
Przegląd
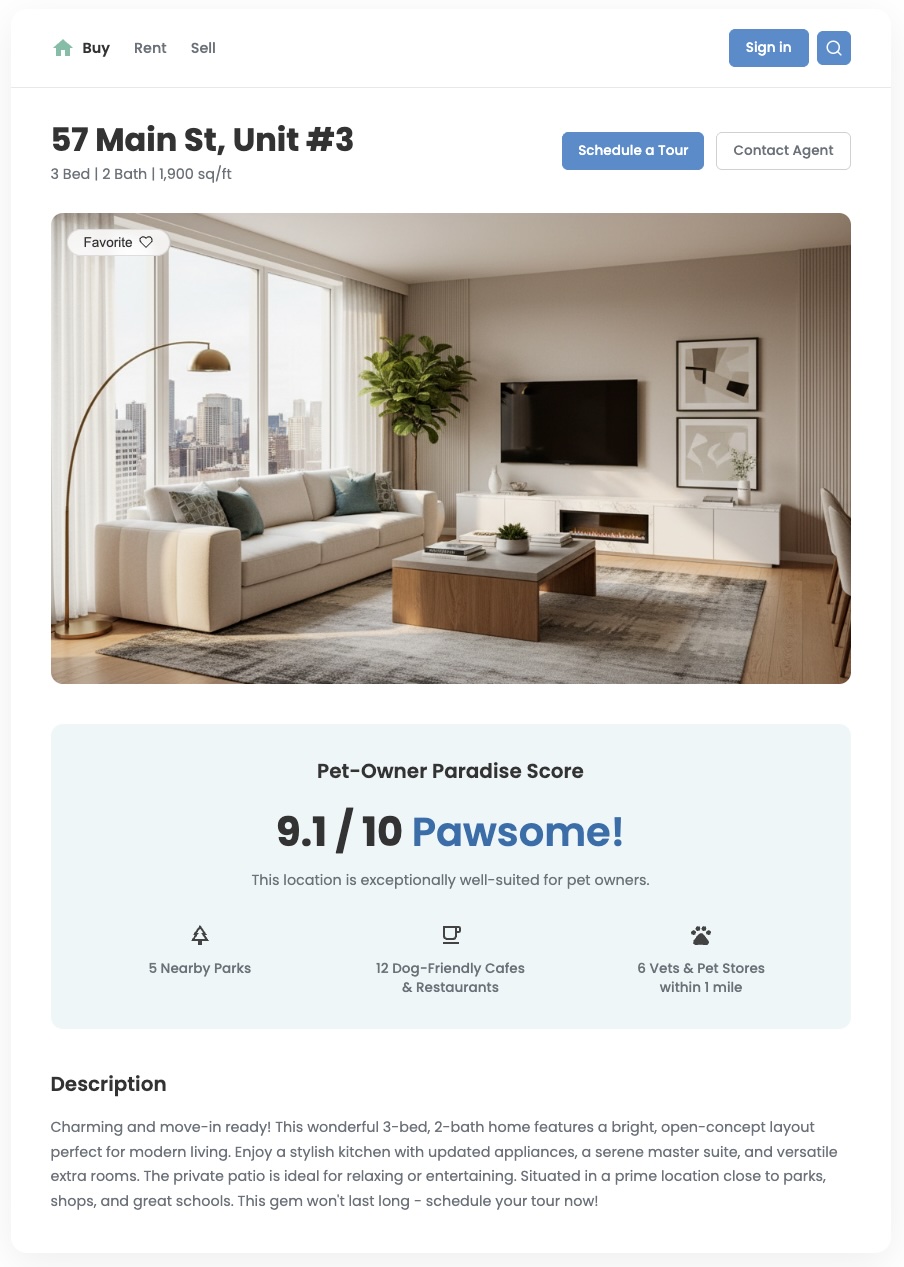
Standardowe dane o lokalizacji mogą Ci powiedzieć, co znajduje się w pobliżu, ale często nie odpowiadają na ważniejsze pytanie: „Jak dobra jest ta okolica dla mnie?”. Potrzeby użytkowników są zróżnicowane. Rodzina z małymi dziećmi ma inne priorytety niż młody pracownik z psem. Aby pomóc im w podejmowaniu trafnych decyzji, musisz dostarczać statystyki odzwierciedlające te konkretne potrzeby. Niestandardowy wynik lokalizacji to skuteczne narzędzie, które pozwala dostarczać tę wartość i zapewniać użytkownikom znacznie lepsze wrażenia.
