
概要
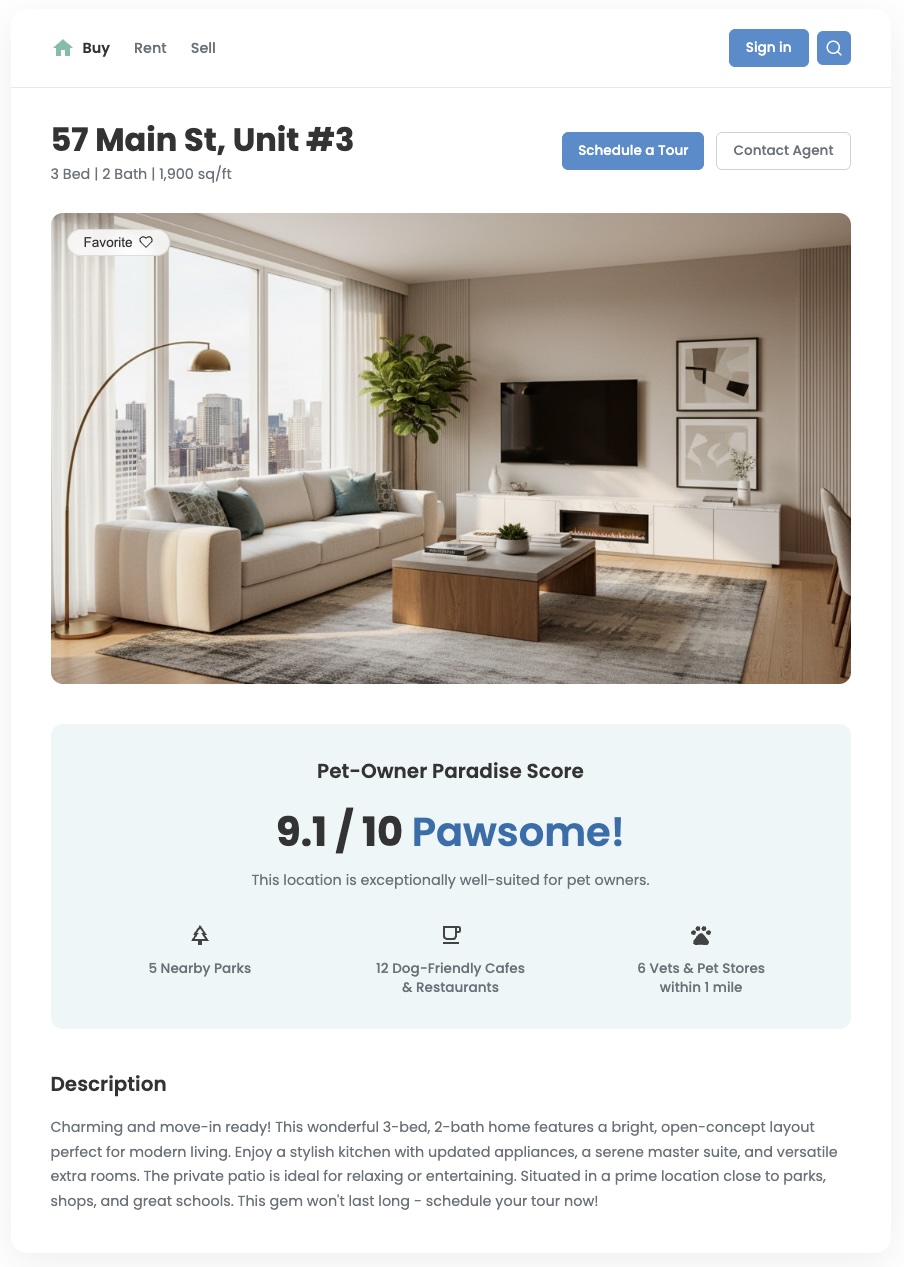
標準的な位置情報データでは、周辺にあるものはわかりますが、 「このエリアは自分にとってどれくらい良いか」という重要な質問に答えることはできません。ユーザーのニーズは多岐にわたります。幼い子供がいる家族と犬を飼っている若い専門職では、優先順位が異なります。ユーザーが自信を持って意思決定できるようにするには、こうした具体的なニーズを反映した分析情報を提供する必要があります。カスタム ロケーション スコアは、この価値を提供し、差別化された優れたユーザー エクスペリエンスを実現するための強力なツールです。
このドキュメントでは、BigQuery の Places Insights データセットを使用して、多面的なカスタム ロケーション スコアを作成する方法について説明します。POI データを意味のある指標に変換することで、不動産、小売、旅行のアプリケーションを強化し、ユーザーに必要な関連情報を提供できます。また、BigQuery で生成 AI を使用してロケーション スコアを計算することもできます。
カスタマイズされたスコアでビジネス価値を高める
次の例は、生のロケーション データを強力なユーザー中心の指標に変換して、アプリケーションを強化する方法を示しています。
- 不動産開発業者は、「ファミリー向けスコア」や「通勤に便利なスコア」を作成して、購入者や賃借人がライフスタイルに合った最適な地域を選択できるようにします。これにより、ユーザー エンゲージメントの向上、質の高いリードの獲得、コンバージョンの迅速化につながります。
- 旅行および宿泊施設のエンジニアは、「ナイトライフ スコア」や「観光客向けスコア」を作成して、旅行者が旅行スタイルに合ったホテルを選べるようにします。これにより、予約率と顧客満足度が向上します。
- 小売アナリストは、「フィットネスと健康スコア」を生成して、近隣の相補的なビジネスに基づいて新しいジムや健康食品店の最適な場所を特定し、適切なユーザー層をターゲットにする可能性を最大限に高めます。
このガイドでは、Places データを BigQuery で直接使用して、あらゆる種類のカスタム ロケーション スコアを作成するための柔軟な 3 部構成の方法について説明します。このパターンを説明するために、ファミリー向けスコア とペットオーナー向けパラダイス スコア という 2 つの異なるスコアを作成します。このアプローチでは、場所の数を数えるだけでなく、Places Insights データセット内の詳細な属性を活用できます。営業時間、子供に適しているかどうか、犬を連れて入れるかどうかなどの情報を使用して、ユーザーにとって洗練された意味のある指標を作成できます。
ソリューションのワークフロー
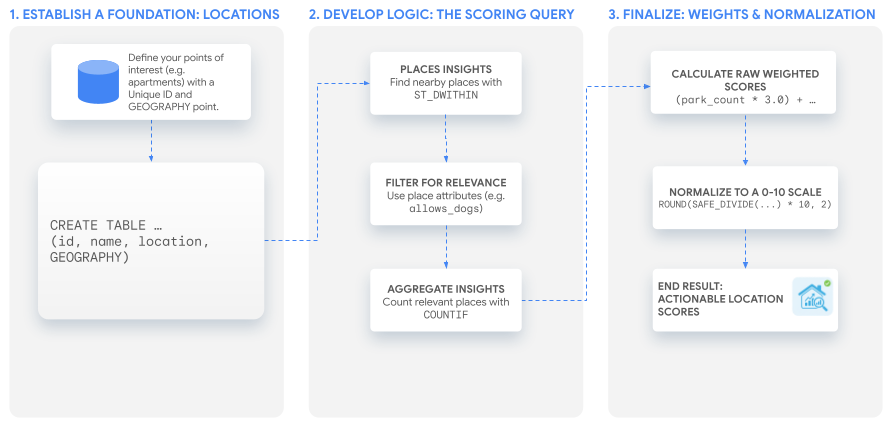
このチュートリアルでは、単一の強力な SQL クエリを使用して、あらゆるユースケースに適応できるカスタム スコアを作成します。架空のアパートのリスティングに対して 2 つのスコアを作成して、このプロセスを説明します。
インタラクティブな環境でこのワークフローを試すには、次のノートブックを実行します。BigQuery 内で
