
खास जानकारी
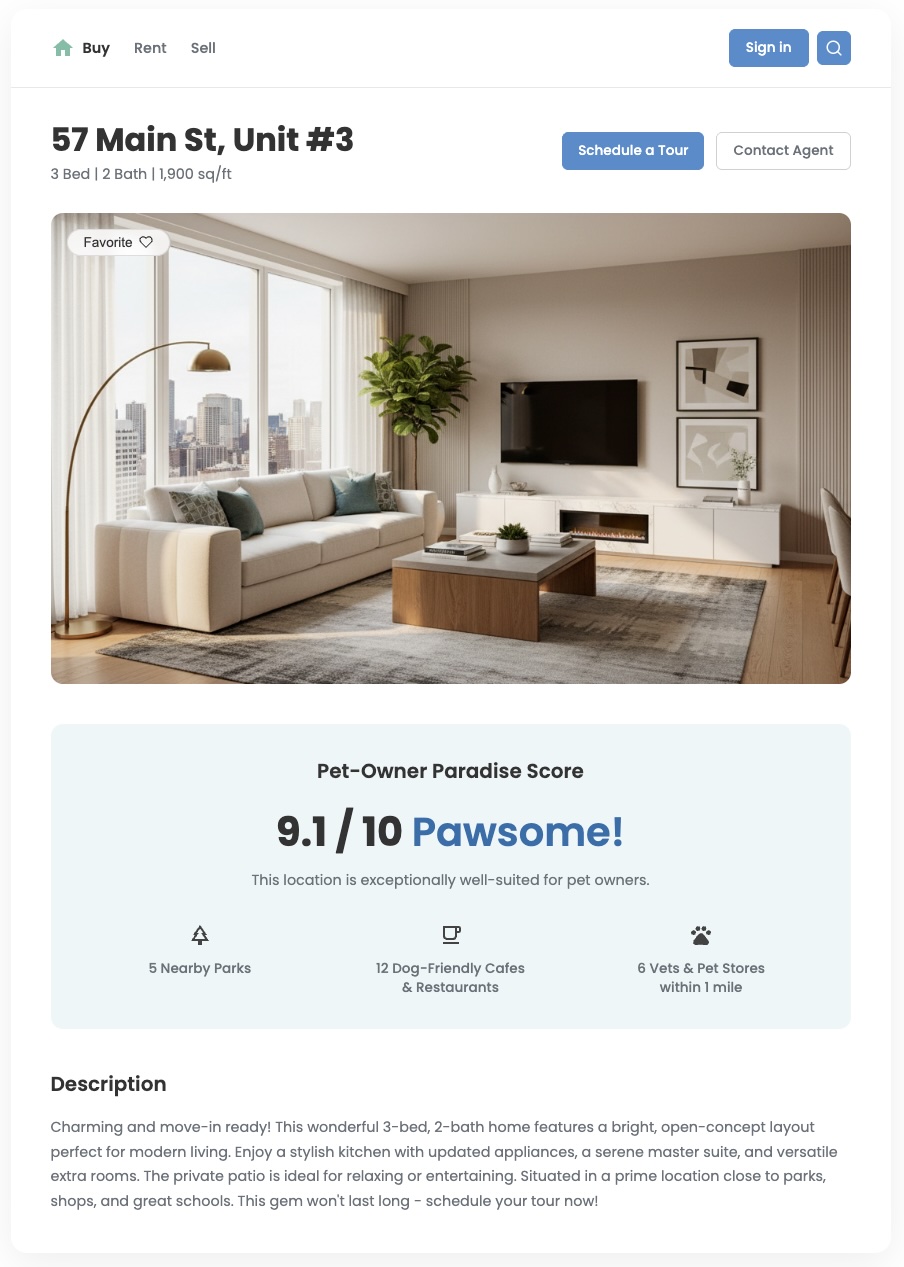
जगह की जानकारी के स्टैंडर्ड डेटा से, आपको यह पता चल सकता है कि आस-पास क्या-क्या है. हालांकि, इससे अक्सर इस ज़्यादा ज़रूरी सवाल का जवाब नहीं मिलता: "यह इलाका मेरे लिए कैसा है?" आपके उपयोगकर्ताओं की ज़रूरतें अलग-अलग हैं. छोटे बच्चों वाले परिवार की प्राथमिकताएं, कुत्ते के साथ रहने वाले युवा पेशेवर की प्राथमिकताओं से अलग होती हैं. उन्हें भरोसे के साथ फ़ैसले लेने में मदद करने के लिए, आपको ऐसी अहम जानकारी देनी होगी जिससे उनकी इन खास ज़रूरतों के बारे में पता चले. कस्टम लोकेशन स्कोर, इस वैल्यू को डिलीवर करने और उपयोगकर्ताओं को अलग अनुभव देने का एक असरदार टूल है.
