
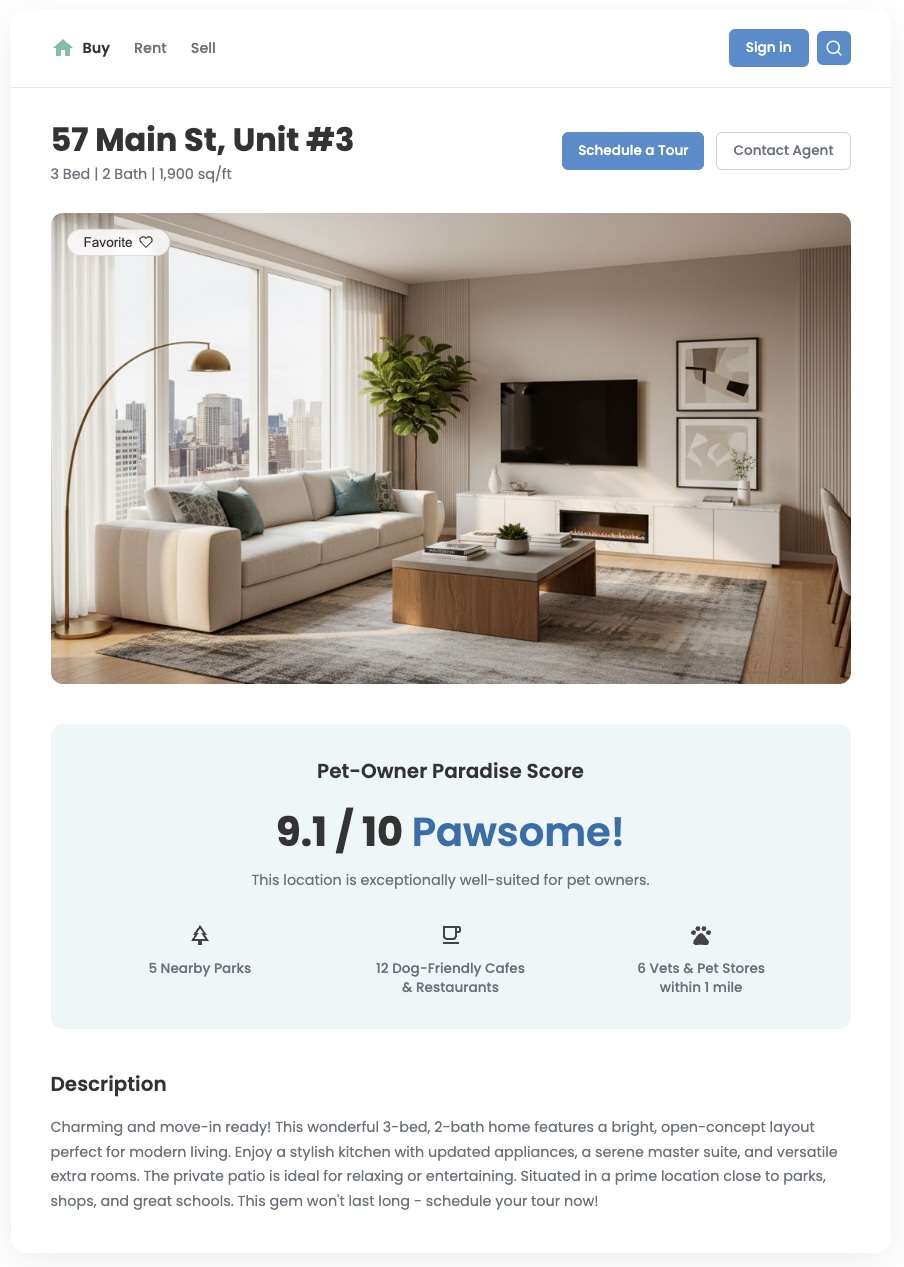
সংক্ষিপ্ত বিবরণ
সাধারণ অবস্থান ডেটা আপনাকে আশেপাশে কী আছে তা জানাতে পারে, কিন্তু এটি প্রায়শই আরও গুরুত্বপূর্ণ একটি প্রশ্নের উত্তর দিতে ব্যর্থ হয়: "এই এলাকাটি আমার জন্য কতটা ভালো?" আপনার ব্যবহারকারীদের চাহিদাগুলো বেশ সূক্ষ্ম। ছোট বাচ্চা সহ একটি পরিবারের অগ্রাধিকার, কুকুর সহ একজন তরুণ পেশাজীবীর অগ্রাধিকারের চেয়ে ভিন্ন। তাদের আত্মবিশ্বাসী সিদ্ধান্ত নিতে সাহায্য করার জন্য, আপনাকে এমন তথ্য সরবরাহ করতে হবে যা এই নির্দিষ্ট চাহিদাগুলোকে প্রতিফলিত করে। এই সুবিধাটি প্রদান করতে এবং একটি উল্লেখযোগ্য স্বতন্ত্র ব্যবহারকারীর অভিজ্ঞতা তৈরি করতে একটি কাস্টম লোকেশন স্কোর একটি শক্তিশালী মাধ্যম।
এই ডকুমেন্টটিতে বর্ণনা করা হয়েছে কিভাবে BigQuery-এর Places Insights ডেটাসেট ব্যবহার করে কাস্টম, বহুমুখী লোকেশন স্কোর তৈরি করা যায়। POI ডেটাকে অর্থপূর্ণ মেট্রিক্সে রূপান্তর করার মাধ্যমে আপনি আপনার রিয়েল এস্টেট, রিটেইল বা ট্র্যাভেল অ্যাপ্লিকেশনগুলোকে সমৃদ্ধ করতে পারেন এবং আপনার ব্যবহারকারীদের প্রয়োজনীয় প্রাসঙ্গিক তথ্য সরবরাহ করতে পারেন। আপনার লোকেশন স্কোর গণনা করার একটি শক্তিশালী উপায় হিসেবে আমরা BigQuery-তে জেনারেটিভ এআই (generative AI) ব্যবহারের বিকল্পও প্রদান করি।
উপযোগী স্কোরের মাধ্যমে ব্যবসায়িক মূল্য বৃদ্ধি করুন
নিম্নলিখিত উদাহরণগুলি দেখায় কিভাবে আপনি আপনার অ্যাপ্লিকেশনকে উন্নত করতে কাঁচা অবস্থান ডেটাকে শক্তিশালী, ব্যবহারকারী-কেন্দ্রিক মেট্রিক্সে রূপান্তর করতে পারেন।
- রিয়েল এস্টেট ডেভেলপাররা ক্রেতা ও ভাড়াটেদের জীবনযাত্রার সাথে মানানসই নিখুঁত এলাকা বেছে নিতে সাহায্য করার জন্য একটি 'পরিবার-বান্ধব স্কোর' বা 'যাতায়াতকারীদের জন্য স্বপ্নের স্কোর' তৈরি করতে পারেন, যা ব্যবহারকারীদের সম্পৃক্ততা বৃদ্ধি করে, উন্নত মানের লিড এনে দেয় এবং দ্রুততর রূপান্তর ঘটায়।
- ট্র্যাভেল অ্যান্ড হসপিটালিটি ইঞ্জিনিয়াররা ভ্রমণকারীদের তাদের অবকাশ যাপনের ধরনের সাথে মানানসই হোটেল বেছে নিতে সাহায্য করার জন্য একটি 'নাইটলাইফ স্কোর' বা 'সাইটসিয়ার্স প্যারাডাইস স্কোর' তৈরি করতে পারেন, যা বুকিংয়ের হার এবং গ্রাহক সন্তুষ্টি বৃদ্ধি করে।
- রিটেইল অ্যানালিস্টরা কাছাকাছি থাকা পরিপূরক ব্যবসাগুলোর ওপর ভিত্তি করে একটি নতুন জিম বা স্বাস্থ্যকর খাবারের দোকানের জন্য সর্বোত্তম স্থান শনাক্ত করতে একটি 'ফিটনেস অ্যান্ড ওয়েলনেস স্কোর' তৈরি করতে পারেন, যা সঠিক ব্যবহারকারী গোষ্ঠীকে লক্ষ্য করার সম্ভাবনাকে সর্বোচ্চ করে তোলে।
