
Ringkasan
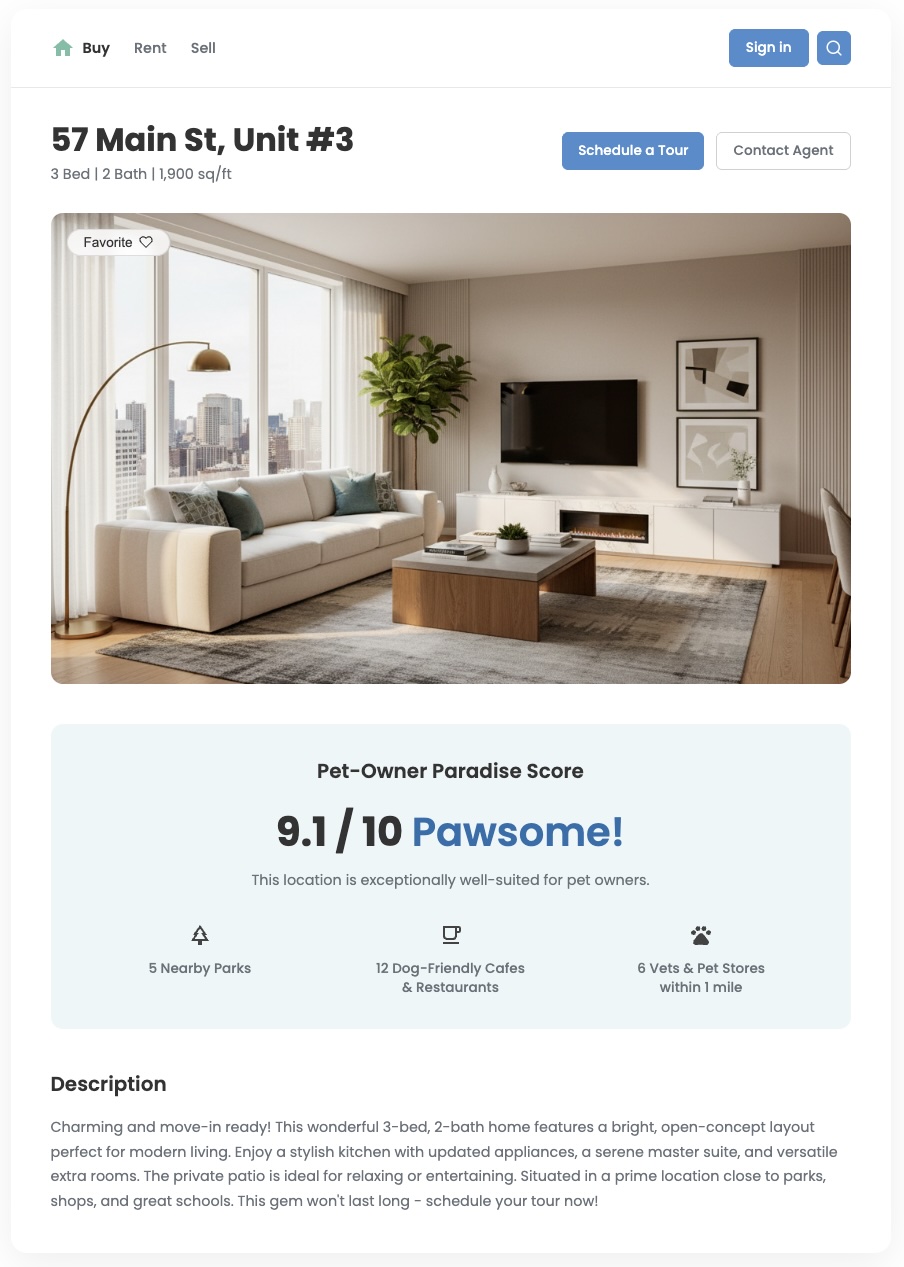
Data lokasi standar dapat memberi tahu Anda apa yang ada di sekitar, tetapi sering kali gagal menjawab pertanyaan yang lebih penting: "Seberapa bagus area ini bagi saya?" Kebutuhan pengguna Anda sangat beragam. Keluarga dengan anak kecil memiliki prioritas yang berbeda dibandingkan dengan profesional muda yang memiliki. Untuk membantu mereka membuat keputusan yang tepat, Anda perlu memberikan insight yang mencerminkan kebutuhan spesifik ini. Skor lokasi kustom adalah alat yang efektif untuk memberikan nilai ini dan menciptakan pengalaman pengguna yang berbeda secara signifikan.
