
Panoramica
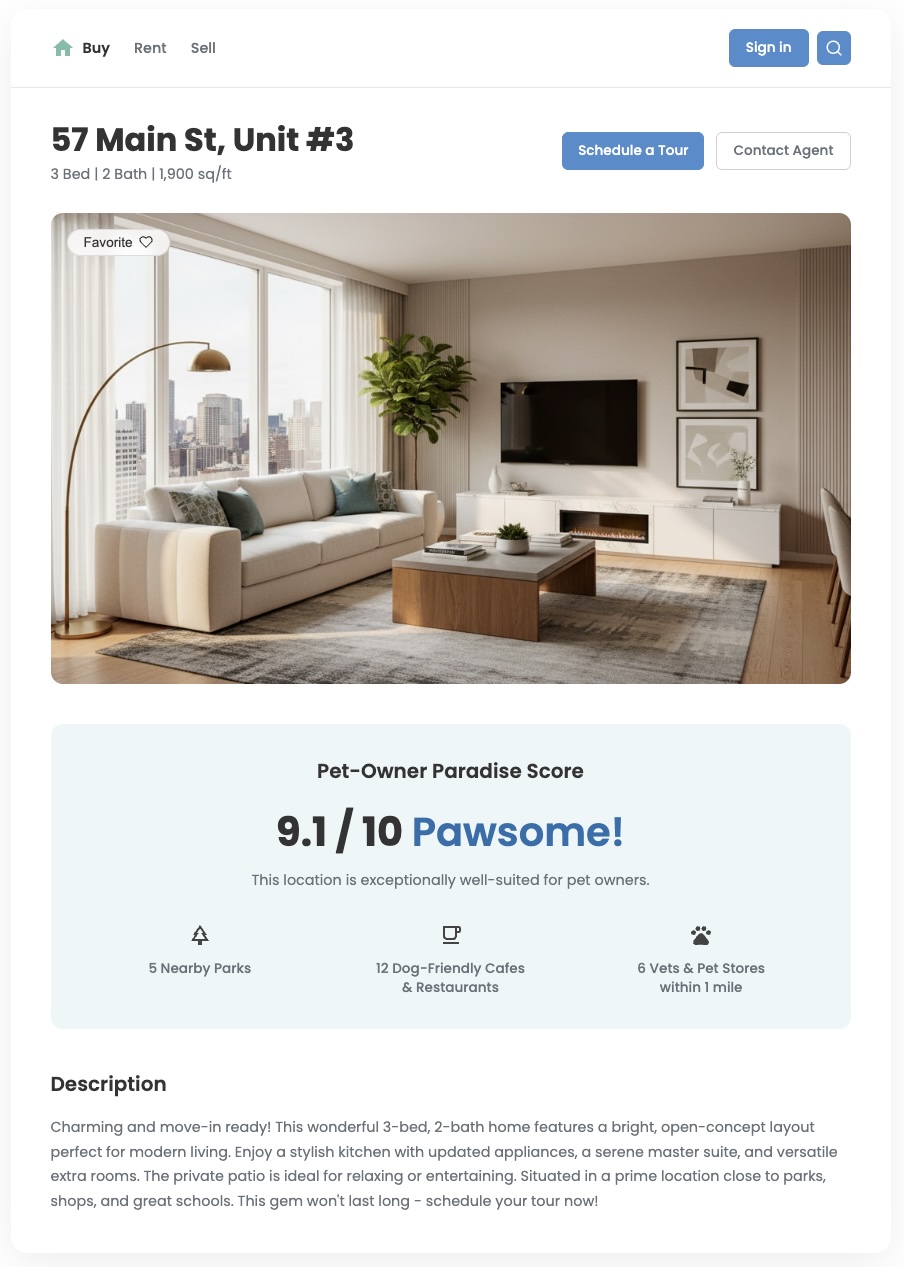
I dati standard sulla posizione possono indicarti cosa si trova nelle vicinanze, ma spesso non riescono a rispondere alla domanda più importante: "Quanto è adatta questa zona a me?" Le esigenze degli utenti sono sfumate. Una famiglia con bambini piccoli ha priorità diverse rispetto a un giovane professionista con un cane. Per aiutarli a prendere decisioni consapevoli, devi fornire approfondimenti che riflettano queste esigenze specifiche. Un punteggio di posizione personalizzato è uno strumento potente per fornire questo valore e creare un'esperienza utente differenziata significativa.