এই নির্দেশিকায়, আপনি BigQuery-তে সরাসরি Places ডেটা ব্যবহার করে যেকোনো ধরনের কাস্টম লোকেশন স্কোর তৈরি করার জন্য একটি নমনীয়, তিন-ধাপের পদ্ধতি শিখবেন। আমরা দুটি স্বতন্ত্র উদাহরণ স্কোর তৈরি করার মাধ্যমে এই পদ্ধতিটি ব্যাখ্যা করব: একটি ফ্যামিলি-ফ্রেন্ডলিনেস স্কোর এবং একটি পেট-ওনার প্যারাডাইস স্কোর । এই পদ্ধতিটি আপনাকে স্থানের সংখ্যা গণনার বাইরে গিয়ে Places Insights ডেটাসেটের মধ্যে থাকা সমৃদ্ধ ও বিস্তারিত অ্যাট্রিবিউটগুলোর সুবিধা নিতে সাহায্য করে। আপনি ব্যবসার সময়, কোনো স্থান শিশুদের জন্য উপযুক্ত কিনা, বা সেখানে কুকুর নিয়ে যাওয়ার অনুমতি আছে কিনা—এই ধরনের তথ্য ব্যবহার করে আপনার ব্যবহারকারীদের জন্য উন্নত ও অর্থপূর্ণ মেট্রিক তৈরি করতে পারেন।
সমাধান কর্মপ্রবাহ
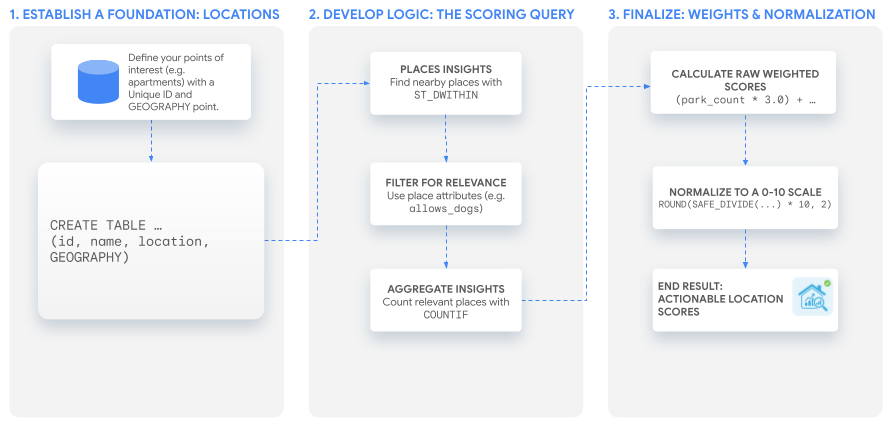
এই টিউটোরিয়ালে একটি শক্তিশালী SQL কোয়েরি ব্যবহার করে একটি কাস্টম স্কোর তৈরি করা হয়েছে, যা আপনি যেকোনো ক্ষেত্রে মানিয়ে নিতে পারবেন। আমরা কাল্পনিক কিছু অ্যাপার্টমেন্ট তালিকার জন্য আমাদের দুটি উদাহরণ স্কোর তৈরি করার মাধ্যমে এই প্রক্রিয়াটি ধাপে ধাপে দেখাবো।
একটি ইন্টারেক্টিভ পরিবেশে এই ওয়ার্কফ্লোটি অন্বেষণ করতে, নিম্নলিখিত নোটবুকটি চালান। এটি দেখায় কিভাবে BigQuery-এর মধ্যে AI.GENERATE ফাংশন ব্যবহার করে একটি লোকেশন স্কোর তৈরি করা যায়।
 গিটহাবে উৎস দেখুন
গিটহাবে উৎস দেখুনপূর্বশর্ত
শুরু করার আগে, প্লেসেস ইনসাইটস সেট আপ করার জন্য এই নির্দেশাবলী অনুসরণ করুন।
১. ভিত্তি স্থাপন করুন: আপনার আগ্রহের স্থানসমূহ
স্কোর তৈরি করার আগে, আপনি যে অবস্থানগুলো বিশ্লেষণ করতে চান তার একটি তালিকা আপনার প্রয়োজন। প্রথম ধাপ হলো BigQuery-তে এই ডেটা একটি টেবিল হিসেবে আছে কিনা তা নিশ্চিত করা। এর জন্য প্রতিটি অবস্থানের একটি অনন্য শনাক্তকারী এবং এর স্থানাঙ্ক সংরক্ষণের জন্য একটি GEOGRAPHY কলাম থাকা আবশ্যক।
এই ধরনের একটি কোয়েরি ব্যবহার করে আপনি স্কোর করার জন্য অবস্থানগুলির একটি টেবিল তৈরি ও তাতে তথ্য যোগ করতে পারেন:
CREATE OR REPLACE TABLE `your_project.your_dataset.apartment_listings`
(
id INT64,
name STRING,
location GEOGRAPHY
);
INSERT INTO `your_project.your_dataset.apartment_listings` VALUES
(1, 'The Downtowner', ST_GEOGPOINT(-74.0077, 40.7093)),
