
Présentation
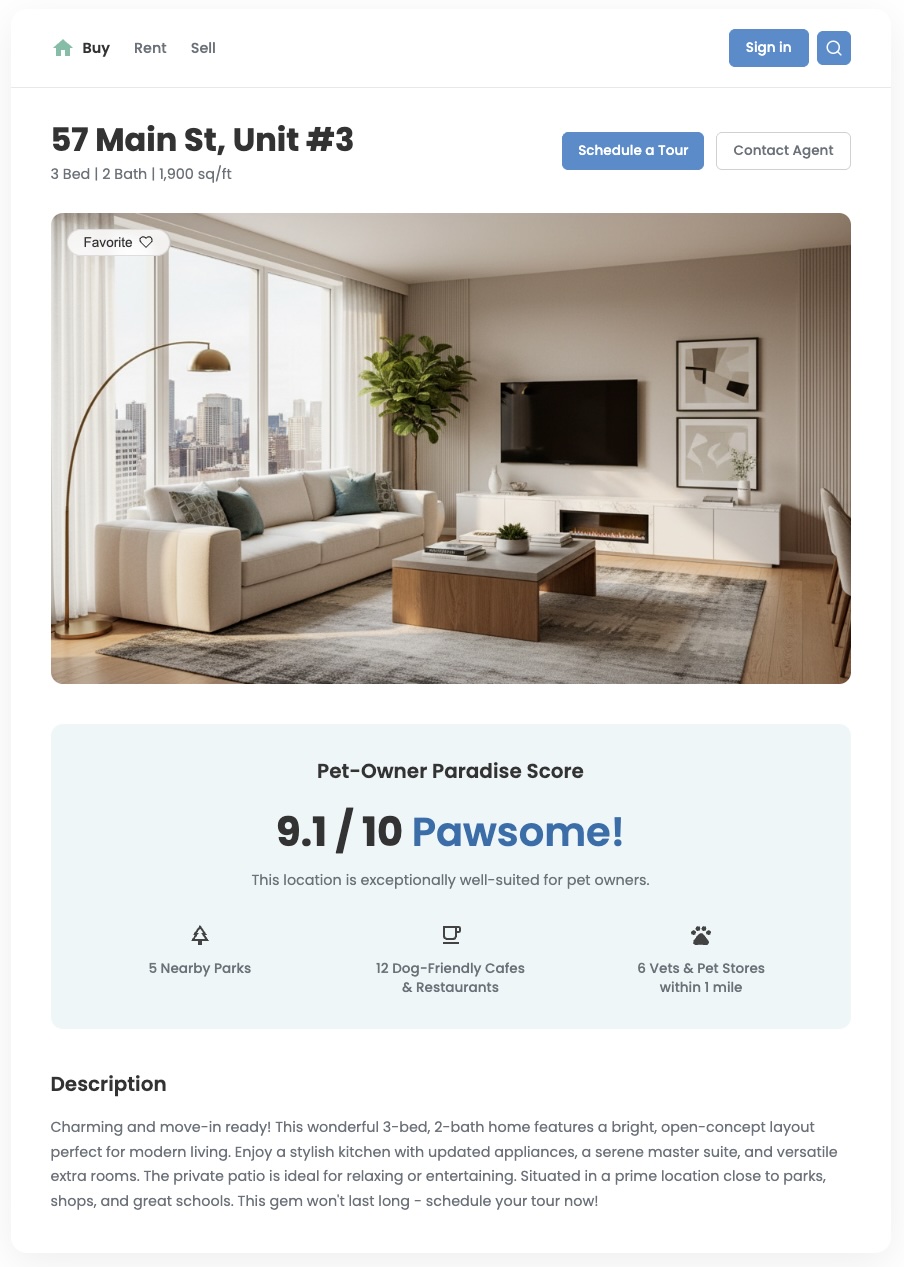
Les données de localisation standards peuvent vous indiquer ce qui se trouve à proximité, mais elles ne répondent souvent pas à la question la plus importante : "Cette zone est-elle intéressante pour moi ?" Les besoins de vos utilisateurs sont nuancés. Les priorités d'une famille avec de jeunes enfants sont différentes de celles d'un jeune professionnel avec un chien. Pour les aider à prendre des décisions éclairées, vous devez leur fournir des insights qui reflètent ces besoins spécifiques. Un score de localisation personnalisé est un outil puissant pour offrir cette valeur et créer une expérience utilisateur différenciée significative.