AI.GENERATE 関数を使用してロケーション スコアを作成する方法を示します。
 [View source on GitHub]
[View source on GitHub]
前提条件
始める前に、次の 手順に沿って Places Insights を設定してください。
1. 基盤を確立する: 関心のある場所
スコアを作成するには、分析する場所のリストが必要です。まず、このデータが BigQuery のテーブルとして存在することを確認します。
重要なのは、各場所の一意の識別子と、座標を格納する GEOGRAPHY 列があることです。
次のようなクエリを使用して、スコアを付ける場所のテーブルを作成してデータを入力できます。
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
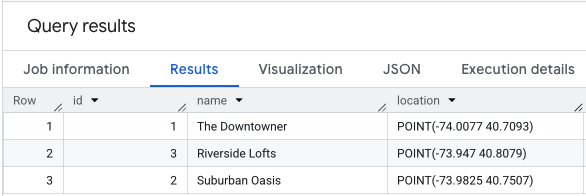
位置情報データに対して SELECT * を実行すると、次のようになります。
2. コアロジックを開発する: スコアリング クエリ
場所を特定したら、次のステップとして、カスタム スコアに関連する周辺の場所を検索、フィルタ、カウントします。これはすべて単一の SELECT ステートメント内で行われます。
地理空間検索で周辺の場所を検索する
まず、Places Insights データセットから、各場所から一定の距離内にあるすべての場所を検索する必要があります。これには、BigQuery 関数 ST_DWITHIN が最適です。apartment_listings テーブルと places_insights テーブルの間で JOIN を実行して、半径 800 メートル以内のすべての場所を検索します。LEFT JOIN を使用すると、一致する場所が近くに見つからなくても、元の場所がすべて結果に含まれます。
高度な属性で関連性をフィルタする
ここでは、スコアの抽象的なコンセプトを具体的なデータフィルタに変換します。2 つのスコアの基準は異なります。
- 「ファミリー向けスコア」 では、子供に適している公園、博物館、レストランを重視します。
- 「ペットオーナー向けパラダイス スコア」 では、公園、動物病院、ペットショップ、犬を連れて入れるレストランやカフェを重視します。
これらの特定の属性でフィルタするには、クエリの WHERE 句で直接フィルタします。
各場所の分析情報を集計する
最後に、各アパート・マンションで見つかった関連性の高いプレイスの数をカウントする必要があります。GROUP BY 句は結果を集計し、COUNTIF 関数は各スコアの特定の基準に一致する場所をカウントします。
次のクエリは、これらの 3 つのステップを組み合わせて、1 回のパスで両方のスコアの生カウントを計算します。
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
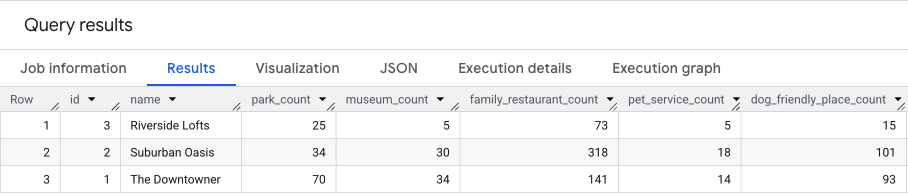
このクエリの結果は次のようになります。
次のセクションでは、これらの結果に基づいて構築します。
3. スコアを作成する
