
نمای کلی
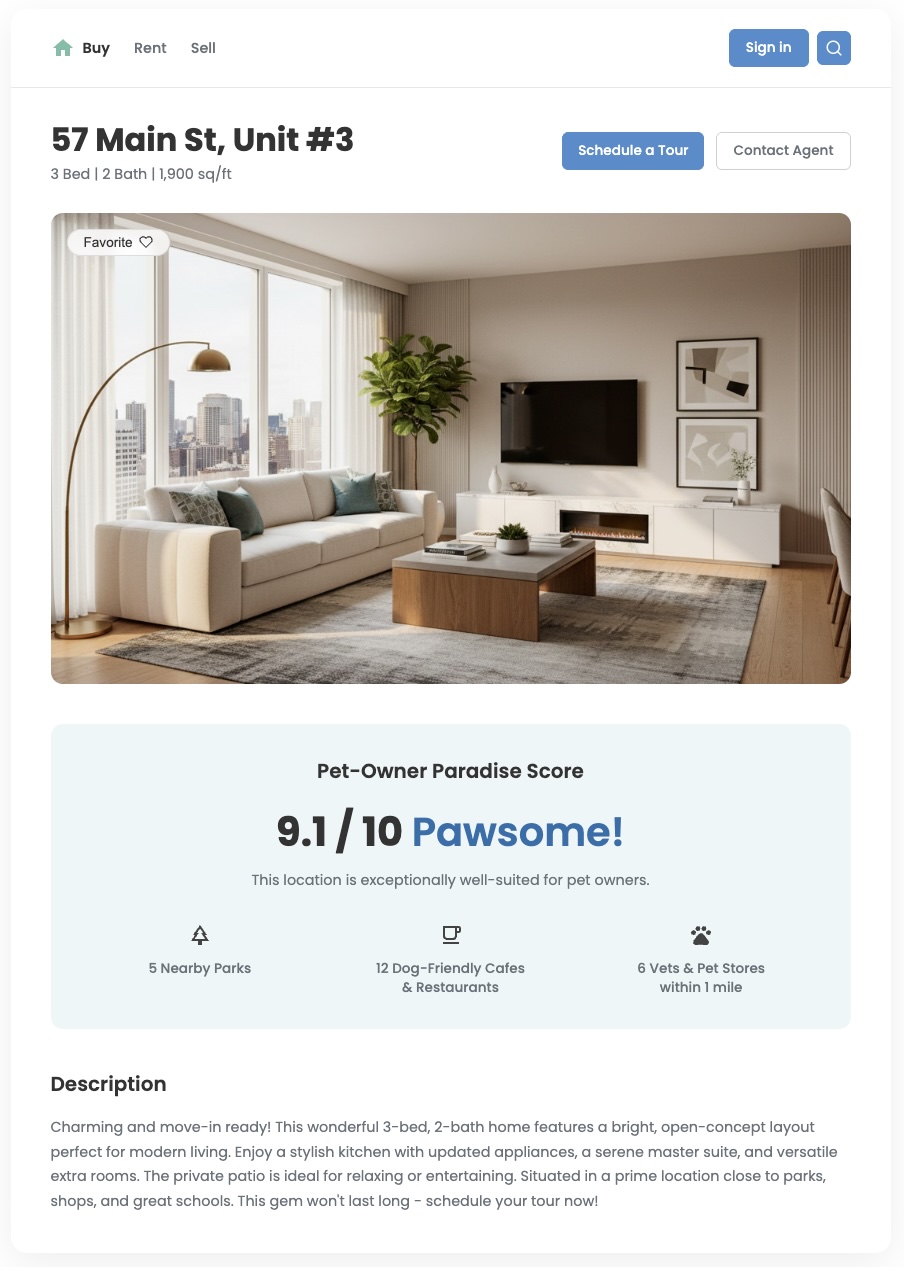
دادههای استاندارد موقعیت مکانی میتوانند به شما بگویند چه چیزهایی در نزدیکی شما هستند، اما اغلب نمیتوانند به سوال مهمتر پاسخ دهند: "این منطقه چقدر برای من خوب است؟" نیازهای کاربران شما متنوع است. یک خانواده با فرزندان خردسال در مقایسه با یک متخصص جوان با سگ، اولویتهای متفاوتی دارند. برای کمک به آنها در تصمیمگیریهای مطمئن، باید بینشهایی ارائه دهید که منعکس کننده این نیازهای خاص باشد. امتیاز موقعیت مکانی سفارشی ابزاری قدرتمند برای ارائه این ارزش و ایجاد یک تجربه کاربری متمایز و قابل توجه است.