Ce document explique comment créer des scores de localisation personnalisés et multifacettes à l'aide de l'ensemble de données Places Insights dans BigQuery. En transformant les données de points d'intérêt en métriques pertinentes, vous pouvez enrichir vos applications immobilières, commerciales ou de voyage, et fournir à vos utilisateurs les informations dont ils ont besoin. Nous vous proposons également d'utiliser l'IA générative dans BigQuery pour calculer vos scores de localisation de manière efficace.
Générez de la valeur commerciale grâce à des scores personnalisés
Les exemples suivants illustrent comment traduire des données brutes de localisation en métriques puissantes axées sur l'utilisateur pour améliorer votre application.
- Les promoteurs immobiliers peuvent créer un "score de convivialité pour les familles" ou un "score de rêve pour les navetteurs" afin d'aider les acheteurs et les locataires à choisir le quartier idéal qui correspond à leur style de vie. Cela permet d'accroître l'engagement des utilisateurs, d'obtenir des prospects de meilleure qualité et d'accélérer les conversions.
- Les ingénieurs du secteur du voyage et de l'hôtellerie peuvent créer un "score de vie nocturne" ou un "score de paradis des touristes" pour aider les voyageurs à choisir un hôtel qui correspond à leur style de vacances, ce qui augmente les taux de réservation et la satisfaction des clients.
- Les analystes du secteur de la vente au détail peuvent générer un "score de forme et de bien-être" pour identifier l'emplacement optimal d'une nouvelle salle de sport ou d'un nouveau magasin d'aliments diététiques en fonction des établissements complémentaires à proximité. Ils peuvent ainsi maximiser le potentiel de ciblage de la bonne tranche d'âge.
Dans ce guide, vous allez découvrir une méthodologie flexible en trois parties pour créer n'importe quel type de score de localisation personnalisé à l'aide des données Places directement dans BigQuery. Nous allons illustrer ce modèle en créant deux exemples de scores distincts : un score de convivialité pour les familles et un score de paradis pour les propriétaires d'animaux de compagnie. Cette approche vous permet d'aller au-delà du nombre de lieux et de profiter des attributs riches et détaillés de l'ensemble de données Places Insights. Vous pouvez utiliser des informations telles que les horaires d'ouverture, si un lieu est adapté aux enfants ou s'il autorise les chiens pour créer des métriques sophistiquées et pertinentes pour vos utilisateurs.
Solution workflow
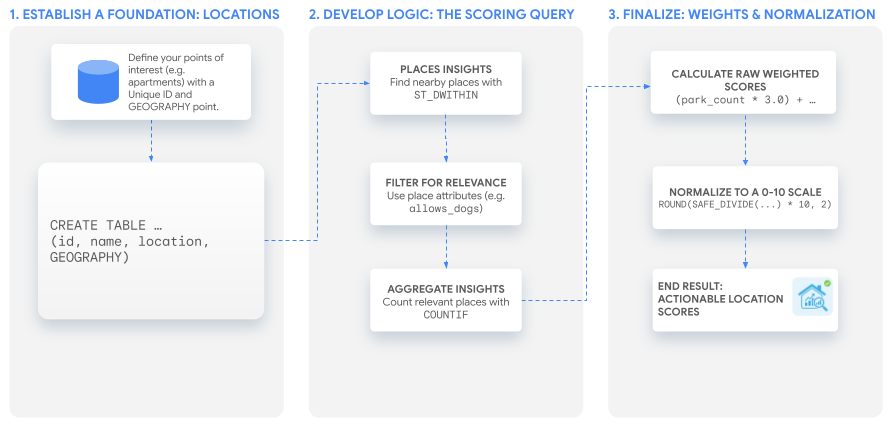
Ce tutoriel utilise une requête SQL unique et puissante pour créer un score personnalisé que vous pouvez adapter à n'importe quel cas d'utilisation. Nous allons passer en revue ce processus en créant nos deux exemples de scores pour un ensemble hypothétique d'annonces d'appartements.
