
Übersicht
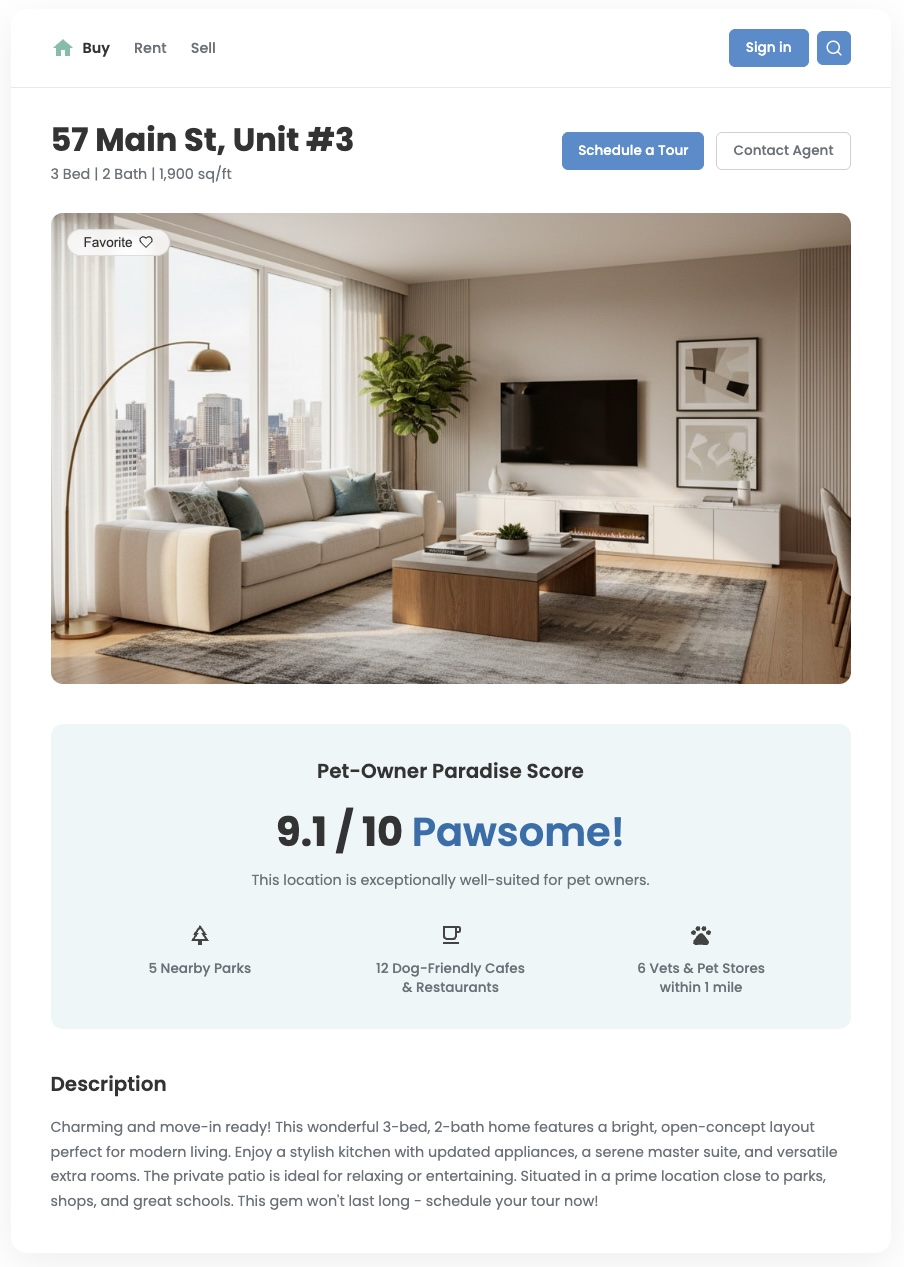
Mit Standardstandortdaten lässt sich zwar herausfinden, was sich in der Nähe befindet, aber die wichtigere Frage „Wie gut ist diese Gegend für mich?“ lässt sich damit oft nicht beantworten. Die Bedürfnisse Ihrer Nutzer sind vielfältig. Eine Familie mit kleinen Kindern hat andere Prioritäten als ein junger Berufstätiger mit einem Hund. Damit sie fundierte Entscheidungen treffen können, müssen Sie ihnen Statistiken zur Verfügung stellen, die diese spezifischen Anforderungen widerspiegeln. Mit einem benutzerdefinierten Standort-Score können Sie diesen Wert liefern und eine deutlich differenzierte Nutzererfahrung schaffen.