این سند نحوه ایجاد امتیازات مکانی سفارشی و چندوجهی را با استفاده از مجموعه دادههای Places Insights در BigQuery شرح میدهد. با تبدیل دادههای POI به معیارهای معنادار، میتوانید برنامههای املاک، خردهفروشی یا مسافرتی خود را غنیسازی کرده و اطلاعات مرتبط مورد نیاز کاربران را در اختیار آنها قرار دهید. ما همچنین گزینهای را برای استفاده از هوش مصنوعی مولد در BigQuery به عنوان روشی قدرتمند برای محاسبه امتیازات مکانی شما ارائه میدهیم.
با امتیازهای متناسب، ارزش کسب و کار را افزایش دهید
مثالهای زیر نشان میدهند که چگونه میتوانید دادههای خام موقعیت مکانی را به معیارهای قدرتمند و کاربرمحور تبدیل کنید تا برنامه خود را بهبود بخشید.
- توسعهدهندگان املاک میتوانند «امتیاز سازگاری با خانواده» یا «امتیاز رویایی رفت و آمد» ایجاد کنند تا به خریداران و مستاجران کمک کنند محلهی ایدهآلی را که با سبک زندگیشان مطابقت دارد، انتخاب کنند و این امر منجر به افزایش تعامل کاربر، افزایش کیفیت سرنخها و افزایش سرعت تبدیل میشود.
- مهندسان سفر و هتلداری میتوانند «امتیاز تفریحات شبانه» یا «امتیاز بهشت گردشگران» را ایجاد کنند تا به مسافران در انتخاب هتلی که با سبک تعطیلات آنها مطابقت دارد، کمک کنند و نرخ رزرو و رضایت مشتری را افزایش دهند.
- تحلیلگران خردهفروشی میتوانند یک «امتیاز تناسب اندام و سلامتی» ایجاد کنند تا مکان بهینه برای یک باشگاه ورزشی جدید یا فروشگاه مواد غذایی سالم را بر اساس کسبوکارهای مکمل مجاور شناسایی کنند و پتانسیل هدف قرار دادن جمعیت مناسب کاربر را به حداکثر برسانند.
در این راهنما، شما یک روش انعطافپذیر و سهقسمتی برای ساخت هر نوع امتیاز مکانی سفارشی با استفاده از دادههای Places مستقیماً در BigQuery خواهید آموخت. ما این الگو را با ساخت دو امتیاز نمونه متمایز نشان خواهیم داد: امتیاز سازگاری با خانواده و امتیاز بهشت صاحبان حیوانات خانگی . این رویکرد به شما امکان میدهد فراتر از تعداد مکانها حرکت کنید و از ویژگیهای غنی و دقیق موجود در مجموعه دادههای Places Insights بهره ببرید. میتوانید از اطلاعاتی مانند ساعات کاری، اینکه آیا یک مکان برای کودکان مناسب است یا اینکه آیا اجازه نگهداری سگ را میدهد، برای ایجاد معیارهای پیچیده و معنادار برای کاربران خود استفاده کنید.