場所の数と、各場所タイプの重み付けがわかったので、カスタム ロケーション スコアを生成できます。このセクションでは、BigQuery で独自のカスタム計算を使用する方法と、BigQuery で 生成 AI 関数を使用する方法の 2 つの方法について説明します。
オプション 1: BigQuery で独自のカスタム計算を使用する
前のステップの生カウントは有益ですが、最終的な目標は、ユーザー フレンドリーな単一のスコアです。最後のステップでは、重みを使用してこれらのカウントを組み合わせ、結果を 0 ~ 10 のスケールに正規化します。
カスタムの重みを適用する 重みを選択することは、芸術と科学の両面があります。 重みは、ビジネスの優先順位や、ユーザーにとって最も重要だと考えるものを反映する必要があります。「ファミリー向け」スコアの場合、公園は博物館の 2 倍重要だと判断するかもしれません。最善の仮定から始め、ユーザー フィードバックに基づいて反復します。
スコアを正規化する 次のクエリでは、2 つの共通テーブル式(CTE)を使用します。1 つ目は以前と同様に生カウントを計算し、2 つ目は重み付けされたスコアを計算します。最後の SELECT ステートメントは、重み付けされたスコアに対して最小最大正規化を実行します。地図上にデータを可視化できるように、サンプル apartment_listings テーブルの location 列が出力されます。
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
クエリの結果は次のようになります。最後の 2 つの列は正規化されたスコアです。

正規化されたスコアについて
この最後の正規化ステップが非常に価値がある理由を理解することが重要です。
重み付けされた生のスコアは、場所の都市密度に応じて 0 から非常に大きな数値まで幅広く変動する可能性があります。コンテキストがないと、500 というスコアはユーザーにとって意味がありません。
正規化により、これらの抽象的な数値が相対的なランキングに変換されます。結果を 0 ~ 10 のスケールにすることで、スコアは特定のデータセット内の他の場所と比較して各場所がどのように評価されるかを明確に伝えます。
- スコア 10 は、生のスコアが最も高い場所に割り当てられ、現在のセットで最適なオプションとしてマークされます。
- スコア 0 は、生のスコアが最も低い場所に割り当てられ、比較の基準となります。これは、その場所に設備がまったくないという意味ではなく、評価対象の他のオプションと比較して最も適していないという意味です。
- 他のすべてのスコア は、その間に比例して割り当てられ、ユーザーはオプションを一目で比較できます。
オプション 2: AI.GENERATE 関数(Gemini)を使用する
固定の数式を使用する代わりに、
BigQuery AI.GENERATE
関数
を使用して、SQL ワークフロー内でカスタム ロケーション スコアを直接計算できます。