In diesem Dokument wird beschrieben, wie Sie benutzerdefinierte, vielseitige Standortbewertungen mit dem Places Insights-Dataset in BigQuery erstellen. Wenn Sie POI-Daten in aussagekräftige Messwerte umwandeln, können Sie Ihre Immobilien-, Einzelhandels- oder Reiseanwendungen optimieren und Ihren Nutzern die relevanten Informationen bereitstellen, die sie benötigen. Außerdem bieten wir die Möglichkeit, generative KI in BigQuery zu verwenden, um Ihre Standortbewertungen zu berechnen.
Geschäftswert mit benutzerdefinierten Messwerten steigern
In den folgenden Beispielen wird veranschaulicht, wie Sie Rohstandortdaten in aussagekräftige, nutzerorientierte Messwerte umwandeln können, um Ihre Anwendung zu optimieren.
- Immobilienentwickler können einen „Familienfreundlichkeits-Score“ oder einen „Pendler-Score“ erstellen, um Käufern und Mietern bei der Auswahl des perfekten Viertels zu helfen, das zu ihrem Lebensstil passt. Das führt zu einer stärkeren Nutzerinteraktion, hochwertigeren Leads und schnelleren Conversions.
- Travel & Hospitality Engineers können einen „Nightlife Score“ oder einen „Sightseer’s Paradise Score“ erstellen, um Reisenden bei der Auswahl eines Hotels zu helfen, das zu ihrem Urlaubsstil passt. So können sie die Buchungsraten und die Kundenzufriedenheit steigern.
- Einzelhandelsanalysten können einen „Fitness- und Wellness-Score“ erstellen, um den optimalen Standort für ein neues Fitnessstudio oder ein Reformhaus zu ermitteln. Dabei werden ergänzende Unternehmen in der Nähe berücksichtigt, um das Potenzial zu maximieren, die richtige Nutzerdemografie anzusprechen.
In dieser Anleitung erfahren Sie, wie Sie mit Ortsdaten direkt in BigQuery eine flexible, dreiteilige Methode zum Erstellen benutzerdefinierter Ortsbewertungen anwenden. Wir veranschaulichen dieses Muster anhand von zwei unterschiedlichen Beispielbewertungen: einer Bewertung für Familienfreundlichkeit und einer Bewertung für Tierhalter. Mit diesem Ansatz können Sie über die Anzahl der Orte hinausgehen und die umfangreichen, detaillierten Attribute im Places Insights-Dataset nutzen. Sie können Informationen wie Öffnungszeiten, ob ein Ort für Kinder geeignet ist oder ob Hunde erlaubt sind, verwenden, um anspruchsvolle und aussagekräftige Messwerte für Ihre Nutzer zu erstellen.
Lösungsablauf
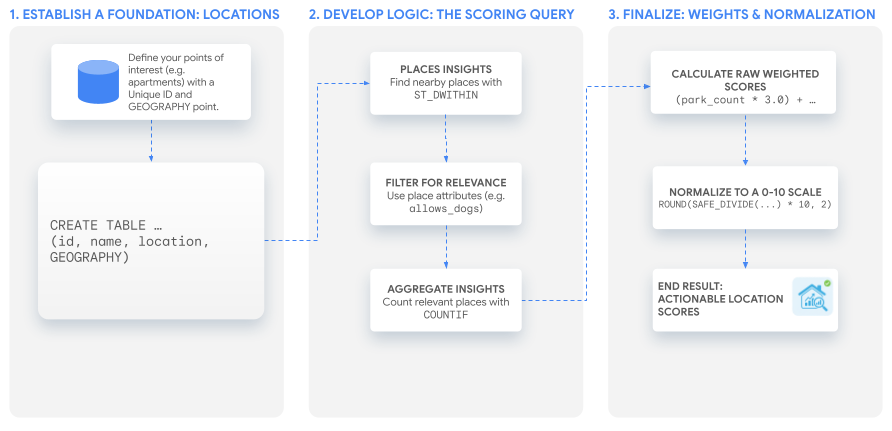
In dieser Anleitung wird eine einzelne, leistungsstarke SQL-Abfrage verwendet, um eine benutzerdefinierte Punktzahl zu erstellen, die Sie an jeden Anwendungsfall anpassen können. Wir werden diesen Prozess durchlaufen, indem wir unsere beiden Beispielbewertungen für eine hypothetische Reihe von Wohnungsangeboten erstellen.