گردش کار راهکار
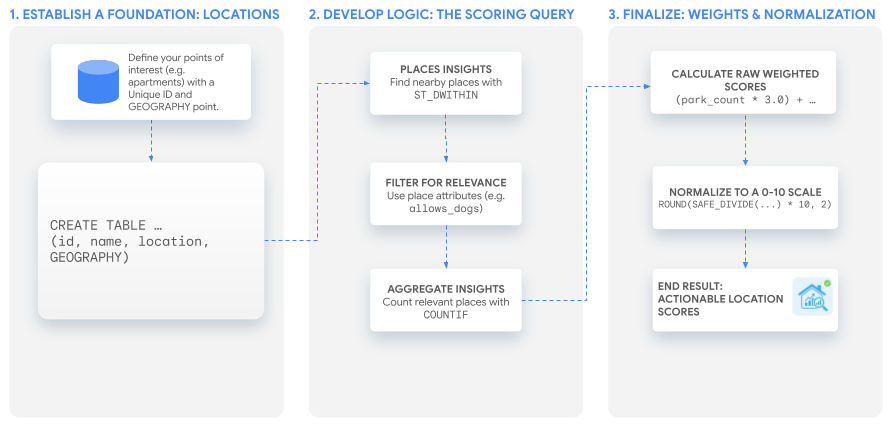
این آموزش از یک کوئری SQL قدرتمند برای ساخت یک امتیاز سفارشی استفاده میکند که میتوانید آن را با هر موردی تطبیق دهید. ما این فرآیند را با ساخت دو امتیاز نمونه برای یک مجموعه فرضی از لیست آپارتمانها طی خواهیم کرد.
برای بررسی این گردش کار در یک محیط تعاملی، دفترچه یادداشت زیر را اجرا کنید. این دفترچه نحوه استفاده از تابع AI.GENERATE در BigQuery را برای ایجاد امتیاز مکانی نشان میدهد.
 مشاهده منبع در گیتهاب
مشاهده منبع در گیتهابپیشنیازها
قبل از شروع، برای تنظیم Places Insights این دستورالعملها را دنبال کنید.
۱. پایه و اساس خود را بنا کنید: مکانهای مورد علاقهتان
قبل از اینکه بتوانید امتیازها را ایجاد کنید، به لیستی از مکانهایی که میخواهید تجزیه و تحلیل کنید نیاز دارید. اولین قدم این است که مطمئن شوید این دادهها به عنوان یک جدول در BigQuery وجود دارند. نکته کلیدی این است که برای هر مکان یک شناسه منحصر به فرد و یک ستون GEOGRAPHY داشته باشید که مختصات آن را ذخیره کند.
شما میتوانید با استفاده از پرسوجویی مانند این، جدولی از مکانها برای امتیازدهی ایجاد و پر کنید:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
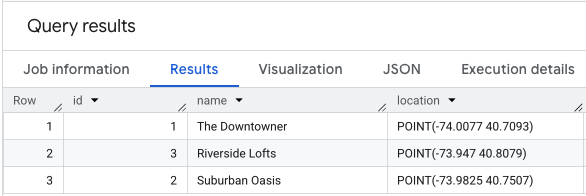
انجام SELECT * روی دادههای موقعیت مکانی شما چیزی شبیه به این خواهد بود.
۲. منطق اصلی را توسعه دهید: پرس و جوی امتیازدهی
با مشخص شدن مکانهایتان، مرحله بعدی پیدا کردن، فیلتر کردن و شمارش مکانهای نزدیک مرتبط با امتیاز سفارشی شما است. همه این کارها در یک دستور SELECT انجام میشود.
با جستجوی مکانی، مکانهای نزدیک را پیدا کنید
ابتدا، باید تمام مکانهایی را از مجموعه دادههای Places Insights که در فاصله مشخصی از هر یک از مکانهای شما قرار دارند، پیدا کنید. تابع ST_DWITHIN در BigQuery برای این کار عالی است. ما یک JOIN بین جدول apartment_listings و جدول places_insights انجام میدهیم تا تمام مکانها را در شعاع ۸۰۰ متری پیدا کنیم. یک LEFT JOIN تضمین میکند که تمام مکانهای اصلی شما در نتایج گنجانده شدهاند، حتی اگر هیچ مکان منطبقی در نزدیکی آنها یافت نشود.
فیلتر کردن برای مرتبط بودن با ویژگیهای پیشرفته
اینجا جایی است که شما مفهوم انتزاعی یک امتیاز را به فیلترهای دادهای ملموس تبدیل میکنید. برای دو امتیاز مثال ما، معیارها متفاوت هستند:
- برای «امتیاز مناسب برای خانواده» ، ما به پارکها، موزهها و رستورانهایی اهمیت میدهیم که صراحتاً برای کودکان مناسب هستند.
- برای «امتیاز بهشت صاحبان حیوانات خانگی» ، ما به پارکها، کلینیکهای دامپزشکی، فروشگاههای حیوانات خانگی و هر رستوران یا کافهای که به سگها اجازه ورود میدهد، اهمیت میدهیم.