Dokumen ini menjelaskan cara membuat skor lokasi multifaset kustom menggunakan set data Insight Tempat di BigQuery. Dengan mengubah data POI menjadi metrik yang bermakna, Anda dapat memperkaya aplikasi real estate, retail, atau perjalanan dan memberikan informasi relevan yang dibutuhkan pengguna. Kami juga menyediakan opsi untuk menggunakan AI generatif di BigQuery sebagai cara yang efektif untuk menghitung skor lokasi Anda.
Mendorong Nilai Bisnis dengan Skor yang Disesuaikan
Contoh berikut mengilustrasikan cara menerjemahkan data lokasi mentah menjadi metrik yang efektif dan berfokus pada pengguna untuk meningkatkan kualitas aplikasi Anda.
- Developer Real Estate dapat membuat "Skor Ramah Keluarga" atau "Skor Impian Komuter" untuk membantu pembeli dan penyewa memilih lingkungan yang sempurna dan sesuai dengan gaya hidup mereka, sehingga meningkatkan engagement pengguna, prospek berkualitas tinggi, dan konversi yang lebih cepat.
- Travel & Hospitality Engineers dapat membuat "Skor Kehidupan Malam" atau "Skor Surga Wisatawan" untuk membantu wisatawan memilih hotel yang sesuai dengan gaya liburan mereka, sehingga meningkatkan rasio pemesanan dan kepuasan pelanggan
- Analis Retail dapat membuat "Skor Kebugaran & Kesehatan" untuk mengidentifikasi lokasi optimal bagi pusat kebugaran atau toko makanan sehat baru berdasarkan bisnis pelengkap di sekitar, sehingga memaksimalkan potensi untuk menargetkan demografi pengguna yang tepat.
Dalam panduan ini, Anda akan mempelajari metodologi tiga bagian yang fleksibel untuk membuat skor lokasi kustom apa pun menggunakan data Places langsung di BigQuery. Kita akan menggambarkan pola ini dengan membuat dua contoh skor yang berbeda: Skor Ramah Keluarga dan Skor Surga Pemilik Hewan Peliharaan. Dengan pendekatan ini, Anda dapat melampaui jumlah tempat dan memanfaatkan atribut yang kaya dan mendetail dalam set data Insight Tempat. Anda dapat menggunakan informasi seperti jam buka, apakah suatu tempat cocok untuk anak-anak, atau apakah diperbolehkan, untuk membuat metrik yang canggih dan bermakna bagi pengguna Anda.
Alur Kerja Solusi
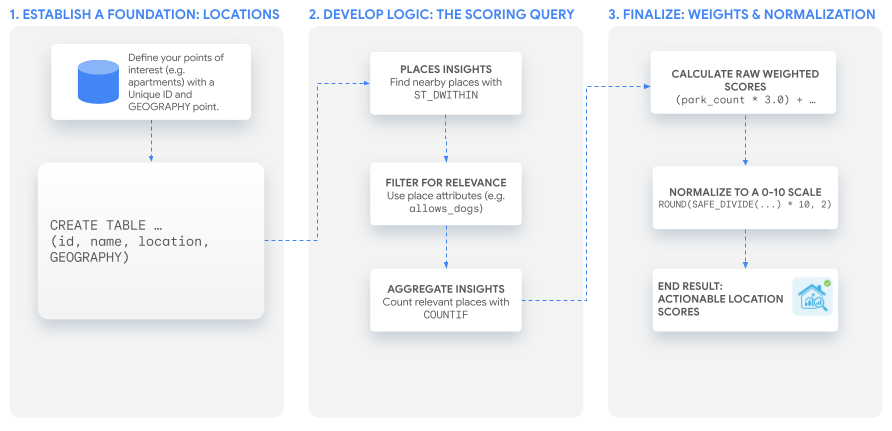
Tutorial ini menggunakan satu kueri SQL yang canggih untuk membuat skor kustom yang dapat Anda sesuaikan dengan kasus penggunaan apa pun. Kita akan membahas proses ini dengan membuat dua contoh skor untuk kumpulan listingan apartemen hipotetis.
Untuk mempelajari alur kerja ini di lingkungan interaktif, jalankan notebook berikut. Contoh ini menunjukkan cara menggunakan fungsi
AI.GENERATE dalam
BigQuery untuk membuat skor lokasi.
 Lihat sumber di GitHub
Lihat sumber di GitHub
Prasyarat
Sebelum memulai, ikuti petunjuk ini untuk menyiapkan Insight Tempat.