Questo documento descrive come creare punteggi di posizione personalizzati e sfaccettati utilizzando il set di dati Places Insights in BigQuery. Trasformando i dati dei PDI in metriche significative, puoi arricchire le tue applicazioni immobiliari, di vendita al dettaglio o di viaggio e fornire agli utenti le informazioni pertinenti di cui hanno bisogno. Forniamo anche un'opzione per utilizzare l'AI generativa in BigQuery come un modo efficace per calcolare i punteggi di posizione.
Generare valore aziendale con punteggi personalizzati
I seguenti esempi mostrano come puoi tradurre i dati sulla posizione non elaborati in metriche efficaci e incentrate sull'utente per migliorare la tua applicazione.
- Gli sviluppatori immobiliari possono creare un "Punteggio di idoneità per le famiglie" o un "Punteggio di idoneità per i pendolari" per aiutare acquirenti e affittuari a scegliere il quartiere perfetto per il loro stile di vita, con conseguente aumento del coinvolgimento degli utenti, lead di qualità superiore e conversioni più rapide.
- Gli ingegneri di viaggi e ospitalità possono creare un "Punteggio di vita notturna" o un "Punteggio di idoneità per i turisti" per aiutare i viaggiatori a scegliere un hotel adatto al loro stile di vacanza, aumentando i tassi di prenotazione e la soddisfazione dei clienti.
- Gli analisti di vendita al dettaglio possono generare un "Punteggio di fitness e benessere" per identificare la posizione ottimale per una nuova palestra o un negozio di alimenti biologici in base alle attività complementari nelle vicinanze, massimizzando il potenziale per scegliere come target i dati demografici degli utenti giusti.
In questa guida imparerai una metodologia flessibile in tre parti per creare qualsiasi tipo di punteggio di posizione personalizzato utilizzando i dati di Places direttamente in BigQuery. Illustreremo questo pattern creando due punteggi di esempio distinti: un Punteggio di idoneità per le famiglie e un Punteggio di idoneità per i proprietari di animali domestici. Questo approccio ti consente di andare oltre i conteggi dei luoghi e di sfruttare gli attributi ricchi e dettagliati all'interno del set di dati Places Insights. Puoi utilizzare informazioni come gli orari di apertura, se un luogo è adatto ai bambini o se ammette i cani, per creare metriche sofisticate e significative per i tuoi utenti.
Flusso di lavoro della soluzione
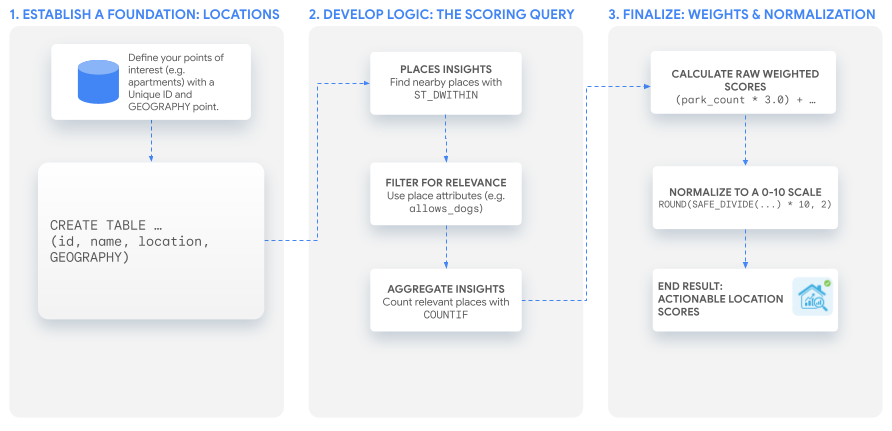
Questo tutorial utilizza una singola query SQL efficace per creare un punteggio personalizzato che puoi adattare a qualsiasi caso d'uso. Ti guideremo attraverso questa procedura creando i nostri due punteggi di esempio per un insieme ipotetico di annunci di appartamenti.