इस दस्तावेज़ में, BigQuery में Places Insights डेटासेट का इस्तेमाल करके, कई पहलुओं के आधार पर जगह के कस्टम स्कोर बनाने का तरीका बताया गया है. पीओआई डेटा को काम की मेट्रिक में बदलकर, अपने रियल एस्टेट, खुदरा, या यात्रा से जुड़े ऐप्लिकेशन को बेहतर बनाया जा सकता है. साथ ही, उपयोगकर्ताओं को उनकी ज़रूरत के हिसाब से काम की जानकारी दी जा सकती है. हम आपको BigQuery में जनरेटिव एआई का इस्तेमाल करने का विकल्प भी देते हैं. इससे आपको लोकेशन के स्कोर का हिसाब लगाने में मदद मिलती है.
ज़रूरत के मुताबिक बनाए गए स्कोर की मदद से, कारोबार को आगे बढ़ाना
यहां दिए गए उदाहरणों में बताया गया है कि अपने ऐप्लिकेशन को बेहतर बनाने के लिए, जगह की जानकारी के रॉ डेटा को उपयोगकर्ता के हिसाब से काम की मेट्रिक में कैसे बदला जा सकता है.
- रियल एस्टेट डेवलपर, "परिवार के हिसाब से सही जगह का स्कोर" या "आसानी से यात्रा करने के हिसाब से सही जगह का स्कोर" बना सकते हैं. इससे खरीदारों और किराएदारों को अपनी लाइफ़स्टाइल के हिसाब से सही जगह चुनने में मदद मिलती है. इससे यूज़र ऐक्टिविटी बढ़ती है, बेहतर क्वालिटी वाली लीड मिलती हैं, और कन्वर्ज़न तेज़ी से होते हैं.
- यात्रा और होटल इंडस्ट्री के इंजीनियर, "नाइटलाइफ़ स्कोर" या "घूमने-फिरने के शौकीन लोगों के लिए सबसे अच्छी जगह का स्कोर" बना सकते हैं. इससे यात्रियों को उनकी छुट्टियों के हिसाब से होटल चुनने में मदद मिलती है. साथ ही, बुकिंग की दरें बढ़ती हैं और ग्राहक संतुष्ट होते हैं
- खुदरा विश्लेषक, "फ़िटनेस और वेलनेस स्कोर" जनरेट कर सकते हैं. इससे उन्हें यह पता लगाने में मदद मिलती है कि नया जिम या सेहतमंद खाना बेचने वाली दुकान खोलने के लिए सबसे सही जगह कौनसी है. इसके लिए, वे आस-पास के पूरक कारोबारों के साथ-साथ, सही उपयोगकर्ता जनसांख्यिकी को टारगेट करने की ज़्यादा से ज़्यादा संभावनाओं को ध्यान में रखते हैं.
इस गाइड में, आपको BigQuery में सीधे तौर पर जगहों के डेटा का इस्तेमाल करके, किसी भी तरह का कस्टम लोकेशन स्कोर बनाने का एक आसान तरीका बताया जाएगा. इसमें तीन चरण होते हैं. हम इस पैटर्न को दो अलग-अलग उदाहरण स्कोर बनाकर दिखाएंगे: परिवार के लिए सही होने का स्कोर और पालतू जानवरों के लिए सही होने का स्कोर. इस तरीके से, जगहों की संख्या के अलावा, जगहों की अहम जानकारी देने वाले डेटासेट में मौजूद ज़्यादा जानकारी वाले एट्रिब्यूट का फ़ायदा उठाया जा सकता है. अपने उपयोगकर्ताओं के लिए बेहतर और काम की मेट्रिक बनाने के लिए, इस तरह की जानकारी का इस्तेमाल किया जा सकता है: कारोबार के खुलने और बंद होने का समय, किसी जगह पर बच्चों को ले जाने की अनुमति है या नहीं या वहां कुत्तों को ले जाने की अनुमति है या नहीं.