Wenn Sie diesen Workflow in einer interaktiven Umgebung ausprobieren möchten, führen Sie das folgende Notebook aus. Darin wird gezeigt, wie Sie die Funktion AI.GENERATE in BigQuery verwenden, um einen Standort-Score zu erstellen.
 Quelle auf GitHub ansehen
Quelle auf GitHub ansehen
Vorbereitung
Folgen Sie dieser Anleitung, um Places Insights einzurichten.
1. Grundlage schaffen: Orte von Interesse
Bevor Sie Bewertungen erstellen können, benötigen Sie eine Liste der Standorte, die Sie analysieren möchten. Im ersten Schritt müssen Sie dafür sorgen, dass diese Daten als Tabelle in BigQuery vorhanden sind.
Wichtig ist, dass Sie für jeden Standort eine eindeutige Kennung und eine GEOGRAPHY-Spalte mit den Koordinaten haben.
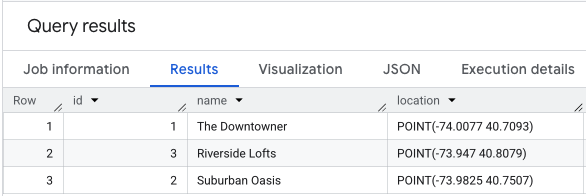
Sie können eine Tabelle mit zu bewertenden Standorten mit einer Abfrage wie dieser erstellen und befüllen:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
Eine SELECT * für Ihre Standortdaten würde in etwa so aussehen.
2. Kernlogik entwickeln: Die Scoring-Abfrage
Nachdem Sie Ihre Standorte festgelegt haben, müssen Sie die Orte in der Nähe, die für Ihre benutzerdefinierte Punktzahl relevant sind, suchen, filtern und zählen. Das alles erfolgt in einer einzigen SELECT-Anweisung.
Mit einer raumbezogenen Suche finden, was in der Nähe ist
Zuerst müssen Sie alle Orte aus dem Places Insights-Dataset finden, die sich in einem bestimmten Umkreis um jeden Ihrer Standorte befinden. Die BigQuery-Funktion ST_DWITHIN ist dafür ideal. Wir führen einen JOIN zwischen unserer Tabelle apartment_listings und der Tabelle places_insights aus, um alle Orte im Umkreis von 800 Metern zu finden. Mit einem LEFT JOIN wird dafür gesorgt, dass alle Ihre ursprünglichen Standorte in den Ergebnissen enthalten sind, auch wenn in der Nähe keine passenden Orte gefunden werden.
Relevanz mit erweiterten Attributen filtern
Hier übersetzen Sie das abstrakte Konzept eines Scores in konkrete Datenfilter. Für unsere beiden Beispielwerte sind die Kriterien unterschiedlich:
- Beim „Familienfreundlichkeitswert“ berücksichtigen wir Parks, Museen und Restaurants, die explizit für Kinder geeignet sind.
- Für den „Pet-Owner Paradise Score“ berücksichtigen wir Parks, Tierarztpraxen, Tierhandlungen und alle Restaurants oder Cafés, in denen Hunde erlaubt sind.
Sie können direkt in der WHERE-Klausel Ihrer Abfrage nach diesen Attributen filtern.