Pour explorer ce workflow dans un environnement interactif, exécutez le notebook suivant. Il montre comment utiliser la fonction AI.GENERATE dans BigQuery pour créer un score de localisation.
 Afficher la source sur GitHub
Afficher la source sur GitHub
Prérequis
Avant de commencer, suivez ces instructions pour configurer Places Insights.
1. Établir une base : vos lieux d'intérêt
Avant de pouvoir créer des scores, vous avez besoin d'une liste des établissements que vous souhaitez analyser. La première étape consiste à s'assurer que ces données existent sous forme de tableau dans BigQuery.
L'essentiel est d'avoir un identifiant unique pour chaque emplacement et une colonne GEOGRAPHY qui stocke ses coordonnées.
Vous pouvez créer et remplir une table de lieux à évaluer avec une requête comme celle-ci :
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
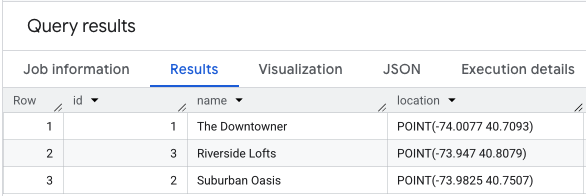
Voici à quoi ressemblerait une SELECT * sur vos données de localisation.
2. Développer la logique principale : la requête de notation
Une fois vos établissements définis, l'étape suivante consiste à trouver, filtrer et comptabiliser les lieux à proximité qui sont pertinents pour votre score personnalisé. Tout cela se fait dans une seule instruction SELECT.
Trouver ce qui se trouve à proximité avec une recherche géospatiale
Vous devez d'abord trouver tous les lieux du jeu de données Places Insights qui se trouvent à une certaine distance de chacun de vos établissements. La fonction BigQuery ST_DWITHIN est idéale pour cela. Nous allons effectuer une JOIN entre notre table apartment_listings et la table places_insights pour trouver tous les lieux situés dans un rayon de 800 mètres. Un LEFT JOIN garantit que tous vos lieux d'origine sont inclus dans les résultats, même si aucun lieu correspondant n'est trouvé à proximité.
Filtrer par pertinence avec des attributs avancés
C'est là que vous traduisez le concept abstrait d'un score en filtres de données concrets. Pour nos deux exemples de scores, les critères sont différents :
- Pour le "score d'aptitude pour les familles", nous nous intéressons aux parcs, musées et restaurants qui sont explicitement adaptés aux enfants.
- Pour le "score de paradis des propriétaires d'animaux de compagnie", nous nous intéressons aux parcs, aux cliniques vétérinaires, aux animaleries, ainsi qu'aux restaurants et cafés qui acceptent les chiens.
Vous pouvez filtrer ces attributs spécifiques directement dans la clause WHERE de votre requête.
Regrouper les insights pour chaque établissement
Enfin, vous devez compter le nombre de lieux pertinents que vous avez trouvés pour chaque appartement. La clause GROUP BY agrège les résultats, et la fonction COUNTIF comptabilise les lieux qui correspondent aux critères spécifiques de chacun de nos scores.
La requête ci-dessous combine ces trois étapes et calcule les nombres bruts pour les deux scores en une seule passe :
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Le résultat de cette requête sera semblable à celui-ci.
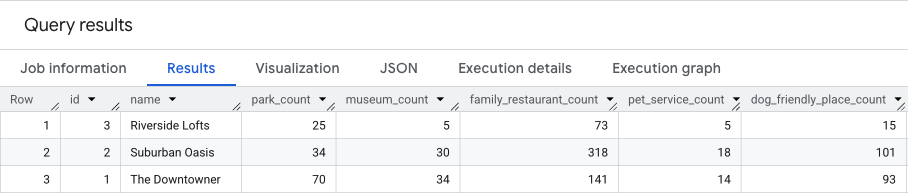
Nous nous appuierons sur ces résultats dans la section suivante.
3. Créer le score
Maintenant que vous disposez du nombre de lieux et de la pondération pour chaque type de lieu et pour chaque emplacement, vous pouvez générer le score personnalisé de l'emplacement. Dans cette section, nous allons aborder deux options : utiliser votre propre calcul personnalisé dans BigQuery ou utiliser les fonctions d'intelligence artificielle (IA) générative dans BigQuery.