सॉल्यूशन वर्कफ़्लो
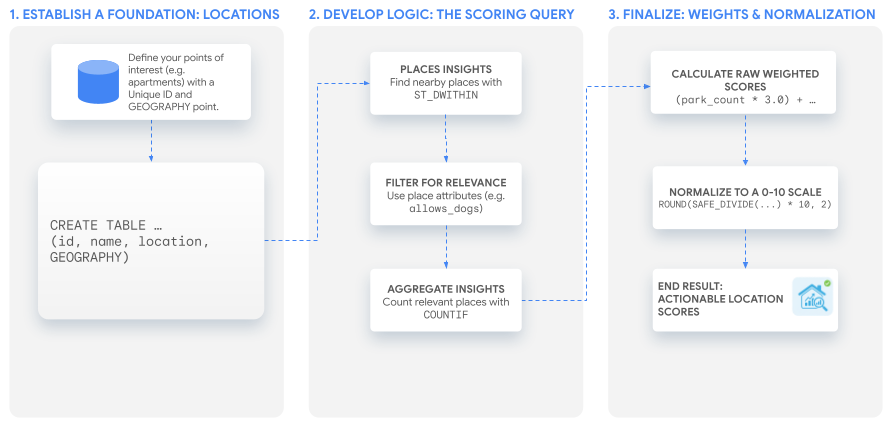
इस ट्यूटोरियल में, कस्टम स्कोर बनाने के लिए एक ही एसक्यूएल क्वेरी का इस्तेमाल किया गया है. इसे किसी भी इस्तेमाल के उदाहरण के हिसाब से बदला जा सकता है. हम इस प्रोसेस को समझने के लिए, अपार्टमेंट की लिस्टिंग के एक काल्पनिक सेट के लिए दो उदाहरण स्कोर बनाएंगे.
इंटरैक्टिव एनवायरमेंट में इस वर्कफ़्लो को एक्सप्लोर करने के लिए, यहां दिया गया नोटबुक चलाएं. इसमें बताया गया है कि BigQuery में AI.GENERATE फ़ंक्शन का इस्तेमाल करके, जगह के हिसाब से स्कोर कैसे बनाया जाता है.
 GitHub पर सोर्स देखें
GitHub पर सोर्स देखें
ज़रूरी शर्तें
शुरू करने से पहले, Places Insights को सेट अप करने के लिए इन निर्देशों का पालन करें.
1. बुनियाद बनाना: दिलचस्पी वाली जगहें
स्कोर बनाने से पहले, आपको उन जगहों की सूची चाहिए जिनका आपको विश्लेषण करना है. सबसे पहले, यह पक्का करें कि यह डेटा, BigQuery में टेबल के तौर पर मौजूद हो.
हर जगह के लिए एक यूनीक आइडेंटिफ़ायर और एक GEOGRAPHY
कॉलम होना ज़रूरी है, जिसमें उसके निर्देशांक सेव किए जाते हैं.
जगहों की टेबल बनाई जा सकती है और उसमें डेटा भरा जा सकता है. इसके बाद, इस तरह की क्वेरी से स्कोर किया जा सकता है:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
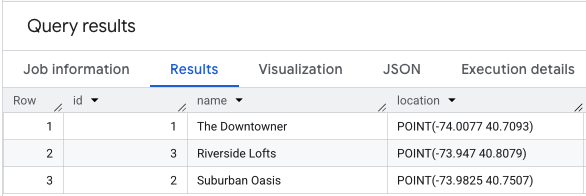
जगह की जानकारी के डेटा पर SELECT * करने पर, आपको कुछ ऐसा दिखेगा.
2. कोर लॉजिक डेवलप करना: स्कोरिंग क्वेरी
जगहें तय करने के बाद, अगला चरण यह है कि आस-पास की उन जगहों को खोजें, फ़िल्टर करें, और उनकी गिनती करें जो आपके कस्टम स्कोर के हिसाब से काम की हैं. यह सब एक ही SELECT स्टेटमेंट में किया जाता है.
जियोस्पेशल सर्च की मदद से, आस-पास की चीज़ें ढूंढना
सबसे पहले, आपको Places Insights डेटासेट में मौजूद उन सभी जगहों का पता लगाना होगा जो आपकी हर जगह से एक तय दूरी पर हैं. इसके लिए, BigQuery का ST_DWITHIN फ़ंक्शन सबसे सही है. हम 800 मीटर के दायरे में मौजूद सभी जगहों का पता लगाने के लिए, अपनी apartment_listings टेबल और places_insights टेबल के बीच JOIN करेंगे. LEFT JOIN से यह पक्का किया जाता है कि खोज के नतीजों में आपकी सभी मूल जगहें शामिल हों. भले ही, आस-पास कोई मिलती-जुलती जगह न मिली हो.