Per esplorare questo workflow in un ambiente interattivo, esegui il seguente notebook. Mostra come utilizzare la
AI.GENERATE funzione in
BigQuery per creare un punteggio di posizione.
 Visualizza il codice sorgente in GitHub
Visualizza il codice sorgente in GitHub
Prerequisiti
Prima di iniziare, segui queste istruzioni per configurare Places Insights.
1. Stabilire una base: le località di interesse
Prima di poter creare i punteggi, devi avere un elenco delle località che vuoi analizzare. Il primo passaggio consiste nell'assicurarsi che questi dati esistano come tabella in BigQuery.
La chiave è avere un identificatore univoco per ogni località e una colonna GEOGRAPHY che memorizzi le relative coordinate.
Puoi creare e compilare una tabella di località da valutare con una query come questa:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
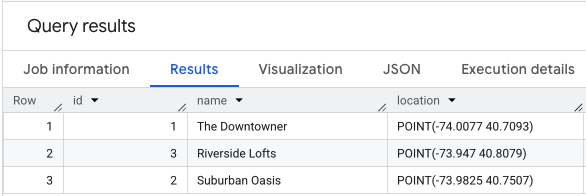
L'esecuzione di un'istruzione SELECT * sui dati sulla posizione sarà simile a questa.
2. Sviluppare la logica principale: la query di punteggio
Una volta stabilite le località, il passaggio successivo consiste nel trovare, filtrare e contare i luoghi nelle vicinanze pertinenti al tuo punteggio personalizzato. Tutto questo viene eseguito all'interno di una singola istruzione SELECT.
Trovare cosa c'è nelle vicinanze con una ricerca geospaziale
Innanzitutto, devi trovare tutti i luoghi del set di dati Places Insights che si trovano a una certa distanza da ciascuna delle tue località. La funzione BigQuery ST_DWITHIN è perfetta per questo scopo. Eseguiremo un'istruzione JOIN tra la tabella apartment_listings e la tabella places_insights per trovare tutti i luoghi entro un raggio di 800 metri. Un'istruzione LEFT JOIN garantisce che tutte le località originali siano incluse nei risultati, anche se non vengono trovati luoghi corrispondenti nelle vicinanze.
Filtrare per pertinenza con attributi avanzati
È qui che traduci il concetto astratto di un punteggio in filtri di dati concreti. Per i nostri due punteggi di esempio, i criteri sono diversi:
- Per il "Punteggio di idoneità per le famiglie", ci interessano parchi, musei e ristoranti esplicitamente adatti ai bambini.
- Per il "Punteggio di idoneità per i proprietari di animali domestici", ci interessano parchi, cliniche veterinarie, negozi di animali e qualsiasi ristorante o bar che ammetta i cani.
Puoi filtrare questi attributi specifici direttamente nella clausola WHERE della query.
Aggregare gli approfondimenti per ogni località
Infine, devi contare quanti luoghi pertinenti hai trovato per ogni appartamento. La clausola GROUP BY aggrega i risultati e la funzione COUNTIF conta i luoghi che corrispondono ai criteri specifici per ciascuno dei nostri punteggi.
La query riportata di seguito combina questi tre passaggi, calcolando i conteggi non elaborati per entrambi i punteggi in un'unica passata:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Il risultato di questa query sarà simile a questo.
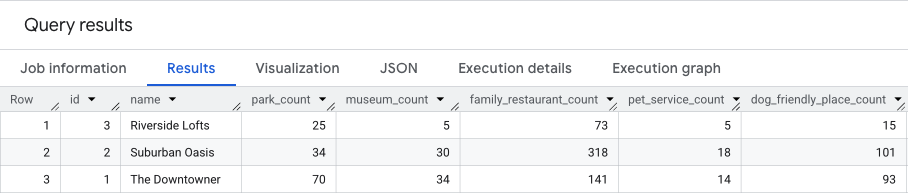
Ci baseremo su questi risultati nella sezione successiva.
3. Creare il punteggio
Ora che hai il conteggio dei luoghi e la ponderazione per ogni tipo di luogo per ogni località, puoi generare il punteggio di posizione personalizzato. In questa sezione parleremo di due opzioni: utilizzare il tuo calcolo personalizzato in BigQuery o utilizzare le funzioni di intelligenza artificiale (AI) generativa in BigQuery.