Option 1 : Utiliser votre propre calcul personnalisé dans BigQuery
Les nombres bruts de l'étape précédente sont intéressants, mais l'objectif est d'obtenir un score unique et convivial. La dernière étape consiste à combiner ces nombres à l'aide de pondérations, puis à normaliser le résultat sur une échelle de 0 à 10.
Appliquer des pondérations personnalisées : choisir vos pondérations est à la fois un art et une science. Elles doivent refléter les priorités de votre entreprise ou ce qui vous semble le plus important pour vos utilisateurs. Pour un score de "Convivialité familiale", vous pouvez décider qu'un parc est deux fois plus important qu'un musée. Commencez par vos meilleures hypothèses et itérez en fonction des commentaires des utilisateurs.
Normaliser le score La requête ci-dessous utilise deux expressions de table courantes (CTE) : la première calcule les nombres bruts comme précédemment, et la seconde calcule les scores pondérés. L'instruction SELECT finale effectue ensuite une normalisation min-max sur les scores pondérés. La colonne location du tableau apartment_listings de l'exemple est générée pour permettre la visualisation des données sur une carte.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Les résultats de la requête seront semblables à ceux ci-dessous. Les deux dernières colonnes correspondent aux scores normalisés.

Comprendre le score normalisé
Il est important de comprendre pourquoi cette dernière étape de normalisation est si précieuse.
Les scores pondérés bruts peuvent aller de 0 à un nombre potentiellement très élevé, en fonction de la densité urbaine de vos établissements. Un score de 500 n'a aucun sens pour un utilisateur sans contexte.
La normalisation transforme ces nombres abstraits en classement relatif. En mettant les résultats sur une échelle de 0 à 10, le score indique clairement comment chaque établissement se compare aux autres dans votre ensemble de données spécifique :
- La note 10 est attribuée à l'établissement ayant obtenu le score brut le plus élevé, ce qui indique qu'il s'agit de la meilleure option de l'ensemble actuel.
- Le score 0 est attribué à l'établissement ayant obtenu le score brut le plus bas, ce qui en fait la référence pour la comparaison. Cela ne signifie pas que l'établissement ne dispose d'aucun équipement, mais plutôt qu'il est le moins adapté par rapport aux autres options évaluées.
- Tous les autres scores se situent proportionnellement entre ces deux extrêmes, ce qui permet à vos utilisateurs de comparer clairement et intuitivement leurs options en un coup d'œil.
Option 2 : Utiliser la fonction AI.GENERATE (Gemini)
Au lieu d'utiliser une formule mathématique fixe, vous pouvez utiliser la fonction AI.GENERATE de BigQuery pour calculer des scores de localisation personnalisés directement dans votre workflow SQL.
L'option 1 est idéale pour une évaluation purement quantitative basée sur le nombre de commodités, mais elle ne permet pas d'intégrer facilement des données qualitatives. La fonction AI.GENERATE vous permet de combiner les chiffres de votre requête Places Insights avec des données non structurées, comme la description textuelle de l'annonce d'appartement (par exemple, "Ce logement convient aux familles et le quartier est calme la nuit") ou des préférences spécifiques du profil utilisateur (par exemple, "Cet utilisateur réserve pour une famille et préfère un quartier calme dans un emplacement central"). Cela vous permet de générer un score plus nuancé qui détecte les subtilités qu'un décompte strict pourrait manquer, comme un lieu ayant une forte densité d'équipements, mais également décrit comme "trop bruyant pour les enfants".
Construire la requête
Pour utiliser cette fonction, les résultats de l'agrégation (étape 2) sont mis en forme dans une requête en langage naturel. Vous pouvez le faire de manière dynamique en SQL en concaténant des colonnes de données avec des instructions pour le modèle.
Dans la requête ci-dessous, les insight_counts sont combinés à la description textuelle de l'appartement pour créer un prompt pour chaque ligne. Un profil utilisateur cible est également défini pour guider la notation.
Générer le score avec SQL
La requête suivante effectue l'intégralité de l'opération dans BigQuery. En voici certains :
- Agrège le nombre de lieux (comme décrit à l'étape 2).
- Construit une requête pour chaque emplacement.