ऐडवांस एट्रिब्यूट की मदद से, काम के प्रॉडक्ट फ़िल्टर करना
यहां स्कोर के ऐब्सट्रैक्ट कॉन्सेप्ट को डेटा फ़िल्टर में बदला जाता है. उदाहरण के तौर पर दिए गए दो स्कोर के लिए, मानदंड अलग-अलग हैं:
- "परिवार के लिए सही जगह होने का स्कोर" के लिए, हम उन पार्कों, म्यूज़ियम, और रेस्टोरेंट को ध्यान में रखते हैं जो खास तौर पर बच्चों के लिए अच्छे होते हैं.
- "पालतू जानवरों के मालिकों के लिए स्वर्ग" स्कोर के लिए, हम पार्क, पशु चिकित्सालय, पालतू जानवरों के स्टोर, और ऐसे रेस्टोरेंट या कैफ़े को ध्यान में रखते हैं जहां कुत्तों को अनुमति है.
इन एट्रिब्यूट को सीधे तौर पर, अपनी क्वेरी के WHERE क्लॉज़ में फ़िल्टर किया जा सकता है.
हर जगह के लिए अहम जानकारी इकट्ठा करना
आखिर में, आपको यह गिनना होगा कि हर अपार्टमेंट के लिए, आपको कितनी काम की जगहें मिलीं. GROUP BY क्लॉज़, नतीजों को इकट्ठा करता है. साथ ही, COUNTIF फ़ंक्शन, उन जगहों की गिनती करता है जो हमारे हर स्कोर के लिए तय की गई शर्तों को पूरा करती हैं.
नीचे दी गई क्वेरी में, इन तीनों चरणों को एक साथ इस्तेमाल किया गया है. इससे एक ही बार में, दोनों स्कोर की रॉ गिनती का पता चलता है:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
इस क्वेरी का नतीजा कुछ ऐसा होगा.
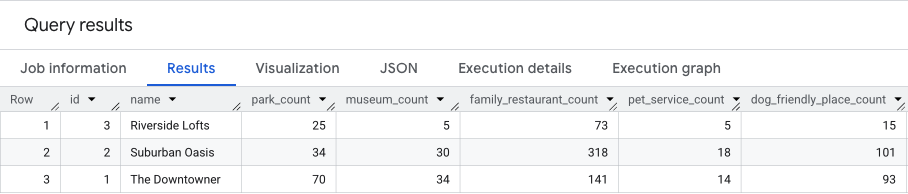
हम अगले सेक्शन में इन नतीजों के बारे में ज़्यादा जानकारी देंगे.
3. स्कोर बनाना
अब आपके पास हर जगह के टाइप के लिए, जगहों की संख्या और वेटिंग की जानकारी है. साथ ही, हर जगह के लिए कस्टम लोकेशन स्कोर जनरेट किया जा सकता है. इस सेक्शन में, हम दो विकल्पों के बारे में बात करेंगे: BigQuery में अपनी कस्टम कैलकुलेशन का इस्तेमाल करना या BigQuery में जनरेटिव आर्टिफ़िशियल इंटेलिजेंस (एआई) फ़ंक्शन का इस्तेमाल करना.
पहला विकल्प: BigQuery में अपनी कस्टम कैलकुलेशन का इस्तेमाल करना
पिछले चरण की रॉ गिनती से अहम जानकारी मिलती है. हालांकि, हमारा लक्ष्य एक ऐसा स्कोर तैयार करना है जो उपयोगकर्ता के लिए आसान हो. आखिरी चरण में, इन संख्याओं को वज़न के हिसाब से जोड़कर, नतीजे को 0 से 10 के स्केल पर सामान्य किया जाता है.
कस्टम वेटेज (महत्व) लागू करना वेटेज (महत्व) चुनना एक कला और विज्ञान, दोनों है. इनमें आपके कारोबार की प्राथमिकताएं या वह जानकारी शामिल होनी चाहिए जो आपके हिसाब से उपयोगकर्ताओं के लिए सबसे अहम है. "परिवार के लिए सही" स्कोर के लिए, यह तय किया जा सकता है कि पार्क, म्यूज़ियम से दोगुना ज़रूरी है. सबसे पहले, अपने सबसे अच्छे अनुमानों के आधार पर काम शुरू करें. इसके बाद, उपयोगकर्ताओं के सुझावों के आधार पर इसमें बदलाव करें.