شما میتوانید این ویژگیهای خاص را مستقیماً در عبارت WHERE کوئری خود فیلتر کنید.
اطلاعات مربوط به هر مکان را جمعآوری کنید
در نهایت، باید تعداد مکانهای مرتبطی که برای هر آپارتمان پیدا کردهاید را بشمارید. عبارت GROUP BY نتایج را تجمیع میکند و تابع COUNTIF مکانهایی را که با معیارهای خاص برای هر یک از امتیازات ما مطابقت دارند، میشمارد.
کوئری زیر این سه مرحله را با هم ترکیب میکند و تعداد خام هر دو امتیاز را در یک مرحله محاسبه میکند:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
نتیجه این کوئری مشابه این خواهد بود.
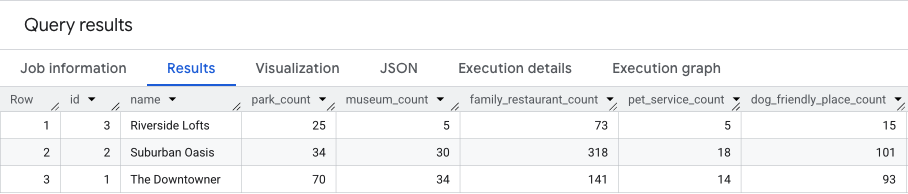
ما در بخش بعدی بر اساس این نتایج کار خواهیم کرد.
۳. امتیاز را ایجاد کنید
حالا که تعداد مکانها و وزن هر نوع مکان را برای هر مکان دارید، میتوانید امتیاز مکان سفارشی را ایجاد کنید. در این بخش دو گزینه را بررسی خواهیم کرد: استفاده از محاسبه سفارشی خودتان در BigQuery یا استفاده از توابع هوش مصنوعی مولد (AI) در BigQuery .
گزینه ۱: از محاسبه سفارشی خود در BigQuery استفاده کنید
شمارشهای خام از مرحله قبل مفید هستند، اما هدف، یک امتیاز واحد و کاربرپسند است. مرحله آخر، ترکیب این شمارشها با استفاده از وزنها و سپس نرمالسازی نتیجه در مقیاس ۰ تا ۱۰ است.
اعمال وزنهای سفارشی انتخاب وزنها هم هنر و هم علم است. آنها باید منعکسکننده اولویتهای تجاری شما یا آنچه که برای کاربرانتان مهمتر میدانید، باشند. برای امتیاز «دوستی خانوادگی» ممکن است تصمیم بگیرید که یک پارک دو برابر یک موزه اهمیت دارد. با بهترین فرضیات خود شروع کنید و بر اساس بازخورد کاربران ما، این کار را تکرار کنید.
نرمالسازی امتیاز پرسوجوی زیر از دو عبارت جدولی مشترک (CTE) استفاده میکند: اولی تعداد خام را مانند قبل محاسبه میکند و دومی امتیازات وزنی را محاسبه میکند. سپس دستور SELECT نهایی، نرمالسازی حداقل-حداکثر را روی امتیازات وزنی انجام میدهد. ستون location جدول مثال apartment_listings در خروجی نمایش داده میشود تا امکان تجسم دادهها روی نقشه فراهم شود.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
نتایج کوئری مشابه زیر خواهد بود. دو ستون آخر نمرات نرمال شده هستند.

نمره نرمال شده را درک کنید
درک این نکته مهم است که چرا این مرحله نهایی نرمالسازی بسیار ارزشمند است. امتیازهای وزنی خام میتوانند بسته به تراکم شهری مکانهای شما، از ۰ تا یک عدد بالقوه بسیار بزرگ متغیر باشند. امتیاز 500 برای کاربری که اطلاعات زمینهای ندارد، بیمعنی است.
نرمالسازی، این اعداد انتزاعی را به یک رتبهبندی نسبی تبدیل میکند. با مقیاسبندی نتایج از ۰ تا ۱۰، امتیاز به وضوح نشان میدهد که هر مکان در مجموعه دادههای خاص شما چگونه با مکانهای دیگر مقایسه میشود:
- امتیاز ۱۰ به مکانی با بالاترین امتیاز خام اختصاص داده میشود و آن را به عنوان بهترین گزینه در مجموعه فعلی مشخص میکند.