- Appelle la fonction
AI.GENERATEpour analyser la requête à l'aide du modèle Gemini. - Analyse le résultat dans un format structuré prêt à être utilisé dans votre application.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Comprendre la configuration
- Sensibilisation aux coûts : cette fonction transmet votre saisie à un modèle Gemini et entraîne des frais dans Vertex AI chaque fois qu'elle est appelée. Si un grand nombre de lieux sont analysés (par exemple, des milliers d'annonces d'appartements), il est recommandé de filtrer d'abord l'ensemble de données pour ne retenir que les candidats les plus pertinents. Pour en savoir plus sur la réduction des coûts, consultez les bonnes pratiques.
endpoint:gemini-flash-latestest spécifié pour cet exemple afin de privilégier la rapidité et la rentabilité. Toutefois, vous pouvez choisir le modèle qui répond le mieux à vos besoins. Consultez la documentation sur les modèles Gemini pour tester différentes versions (par exemple, Gemini Pro pour les tâches de raisonnement plus complexes) et trouver celle qui convient le mieux à votre cas d'utilisation.output_schema: au lieu d'analyser le texte brut, un schéma est appliqué (FLOAT64pour le score etSTRINGpour le raisonnement). Cela garantit que le résultat est immédiatement utilisable dans vos outils d'application ou de visualisation sans post-traitement.
Exemple de résultat
La requête renvoie une table BigQuery standard avec le score personnalisé et le raisonnement du modèle.
| id | nom | family_friendliness_score | raisonnement |
|---|---|---|---|
| 1 | The Downtowner | 5,5 | Excellent nombre d'équipements (parcs, restaurants), répondant aux métriques quantitatives. Cependant, les données qualitatives indiquent un bruit excessif le week-end et une forte concentration de vie nocturne, ce qui est en contradiction directe avec le besoin de calme de l'utilisateur cible. |
| 2 | Oasis suburbaine | 9,8 | Données quantitatives exceptionnelles combinées à une description ("rue calme et arborée") qui correspond parfaitement au profil de la famille cible. Les modificateurs positifs élevés génèrent un score presque parfait. |
Cette procédure vous permet de fournir une évaluation très personnalisée, compréhensible et adaptée à chaque utilisateur, le tout dans une seule requête SQL.
4. Visualiser vos scores sur une carte
BigQuery Studio inclut une visualisation de carte intégrée pour tout résultat de requête contenant une colonne GEOGRAPHY. Étant donné que notre requête génère la colonne location, vous pouvez visualiser immédiatement vos scores.