(2, 'Suburban Oasis', ST_GEOGPOINT(-73.9825, 40.7507)),
(3, 'Riverside Lofts', ST_GEOGPOINT(-73.9470, 40.8079))
-- More rows can be added here
. . . ;
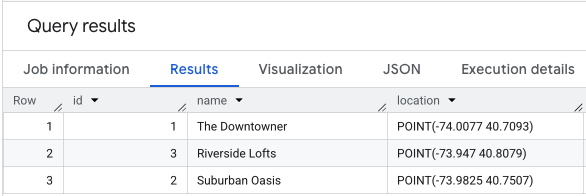
আপনার অবস্থানের ডেটার উপর একটি SELECT * চালালে তা দেখতে অনেকটা এইরকম হবে।
২. মূল লজিক তৈরি করুন: স্কোরিং কোয়েরি
আপনার অবস্থানগুলো নির্ধারণ করা হয়ে গেলে, পরবর্তী ধাপ হলো আপনার কাস্টম স্কোরের সাথে প্রাসঙ্গিক কাছাকাছি স্থানগুলো খুঁজে বের করা, ফিল্টার করা এবং গণনা করা। এই পুরো কাজটি একটিমাত্র SELECT স্টেটমেন্টের মাধ্যমেই করা হয়।
ভূ-স্থানিক অনুসন্ধানের মাধ্যমে কাছাকাছি কী আছে তা খুঁজুন।
প্রথমে, আপনাকে Places Insights ডেটাসেট থেকে আপনার প্রতিটি অবস্থানের একটি নির্দিষ্ট দূরত্বের মধ্যে থাকা সমস্ত স্থান খুঁজে বের করতে হবে। এর জন্য BigQuery ফাংশন ST_DWITHIN একদম উপযুক্ত। ৮০০-মিটার ব্যাসার্ধের মধ্যে থাকা সমস্ত স্থান খুঁজে বের করার জন্য আমরা আমাদের apartment_listings টেবিল এবং places_insights টেবিলের মধ্যে একটি JOIN করব। একটি LEFT JOIN নিশ্চিত করে যে, কাছাকাছি কোনো মিলযুক্ত স্থান খুঁজে না পাওয়া গেলেও আপনার সমস্ত মূল অবস্থান ফলাফলে অন্তর্ভুক্ত থাকবে।
উন্নত বৈশিষ্ট্য ব্যবহার করে প্রাসঙ্গিকতা অনুসারে ফিল্টার করুন
এখানেই আপনি স্কোরের বিমূর্ত ধারণাটিকে সুনির্দিষ্ট ডেটা ফিল্টারে রূপান্তর করেন। আমাদের দুটি উদাহরণ স্কোরের ক্ষেত্রে মানদণ্ডগুলো ভিন্ন:
- ‘পারিবারিক-বান্ধব স্কোর’-এর জন্য আমরা সেইসব পার্ক, জাদুঘর এবং রেস্তোরাঁকে গুরুত্ব দিই, যেগুলো বিশেষভাবে শিশুদের জন্য উপযুক্ত।
- ‘পেট-ওনার প্যারাডাইস স্কোর’-এর জন্য আমরা পার্ক, পশুচিকিৎসা কেন্দ্র, পোষ্যের দোকান এবং কুকুর প্রবেশের অনুমতি আছে এমন যেকোনো রেস্তোরাঁ বা ক্যাফেকে বিবেচনা করি।
আপনি আপনার কোয়েরির WHERE ক্লজে সরাসরি এই নির্দিষ্ট অ্যাট্রিবিউটগুলো ফিল্টার করতে পারেন।
প্রতিটি অবস্থানের জন্য প্রাপ্ত তথ্য একত্রিত করুন
অবশেষে, প্রতিটি অ্যাপার্টমেন্টের জন্য আপনি কতগুলি প্রাসঙ্গিক স্থান খুঁজে পেয়েছেন তা গণনা করতে হবে। GROUP BY ক্লজটি ফলাফলগুলিকে একত্রিত করে, এবং COUNTIF ফাংশনটি আমাদের প্রতিটি স্কোরের জন্য নির্দিষ্ট মানদণ্ডের সাথে মেলে এমন স্থানগুলি গণনা করে।
নিচের কোয়েরিটি এই তিনটি ধাপকে একত্রিত করে, একবারে উভয় স্কোরের মূল সংখ্যা গণনা করে:
-- This Common Table Expression (CTE) will hold the raw counts for each score component.