Z tego dokumentu dowiesz się, jak tworzyć niestandardowe, wieloaspektowe oceny lokalizacji za pomocą zbioru danych Statystyki miejsc w BigQuery. Przekształcając dane o ciekawych miejscach w przydatne wskaźniki, możesz wzbogacić aplikacje związane z nieruchomościami, handlem detalicznym lub podróżami i dostarczać użytkownikom potrzebne im informacje. Udostępniamy też opcję korzystania z generatywnej AI w BigQuery, która jest skutecznym sposobem obliczania wyników lokalizacji.
Zwiększanie wartości biznesowej dzięki dostosowanym wynikom
Poniższe przykłady pokazują, jak przekształcić surowe dane o lokalizacji w przydatne dane o użytkownikach, aby ulepszyć aplikację.
- Deweloperzy mogą tworzyć „ocenę przyjazności dla rodzin” lub „ocenę dla osób dojeżdżających do pracy”, aby pomóc kupującym i najemcom wybrać idealną okolicę, która odpowiada ich stylowi życia. Prowadzi to do zwiększenia zaangażowania użytkowników, uzyskiwania większej liczby wartościowych potencjalnych klientów i szybszych konwersji.
- Inżynierowie z branży turystycznej i hotelarskiej mogą opracować „ocenę życia nocnego” lub „ocenę dla miłośników zwiedzania”, aby pomóc podróżnym wybrać hotel dopasowany do ich stylu wypoczynku, co zwiększy liczbę rezerwacji i zadowolenie klientów.
- Analitycy handlu detalicznego mogą generować „Wynik dotyczący fitnessu i zdrowia”, aby określić optymalną lokalizację nowej siłowni lub sklepu ze zdrową żywnością na podstawie pobliskich firm uzupełniających, co pozwala zmaksymalizować potencjał kierowania reklam na odpowiednią grupę demograficzną użytkowników.
Z tego przewodnika dowiesz się, jak za pomocą danych Miejsc bezpośrednio w BigQuery utworzyć dowolny rodzaj niestandardowego wyniku lokalizacji. Aby zilustrować ten wzorzec, utworzymy 2 różne przykładowe oceny: ocenę przyjazności dla rodzin i ocenę raju dla właścicieli zwierząt. To podejście pozwala wyjść poza liczbę miejsc i skorzystać z bogatych, szczegółowych atrybutów w zbiorze danych Statystyk miejsc. Możesz używać informacji takich jak godziny otwarcia, czy miejsce jest odpowiednie dla dzieci lub czy można wejść do niego z psem, aby tworzyć zaawansowane i przydatne dane dla użytkowników.