Opzione 1: utilizzare il proprio calcolo personalizzato in BigQuery
I conteggi non elaborati del passaggio precedente sono utili, ma l'obiettivo è un singolo punteggio di facile utilizzo. Il passaggio finale consiste nel combinare questi conteggi utilizzando le ponderazioni e quindi normalizzare il risultato su una scala da 0 a 10.
Applicare ponderazioni personalizzate La scelta delle ponderazioni è sia un'arte che una scienza. Devono riflettere le priorità della tua attività o ciò che ritieni sia più importante per i tuoi utenti. Per un punteggio di idoneità per le famiglie, potresti decidere che un parco è due volte più importante di un museo. Inizia con le tue ipotesi migliori e ripeti in base al feedback degli utenti.
Normalizzare il punteggio La query riportata di seguito utilizza due espressioni di tabella comuni (CTE): la prima calcola i conteggi non elaborati come prima e la seconda calcola i punteggi ponderati. L'istruzione SELECT finale esegue quindi una normalizzazione min-max sui punteggi ponderati. Viene restituita la colonna location della tabella apartment_listings di esempio per consentire la visualizzazione dei dati su una mappa.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
I risultati della query saranno simili a quelli riportati di seguito. Le ultime due colonne sono i punteggi normalizzati.

Informazioni sul punteggio normalizzato
È importante capire perché questo passaggio di normalizzazione finale è così prezioso.
I punteggi ponderati non elaborati possono variare da 0 a un numero potenzialmente molto elevato a seconda della densità urbana delle tue località. Un punteggio di 500 non ha significato per un utente senza contesto.
La normalizzazione trasforma questi numeri astratti in una classifica relativa. Scalando i risultati da 0 a 10, il punteggio comunica chiaramente il confronto tra ogni località e le altre nel tuo set di dati specifico:
- Un punteggio di 10 viene assegnato alla località con il punteggio non elaborato più alto, contrassegnandola come l'opzione migliore nel set corrente.
- Un punteggio di 0 viene assegnato alla località con il punteggio non elaborato più basso, rendendola la base di riferimento per il confronto. Questo non significa che la località non abbia servizi, ma piuttosto che è la meno adatta rispetto alle altre opzioni in fase di valutazione.
- Tutti gli altri punteggi rientrano proporzionalmente tra questi due valori, offrendo agli utenti un modo chiaro e intuitivo per confrontare le opzioni a colpo d'occhio.
Opzione 2: utilizzare la funzione AI.GENERATE (Gemini)
In alternativa all'utilizzo di una formula matematica fissa, puoi utilizzare la
funzione AI.GENERATE
BigQuery
per calcolare i punteggi di posizione personalizzati direttamente nel flusso di lavoro SQL.
Sebbene l'opzione 1 sia eccellente per la valutazione puramente quantitativa basata sui conteggi dei servizi, non può facilmente tenere conto dei dati qualitativi. La funzione AI.GENERATE ti consente di combinare i numeri della query Places Insights con dati non strutturati, come la descrizione testuale della scheda dell'appartamento (ad es. "Questa località è adatta alle famiglie e la zona è tranquilla di notte") o le preferenze specifiche del profilo utente (ad es. "Questo utente sta prenotando per una famiglia e preferisce una zona tranquilla in una posizione centrale"). In questo modo puoi generare un punteggio più sfumato che rileva le sottigliezze che un conteggio rigoroso potrebbe non rilevare, ad esempio una località con un'elevata densità di servizi ma descritta anche come "troppo rumorosa per i bambini".
Creare il prompt
Per utilizzare questa funzione, i risultati dell'aggregazione (dal passaggio 2) vengono formattati in un prompt in linguaggio naturale. Questa operazione può essere eseguita dinamicamente in SQL concatenando le colonne di dati con le istruzioni per il modello.
Nella query riportata di seguito, insight_counts vengono combinati con la descrizione testuale dell'appartamento per creare un prompt per ogni riga. Viene anche definito un profilo utente target per guidare la valutazione.
Generare il punteggio con SQL
La query seguente esegue l'intera operazione in BigQuery. Il GDPR:
- Aggrega i conteggi dei luoghi (come descritto nel passaggio 2).
- Crea un prompt per ogni località.