स्कोर को सामान्य बनाना यहां दी गई क्वेरी में दो कॉमन टेबल एक्सप्रेशन (सीटीई) का इस्तेमाल किया गया है: पहला सीटीई, पहले की तरह रॉ काउंट का हिसाब लगाता है. वहीं, दूसरा सीटीई, वेटेज वाले स्कोर का हिसाब लगाता है. इसके बाद, फ़ाइनल SELECT स्टेटमेंट, वज़न के हिसाब से मिले स्कोर पर कम से कम और ज़्यादा से ज़्यादा वैल्यू के बीच के अंतर को सामान्य करता है. उदाहरण के तौर पर दी गई location टेबल का apartment_listings कॉलम, आउटपुट के तौर पर दिखाया गया है, ताकि मैप पर डेटा विज़ुअलाइज़ेशन को चालू किया जा सके.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
क्वेरी के नतीजे, यहां दिए गए नतीजों से मिलते-जुलते होंगे. आखिरी दो कॉलम, नॉर्मलाइज़ किए गए स्कोर हैं.

सामान्य किए गए स्कोर के बारे में जानकारी
यह समझना ज़रूरी है कि सामान्य बनाने का यह आखिरी चरण इतना अहम क्यों है.
वज़न के हिसाब से मिले रॉ स्कोर, 0 से लेकर बहुत ज़्यादा तक हो सकते हैं. यह इस बात पर निर्भर करता है कि आपकी जगहों पर शहरी घनत्व कितना है. किसी उपयोगकर्ता के लिए, कॉन्टेक्स्ट के बिना 500 स्कोर का कोई मतलब नहीं होता.
सामान्य बनाने की प्रोसेस, इन ऐब्स्ट्रैक्ट नंबर को रिलेटिव रैंकिंग में बदल देती है. नतीजों को 0 से 10 तक स्केल करके, स्कोर से साफ़ तौर पर पता चलता है कि आपके डेटासेट में मौजूद हर जगह की तुलना, दूसरी जगहों से कैसे की जाती है:
- सबसे ज़्यादा रॉ स्कोर वाली जगह को 10 का स्कोर असाइन किया जाता है. इससे यह पता चलता है कि मौजूदा सेट में यह सबसे अच्छा विकल्प है.
- सबसे कम रॉ स्कोर वाली जगह को 0 का स्कोर असाइन किया जाता है. इससे तुलना करने के लिए बेसलाइन तय होती है. इसका मतलब यह नहीं है कि जगह पर कोई सुविधा नहीं है. इसका मतलब यह है कि यह जगह, अन्य विकल्पों की तुलना में सबसे कम सही है.
- बाकी सभी स्कोर, इनके बीच में आते हैं. इससे उपयोगकर्ताओं को एक नज़र में अपने विकल्पों की तुलना करने का आसान और बेहतर तरीका मिलता है.
दूसरा विकल्प: AI.GENERATE फ़ंक्शन (Gemini) का इस्तेमाल करना
गणित के तय फ़ॉर्मूले का इस्तेमाल करने के बजाय, BigQuery AI.GENERATE फ़ंक्शन का इस्तेमाल किया जा सकता है. इससे, सीधे तौर पर अपने एसक्यूएल वर्कफ़्लो में कस्टम लोकेशन स्कोर का हिसाब लगाया जा सकता है.
पहला विकल्प, सुविधाओं की संख्या के आधार पर सिर्फ़ मात्रात्मक स्कोरिंग के लिए सबसे अच्छा है. हालांकि, इसमें गुणात्मक डेटा को आसानी से शामिल नहीं किया जा सकता. AI.GENERATE फ़ंक्शन की मदद से, Places Insights क्वेरी के नंबर को बिना किसी स्ट्रक्चर वाले डेटा के साथ जोड़ा जा सकता है. जैसे, अपार्टमेंट की लिस्टिंग का टेक्स्ट ब्यौरा (उदाहरण के लिए, "यह जगह परिवारों के लिए सही है और यहाँ रात में शांति रहती है") या उपयोगकर्ता की प्रोफ़ाइल की खास प्राथमिकताएँ (उदाहरण के लिए, "यह उपयोगकर्ता परिवार के लिए बुकिंग कर रहा है और इसे ऐसी जगह चाहिए जो शहर के बीच में हो और शांत हो"). इससे आपको ज़्यादा बारीकी से स्कोर जनरेट करने में मदद मिलती है. इससे ऐसी बारीकियां भी पता चलती हैं जो सिर्फ़ गिनती करने से नहीं पता चलतीं. जैसे, किसी जगह पर सुविधाएं ज़्यादा हैं, लेकिन उसे 'बच्चों के लिए बहुत शोरगुल वाली जगह' के तौर पर भी बताया गया है.