- امتیاز ۰ به مکانی با کمترین امتیاز خام اختصاص داده میشود و آن را به عنوان مبنای مقایسه قرار میدهد. این بدان معنا نیست که مکان هیچ امکانات رفاهی ندارد، بلکه به این معنی است که نسبت به سایر گزینههای مورد ارزیابی، نامناسبترین است.
- تمام امتیازات دیگر به طور متناسب در بین این دو قرار میگیرند و به کاربران شما روشی واضح و شهودی برای مقایسه گزینههایشان در یک نگاه ارائه میدهند.
گزینه ۲: استفاده از تابع AI.GENERATE (Gemini)
به عنوان جایگزینی برای استفاده از یک فرمول ریاضی ثابت، میتوانید از تابع BigQuery AI.GENERATE برای محاسبه امتیازهای مکانی سفارشی مستقیماً در گردش کار SQL خود استفاده کنید.
اگرچه گزینه ۱ برای امتیازدهی صرفاً کمی بر اساس تعداد امکانات رفاهی عالی است، اما نمیتواند به راحتی دادههای کیفی را در نظر بگیرد. تابع AI.GENERATE به شما امکان میدهد اعداد حاصل از کوئری Places Insights خود را با دادههای بدون ساختار، مانند توضیحات متنی آگهی آپارتمان (مثلاً "این مکان برای خانوادهها مناسب است و منطقه در شب ساکت است") یا تنظیمات پروفایل خاص کاربر (مثلاً "این کاربر برای یک خانواده رزرو میکند و یک منطقه آرام در یک مکان مرکزی را ترجیح میدهد") ترکیب کنید. این به شما امکان میدهد امتیاز دقیقتری ایجاد کنید که ظرافتهایی را که شمارش دقیق ممکن است از دست بدهد، تشخیص میدهد، مانند مکانی که تراکم امکانات رفاهی بالایی دارد اما به عنوان "بسیار پر سر و صدا برای کودکان" نیز توصیف میشود.
ساخت اعلان
برای استفاده از این تابع، نتایج تجمیع (از مرحله ۲) در یک اعلان زبان طبیعی قالببندی میشوند. این کار را میتوان به صورت پویا در SQL با الحاق ستونهای داده با دستورالعملهای مدل انجام داد.
در کوئری زیر، insight_counts با توضیحات متنی آپارتمان ترکیب شده تا برای هر ردیف یک اعلان ایجاد شود. همچنین یک پروفایل کاربر هدف برای هدایت امتیازدهی تعریف شده است.
تولید امتیاز با SQL
کوئری زیر کل عملیات را در BigQuery انجام میدهد:
- تعداد مکانها را جمع میکند (مطابق آنچه در مرحله ۲ توضیح داده شد).
- برای هر مکان یک اعلان ایجاد میکند .
- تابع
AI.GENERATEرا برای تجزیه و تحلیل اعلان با استفاده از مدل Gemini فراخوانی میکند . - نتیجه را به فرمتی ساختاریافته تجزیه میکند که برای استفاده در برنامه شما آماده است.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
پیکربندی را درک کنید
- آگاهی از هزینه: این تابع ورودی شما را به یک مدل Gemini منتقل میکند و هر بار که فراخوانی میشود، در Vertex AI هزینههایی را متحمل میشود. اگر تعداد زیادی مکان در حال تجزیه و تحلیل هستند (مثلاً هزاران لیست آپارتمان)، ابتدا فیلتر کردن مجموعه دادهها به مرتبطترین نامزدها توصیه میشود. برای جزئیات بیشتر در مورد به حداقل رساندن هزینهها، به بهترین شیوهها مراجعه کنید.
-
endpoint:gemini-flash-latestبرای این مثال مشخص شده است تا سرعت و مقرون به صرفه بودن را در اولویت قرار دهد. با این حال، میتوانید مدلی را انتخاب کنید که به بهترین وجه با نیازهای شما مطابقت داشته باشد. برای آزمایش نسخههای مختلف (مثلاً Gemini Pro برای وظایف استدلال پیچیدهتر) و یافتن بهترین مورد مناسب برای مورد استفاده خود، به مستندات مدلهای Gemini مراجعه کنید. -
output_schema: به جای تجزیه متن خام، یک طرحواره (Schema) اعمال میشود (FLOAT64برای امتیاز وSTRINGبرای استدلال). این تضمین میکند که خروجی بلافاصله در برنامه یا ابزارهای تجسم شما بدون پردازش پس از پردازش قابل استفاده است.