- Chiama la funzione
AI.GENERATEper analizzare il prompt utilizzando il modello Gemini. - Analizza il risultato in un formato strutturato pronto per l'uso nella tua applicazione.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Informazioni sulla configurazione
- Consapevolezza dei costi: questa funzione passa l'input a un modello Gemini e comporta addebiti in Vertex AI ogni volta che viene chiamata. Se viene analizzato un numero elevato di località (ad es. migliaia di annunci di appartamenti), è consigliabile filtrare prima il set di dati in base ai candidati più pertinenti. Per maggiori dettagli sulla riduzione al minimo dei costi, consulta le best practice.
endpoint: in questo esempio viene specificatogemini-flash-latestper dare la priorità alla velocità e all'efficienza in termini di costi. Tuttavia, puoi scegliere il modello più adatto alle tue esigenze. Consulta la documentazione dei modelli Gemini per sperimentare versioni diverse (ad es. Gemini Pro per attività di ragionamento più complesse) e trovare quella più adatta al tuo caso d'uso.output_schema: anziché analizzare il testo non elaborato, viene applicato uno schema (FLOAT64per il punteggio eSTRINGper il ragionamento). In questo modo, l'output è immediatamente utilizzabile negli strumenti di visualizzazione o nell'applicazione senza post-elaborazione.
Output di esempio
La query restituisce una tabella BigQuery standard con il punteggio personalizzato e il ragionamento del modello.
| id | nome | family_friendliness_score | ragionamento |
|---|---|---|---|
| 1 | The Downtowner | 5,5 | Conteggi eccellenti dei servizi (parchi, ristoranti), che soddisfano le metriche quantitative. Tuttavia, i dati qualitativi indicano un rumore eccessivo durante il fine settimana e una forte attenzione alla vita notturna, in conflitto diretto con l'esigenza di tranquillità dell'utente target. |
| 2 | Suburban Oasis | 9,8 | Dati quantitativi eccezionali combinati con una descrizione ("strada tranquilla e alberata") che si allinea perfettamente al profilo della famiglia target. I modificatori positivi elevati generano un punteggio quasi perfetto. |
Questa procedura ti consente di fornire punteggi altamente personalizzati, comprensibili e su misura per ogni singolo utente, il tutto all'interno di una singola query SQL.
4. Visualizzare i punteggi su una mappa
BigQuery Studio includes an integrated map
visualization