प्रॉम्प्ट बनाना
इस फ़ंक्शन का इस्तेमाल करने के लिए, एग्रीगेशन (दूसरे चरण से) के नतीजों को आम भाषा में प्रॉम्प्ट के तौर पर फ़ॉर्मैट किया जाता है. एसक्यूएल में, डेटा कॉलम को मॉडल के निर्देशों के साथ जोड़कर, इसे डाइनैमिक तौर पर किया जा सकता है.
नीचे दी गई क्वेरी में, insight_counts को अपार्टमेंट के बारे में दी गई जानकारी के साथ जोड़ा गया है, ताकि हर लाइन के लिए एक प्रॉम्प्ट बनाया जा सके. स्कोरिंग के लिए, टारगेट उपयोगकर्ता प्रोफ़ाइल भी तय की जाती है.
एसक्यूएल की मदद से स्कोर जनरेट करना
नीचे दी गई क्वेरी, BigQuery में पूरा ऑपरेशन करती है. इससे:
- यह चरण 2 में बताए गए तरीके से, जगहों की संख्या को एग्रीगेट करता है.
- यह हर जगह के लिए एक प्रॉम्प्ट बनाता है.
- Calls the
AI.GENERATEfunction to analyze the prompt using the Gemini model. - यह नतीजे को स्ट्रक्चर्ड फ़ॉर्मैट में पार्स करता है, ताकि इसे आपके ऐप्लिकेशन में इस्तेमाल किया जा सके.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
कॉन्फ़िगरेशन के बारे में जानकारी
- लागत की जानकारी: यह फ़ंक्शन, आपके इनपुट को Gemini मॉडल को पास करता है. साथ ही, Vertex AI में हर बार इसे कॉल करने पर शुल्क लगता है. अगर बड़ी संख्या में जगहों का विश्लेषण किया जा रहा है (जैसे, अपार्टमेंट की हज़ारों लिस्टिंग), तो हमारा सुझाव है कि डेटासेट को फ़िल्टर करके, सबसे काम के उम्मीदवारों को पहले दिखाया जाए. लागत कम करने के बारे में ज़्यादा जानने के लिए, सबसे सही तरीके देखें.
endpoint: इस उदाहरण में,gemini-flash-latestको इसलिए चुना गया है, ताकि तेज़ी से और कम लागत में काम किया जा सके. हालांकि, अपनी ज़रूरतों के हिसाब से मॉडल चुना जा सकता है. Gemini के मॉडल से जुड़ा दस्तावेज़ देखें.इसमें अलग-अलग वर्शन (जैसे, ज़्यादा मुश्किल तर्कों वाले कामों के लिए Gemini Pro) आज़माने के बारे में बताया गया है. इससे आपको अपने इस्तेमाल के हिसाब से सबसे सही वर्शन ढूंढने में मदद मिलेगी.output_schema: रॉ टेक्स्ट को पार्स करने के बजाय, स्कीमा लागू किया जाता है (स्कोर के लिएFLOAT64और वजह के लिएSTRING). इससे यह पक्का होता है कि आउटपुट को पोस्ट-प्रोसेसिंग के बिना, आपके ऐप्लिकेशन या विज़ुअलाइज़ेशन टूल में तुरंत इस्तेमाल किया जा सकता है.
आउटपुट का उदाहरण
क्वेरी, कस्टम स्कोर और मॉडल के तर्क के साथ एक स्टैंडर्ड BigQuery टेबल दिखाती है.