Przepływ pracy rozwiązania
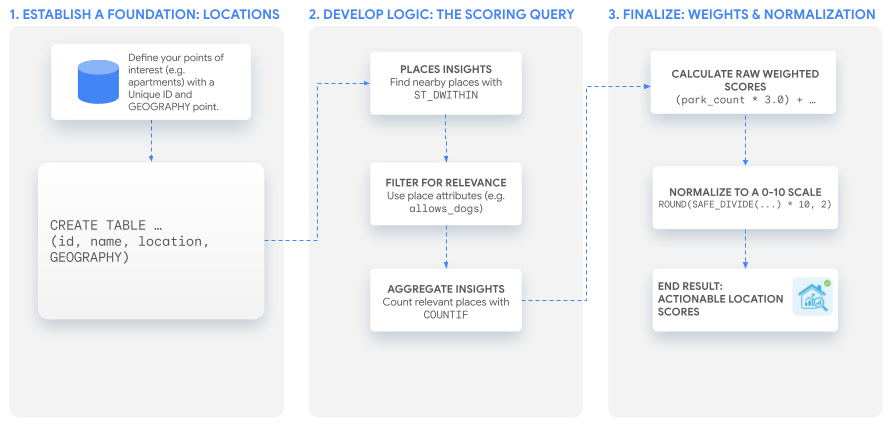
W tym samouczku używamy jednego, zaawansowanego zapytania SQL do utworzenia niestandardowego wyniku, który możesz dostosować do dowolnego przypadku użycia. Przeprowadzimy Cię przez ten proces, tworząc 2 przykładowe wyniki dla hipotetycznego zestawu ofert mieszkań.
Aby zapoznać się z tym przepływem pracy w interaktywnym środowisku, uruchom ten notatnik. Pokazuje, jak używać funkcji AI.GENERATE w BigQuery do tworzenia oceny lokalizacji.
 Wyświetl źródło w GitHubie
Wyświetl źródło w GitHubie
Wymagania wstępne
Zanim zaczniesz, wykonaj te instrukcje, aby skonfigurować Statystyki miejsc.
1. Stwórz podstawy: lokalizacje interesujące użytkowników
Zanim utworzysz wyniki, musisz mieć listę lokalizacji, które chcesz analizować. Pierwszym krokiem jest sprawdzenie, czy te dane są dostępne w BigQuery w postaci tabeli.
Kluczem jest posiadanie unikalnego identyfikatora dla każdej lokalizacji i GEOGRAPHYkolumny, w której są przechowywane jej współrzędne.
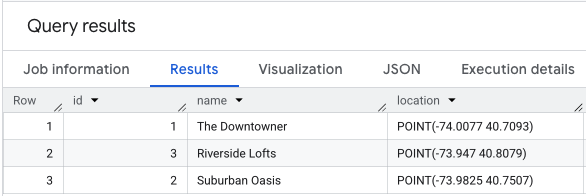
Możesz utworzyć i wypełnić tabelę lokalizacji do oceny za pomocą zapytania takiego jak to:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
Wykonanie SELECT * na danych o lokalizacji wyglądałoby podobnie do tego.
2. Opracuj logikę podstawową: zapytanie dotyczące oceny
Po ustaleniu lokalizacji następnym krokiem jest znalezienie, filtrowanie i zliczanie pobliskich miejsc, które są istotne dla Twojego wyniku niestandardowego. Wszystko to odbywa się w ramach jednej SELECT instrukcji.
Znajdowanie tego, co jest w pobliżu, za pomocą wyszukiwania geoprzestrzennego
Najpierw musisz znaleźć wszystkie miejsca ze zbioru danych Statystyki miejsc, które znajdują się w określonej odległości od każdej z Twoich lokalizacji. Funkcja BigQuery
ST_DWITHIN jest do tego idealna. Wykonamy JOIN między naszą tabelą apartment_listings a tabelą places_insights, aby znaleźć wszystkie miejsca w promieniu 800 metrów. Symbol LEFT JOIN zapewnia, że w wynikach zostaną uwzględnione wszystkie Twoje pierwotne lokalizacje, nawet jeśli w pobliżu nie zostaną znalezione żadne pasujące miejsca.
Filtrowanie według trafności za pomocą atrybutów zaawansowanych
W tym miejscu przekształcasz abstrakcyjną koncepcję wyniku w konkretne filtry danych. W przypadku 2 przykładowych wyników kryteria są różne:
- W przypadku „oceny przyjazności dla rodzin” bierzemy pod uwagę parki, muzea i restauracje, które są szczególnie odpowiednie dla dzieci.