WITH insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD -- Correctly includes the mandatory aggregation threshold
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places -- Corrected table name for the US dataset
ON ST_DWITHIN(apartments.location, places.point, 800) -- Find places within 800 meters
GROUP BY
apartments.id, apartments.name
)
SELECT * FROM insight_counts;
এই কোয়েরির ফলাফল এর অনুরূপ হবে।
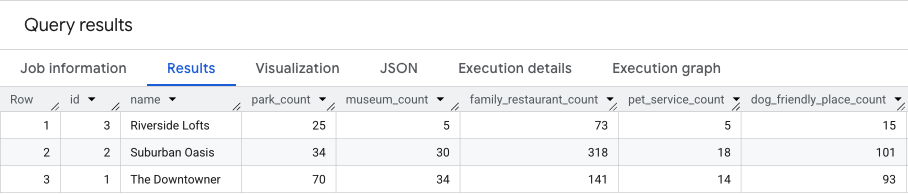
আমরা পরবর্তী অংশে এই ফলাফলগুলোর ওপর ভিত্তি করে আলোচনা করব।
৩. স্কোর তৈরি করুন
এখন আপনার কাছে প্রতিটি অবস্থানের জন্য স্থানের সংখ্যা এবং প্রতিটি স্থানের ধরনের ওয়েটিং (গুরুত্ব) রয়েছে, আপনি এখন কাস্টম লোকেশন স্কোর তৈরি করতে পারেন। এই বিভাগে আমরা দুটি বিকল্প নিয়ে আলোচনা করব: BigQuery-তে আপনার নিজস্ব কাস্টম ক্যালকুলেশন ব্যবহার করা অথবা BigQuery-তে জেনারেটিভ আর্টিফিশিয়াল ইন্টেলিজেন্স (AI) ফাংশন ব্যবহার করা।
বিকল্প ১: BigQuery-তে আপনার নিজস্ব কাস্টম ক্যালকুলেশন ব্যবহার করুন
পূর্ববর্তী ধাপের প্রাথমিক গণনাগুলো অন্তর্দৃষ্টিপূর্ণ, কিন্তু লক্ষ্য হলো একটি একক, ব্যবহার-বান্ধব স্কোর তৈরি করা। চূড়ান্ত ধাপ হলো ওয়েট ব্যবহার করে এই গণনাগুলোকে একত্রিত করা এবং তারপর ফলাফলটিকে একটি ০-১০ স্কেলে স্বাভাবিকীকরণ করা।
কাস্টম ওয়েট প্রয়োগ করা আপনার ওয়েট নির্বাচন করা একাধারে একটি শিল্প এবং বিজ্ঞান। এগুলিকে আপনার ব্যবসায়িক অগ্রাধিকার অথবা আপনার ব্যবহারকারীদের কাছে যা সবচেয়ে গুরুত্বপূর্ণ বলে আপনি মনে করেন, তা প্রতিফলিত করতে হবে। একটি 'পারিবারিক বন্ধুত্বপূর্ণতা' স্কোরের জন্য আপনি হয়তো সিদ্ধান্ত নিতে পারেন যে একটি পার্ক একটি জাদুঘরের চেয়ে দ্বিগুণ গুরুত্বপূর্ণ। আপনার সেরা অনুমানগুলি দিয়ে শুরু করুন এবং আমাদের ব্যবহারকারীদের প্রতিক্রিয়ার উপর ভিত্তি করে পুনরাবৃত্তি করুন।
স্কোরের নর্মালাইজেশন: নিচের কোয়েরিটিতে দুটি কমন টেবিল এক্সপ্রেশন (CTE) ব্যবহার করা হয়েছে: প্রথমটি আগের মতোই র কাউন্ট গণনা করে এবং দ্বিতীয়টি ওয়েটেড স্কোর গণনা করে। এরপর চূড়ান্ত SELECT স্টেটমেন্টটি ওয়েটেড স্কোরগুলোর উপর একটি মিন-ম্যাক্স নর্মালাইজেশন সম্পাদন করে। উদাহরণস্বরূপ apartment_listings টেবিলের location কলামটি আউটপুট হিসেবে দেখানো হয়, যাতে একটি মানচিত্রে ডেটা ভিজ্যুয়ালাইজেশন করা যায়।
WITH
-- CTE 1: Count nearby amenities of interest for each apartment listing.