オプション 1 は、アメニティの数に基づく純粋に定量的なスコアリングには優れていますが、定性的なデータを簡単に考慮することはできません。AI.GENERATE 関数を使用すると、Places Insights クエリの数値と、アパートのリスティングのテキスト説明(「この場所は家族に適しており、夜は静かです」など)や特定のユーザー プロフィールの設定(「このユーザーは家族で予約しており、中心部の静かなエリアを希望しています」など)などの構造化されていないデータを組み合わせることができます。これにより、厳密なカウントでは見落とされる可能性のある微妙な違い(アメニティの密度が高いが、「子供にはうるさすぎる」と説明されている場所など)を検出する、よりニュアンスのあるスコアを生成できます。
プロンプトを作成する
この関数を使用するには、集計の結果(ステップ 2)を自然言語プロンプトにフォーマットします。これは、データ列とモデルへの指示を連結することで、SQL で動的に行うことができます。
次のクエリでは、insight_counts とアパートのテキスト説明を組み合わせて、各行のプロンプトを作成します。スコアリングをガイドするターゲット ユーザー プロフィールも定義します。
SQL でスコアを生成する
次のクエリは、BigQuery でオペレーション全体を実行します。つまり、
- 場所の数を集計 します(ステップ 2 で説明したとおり)。
- 各場所のプロンプトを作成 します。
AI.GENERATE関数を呼び出し て、Gemini モデルを使用してプロンプトを分析します。- アプリケーションで使用できる構造化された形式に結果を解析 します。
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
構成について
- 費用に関する考慮事項: この関数は入力を Gemini モデルに渡し、呼び出されるたびに Vertex AI で料金が発生します。多数の場所(数千件のアパートのリストなど)を分析する場合は、まずデータセットを最も関連性の高い候補にフィルタすることをおすすめします。 費用を最小限に抑える方法について詳しくは、ベスト プラクティスをご覧ください。
endpoint: この例では、速度と費用対効果を優先するため、gemini-flash-latestが指定されています。ただし、ニーズに最適なモデルを選択できます。Gemini モデルのドキュメントで、さまざまなバージョン(より複雑な 推論タスクには Gemini Pro など)を試して、ユースケースに最適なものを見つけてください。output_schema: 生のテキストを解析する代わりに、スキーマが適用されます(スコアにはFLOAT64、推論にはSTRING)。これにより、後処理を行わずに、アプリケーションや可視化ツールで出力をすぐに使用できます。
出力例
クエリは、カスタム スコアとモデルの推論を含む標準の BigQuery テーブルを返します。
| id | name | family_friendliness_score | 推論 |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | アメニティの数が多く(公園、レストラン)、定量的な指標を満たしています。ただし、定性的なデータでは、週末の騒音が激しく、ナイトライフに重点が置かれていることが示されており、ターゲット ユーザーの静かな場所を求めるニーズと直接矛盾しています。 |