- W przypadku „oceny dla właścicieli zwierząt” bierzemy pod uwagę parki, kliniki weterynaryjne, sklepy zoologiczne oraz restauracje i kawiarnie, w których można przebywać z psami.
Te konkretne atrybuty możesz filtrować bezpośrednio w klauzuli WHERE zapytania.
Zbieranie statystyk dla każdej lokalizacji
Na koniec musisz policzyć, ile odpowiednich miejsc udało Ci się znaleźć w przypadku każdego mieszkania. Klauzula GROUP BY agreguje wyniki, a funkcja COUNTIF zlicza miejsca, które spełniają określone kryteria dla każdego z naszych wyników.
Poniższe zapytanie łączy te 3 kroki, obliczając surowe liczby dla obu wyników w jednym przebiegu:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Wynik tego zapytania będzie podobny do tego.
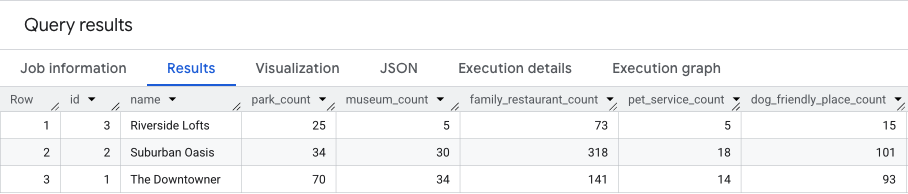
W następnej sekcji wykorzystamy te wyniki.
3. Tworzenie wyniku
Teraz masz liczbę miejsc i wagi dla każdego typu miejsca w każdej lokalizacji, więc możesz wygenerować niestandardowy wynik lokalizacji. W tej sekcji omówimy 2 opcje: używanie własnych obliczeń niestandardowych w BigQuery lub korzystanie z funkcji generatywnej sztucznej inteligencji (AI) w BigQuery.
Opcja 1. Użyj własnych obliczeń niestandardowych w BigQuery
Surowe dane z poprzedniego kroku są przydatne, ale celem jest uzyskanie jednego, łatwego w interpretacji wyniku. Ostatnim krokiem jest połączenie tych wartości za pomocą wag, a następnie znormalizowanie wyniku do skali 0–10.
Stosowanie wag niestandardowych Wybór wag to zarówno sztuka, jak i nauka. Powinny one odzwierciedlać priorytety Twojej firmy lub to, co Twoim zdaniem jest najważniejsze dla użytkowników. W przypadku oceny „Przyjazność dla rodzin” możesz uznać, że park jest 2 razy ważniejszy niż muzeum. Zacznij od najlepszych założeń i wprowadzaj zmiany na podstawie opinii użytkowników.
Normalizowanie wyniku Zapytanie poniżej używa 2 zapytań CTE (Common Table Expression): pierwsze oblicza surowe liczby tak jak wcześniej, a drugie oblicza ważone wyniki. Ostateczne stwierdzenie SELECT wykonuje normalizację min-max na ważonych wynikach. Wyświetlana jest kolumna location tabeli przykładowejapartment_listings, aby umożliwić wizualizację danych na mapie.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Wyniki zapytania będą podobne do tych poniżej. Dwie ostatnie kolumny zawierają znormalizowane wyniki.

Interpretowanie znormalizowanej oceny
Warto zrozumieć, dlaczego ten ostatni krok normalizacji jest tak cenny.
Surowe ważone wyniki mogą się wahać od 0 do potencjalnie bardzo dużej liczby w zależności od gęstości zaludnienia w Twoich lokalizacjach. Wynik 500 jest bez kontekstu bez znaczenia dla użytkownika.
Normalizacja przekształca te abstrakcyjne liczby w ranking względny. Skalując wyniki od 0 do 10, wynik wyraźnie pokazuje, jak poszczególne lokalizacje wypadają na tle innych w Twoim konkretnym zbiorze danych:
- Wynik 10 jest przypisywany do lokalizacji z najwyższym wynikiem surowym, co oznacza, że jest to najlepsza opcja w bieżącym zbiorze.