خروجی مثال
این پرسوجو یک جدول استاندارد BigQuery را با امتیاز سفارشی و استدلال مدل برمیگرداند.
| شناسه | نام | امتیاز_دوستی_با_خانواده | استدلال |
|---|---|---|---|
| ۱ | صاحبخانه | ۵.۵ | امکانات رفاهی عالی (پارکها، رستورانها) که معیارهای کمی را برآورده میکنند. با این حال، دادههای کیفی نشاندهنده سر و صدای بیش از حد آخر هفته و تمرکز شدید بر زندگی شبانه است که مستقیماً با نیاز کاربر هدف به سکوت در تضاد است. |
| ۲ | واحه حومه شهر | ۹.۸ | دادههای کمی برجسته همراه با توصیفی ("خیابان آرام و درختکاری شده") که کاملاً با مشخصات خانواده هدف همسو است. توصیفکنندههای مثبت بالا منجر به امتیاز تقریباً کامل میشوند. |
این روش به شما امکان میدهد امتیازدهی بسیار شخصیسازیشدهای ارائه دهید که برای هر کاربر قابل فهم و متناسب با او باشد، و همه اینها در یک کوئری SQL واحد انجام میشود.
۴. نمرات خود را روی نقشه تجسم کنید
BigQuery Studio شامل یک نمایش نقشه یکپارچه برای هر نتیجه پرسوجویی است که شامل ستون GEOGRAPHY باشد. از آنجایی که پرسوجوی ما ستون location را نمایش میدهد، میتوانید بلافاصله امتیازات خود را نمایش دهید.
با کلیک بر روی تب Visualization ، نقشه نمایش داده میشود و منوی کشویی Data Column امتیاز مکانی را که باید نمایش داده شود، کنترل میکند. در این مثال، normalized_pet_score از مثال Option 1 نمایش داده شده است. توجه داشته باشید که برای این مثال، مکانهای بیشتری به جدول apartment_listings اضافه شدهاند.
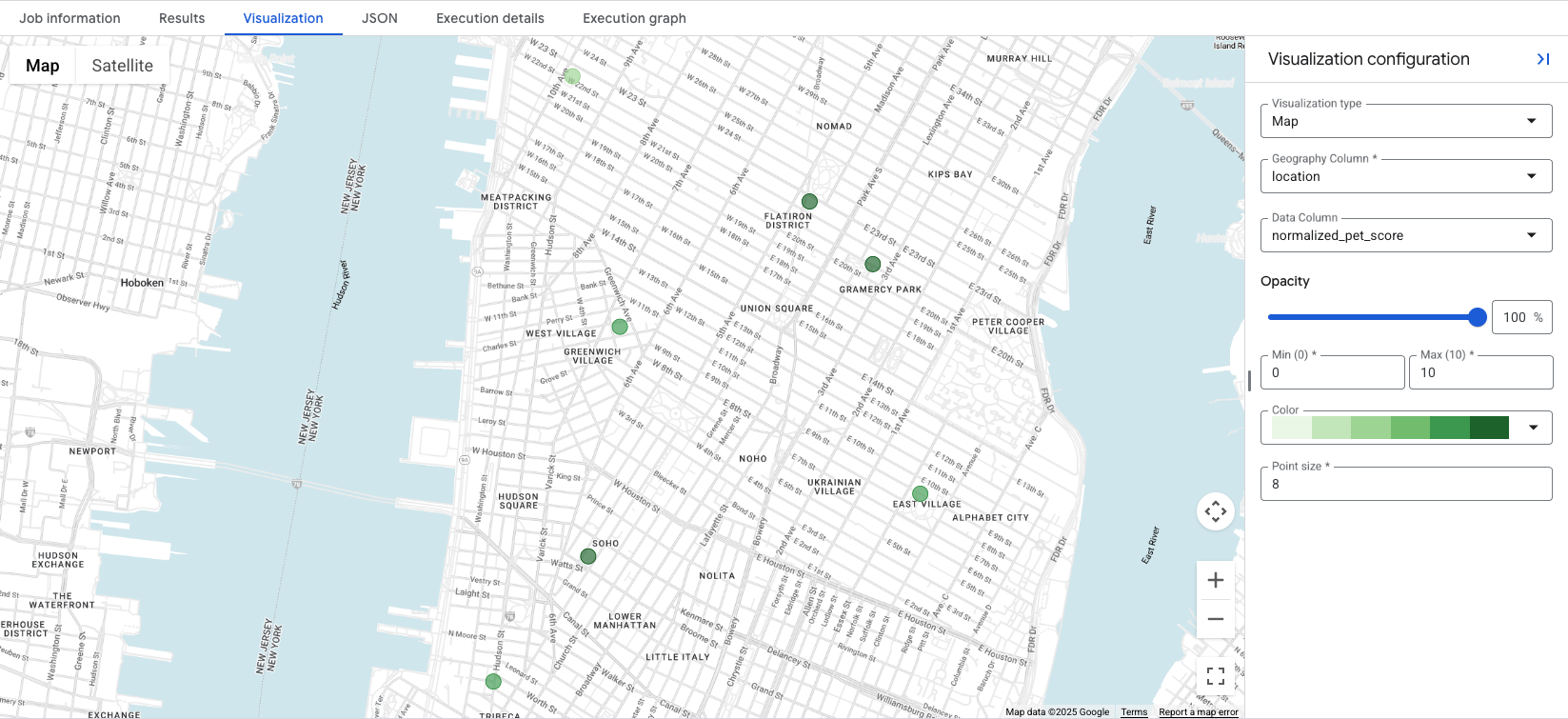
تجسم دادهها در یک نگاه، مناسبترین مکانها برای امتیاز ایجاد شده را نشان میدهد، که در این مورد دایرههای سبز تیرهتر نشاندهنده مکانهایی با normalized_pet_score بالاتر هستند. برای گزینههای تجسم بیشتر دادههای Places Insights، به Visualize query results مراجعه کنید.