per qualsiasi risultato della query che contenga una colonna GEOGRAPHY. Poiché la query restituisce la colonna location, puoi visualizzare immediatamente i punteggi.
Se fai clic sulla scheda Visualization, viene visualizzata la mappa e l'elenco a discesa Data Column controlla il punteggio di posizione da visualizzare. In questo esempio, viene visualizzato il
normalized_pet_score dall'esempio
dell'opzione 1. Tieni presente che in questo esempio sono state aggiunte altre località alla tabella apartment_listings.
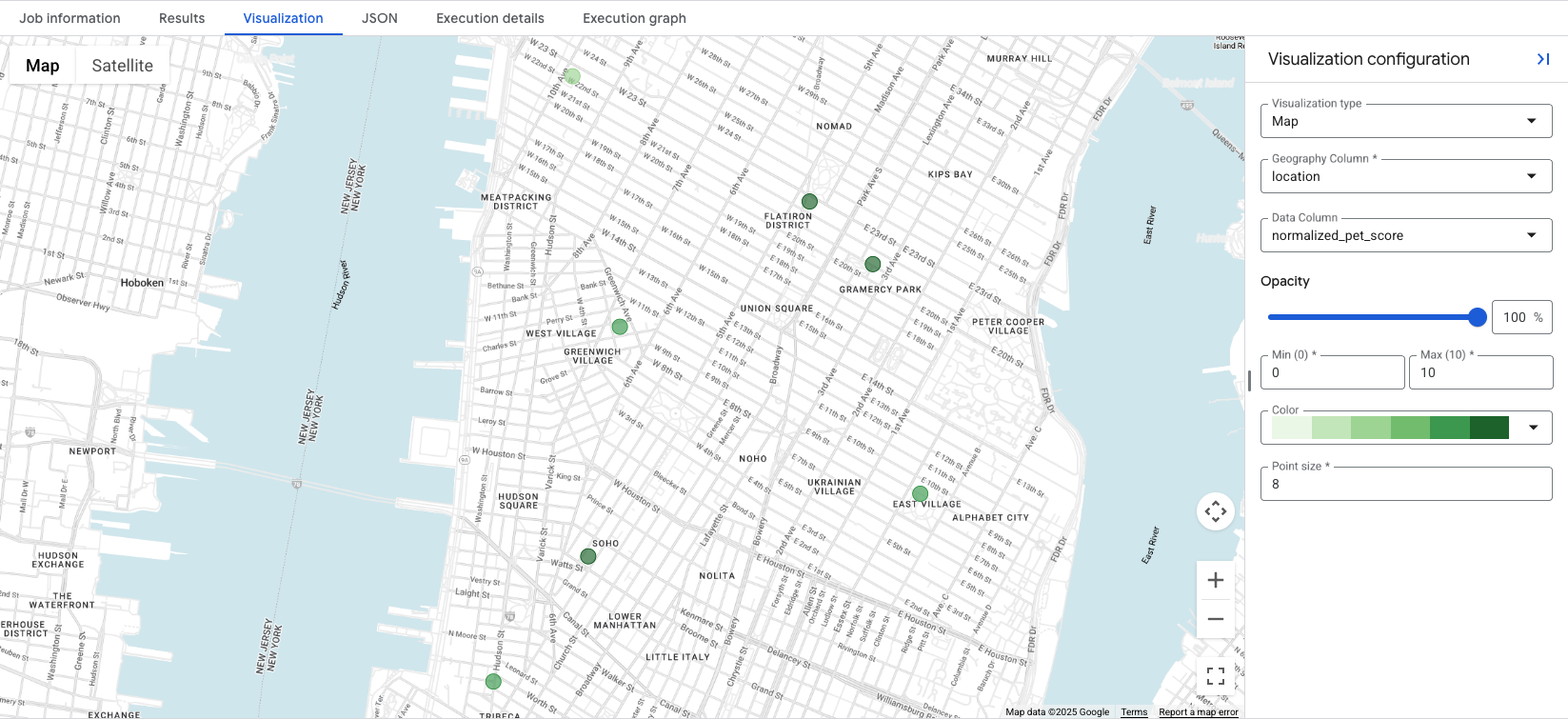
La visualizzazione dei dati rivela a colpo d'occhio le località più adatte al punteggio creato, con cerchi verdi più scuri che rappresentano le località con un normalized_pet_score più alto, in questo caso. Per ulteriori opzioni di visualizzazione dei dati di Places Insights, consulta Visualizzare i risultati delle query.
Conclusione
Ora disponi di una metodologia efficace e ripetibile per creare punteggi di posizione sfumati. Partendo dalle tue località, hai creato una singola query SQL in BigQuery che trova i luoghi nelle vicinanze con ST_DWITHIN, li filtra in base ad attributi avanzati come good_for_children e allows_dogs e aggrega i risultati con COUNTIF. Applicando ponderazioni personalizzate e normalizzando il risultato, hai prodotto un singolo punteggio di facile utilizzo che fornisce approfondimenti approfonditi e utili. Puoi applicare direttamente questo pattern per trasformare i dati sulla posizione non elaborati in un vantaggio competitivo significativo.
Azioni successive
Ora tocca a te creare. Questo tutorial fornisce un modello. Puoi utilizzare le informazioni aggiuntive disponibili nello schema di Places Insights per creare i punteggi più necessari per il tuo caso d'uso. Considera questi altri punteggi che potresti creare:
- "Punteggio di vita notturna": combina i filtri per
primary_type(bar,night_club),price_levele gli orari di apertura notturni per trovare le zone più vivaci dopo il tramonto. - "Punteggio di fitness e benessere": conta i
gyms, iparkse ihealth_food_storesnelle vicinanze e filtra i ristoranti in base a quelli conserves_vegetarian_foodper valutare le località per gli utenti attenti alla salute. - "Punteggio di idoneità per i pendolari": trova le località con un'alta densità di luoghi
transit_stationeparkingnelle vicinanze per aiutare gli utenti che apprezzano l'accesso ai trasporti.
Collaboratori
Henrik Valve | Ingegnere DevX