Zusammenfassen der Statistiken für jeden Standort
Zählen Sie zum Schluss, wie viele relevante Orte Sie für jede Wohnung gefunden haben. Mit der GROUP BY-Klausel werden die Ergebnisse aggregiert und mit der Funktion COUNTIF werden Orte gezählt, die den jeweiligen Kriterien für unsere Werte entsprechen.
In der folgenden Abfrage werden diese drei Schritte kombiniert und die Rohanzahl für beide Werte in einem einzigen Durchlauf berechnet:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
Das Ergebnis dieser Abfrage sieht etwa so aus:
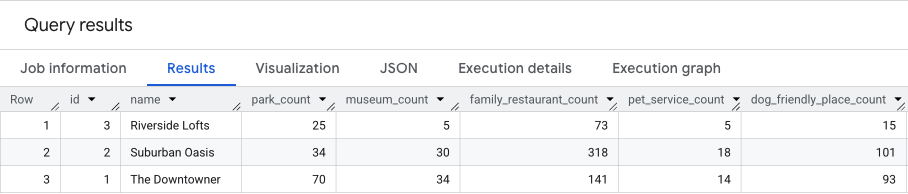
Im nächsten Abschnitt werden wir auf diesen Ergebnissen aufbauen.
3. Punktzahl erstellen
Nachdem Sie die Anzahl der Orte und die Gewichtung für jeden Ortstyp für jeden Standort haben, können Sie jetzt den benutzerdefinierten Standort-Score generieren. In diesem Abschnitt werden zwei Optionen behandelt: die Verwendung einer eigenen benutzerdefinierten Berechnung in BigQuery oder die Verwendung von generativen KI-Funktionen in BigQuery.
Option 1: Eigene benutzerdefinierte Berechnung in BigQuery verwenden
Die Rohzahlen aus dem vorherigen Schritt sind aufschlussreich, aber ein einzelner, benutzerfreundlicher Wert ist das Ziel. Im letzten Schritt werden diese Zählungen mithilfe von Gewichten kombiniert und das Ergebnis wird auf eine Skala von 0 bis 10 normalisiert.
Benutzerdefinierte Gewichte anwenden: Die Auswahl der Gewichte ist sowohl eine Kunst als auch eine Wissenschaft. Sie müssen Ihre geschäftlichen Prioritäten oder das widerspiegeln, was Ihrer Meinung nach für Ihre Nutzer am wichtigsten ist. Für den „Familienfreundlichkeit“-Faktor könnte ein Park doppelt so wichtig sein wie ein Museum. Beginnen Sie mit Ihren besten Annahmen und passen Sie sie anhand des Nutzerfeedbacks an.
Score normalisieren: In der folgenden Abfrage werden zwei Common Table Expressions (CTEs) verwendet: Mit der ersten werden die Rohzahlen wie zuvor berechnet, mit der zweiten die gewichteten Scores. Mit der abschließenden SELECT-Anweisung wird dann eine Min-Max-Normalisierung der gewichteten Werte durchgeführt. Die Spalte location der Beispielstabelle apartment_listings wird ausgegeben, um die Datenvisualisierung auf einer Karte zu ermöglichen.
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
Die Ergebnisse der Abfrage sehen in etwa so aus: Die letzten beiden Spalten enthalten die normalisierten Werte.

Normalisierte Bewertung
Es ist wichtig zu verstehen, warum dieser letzte Normalisierungsschritt so wertvoll ist.
Die gewichteten Rohwerte können je nach Bevölkerungsdichte Ihrer Standorte zwischen 0 und einer potenziell sehr großen Zahl liegen. Eine Punktzahl von 500 ist für einen Nutzer ohne Kontext bedeutungslos.
Durch die Normalisierung werden diese abstrakten Zahlen in ein relatives Ranking umgewandelt. Durch die Skalierung der Ergebnisse von 0 bis 10 wird deutlich, wie die einzelnen Standorte im Vergleich zu den anderen in Ihrem spezifischen Datensatz abschneiden:
- Dem Standort mit dem höchsten Rohwert wird ein Wert von 10 zugewiesen. Er ist damit die beste Option im aktuellen Set.