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count,
COUNTIF(places.primary_type IN ('veterinary_care', 'pet_store')) AS pet_service_count,
COUNTIF(places.allows_dogs = TRUE) AS dog_friendly_place_count
FROM
`your_project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id,
apartments.name
),
-- CTE 2: Apply custom weighting to the amenity counts to generate raw scores.
raw_scores AS (
SELECT
id,
name,
(park_count * 3.0) + (museum_count * 1.5) + (family_restaurant_count * 2.5) AS family_friendliness_score,
(park_count * 2.0) + (pet_service_count * 3.5) + (dog_friendly_place_count * 2.5) AS pet_paradise_score
FROM
insight_counts
)
-- Final Step: Normalize scores to a 0-10 scale and rejoin to retrieve the location geometry.
SELECT
raw_scores.id,
raw_scores.name,
apartments.location,
raw_scores.family_friendliness_score,
raw_scores.pet_paradise_score,
-- Normalize Family Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.family_friendliness_score - MIN(raw_scores.family_friendliness_score) OVER ()),
(MAX(raw_scores.family_friendliness_score) OVER () - MIN(raw_scores.family_friendliness_score) OVER ())
) * 10,
0
),
2
) AS normalized_family_score,
-- Normalize Pet Score using a MIN/MAX window function.
ROUND(
COALESCE(
SAFE_DIVIDE(
(raw_scores.pet_paradise_score - MIN(raw_scores.pet_paradise_score) OVER ()),
(MAX(raw_scores.pet_paradise_score) OVER () - MIN(raw_scores.pet_paradise_score) OVER ())
) * 10,
0
),
2
) AS normalized_pet_score
FROM
raw_scores
JOIN
`your_project.your_dataset.apartment_listings` AS apartments
ON raw_scores.id = apartments.id;
কোয়েরির ফলাফল নীচেরটির মতো হবে। শেষের দুটি কলাম হলো নর্মালাইজড স্কোর।

স্বাভাবিককৃত স্কোর বুঝুন
এই চূড়ান্ত স্বাভাবিকীকরণ ধাপটি কেন এত মূল্যবান, তা বোঝা জরুরি। আপনার অবস্থানগুলোর শহুরে ঘনত্বের ওপর নির্ভর করে, কাঁচা ভারযুক্ত স্কোর ০ থেকে সম্ভাব্য একটি অনেক বড় সংখ্যা পর্যন্ত হতে পারে। প্রেক্ষাপট ছাড়া একজন ব্যবহারকারীর কাছে 500 -এর একটি স্কোর অর্থহীন।
নর্মালাইজেশন এই বিমূর্ত সংখ্যাগুলোকে একটি আপেক্ষিক র্যাঙ্কিং-এ রূপান্তরিত করে। ফলাফলকে ০ থেকে ১০ পর্যন্ত স্কেল করার মাধ্যমে, স্কোরটি স্পষ্টভাবে তুলে ধরে যে আপনার নির্দিষ্ট ডেটাসেটে প্রতিটি অবস্থান অন্যগুলোর তুলনায় কেমন।
- সর্বোচ্চ কাঁচা স্কোর প্রাপ্ত স্থানটিকে ১০ স্কোর প্রদান করা হয়, যা এটিকে বর্তমান সেটের সেরা বিকল্প হিসেবে চিহ্নিত করে।
- সর্বনিম্ন প্রাথমিক স্কোর পাওয়া স্থানটিকে ০ স্কোর দেওয়া হয়, যা তুলনার জন্য ভিত্তি হিসেবে কাজ করে। এর মানে এই নয় যে স্থানটিতে কোনো সুযোগ-সুবিধা নেই, বরং মূল্যায়ন করা অন্যান্য বিকল্পগুলোর তুলনায় এটি সবচেয়ে কম উপযুক্ত।
- অন্যান্য সমস্ত স্কোর আনুপাতিকভাবে এর মাঝামাঝি অবস্থানে থাকে, যা আপনার ব্যবহারকারীদের এক নজরে তাদের বিকল্পগুলো তুলনা করার একটি স্পষ্ট ও সহজবোধ্য উপায় প্রদান করে।
