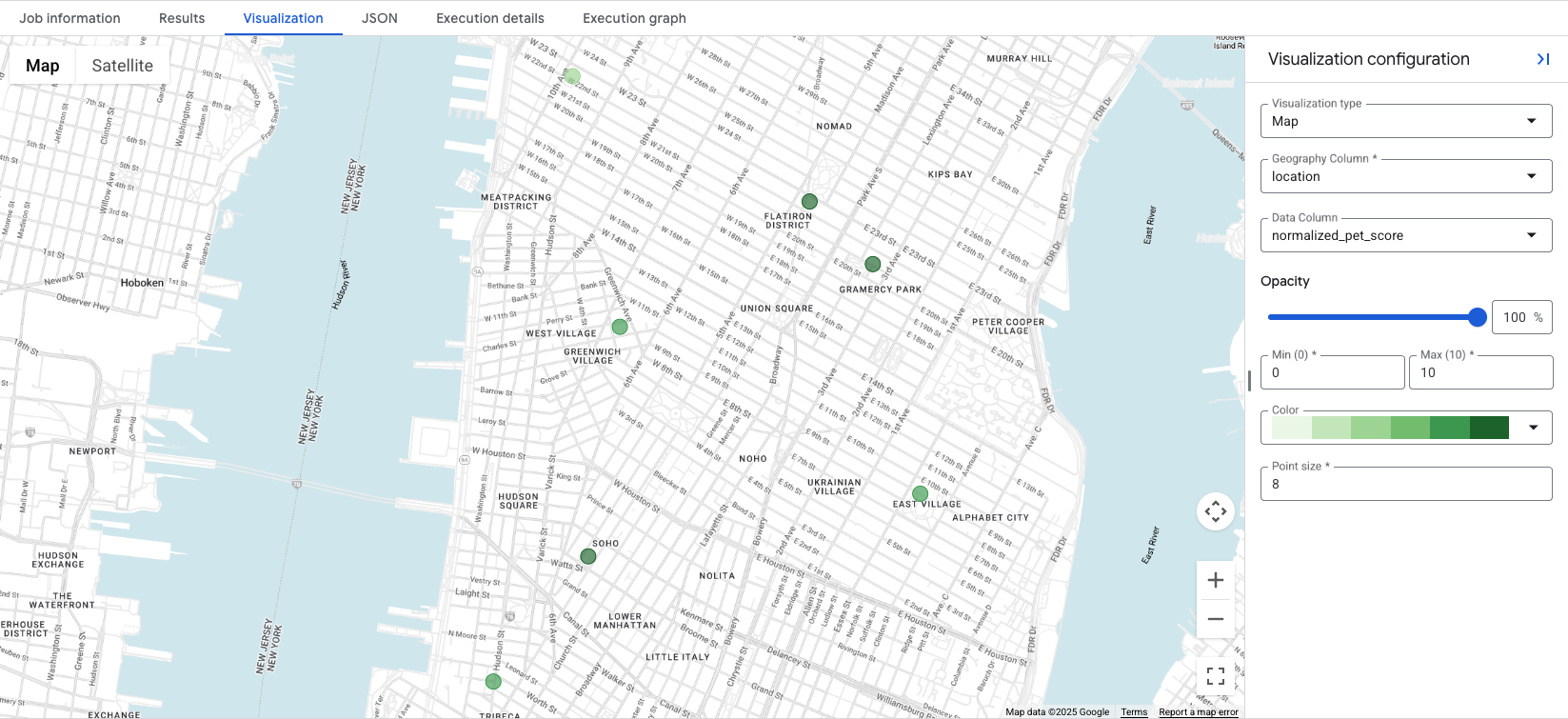
A visualização dos dados revela de relance os locais mais adequados para a pontuação criada, com círculos verdes mais escuros representando locais com um normalized_pet_score maior, neste caso. Para mais opções de visualização de dados do Insights de Lugares, consulte Visualizar resultados da consulta.
Conclusão
Agora você tem uma metodologia eficaz e repetível para criar índices de localização detalhados. Começando com seus locais, você criou uma única consulta SQL no BigQuery que encontra lugares próximos com ST_DWITHIN, filtra-os por atributos avançados como good_for_children e allows_dogs e agrega os resultados com COUNTIF. Ao aplicar ponderações personalizadas e normalizar o resultado, você produziu um único índice fácil de usar que oferece insights detalhados e acionáveis. Você pode aplicar esse padrão diretamente para transformar dados de localização brutos em uma vantagem competitiva significativa.
Próximas ações
Agora é sua vez de criar. Este tutorial fornece um modelo. Você pode usar os dados avançados disponíveis no esquema do Insights de Lugares para criar os índices mais necessários para seu caso de uso. Considere estes outros índices que você pode criar:
- "Índice de vida noturna": combine filtros para
primary_type(bar,night_club),price_levele horário de funcionamento noturno para encontrar as áreas mais vibrantes depois do anoitecer. - "Índice de condicionamento físico e bem-estar": Conte
gyms,parksehealth_food_storespróximos e filtre restaurantes para aqueles comserves_vegetarian_foodpara pontuar locais para usuários preocupados com a saúde. - "Pontuação de sonho do motorista habitual": encontre locais com alta densidade de lugares próximos
transit_stationeparkingpara ajudar os usuários que valorizam o acesso ao transporte.
Colaboradores
Henrik Valve | Engenheiro de DevX