نتیجهگیری
اکنون شما یک روش قدرتمند و تکرارپذیر برای ایجاد امتیازهای مکانی دقیق دارید. با شروع از مکانهای خود، یک کوئری SQL واحد در BigQuery ایجاد کردید که مکانهای نزدیک را با ST_DWITHIN پیدا میکند، آنها را با ویژگیهای پیشرفتهای مانند good_for_children و allows_dogs فیلتر میکند و نتایج را با COUNTIF جمع میکند. با اعمال وزنهای سفارشی و نرمالسازی نتیجه، یک امتیاز واحد و کاربرپسند ایجاد کردید که بینش عمیق و کاربردی ارائه میدهد. میتوانید مستقیماً از این الگو برای تبدیل دادههای خام مکانی به یک مزیت رقابتی قابل توجه استفاده کنید.
اقدامات بعدی
حالا نوبت شماست که بسازید. این آموزش یک الگو ارائه میدهد. میتوانید از دادههای غنی موجود در طرحواره Places Insights برای ایجاد امتیازهایی که برای مورد استفاده شما ضروریتر هستند استفاده کنید. این امتیازهای دیگری را که میتوانید بسازید در نظر بگیرید:
- «امتیاز تفریحات شبانه»: فیلترهای
primary_type(bar،night_club)،price_levelو ساعات کاری آخر شب را ترکیب کنید تا پرجنبوجوشترین مناطق بعد از تاریکی هوا را پیدا کنید. - «امتیاز تناسب اندام و سلامتی»:
gyms،parksوhealth_food_storesنزدیک را بشمارید و رستورانهایی را که دارایserves_vegetarian_foodهستند فیلتر کنید تا مکانها را برای کاربرانی که به سلامتی خود اهمیت میدهند، امتیازدهی کنید. - «امتیاز رویایی رفت و آمد»: مکانهایی با تراکم بالای
transit_stationوparkingنزدیک را پیدا کنید تا به کاربرانی که برای دسترسی به حمل و نقل ارزش قائل هستند، کمک کنید.
مشارکتکنندگان
هنریک والو | مهندس DevX