- Der Standort mit dem niedrigsten Rohwert erhält einen Wert von 0 und dient als Vergleichsbasis. Das bedeutet nicht, dass der Standort keine Annehmlichkeiten bietet, sondern dass er im Vergleich zu den anderen Optionen, die bewertet werden, am wenigsten geeignet ist.
- Alle anderen Werte liegen proportional dazwischen. So können Nutzer ihre Optionen auf einen Blick vergleichen.
Option 2: Funktion AI.GENERATE (Gemini) verwenden
Alternativ zu einer festen mathematischen Formel können Sie die BigQuery-Funktion AI.GENERATE verwenden, um benutzerdefinierte Standortbewertungen direkt in Ihrem SQL-Workflow zu berechnen.
Option 1 eignet sich hervorragend für die rein quantitative Bewertung auf Grundlage der Anzahl der Annehmlichkeiten, qualitative Daten lassen sich jedoch nicht ohne Weiteres berücksichtigen. Mit der Funktion AI.GENERATE können Sie die Zahlen aus Ihrer Places Insights-Anfrage mit unstrukturierten Daten kombinieren, z. B. mit der Textbeschreibung des Apartmentangebots (z. B. „Dieser Ort ist für Familien geeignet und die Gegend ist nachts ruhig“) oder mit bestimmten Nutzerprofilpräferenzen (z. B. „Dieser Nutzer bucht für eine Familie und bevorzugt eine ruhige Gegend in zentraler Lage“). So können Sie einen differenzierteren Wert generieren, der Feinheiten berücksichtigt, die bei einer reinen Zählung möglicherweise nicht erfasst werden, z. B. wenn ein Ort eine hohe Dichte an Annehmlichkeiten aufweist, aber auch als „zu laut für Kinder“ beschrieben wird.
Prompt erstellen
Für die Verwendung dieser Funktion werden die Ergebnisse der Aggregation (aus Schritt 2) in einen Prompt in natürlicher Sprache formatiert. Dies kann dynamisch in SQL erfolgen, indem Datenkolonnen mit Anweisungen für das Modell verkettet werden.
In der folgenden Abfrage werden insight_counts mit der Textbeschreibung der Wohnung kombiniert, um für jede Zeile einen Prompt zu erstellen. Außerdem wird ein Zielnutzerprofil definiert, um die Bewertung zu steuern.
Punktzahl mit SQL generieren
Mit der folgenden Abfrage wird der gesamte Vorgang in BigQuery ausgeführt. Die DSGVO hat folgenden Zweck:
- Aggregates die Anzahl der Orte (wie in Schritt 2 beschrieben).
- Erstellt einen Prompt für jeden Standort.
- Ruft die Funktion
AI.GENERATEauf, um den Prompt mit dem Gemini-Modell zu analysieren. - Das Ergebnis wird geparst und in ein strukturiertes Format umgewandelt, das in Ihrer Anwendung verwendet werden kann.
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
Konfiguration verstehen
- Kostenbewusstsein:Diese Funktion übergibt Ihre Eingabe an ein Gemini-Modell. Jedes Mal, wenn sie aufgerufen wird, fallen in Vertex AI Gebühren an. Wenn eine große Anzahl von Standorten analysiert wird (z.B. Tausende von Wohnungsangeboten), empfiehlt es sich, das Dataset zuerst nach den relevantesten Kandidaten zu filtern. Weitere Informationen zur Minimierung von Kosten finden Sie unter Best Practices.
endpoint: Für dieses Beispiel wirdgemini-flash-latestangegeben, um Geschwindigkeit und Kosteneffizienz zu priorisieren. Sie können jedoch das Modell auswählen, das Ihren Anforderungen am besten entspricht. In der Dokumentation zu Gemini-Modellen können Sie verschiedene Versionen ausprobieren (z.B. Gemini Pro für komplexere Aufgaben) und das Modell finden, das am besten zu Ihrem Anwendungsfall passt.output_schema: Anstatt Rohtext zu parsen, wird ein Schema erzwungen (FLOAT64für die Punktzahl undSTRINGfür die Begründung). So ist die Ausgabe ohne Nachbearbeitung sofort in Ihrer Anwendung oder Ihren Visualisierungstools verwendbar.