বিকল্প ২: AI.GENERATE ফাংশনটি ব্যবহার করুন (মিথুন রাশি)
একটি নির্দিষ্ট গাণিতিক সূত্র ব্যবহারের বিকল্প হিসেবে, আপনি আপনার SQL ওয়ার্কফ্লোর মধ্যেই সরাসরি কাস্টম লোকেশন স্কোর গণনা করতে BigQuery AI.GENERATE ফাংশনটি ব্যবহার করতে পারেন।
যদিও সুযোগ-সুবিধার সংখ্যার উপর ভিত্তি করে সম্পূর্ণ পরিমাণগত স্কোরিংয়ের জন্য অপশন ১ চমৎকার, তবে এটি সহজে গুণগত ডেটা অন্তর্ভুক্ত করতে পারে না। AI.GENERATE ফাংশনটি আপনাকে আপনার প্লেসেস ইনসাইটস কোয়েরির সংখ্যাগুলোকে অসংগঠিত ডেটার সাথে একত্রিত করতে দেয়, যেমন অ্যাপার্টমেন্ট লিস্টিংয়ের টেক্সট বিবরণ (উদাহরণস্বরূপ, "এই অবস্থানটি পরিবারের জন্য উপযুক্ত এবং এলাকাটি রাতে শান্ত থাকে") অথবা ব্যবহারকারীর প্রোফাইলের নির্দিষ্ট পছন্দসমূহ (উদাহরণস্বরূপ, "এই ব্যবহারকারী একটি পরিবারের জন্য বুকিং করছেন এবং একটি কেন্দ্রীয় অবস্থানে শান্ত এলাকা পছন্দ করেন")। এটি আপনাকে আরও সূক্ষ্ম একটি স্কোর তৈরি করতে দেয় যা এমন সব খুঁটিনাটি বিষয় শনাক্ত করতে পারে যা একটি কঠোর গণনায় বাদ পড়ে যেতে পারে, যেমন কোনো একটি অবস্থানে সুযোগ-সুবিধার ঘনত্ব বেশি থাকা সত্ত্বেও সেটিকে 'বাচ্চাদের জন্য খুব কোলাহলপূর্ণ' হিসেবে বর্ণনা করা হয়েছে।
প্রম্পটটি তৈরি করুন
এই ফাংশনটি ব্যবহার করার জন্য, অ্যাগ্রিগেশনের (ধাপ ২ থেকে প্রাপ্ত) ফলাফলগুলোকে একটি স্বাভাবিক ভাষার প্রম্পটে ফরম্যাট করা হয়। SQL-এ মডেলের নির্দেশাবলীর সাথে ডেটা কলাম সংযুক্ত করে এটি ডাইনামিকভাবে করা যেতে পারে।
নিচের কোয়েরিটিতে, প্রতিটি সারির জন্য একটি প্রম্পট তৈরি করতে insight_counts অ্যাপার্টমেন্টের টেক্সট বর্ণনার সাথে একত্রিত করা হয়েছে। স্কোরিংকে নির্দেশিত করার জন্য একটি টার্গেট ইউজার প্রোফাইলও সংজ্ঞায়িত করা হয়েছে।
SQL দিয়ে স্কোর তৈরি করুন
নিম্নলিখিত কোয়েরিটি BigQuery-তে সম্পূর্ণ অপারেশনটি সম্পাদন করে। এটি:
- স্থানভিত্তিক গণনাগুলোকে একত্রিত করে (যেমনটি ধাপ ২-এ বর্ণনা করা হয়েছে)।
- প্রতিটি অবস্থানের জন্য একটি প্রম্পট তৈরি করে ।
- জেমিনি মডেল ব্যবহার করে প্রম্পটটি বিশ্লেষণ করার জন্য
AI.GENERATEফাংশনটি কল করা হয় । - ফলাফলটিকে একটি কাঠামোগত বিন্যাসে পার্স করে , যা আপনার অ্যাপ্লিকেশনে ব্যবহারের জন্য প্রস্তুত থাকে।
WITH
-- CTE 1: Aggregate Place counts (Same as Step 2)
insight_counts AS (
SELECT WITH AGGREGATION_THRESHOLD
apartments.id,
apartments.name,
apartments.description, -- Assuming your table has a description column
COUNTIF(places.primary_type = 'park') AS park_count,
COUNTIF(places.primary_type = 'museum') AS museum_count,
COUNTIF(places.primary_type = 'restaurant' AND places.good_for_children = TRUE) AS family_restaurant_count
FROM
`your-project.your_dataset.apartment_listings` AS apartments
LEFT JOIN
`your-project.places_insights___us.places` AS places
ON ST_DWITHIN(apartments.location, places.point, 800)
GROUP BY
apartments.id, apartments.name, apartments.description
),
-- CTE 2: Construct the Prompt
prepared_prompts AS (
SELECT
id,
name,