1. Membangun Fondasi: Lokasi Minat Anda
Sebelum dapat membuat skor, Anda memerlukan daftar lokasi yang ingin dianalisis. Langkah pertama adalah memastikan data ini ada sebagai tabel di BigQuery.
Kuncinya adalah memiliki ID unik untuk setiap lokasi dan kolom GEOGRAPHY yang menyimpan koordinatnya.
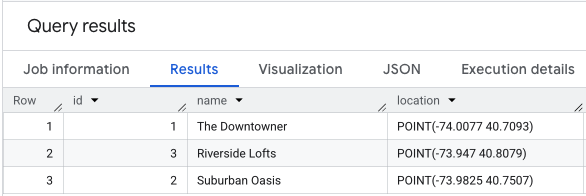
Anda dapat membuat dan mengisi tabel lokasi untuk diberi skor dengan kueri seperti ini:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
Melakukan SELECT * pada data lokasi Anda akan terlihat seperti ini.
2. Mengembangkan Logika Inti: Kueri Pemberian Skor
Setelah lokasi Anda ditetapkan, langkah berikutnya adalah menemukan, memfilter, dan menghitung
tempat terdekat yang relevan dengan skor kustom Anda. Semua ini dilakukan dalam satu pernyataan SELECT.
Menemukan Apa yang Ada di Sekitar dengan Penelusuran Geospasial
Pertama, Anda perlu menemukan semua tempat dari set data Insight Tempat yang berada dalam jarak tertentu dari setiap lokasi Anda. Fungsi BigQuery
ST_DWITHIN sangat cocok untuk tugas ini. Kita akan melakukan JOIN antara tabel
apartment_listings dan tabel places_insights untuk menemukan semua tempat
dalam radius 800 meter. LEFT JOIN memastikan semua lokasi asli Anda disertakan dalam hasil, meskipun tidak ada tempat yang cocok di sekitar.
Filter untuk Relevansi dengan Atribut Lanjutan
Di sinilah Anda menerjemahkan konsep abstrak skor menjadi filter data konkret. Untuk dua contoh skor kami, kriteria yang digunakan berbeda:
- Untuk "Skor Kesesuaian untuk Keluarga", kami memperhatikan taman, museum, dan restoran yang secara eksplisit cocok untuk anak-anak.
- Untuk "Skor Surga Pemilik Hewan Peliharaan", kami memperhatikan taman, klinik hewan, toko hewan peliharaan, dan restoran atau kafe yang mengizinkan.
Anda dapat memfilter atribut tertentu ini langsung dalam klausa WHERE dari
kueri Anda.
Menggabungkan Insight untuk Setiap Lokasi
Terakhir, Anda perlu menghitung berapa banyak tempat yang relevan yang Anda temukan untuk setiap
apartemen. Klausul GROUP BY menggabungkan hasil, dan fungsi COUNTIF
menghitung tempat yang cocok dengan kriteria tertentu untuk setiap skor kami.
Kueri di bawah menggabungkan ketiga langkah ini, menghitung jumlah mentah untuk kedua skor dalam satu proses:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Hasil kueri ini akan mirip dengan ini.
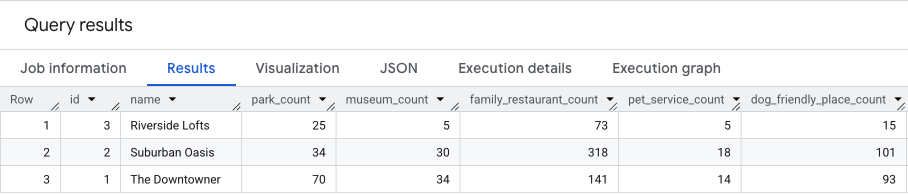
Kita akan membahas hasil ini lebih lanjut di bagian berikutnya.
3. Membuat Skor
Setelah memiliki jumlah tempat dan pembobotan untuk setiap jenis tempat di setiap lokasi, Anda kini dapat membuat skor lokasi kustom. Kita akan membahas dua opsi di bagian ini: menggunakan penghitungan kustom Anda sendiri di BigQuery atau menggunakan fungsi kecerdasan buatan (AI) generatif di BigQuery.
Opsi 1: Menggunakan penghitungan kustom Anda sendiri di BigQuery
Jumlah mentah dari langkah sebelumnya memberikan insight, tetapi tujuannya adalah satu skor yang mudah digunakan. Langkah terakhir adalah menggabungkan jumlah ini menggunakan bobot, lalu menormalisasi hasilnya ke skala 0-10.