Beispielausgabe
Die Abfrage gibt eine Standard-BigQuery-Tabelle mit dem benutzerdefinierten Score und der Begründung des Modells zurück.
| id | name | family_friendliness_score | Schlussfolgerung |
|---|---|---|---|
| 1 | Der Downtowner | 5,5 | Hervorragende Anzahl an Annehmlichkeiten (Parks, Restaurants), die quantitative Messwerte erfüllt. Die qualitativen Daten deuten jedoch auf übermäßiges Rauschen am Wochenende und einen starken Fokus auf das Nachtleben hin, was direkt mit dem Bedürfnis der Zielgruppe nach Ruhe kollidiert. |
| 2 | Suburban Oasis | 9,8 | Hervorragende quantitative Daten in Kombination mit einer Beschreibung („ruhige, von Bäumen gesäumte Straße“), die perfekt zum Profil der Zielgruppe passt. Hohe positive Modifikatoren führen zu einem nahezu perfekten Ergebnis. |
Mit diesem Verfahren können Sie hochgradig personalisierte Bewertungen erstellen, die für jeden einzelnen Nutzer nachvollziehbar und maßgeschneidert sind – und das alles mit einer einzigen SQL-Abfrage.
4. Ergebnisse auf einer Karte visualisieren
BigQuery Studio enthält eine integrierte Kartenvisualisierung für alle Abfrageergebnisse, die eine GEOGRAPHY-Spalte enthalten. Da in unserer Abfrage die Spalte location ausgegeben wird, können Sie Ihre Werte sofort visualisieren.
Wenn Sie auf den Tab Visualization klicken, wird die Karte aufgerufen. Mit dem Drop-down-Menü Data Column können Sie die zu visualisierende Standortbewertung auswählen. In diesem Beispiel wird der normalized_pet_score anhand von Option 1 visualisiert. Beachten Sie, dass der Tabelle apartment_listings in diesem Beispiel weitere Standorte hinzugefügt wurden.
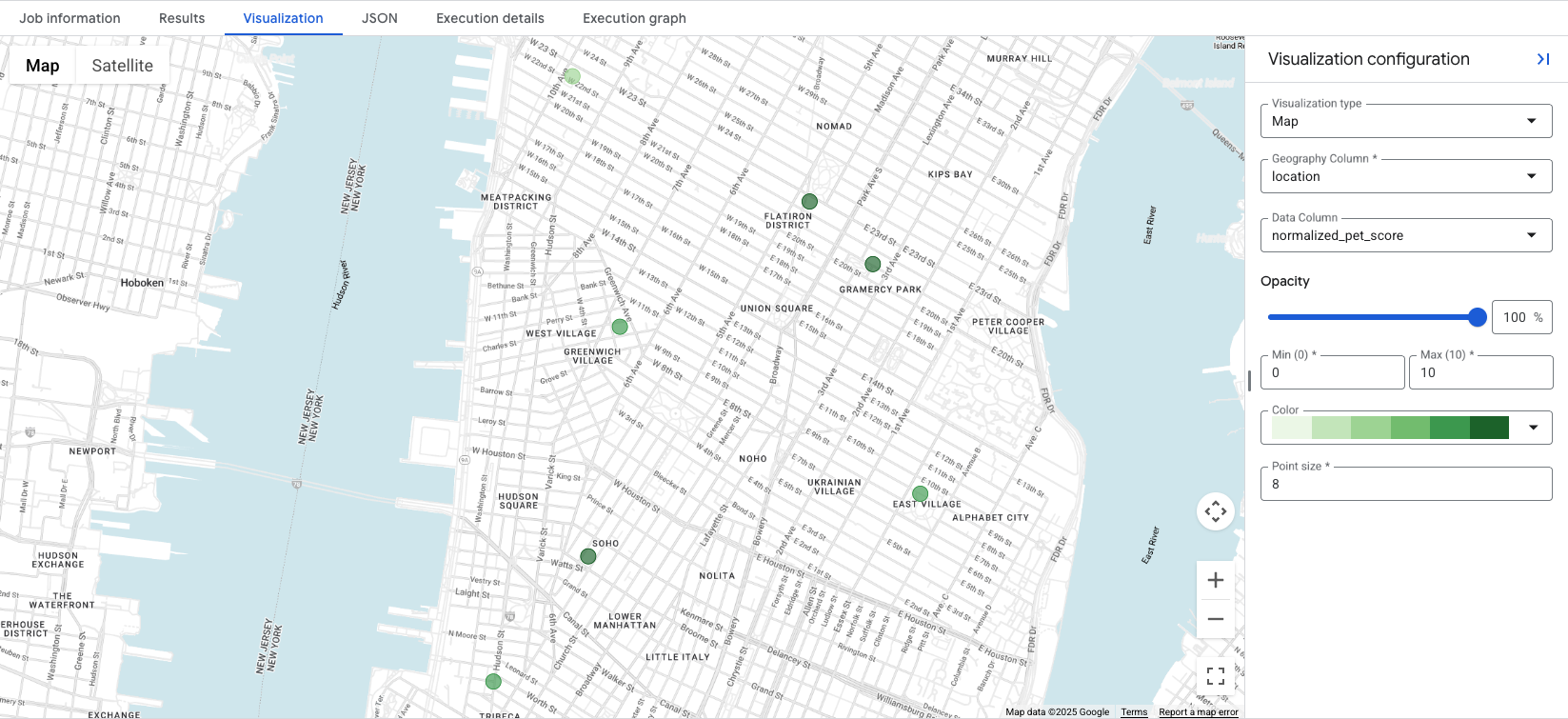