| 2 | Suburban Oasis | 9.8 | 優れた定量データと、ターゲット ファミリー プロフィールに完全に合致する説明(「静かで並木道」)が組み合わされています。正の修飾子が高いため、ほぼ完璧なスコアになっています。 |
この手順では、単一の SQL クエリ内で、各ユーザーにとってわかりやすく、カスタマイズされた、高度にパーソナライズされたスコアリングを提供できます。
4. 地図上にスコアを可視化する
BigQuery Studio には、統合地図
可視化機能
が、GEOGRAPHY 列を含むクエリ結果に用意されています。クエリは location 列を出力するため、スコアをすぐに可視化できます。
Visualization[Data Column] タブをクリックすると地図が表示され、
[ドロップダウン]で可視化するロケーション スコアを制御できます。この例では、
normalized_pet_scoreはオプション 1
例から可視化されています。この例では、apartment_listings テーブルにさらに多くの場所が追加されています。
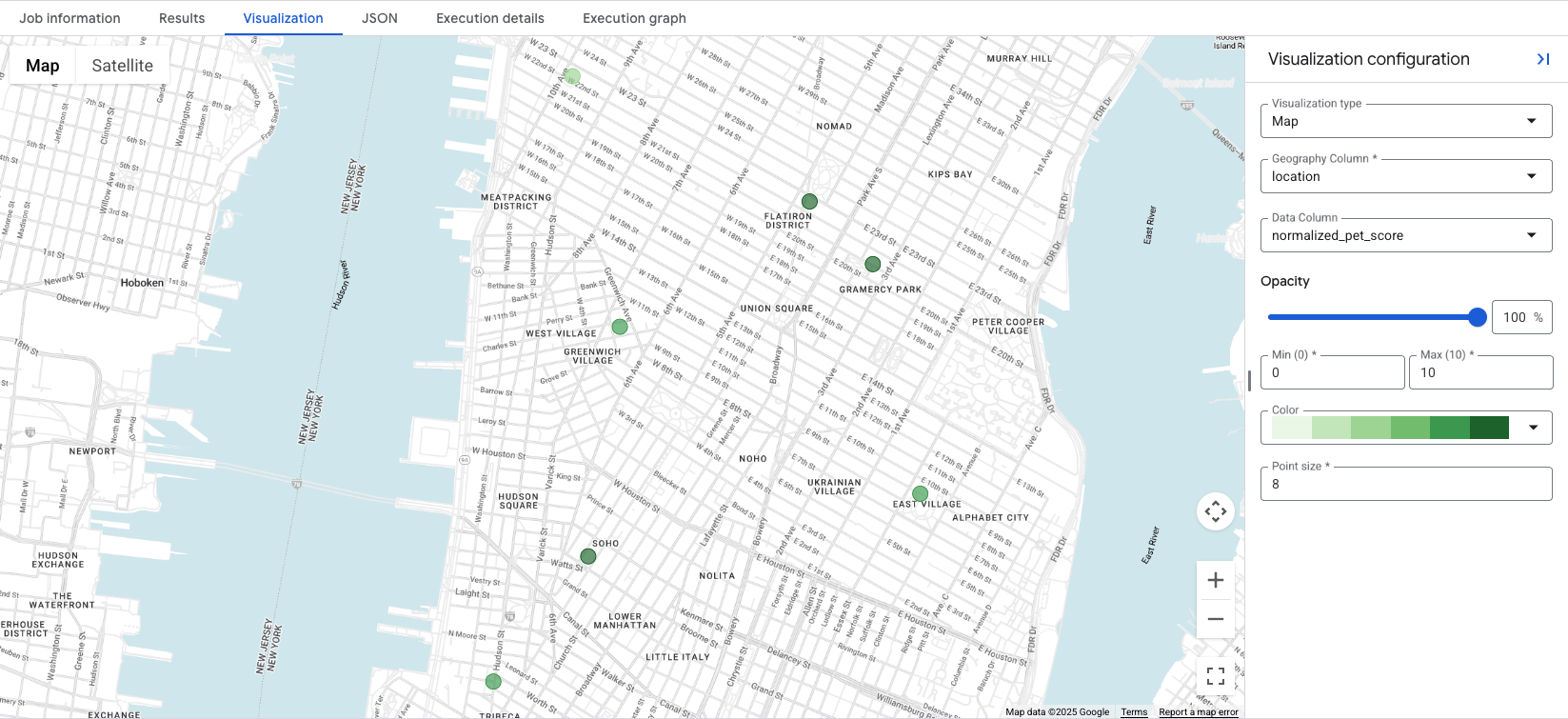
データを可視化すると、作成したスコアに最適な場所が一目でわかります。この場合、濃い緑色の円は normalized_pet_score が高い場所を表します。Places Insights データ
の可視化オプションについて詳しくは、クエリ結果
を可視化するをご覧ください。
まとめ
これで、ニュアンスのあるロケーション スコアを作成するための強力で再現可能な方法を習得しました。まず、場所から始めて、BigQuery で単一の SQL クエリを作成します。このクエリは、ST_DWITHIN を使用して周辺の場所を検索し、good_for_children や allows_dogs などの高度な属性でフィルタし、COUNTIF で結果を集計します。カスタムの重みを適用して結果を正規化することで、深い洞察と実用的な分析情報を提供する、ユーザー フレンドリーな単一のスコアが生成されました。このパターンを直接適用して、生のロケーション データを大きな競争優位性に変えることができます。
次の対策
次は、実際に構築してみましょう。このチュートリアルでは、テンプレートを提供します。Places Insights スキーマで利用可能なリッチデータを使用して、ユースケースに最も必要なスコアを作成できます。作成できるその他のスコアを次に示します。
- 「ナイトライフ スコア」:
primary_type(bar、night_club)、price_level、深夜の営業時間のフィルタを組み合わせて、夜間に最も 活気のあるエリアを検索します。 - 「フィットネスと健康スコア」: 周辺の
gyms、parks、およびhealth_food_storesをカウントし、serves_vegetarian_foodのレストランをフィルタして、健康志向のユーザー向けの場所をスコアリングします。 - 「通勤に便利なスコア」: 周辺の
transit_stationとparkingの密度が高い場所を検索して、 交通機関へのアクセスを重視するユーザーを支援します。
コントリビューター
Henrik Valve | DevX エンジニア