Menerapkan Bobot Kustom Memilih bobot adalah seni dan sains. Hal ini harus mencerminkan prioritas bisnis Anda atau apa yang menurut Anda paling penting bagi pengguna. Untuk Skor "Kesesuaian keluarga", Anda dapat memutuskan bahwa taman dua kali lebih penting daripada museum. Mulai dengan asumsi terbaik Anda dan lakukan iterasi berdasarkan masukan pengguna kami.
Menormalisasi Skor Kueri di bawah menggunakan dua Ekspresi Tabel Umum (CTE): yang pertama menghitung jumlah mentah seperti sebelumnya, dan yang kedua menghitung skor berbobot. Pernyataan SELECT terakhir kemudian melakukan normalisasi min-maks pada skor berbobot. Kolom location dari contoh
tabel apartment_listings akan ditampilkan, untuk mengaktifkan visualisasi data di peta.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Hasil kueri akan mirip dengan di bawah ini. Dua kolom terakhir adalah skor yang dinormalisasi.

Memahami Skor yang Dinormalisasi
Penting untuk memahami mengapa langkah normalisasi akhir ini sangat berharga.
Skor berbobot mentah dapat berkisar dari 0 hingga angka yang berpotensi sangat besar, bergantung pada kepadatan perkotaan lokasi Anda. Skor 500 tidak berarti bagi pengguna tanpa konteks.
Normalisasi mengubah angka abstrak ini menjadi peringkat relatif. Dengan menskalakan hasil dari 0 hingga 10, skor mengomunikasikan dengan jelas perbandingan setiap lokasi dengan lokasi lain dalam set data spesifik Anda:
- Skor 10 diberikan ke lokasi dengan skor mentah tertinggi, menandainya sebagai opsi terbaik dalam kumpulan saat ini.
- Skor 0 diberikan ke lokasi dengan skor mentah terendah, sehingga menjadikannya dasar perbandingan. Hal ini tidak berarti lokasi tersebut tidak memiliki fasilitas, tetapi lebih berarti bahwa lokasi tersebut adalah yang paling tidak sesuai dibandingkan dengan opsi lain yang sedang dievaluasi.
- Semua skor lainnya berada di antara kedua skor tersebut secara proporsional, sehingga memberikan cara yang jelas dan intuitif bagi pengguna untuk membandingkan opsi mereka secara sekilas.
Opsi 2: Menggunakan fungsi AI.GENERATE (Gemini)
Sebagai alternatif untuk menggunakan formula matematika tetap, Anda dapat menggunakan fungsi
BigQuery AI.GENERATE
untuk menghitung skor lokasi kustom langsung dalam alur kerja SQL Anda.
Meskipun Opsi 1 sangat baik untuk pemberian skor kuantitatif murni berdasarkan jumlah fasilitas, opsi ini tidak dapat dengan mudah memperhitungkan data kualitatif. Fungsi AI.GENERATE memungkinkan Anda menggabungkan angka dari kueri Insight Tempat dengan data tidak terstruktur, seperti deskripsi teks listingan apartemen (misalnya, "Lokasi ini cocok untuk keluarga dan area ini tenang pada malam hari") atau preferensi profil pengguna tertentu (misalnya, "Pengguna ini memesan untuk keluarga dan lebih suka area yang tenang di lokasi pusat"). Dengan demikian, Anda dapat membuat skor yang lebih bernuansa yang mendeteksi hal-hal halus yang mungkin terlewatkan oleh jumlah yang ketat, seperti lokasi yang memiliki kepadatan fasilitas tinggi, tetapi juga dideskripsikan sebagai 'terlalu bising untuk anak-anak'.
Menyusun Perintah
Untuk menggunakan fungsi ini, hasil agregasi (dari Langkah 2) diformat menjadi perintah bahasa alami. Hal ini dapat dilakukan secara dinamis di SQL dengan menggabungkan kolom data dengan petunjuk untuk model.
Dalam kueri di bawah, insight_counts digabungkan dengan deskripsi teks apartemen untuk membuat perintah bagi setiap baris. Profil pengguna target juga
ditentukan untuk memandu pemberian skor.
Membuat Skor dengan SQL
Kueri berikut melakukan seluruh operasi di BigQuery. Persyaratan ini:
- Menggabungkan jumlah Tempat (seperti yang dijelaskan di Langkah 2).
- Membuat perintah untuk setiap lokasi.