Durch die Visualisierung der Daten lassen sich die am besten geeigneten Standorte für den erstellten Wert auf einen Blick erkennen. Dunkelgrüne Kreise stehen in diesem Fall für Standorte mit einem höheren normalized_pet_score. Weitere Optionen zur Visualisierung von Places Insights-Daten finden Sie unter Abfrageergebnisse visualisieren.
Fazit
Sie verfügen jetzt über eine leistungsstarke und wiederholbare Methode zum Erstellen differenzierter Standortbewertungen. Ausgehend von Ihren Standorten haben Sie in BigQuery eine einzelne SQL-Abfrage erstellt, mit der Sie nahegelegene Orte mit ST_DWITHIN finden, sie nach erweiterten Attributen wie good_for_children und allows_dogs filtern und die Ergebnisse mit COUNTIF zusammenfassen. Durch die Anwendung benutzerdefinierter Gewichtungen und die Normalisierung des Ergebnisses haben Sie einen einzelnen, benutzerfreundlichen Wert erhalten, der fundierte, umsetzbare Informationen liefert. Sie können dieses Muster direkt anwenden, um Rohstandortdaten in einen erheblichen Wettbewerbsvorteil zu verwandeln.
Nächste Aktionen
Jetzt sind Sie an der Reihe. In dieser Anleitung wird eine Vorlage bereitgestellt. Mit den umfangreichen Daten, die im Places Insights-Schema verfügbar sind, können Sie die für Ihren Anwendungsfall wichtigsten Werte erstellen. Weitere mögliche Scores:
- Nachtleben-Index: Kombinieren Sie Filter für
primary_type(bar,night_club),price_levelund Öffnungszeiten bis spät in die Nacht, um die lebendigsten Gegenden nach Einbruch der Dunkelheit zu finden. - Fitness- und Wellness-Score: In der Nähe befindliche
gyms,parksundhealth_food_storeswerden gezählt und Restaurants nachserves_vegetarian_foodgefiltert, um Standorte für gesundheitsbewusste Nutzer zu bewerten. - „Pendlerfreundlich“-Bewertung: Hier finden Sie Orte mit einer hohen Dichte an
transit_station- undparking-Orten in der Nähe, um Nutzern zu helfen, die Wert auf eine gute Verkehrsanbindung legen.
Beitragende
Henrik Valve | DevX Engineer