Cliquez sur l'onglet Visualization pour afficher la carte. Le menu déroulant Data Column permet de sélectionner le score de localisation à visualiser. Dans cet exemple, normalized_pet_score est visualisé à partir de l'exemple de l'option 1. Notez que d'autres lieux ont été ajoutés à la table apartment_listings pour cet exemple.
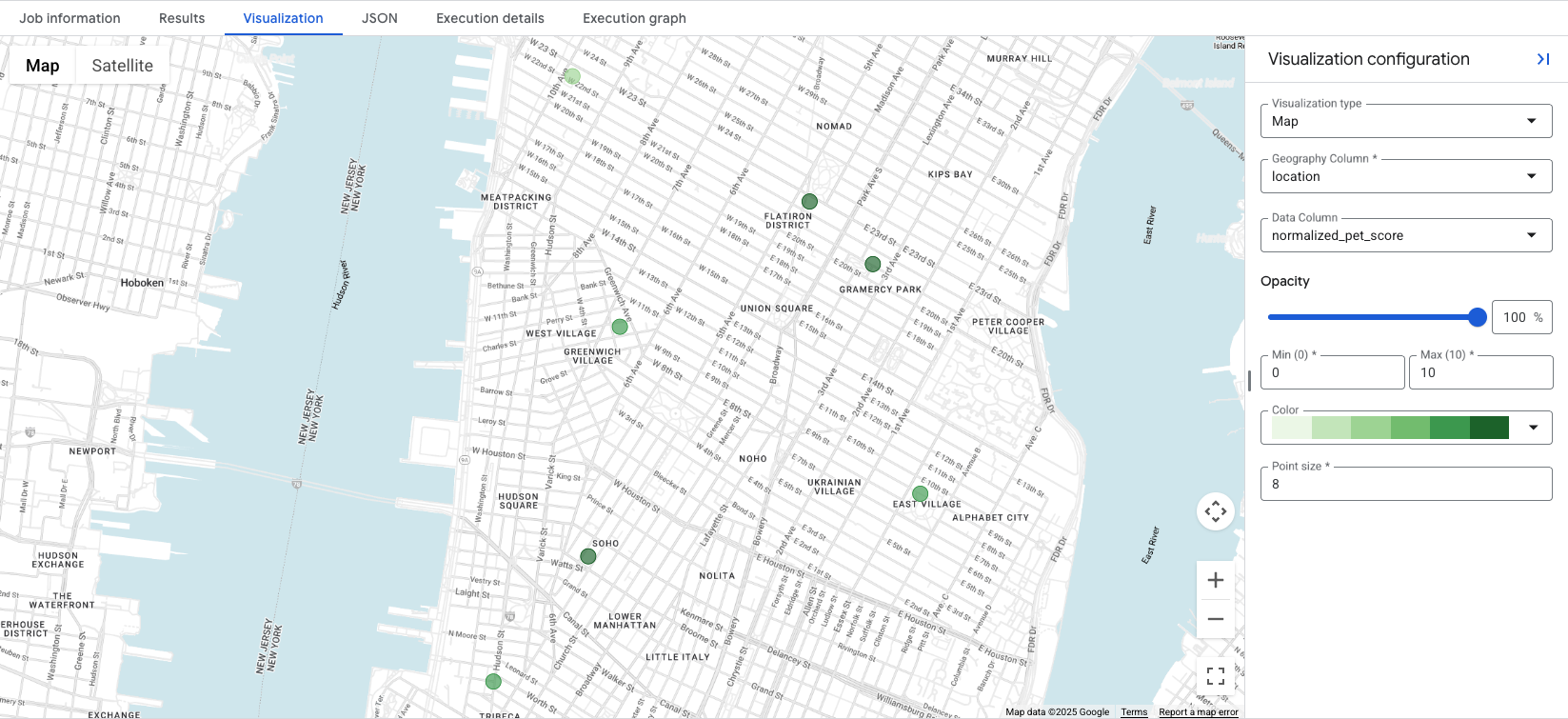
La visualisation des données révèle en un coup d'œil les emplacements les plus appropriés pour le score créé, les cercles vert foncé représentant les emplacements avec un normalized_pet_score plus élevé dans ce cas. Pour en savoir plus sur les options de visualisation des données Places Insights, consultez Visualiser les résultats des requêtes.
Conclusion
Vous disposez désormais d'une méthodologie puissante et reproductible pour créer des scores de localisation nuancés. En partant de vos établissements, vous avez créé une requête SQL unique dans BigQuery qui trouve les lieux à proximité avec ST_DWITHIN, les filtre par attributs avancés tels que good_for_children et allows_dogs, et agrège les résultats avec COUNTIF. En appliquant des pondérations personnalisées et en normalisant le résultat, vous avez obtenu un score unique et facile à utiliser qui fournit des insights approfondis et exploitables. Vous pouvez appliquer directement ce modèle pour transformer les données brutes de localisation en un avantage concurrentiel significatif.
Actions suivantes
À vous de jouer ! Ce tutoriel fournit un modèle. Vous pouvez utiliser les données enrichies disponibles dans le schéma Places Insights pour créer les scores les plus adaptés à votre cas d'utilisation. Voici d'autres scores que vous pouvez créer :
- Score "Vie nocturne" : combinez les filtres pour
primary_type(bar,night_club),price_levelet les horaires d'ouverture tardifs pour trouver les quartiers les plus animés après la tombée de la nuit. - Score de forme et de bien-être : compte le nombre de
gyms,parksethealth_food_storesà proximité, et filtre les restaurants en fonction de ceux qui proposentserves_vegetarian_foodpour attribuer un score aux établissements pour les utilisateurs soucieux de leur santé. - Score"Rêve du pendulaire" : identifiez les lieux où se trouvent de nombreux
transit_stationetparkingà proximité pour aider les utilisateurs qui apprécient d'avoir accès aux transports.
Contributeurs
Henrik Valve | Ingénieur DevX