FORMAT("""
You are an expert real estate analyst. Generate a 'Family-Friendliness Score' (0-10) for this location.
Target User: Young family with a toddler, looking for a balance of activity and quiet.
Location Data:
- Name: %s
- Description: %s
- Parks nearby: %d
- Museums nearby: %d
- Family-friendly restaurants nearby: %d
Scoring Rules:
- High importance: Proximity to parks and high restaurant count.
- Negative modifiers: Descriptions indicating excessive noise or nightlife focus.
- Positive modifiers: Descriptions indicating quiet streets or backyards.
""", name, description, park_count, museum_count, family_restaurant_count) AS prompt_text
FROM insight_counts
)
-- Final Step: Call AI.GENERATE
SELECT
id,
name,
-- Access the structured fields returned by the model
generated.family_friendliness_score,
generated.reasoning
FROM
prepared_prompts,
AI.GENERATE(
prompt_text,
endpoint => 'gemini-flash-latest',
output_schema => 'family_friendliness_score FLOAT64, reasoning STRING'
) AS generated;
কনফিগারেশনটি বুঝুন
- খরচ সচেতনতা: এই ফাংশনটি আপনার ইনপুট একটি জেমিনি মডেলে পাঠায় এবং প্রতিবার কল করার জন্য ভার্টেক্স এআই-তে চার্জ প্রযোজ্য হয়। যদি বিপুল সংখ্যক অবস্থান বিশ্লেষণ করা হয় (যেমন, হাজার হাজার অ্যাপার্টমেন্টের তালিকা), তবে প্রথমে ডেটাসেট থেকে সবচেয়ে প্রাসঙ্গিক বিকল্পগুলো ফিল্টার করে নেওয়ার পরামর্শ দেওয়া হয়। খরচ কমানোর বিষয়ে আরও বিস্তারিত জানতে, সেরা অনুশীলন (Best Practices) দেখুন।
- গতি এবং খরচ-দক্ষতাকে অগ্রাধিকার দিতে এই উদাহরণের জন্য
endpointহিসেবেgemini-flash-latestনির্দিষ্ট করা হয়েছে। তবে, আপনি আপনার প্রয়োজন অনুসারে সেরা মডেলটি বেছে নিতে পারেন। বিভিন্ন সংস্করণ (যেমন, আরও জটিল রিজনিং টাস্কের জন্য Gemini Pro) নিয়ে পরীক্ষা করতে এবং আপনার ব্যবহারের জন্য সবচেয়ে উপযুক্ত মডেলটি খুঁজে পেতে Gemini মডেলগুলোর ডকুমেন্টেশন দেখুন। -
output_schema: সরাসরি টেক্সট পার্স করার পরিবর্তে, একটি স্কিমা প্রয়োগ করা হয় (স্কোরের জন্যFLOAT64এবং যুক্তির জন্যSTRING)। এটি নিশ্চিত করে যে আউটপুটটি কোনো পোস্ট-প্রসেসিং ছাড়াই আপনার অ্যাপ্লিকেশন বা ভিজ্যুয়ালাইজেশন টুলগুলিতে অবিলম্বে ব্যবহারযোগ্য।
উদাহরণ আউটপুট
কোয়েরিটি কাস্টম স্কোর এবং মডেলের যুক্তিসহ একটি স্ট্যান্ডার্ড BigQuery টেবিল ফেরত দেয়।
| আইডি | নাম | পরিবার-বান্ধবতার স্কোর | যুক্তি |
|---|---|---|---|
| ১ | ডাউনটাউনার | ৫.৫ | চমৎকার সুযোগ-সুবিধা (পার্ক, রেস্তোরাঁ) পরিমাণগত মানদণ্ড পূরণ করে। তবে, গুণগত তথ্য থেকে সপ্তাহান্তে অতিরিক্ত কোলাহল এবং রাত্রিকালীন বিনোদনের প্রতি প্রবল মনোযোগের ইঙ্গিত পাওয়া যায়, যা লক্ষ্য ব্যবহারকারীর নিরিবিলি পরিবেশের চাহিদার সাথে সরাসরি সাংঘর্ষিক। |
| ২ | শহরতলির মরূদ্যান | ৯.৮ | চমৎকার পরিমাণগত তথ্যের সাথে এমন একটি বর্ণনা ("শান্ত, গাছপালা ঘেরা রাস্তা") যা লক্ষ্য পরিবারের প্রোফাইলের সাথে পুরোপুরি মিলে যায়। উচ্চ ইতিবাচক সংশোধকগুলির ফলে প্রায় নিখুঁত স্কোর পাওয়া যায়। |