- Wynik 0 jest przypisywany do lokalizacji z najniższym wynikiem pierwotnym, co czyni ją punktem odniesienia do porównania. Nie oznacza to, że w tej lokalizacji nie ma żadnych udogodnień, ale że jest ona najmniej odpowiednia w porównaniu z innymi rozważanymi opcjami.
- Wszystkie inne wyniki są proporcjonalnie rozłożone pomiędzy tymi wartościami, co pozwala użytkownikom szybko i intuicyjnie porównać dostępne opcje.
Opcja 2. Używanie funkcji AI.GENERATE (Gemini)
Zamiast korzystać ze stałego wzoru matematycznego, możesz użyć funkcji AI.GENERATE BigQuery, aby obliczać niestandardowe wyniki lokalizacji bezpośrednio w przepływie pracy SQL.
Sposób 1 doskonale sprawdza się w przypadku czysto ilościowej oceny na podstawie liczby udogodnień, ale nie uwzględnia danych jakościowych. Funkcja AI.GENERATE umożliwia łączenie liczb z zapytania Statystyki miejsc z nieustrukturyzowanymi danymi, takimi jak tekstowy opis oferty mieszkania (np. „Ta lokalizacja jest odpowiednia dla rodzin, a w nocy jest tu cicho”) lub konkretne preferencje profilu użytkownika (np. „Ten użytkownik rezerwuje nocleg dla rodziny i woli cichą okolicę w centralnej lokalizacji”). Pozwala to wygenerować bardziej szczegółowy wynik, który wykrywa subtelności, które mogą umknąć ścisłemu zliczaniu, np. lokalizację o dużym zagęszczeniu udogodnień, ale opisaną jako „zbyt głośną dla dzieci”.
Tworzenie prompta
Aby użyć tej funkcji, wyniki agregacji (z kroku 2) są formatowane w prompt w języku naturalnym. Można to zrobić dynamicznie w SQL, łącząc kolumny danych z instrukcjami dla modelu.
W zapytaniu poniżej insight_counts są łączone z opisem tekstowym mieszkania, aby utworzyć prompt dla każdego wiersza. Określony jest też profil użytkownika docelowego, który pomaga w ocenie.
Generowanie wyniku za pomocą SQL
Poniższe zapytanie wykonuje całą operację w BigQuery. Oto one:
- Agreguje liczbę miejsc (zgodnie z opisem w kroku 2).
- Tworzy prompt dla każdej lokalizacji.
- Wywołuje funkcję
AI.GENERATE, aby przeanalizować prompt za pomocą modelu Gemini. - Analizuje wynik i przekształca go w uporządkowany format gotowy do użycia w Twojej aplikacji.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Informacje o konfiguracji
- Świadomość kosztów: ta funkcja przekazuje dane wejściowe do modelu Gemini i za każdym razem, gdy jest wywoływana, generuje opłaty w Vertex AI. Jeśli analizowana jest duża liczba lokalizacji (np. tysiące ofert mieszkań), zalecamy najpierw odfiltrować zbiór danych, aby uwzględnić tylko najbardziej odpowiednie kandydatury. Więcej informacji o minimalizowaniu kosztów znajdziesz w sekcji Sprawdzone metody.
endpoint: w tym przykładzie określono modelgemini-flash-latest, aby priorytetowo traktować szybkość i opłacalność. Możesz jednak wybrać model, który najlepiej odpowiada Twoim potrzebom. W dokumentacji modele Gemini znajdziesz informacje o tym, jak eksperymentować z różnymi wersjami (np. Gemini Pro do bardziej złożonych zadań wymagających wyciągania wniosków) i znaleźć najlepsze rozwiązanie dla swojego przypadku użycia.output_schema: zamiast analizować zwykły tekst, wymuszana jest struktura (FLOAT64w przypadku wyniku iSTRINGw przypadku uzasadnienia). Dzięki temu dane wyjściowe są od razu gotowe do użycia w aplikacji lub narzędziach do wizualizacji bez konieczności przetwarzania końcowego.