| आईडी | नाम | family_friendliness_score | गहराई से विश्लेषण करना |
|---|---|---|---|
| 1 | The Downtowner | 5.5 | यहां पार्क और रेस्टोरेंट जैसी सुविधाएं अच्छी संख्या में हैं. साथ ही, यहां मात्रात्मक मेट्रिक पूरी की जाती हैं. हालांकि, क्वालिटी डेटा से पता चलता है कि वीकेंड पर बहुत ज़्यादा शोर होता है और नाइटलाइफ़ पर ज़्यादा फ़ोकस किया जाता है. यह सीधे तौर पर टारगेट किए गए उपयोगकर्ता की शांति की ज़रूरत के ख़िलाफ़ है. |
| 2 | सबर्बन ओएसिस | 9.8 | बेहतरीन संख्यात्मक डेटा के साथ-साथ, ऐसा ब्यौरा ("शांत, पेड़ों वाली सड़क") दिया गया है जो टारगेट की गई फ़ैमिली प्रोफ़ाइल से पूरी तरह मेल खाता है. ज़्यादा पॉज़िटिव मॉडिफ़ायर से, लगभग सही स्कोर मिलता है. |
इस प्रोसेस की मदद से, हर उपयोगकर्ता के लिए अलग-अलग स्कोरिंग की जा सकती है. साथ ही, यह भी तय किया जा सकता है कि स्कोरिंग को हर उपयोगकर्ता के हिसाब से बनाया जाए. यह सब एक ही एसक्यूएल क्वेरी में किया जा सकता है.
4. मैप पर अपने स्कोर देखना
BigQuery Studio में, GEOGRAPHY कॉलम वाले क्वेरी के किसी भी नतीजे के लिए, इंटिग्रेटेड मैप विज़ुअलाइज़ेशन शामिल होता है. हमारी क्वेरी से location कॉलम का आउटपुट मिलता है. इसलिए, आपको अपने स्कोर तुरंत दिख सकते हैं.
Visualization टैब पर क्लिक करने से मैप खुल जाएगा. साथ ही, Data Column ड्रॉप-डाउन से, जगह की जानकारी के स्कोर को विज़ुअलाइज़ किया जा सकेगा. इस उदाहरण में, पहले विकल्प के उदाहरण से normalized_pet_score को विज़ुअलाइज़ किया गया है. ध्यान दें कि इस उदाहरण के लिए, apartment_listings टेबल में ज़्यादा जगहें जोड़ी गई हैं.
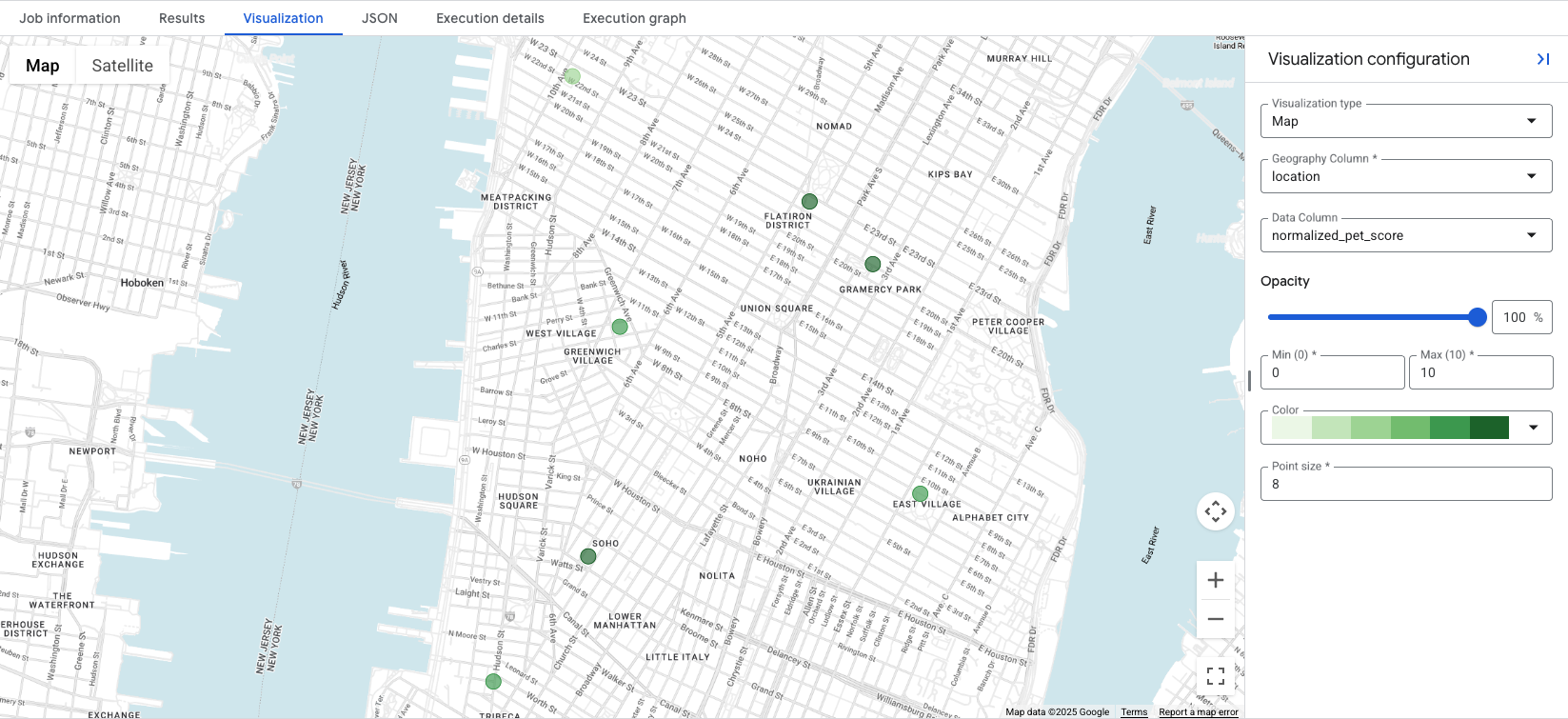
डेटा को विज़ुअलाइज़ करने से, बनाए गए स्कोर के लिए सबसे सही जगहों के बारे में एक नज़र में पता चलता है. गहरे हरे रंग के सर्कल से उन जगहों के बारे में पता चलता है जहां normalized_pet_score ज़्यादा है. जगह की अहम जानकारी वाले डेटा को विज़ुअलाइज़ करने के अन्य विकल्पों के लिए, क्वेरी के नतीजों को विज़ुअलाइज़ करना लेख पढ़ें.