এই পদ্ধতিটি আপনাকে একটিমাত্র SQL কোয়েরির মাধ্যমেই অত্যন্ত ব্যক্তিগতকৃত স্কোরিং প্রদান করতে দেয়, যা প্রতিটি ব্যবহারকারীর কাছে বোধগম্য এবং তাদের প্রয়োজন অনুযায়ী তৈরি বলে মনে হয়।
৪. মানচিত্রে আপনার স্কোরগুলো দেখুন
BigQuery Studio-তে এমন যেকোনো কোয়েরি ফলাফলের জন্য একটি সমন্বিত মানচিত্র ভিজ্যুয়ালাইজেশন রয়েছে, যেটিতে একটি GEOGRAPHY কলাম থাকে। যেহেতু আমাদের কোয়েরিটি location কলামটি আউটপুট করে, আপনি তাৎক্ষণিকভাবে আপনার স্কোরগুলো দেখতে পারবেন।
Visualization ট্যাবে ক্লিক করলে ম্যাপটি প্রদর্শিত হবে, এবং Data Column ড্রপ-ডাউনটি ভিজ্যুয়ালাইজ করার জন্য লোকেশন স্কোর নিয়ন্ত্রণ করে। এই উদাহরণে, অপশন ১ উদাহরণ থেকে normalized_pet_score টি ভিজ্যুয়ালাইজ করা হয়েছে। লক্ষ্য করুন যে, এই উদাহরণের জন্য apartment_listings টেবিলে আরও লোকেশন যোগ করা হয়েছে।
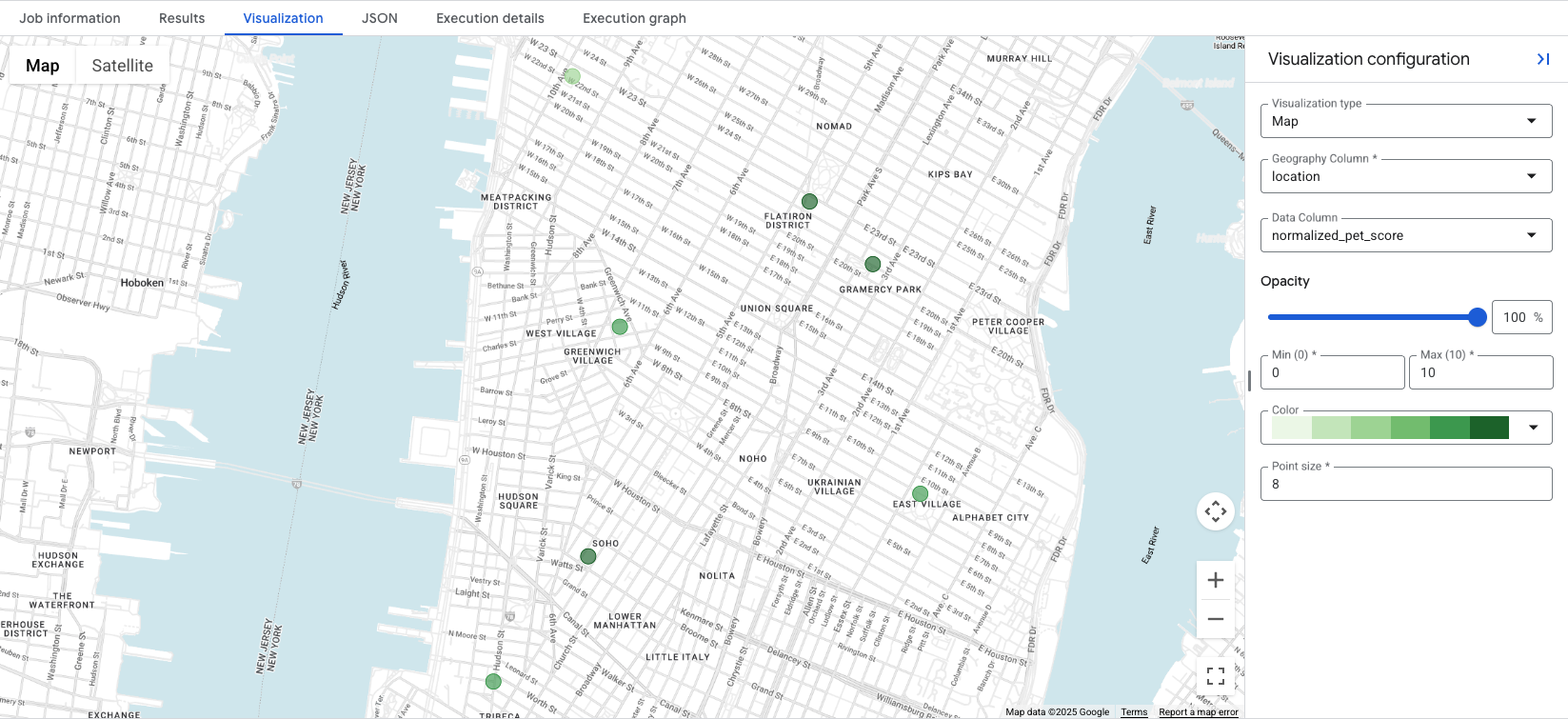
ডেটা ভিজ্যুয়ালাইজ করলে তৈরি করা স্কোরের জন্য সবচেয়ে উপযুক্ত স্থানগুলো এক নজরেই দেখা যায়, এক্ষেত্রে গাঢ় সবুজ বৃত্তগুলো উচ্চতর normalized_pet_score যুক্ত স্থানগুলোকে নির্দেশ করে। Places Insights-এর আরও ডেটা ভিজ্যুয়ালাইজেশন বিকল্পের জন্য, 'কোয়েরির ফলাফল ভিজ্যুয়ালাইজ করুন ' দেখুন।
উপসংহার
এখন আপনার কাছে সূক্ষ্ম অবস্থান স্কোর তৈরির জন্য একটি শক্তিশালী এবং পুনরাবৃত্তিযোগ্য পদ্ধতি রয়েছে। আপনার অবস্থানগুলো থেকে শুরু করে, আপনি BigQuery-তে একটি একক SQL কোয়েরি তৈরি করেছেন যা ST_DWITHIN ব্যবহার করে কাছাকাছি স্থান খুঁজে বের করে, good_for_children এবং allows_dogs মতো উন্নত অ্যাট্রিবিউট দ্বারা সেগুলোকে ফিল্টার করে এবং COUNTIF ব্যবহার করে ফলাফলগুলোকে একত্রিত করে। কাস্টম ওয়েট প্রয়োগ করে এবং ফলাফলকে নর্মালাইজ করে, আপনি একটি একক, ব্যবহারকারী-বান্ধব স্কোর তৈরি করেছেন যা গভীর ও কার্যকরী অন্তর্দৃষ্টি প্রদান করে। আপনি এই প্যাটার্নটি সরাসরি প্রয়োগ করে কাঁচা অবস্থান ডেটাকে একটি উল্লেখযোগ্য প্রতিযোগিতামূলক সুবিধায় রূপান্তরিত করতে পারেন।
পরবর্তী পদক্ষেপ
এখন আপনার তৈরির পালা। এই টিউটোরিয়ালটি একটি টেমপ্লেট প্রদান করে। আপনার ব্যবহারের ক্ষেত্রে সবচেয়ে প্রয়োজনীয় স্কোরগুলো তৈরি করতে আপনি প্লেসেস ইনসাইটস স্কিমাতে উপলব্ধ সমৃদ্ধ ডেটা ব্যবহার করতে পারেন। আপনি তৈরি করতে পারেন এমন অন্যান্য স্কোরগুলোও বিবেচনা করতে পারেন:
- "নাইটলাইফ স্কোর": রাতের অন্ধকারে সবচেয়ে প্রাণবন্ত এলাকাগুলো খুঁজে পেতে
primary_type(bar,night_club),price_levelএবং লেট-নাইট ওপেনিং আওয়ার্স-এর ফিল্টারগুলো একত্রিত করুন। - "ফিটনেস ও ওয়েলনেস স্কোর": স্বাস্থ্য-সচেতন ব্যবহারকারীদের জন্য স্থানগুলোকে স্কোর দেওয়ার উদ্দেশ্যে, কাছাকাছি থাকা
gyms,parksওhealth_food_storesগণনা করুন এবংserves_vegetarian_foodকরে এমন রেস্তোরাঁগুলো ফিল্টার করুন। - "যাত্রীদের জন্য স্বপ্নের স্কোর": যেসব ব্যবহারকারী যাতায়াতের সুবিধাকে গুরুত্ব দেন, তাদের সাহায্য করার জন্য কাছাকাছি
transit_stationএবংparkingস্থানের ঘনত্ব বেশি এমন এলাকা খুঁজুন।
অবদানকারীরা
হেনরিক ভালভ | ডেভএক্স ইঞ্জিনিয়ার