Przykładowe dane wyjściowe
Zapytanie zwraca standardową tabelę BigQuery z niestandardowym wynikiem i uzasadnieniem modelu.
| id | nazwa | family_friendliness_score | rozumowanie, |
|---|---|---|---|
| 1 | The Downtowner | 5,5 | Wysoka liczba udogodnień (parki, restauracje) spełniająca kryteria ilościowe. Dane jakościowe wskazują jednak na nadmierny hałas w weekendy i duże natężenie życia nocnego, co jest sprzeczne z potrzebą ciszy u docelowego użytkownika. |
| 2 | Suburban Oasis | 9.8 | Wyjątkowe dane ilościowe połączone z opisem („cicha, wysadzana drzewami ulica”), który idealnie pasuje do profilu rodziny docelowej. Wysokie modyfikatory dodatnie dają niemal idealny wynik. |
Ta procedura umożliwia dostarczanie wysoce spersonalizowanych wyników, które są zrozumiałe i dopasowane do każdego użytkownika, a wszystko to w ramach jednego zapytania SQL.
4. Wizualizacja wyników na mapie
BigQuery Studio zawiera zintegrowaną wizualizację mapy
dla każdego wyniku zapytania, który zawiera kolumnę GEOGRAPHY. Ponieważ zapytanie zwraca kolumnę location, możesz od razu wizualizować swoje wyniki.
Kliknięcie karty Visualization spowoduje wyświetlenie mapy, a menu Data Column
umożliwia kontrolowanie wyniku lokalizacji, który ma być wizualizowany. W tym przykładzie normalized_pet_score jest wizualizowany na podstawie przykładu opcji 1. Zwróć uwagę, że w tym przykładzie do tabeli apartment_listings dodano więcej lokalizacji.
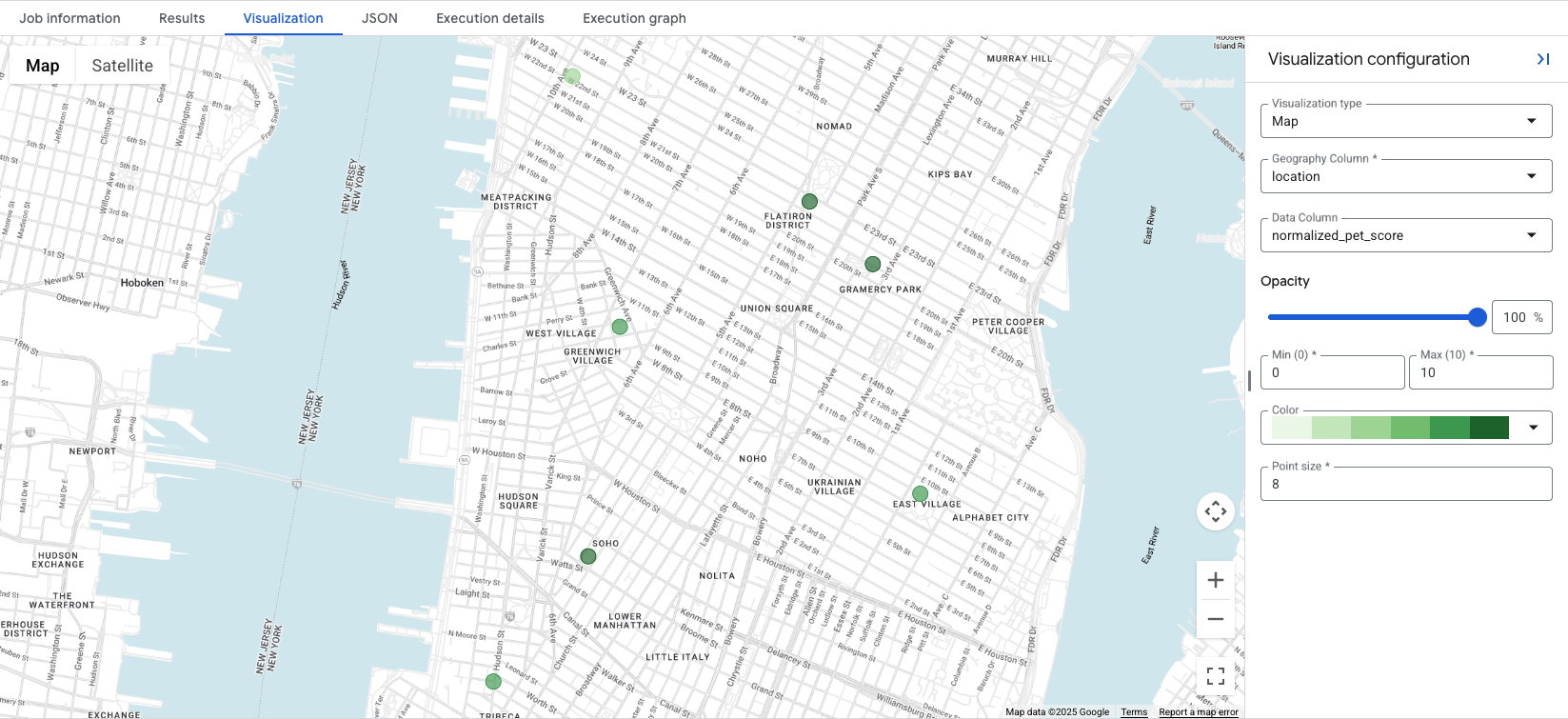
Wizualizacja danych pozwala na pierwszy rzut oka określić najbardziej odpowiednie lokalizacje dla utworzonego wyniku. Ciemniejsze zielone kółka oznaczają lokalizacje o wyższym poziomie normalized_pet_score, w tym przypadku. Więcej opcji wizualizacji danych Statystyk miejsc znajdziesz w artykule Wizualizacja wyników zapytania.