- Memanggil fungsi
AI.GENERATEuntuk menganalisis perintah menggunakan model Gemini. - Mengurai hasil ke dalam format terstruktur yang siap digunakan di aplikasi Anda.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Memahami Konfigurasi
- Pemahaman Biaya: Fungsi ini meneruskan input Anda ke model Gemini dan dikenai biaya di Vertex AI setiap kali dipanggil. Jika sejumlah besar lokasi sedang dianalisis (misalnya, ribuan listingan apartemen), sebaiknya filter set data ke kandidat yang paling relevan terlebih dahulu. Untuk mengetahui detail selengkapnya tentang cara meminimalkan biaya, lihat Praktik Terbaik.
endpoint:gemini-flash-latestditentukan untuk contoh ini guna memprioritaskan kecepatan dan efisiensi biaya. Namun, Anda dapat memilih model yang paling sesuai dengan kebutuhan Anda. Lihat dokumentasi model Gemini untuk bereksperimen dengan berbagai versi (misalnya, Gemini Pro untuk tugas penalaran yang lebih kompleks) dan temukan yang paling sesuai dengan kasus penggunaan Anda.output_schema: Daripada mengurai teks mentah, skema diterapkan (FLOAT64untuk skor danSTRINGuntuk alasan). Hal ini memastikan output dapat langsung digunakan di aplikasi atau alat visualisasi Anda tanpa perlu diproses lebih lanjut.
Contoh Output
Kueri menampilkan tabel BigQuery standar dengan skor kustom dan alasan model.
| id | nama | family_friendliness_score | penalaran |
|---|---|---|---|
| 1 | The Downtowner | 5,5 | Jumlah fasilitas yang sangat baik (taman, restoran), memenuhi metrik kuantitatif. Namun, data kualitatif menunjukkan kebisingan berlebihan di akhir pekan dan fokus yang kuat pada kehidupan malam, yang bertentangan langsung dengan kebutuhan pengguna target akan ketenangan. |
| 2 | Oasis di Pinggiran Kota | 9.8 | Data kuantitatif yang luar biasa dikombinasikan dengan deskripsi ("jalan yang tenang dan dikelilingi pepohonan") yang sangat sesuai dengan profil keluarga target. Pengubah positif tinggi menghasilkan skor yang hampir sempurna. |
Prosedur ini memungkinkan Anda memberikan pemberian skor yang sangat dipersonalisasi yang terasa dapat dipahami dan disesuaikan dengan setiap pengguna, semuanya dalam satu kueri SQL.
4. Memvisualisasikan skor Anda di peta
BigQuery Studio menyertakan visualisasi peta terintegrasi untuk hasil kueri apa pun yang berisi kolom GEOGRAPHY. Karena kueri kita menampilkan