नतीजा
अब आपके पास, सटीक लोकेशन स्कोर बनाने के लिए एक असरदार और बार-बार इस्तेमाल की जा सकने वाली कार्यप्रणाली है. आपने अपनी जगहों के हिसाब से, BigQuery में एक एसक्यूएल क्वेरी बनाई. इससे आस-पास की जगहों का पता चलता है. साथ ही, ST_DWITHIN जैसे ऐडवांस एट्रिब्यूट के हिसाब से फ़िल्टर किया जाता है और good_for_children और allows_dogs जैसे एट्रिब्यूट के हिसाब से एग्रीगेट किया जाता है. इसके बाद, COUNTIF के हिसाब से नतीजे दिखाए जाते हैं. आपने कस्टम वेट लागू करके और नतीजे को सामान्य करके, उपयोगकर्ता के लिए आसान स्कोर जनरेट किया. इससे काम की अहम जानकारी मिलती है. इस पैटर्न को सीधे तौर पर लागू करके, जगह की जानकारी के रॉ डेटा को
एक अहम कॉम्पटिटिव फ़ायदे में बदला जा सकता है.
अगली कार्रवाइयां
अब आपकी बारी है. इस ट्यूटोरियल में एक टेंप्लेट दिया गया है. Places Insights स्कीमा में उपलब्ध रिच डेटा का इस्तेमाल करके, ऐसे स्कोर बनाए जा सकते हैं जो आपके इस्तेमाल के उदाहरण के लिए सबसे ज़रूरी हैं. इन अन्य स्कोर को भी बनाया जा सकता है:
- "नाइटलाइफ़ स्कोर":
primary_type(bar,night_club),price_level, और देर रात तक खुले रहने वाले कारोबारों के लिए फ़िल्टर को एक साथ इस्तेमाल करें. इससे, अंधेरा होने के बाद सबसे ज़्यादा चहल-पहल वाले इलाके ढूंढने में मदद मिलती है. - "फ़िटनेस और वेलनेस स्कोर": आस-पास मौजूद
gyms,parks, औरhealth_food_storesकी संख्या गिनें. साथ ही, सेहत के बारे में जागरूक लोगों के लिए,serves_vegetarian_foodवाले रेस्टोरेंट को फ़िल्टर करें, ताकि जगहों को स्कोर किया जा सके. - "कम्यूटर का ड्रीम स्कोर": आस-पास मौजूद
transit_stationऔरparkingजगहों की ज़्यादा संख्या वाली जगहों का पता लगाएं. इससे उन लोगों की मदद की जा सकती है जो परिवहन की सुविधाओं को अहमियत देते हैं.
योगदानकर्ता
हेनरिक वाल्व | DevX इंजीनियर