Podsumowanie
Masz teraz do dyspozycji skuteczną i powtarzalną metodę tworzenia szczegółowych wyników lokalizacji. Na podstawie lokalizacji utworzono w BigQuery jedno zapytanie SQL, które wyszukuje pobliskie miejsca z ST_DWITHIN, filtruje je według zaawansowanych atrybutów, takich jak good_for_children i allows_dogs, oraz agreguje wyniki za pomocą funkcji COUNTIF. Dzięki zastosowaniu niestandardowych wag i normalizacji wyniku udało Ci się uzyskać jeden, łatwy w użyciu wynik, który dostarcza szczegółowych i przydatnych informacji. Możesz bezpośrednio zastosować ten wzorzec, aby przekształcić surowe dane o lokalizacji w znaczącą przewagę konkurencyjną.
Następne działania
Teraz Twoja kolej na tworzenie. W tym samouczku znajdziesz szablon. Możesz użyć danych rozszerzonych dostępnych w schemacie Statystyk miejsc, aby utworzyć wyniki, które są najbardziej potrzebne w Twoim przypadku użycia. Możesz też utworzyć inne oceny:
- „Ocena życia nocnego”: połącz filtry
primary_type(bar,night_club),price_leveli godziny otwarcia w nocy, aby znaleźć najbardziej tętniące życiem miejsca po zmroku. - „Ocena fitnessu i dobrego samopoczucia”: zliczanie pobliskich
gyms,parksihealth_food_storesoraz filtrowanie restauracji pod kątem tych, które mająserves_vegetarian_food, aby oceniać lokalizacje pod kątem użytkowników dbających o zdrowie. - „Wynik dla dojeżdżających do pracy”: znajdź miejsca z dużą gęstością pobliskich
transit_stationiparking, aby pomóc użytkownikom, którzy cenią sobie dostęp do transportu.
Współtwórcy
Henrik Valve | Inżynier DevX