kolom location, Anda dapat langsung memvisualisasikan skor Anda.
Mengklik tab Visualization akan menampilkan peta, dan drop-down Data Column
mengontrol skor lokasi yang akan divisualisasikan. Dalam contoh ini, normalized_pet_score divisualisasikan dari contoh Opsi 1. Perhatikan bahwa lebih banyak lokasi ditambahkan ke tabel apartment_listings untuk contoh ini.
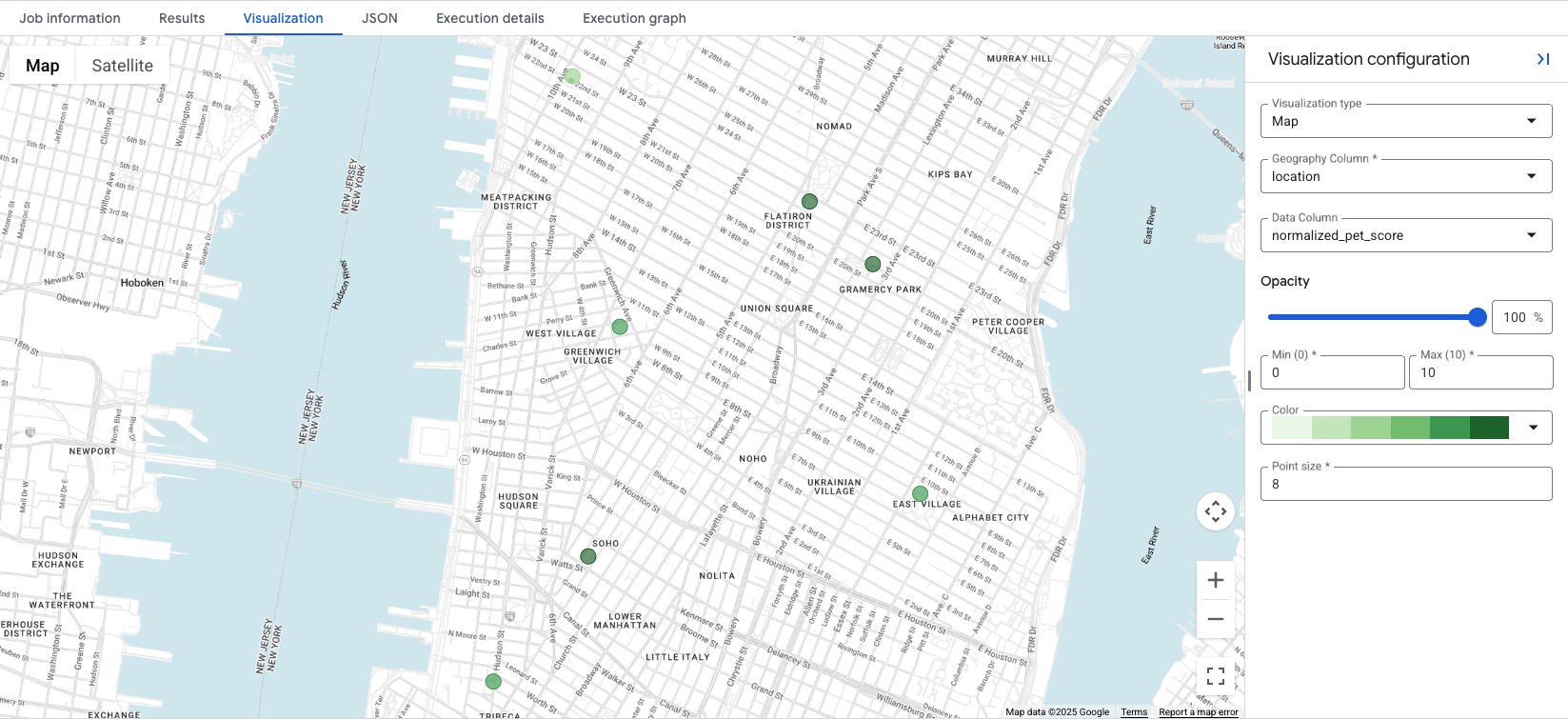
Visualisasi data akan menunjukkan sekilas lokasi yang paling sesuai untuk skor yang dibuat, dengan lingkaran hijau yang lebih gelap mewakili lokasi dengan normalized_pet_score yang lebih tinggi, dalam hal ini. Untuk opsi visualisasi data Places Insights lebih lanjut, lihat Memvisualisasikan hasil kueri.
Kesimpulan
Sekarang Anda memiliki metodologi yang efektif dan dapat diulang untuk membuat skor lokasi yang bernuansa. Dengan memulai dari lokasi Anda, Anda membuat satu kueri SQL di BigQuery yang menemukan tempat terdekat dengan ST_DWITHIN, memfilternya menurut atribut lanjutan seperti good_for_children dan allows_dogs, serta menggabungkan hasilnya dengan COUNTIF. Dengan menerapkan bobot kustom dan menormalisasi hasilnya,
Anda menghasilkan skor tunggal yang mudah digunakan dan memberikan insight
mendalam yang dapat ditindaklanjuti. Anda dapat menerapkan pola ini secara langsung untuk mengubah data lokasi mentah menjadi keunggulan kompetitif yang signifikan.
Tindakan Berikutnya
Sekarang giliran Anda untuk membangun. Tutorial ini menyediakan template. Anda dapat menggunakan data lengkap yang tersedia dalam skema Insight Tempat untuk membuat skor yang paling diperlukan untuk kasus penggunaan Anda. Pertimbangkan skor lainnya yang dapat Anda bangun:
- "Skor Kehidupan Malam": Gabungkan filter untuk
primary_type(bar,night_club),price_level, dan jam buka larut malam untuk menemukan area paling ramai setelah hari gelap. - "Skor Kebugaran & Kesehatan": Menghitung
gyms,parks, danhealth_food_storesdi sekitar, serta memfilter restoran yang memilikiserves_vegetarian_fooduntuk memberi skor lokasi bagi pengguna yang peduli kesehatan. - "Skor Impian Komuter": Temukan lokasi dengan kepadatan tinggi tempat
transit_stationdanparkingdi sekitar untuk membantu pengguna yang menghargai akses ke transportasi.
Kontributor
Henrik Valve | DevX Engineer