
מטרה
במדריך אימות כתובות בכמות גדולה מוסבר על תרחישים שונים שבהם אפשר להשתמש באימות כתובות בכמות גדולה. במדריך הזה נציג לכם דפוסי עיצוב שונים ב-Google Cloud Platform להפעלת אימות כתובות בכמויות גדולות.
נתחיל בסקירה כללית על הרצת Address Validation בכמות גדולה ב-Google Cloud Platform באמצעות Cloud Run, Compute Engine או Google Kubernetes Engine להרצה חד-פעמית. לאחר מכן נראה איך אפשר לכלול את היכולת הזו כחלק מפייפליין.
בסוף המאמר הזה תהיה לכם הבנה טובה של האפשרויות השונות להפעלת Address Validation בנפח גבוה בסביבת Google Cloud.
ארכיטקטורת הפניה ב-Google Cloud Platform
בקטע הזה נסביר יותר לעומק על דפוסי עיצוב שונים לאימות כתובות בכמויות גדולות באמצעות Google Cloud Platform. הפלטפורמה פועלת ב-Google Cloud Platform, כך שתוכלו לשלב אותה עם התהליכים וצינורות הנתונים הקיימים שלכם.
הפעלת Address Validation בכמות גדולה פעם אחת ב-Google Cloud Platform
בהמשך מוצגת ארכיטקטורת עזר להטמעה ב-Google Cloud Platform, שמתאימה יותר לפעולות חד-פעמיות או לבדיקות.

במקרה כזה, מומלץ להעלות את קובץ ה-CSV לקטגוריה של Cloud Storage. אחרי כן, אפשר להריץ את הסקריפט 'Address Validation בכמות גדולה' בסביבת Cloud Run. עם זאת, אפשר להריץ אותו בכל סביבת זמן ריצה אחרת, כמו Compute Engine או Google Kubernetes Engine. אפשר גם להעלות את קובץ ה-CSV שנוצר לקטגוריה ב-Cloud Storage.
הפעלה כפייפליין נתונים של Google Cloud Platform
דפוס הפריסה שמוצג בקטע הקודם מתאים לבדיקה מהירה של Address Validation בכמויות גדולות לשימוש חד-פעמי. עם זאת, אם אתם צריכים להשתמש בו באופן קבוע כחלק מ<b>פייפליין</b> נתונים, כדאי לכם להשתמש ביכולות המובנות של Google Cloud Platform כדי להפוך אותו ליציב יותר. דוגמאות לשינויים שאפשר לבצע:
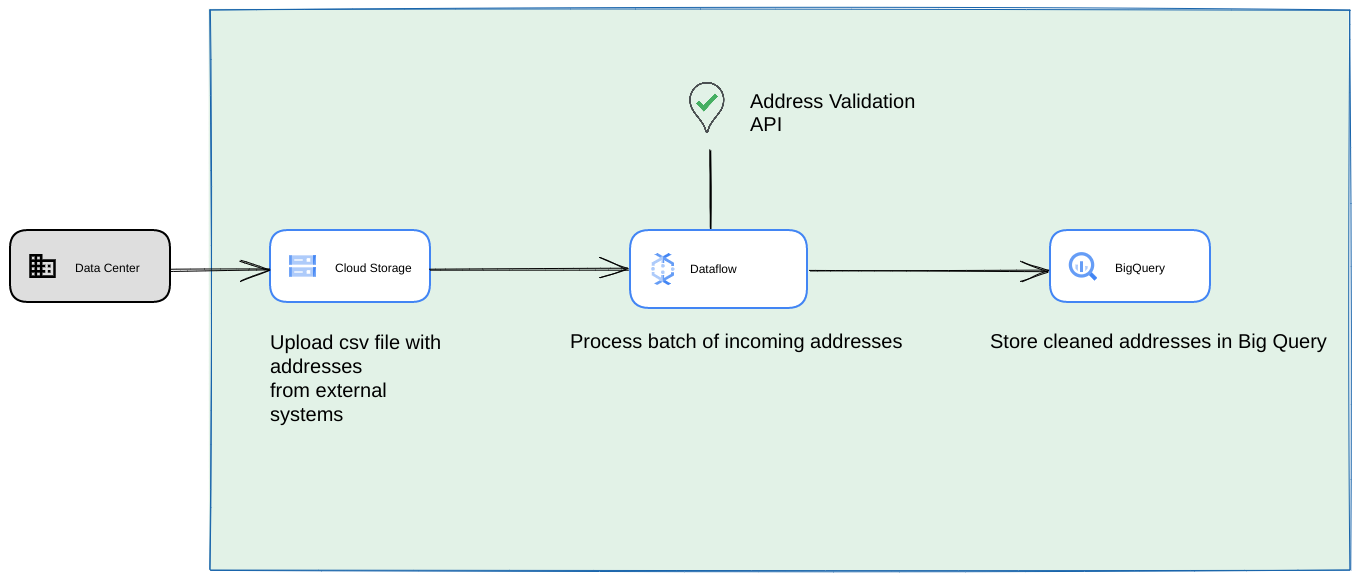
- במקרה כזה, אפשר להעביר קובצי CSV לקטגוריות של Cloud Storage.
- משימת Dataflow יכולה לאסוף את הכתובות לעיבוד ואז לשמור אותן במטמון ב-BigQuery.
- אפשר להרחיב את ספריית Python של Dataflow כדי להוסיף לה לוגיקה לאימות כתובות בכמויות גדולות, וכך לאמת את הכתובות מעבודת Dataflow.
הפעלת הסקריפט מפייפליין נתונים כתהליך חוזר שנמשך זמן רב
גישה נפוצה נוספת היא אימות של אצווה של כתובות כחלק מפייפליין נתונים של סטרימינג, כתהליך חוזר. יכול להיות שהכתובות שמורות גם במאגר נתונים של BigQuery. בגישה הזו נראה איך לבנות פייפליין נתונים חוזר (שצריך להפעיל אותו מדי יום, שבוע או חודש)
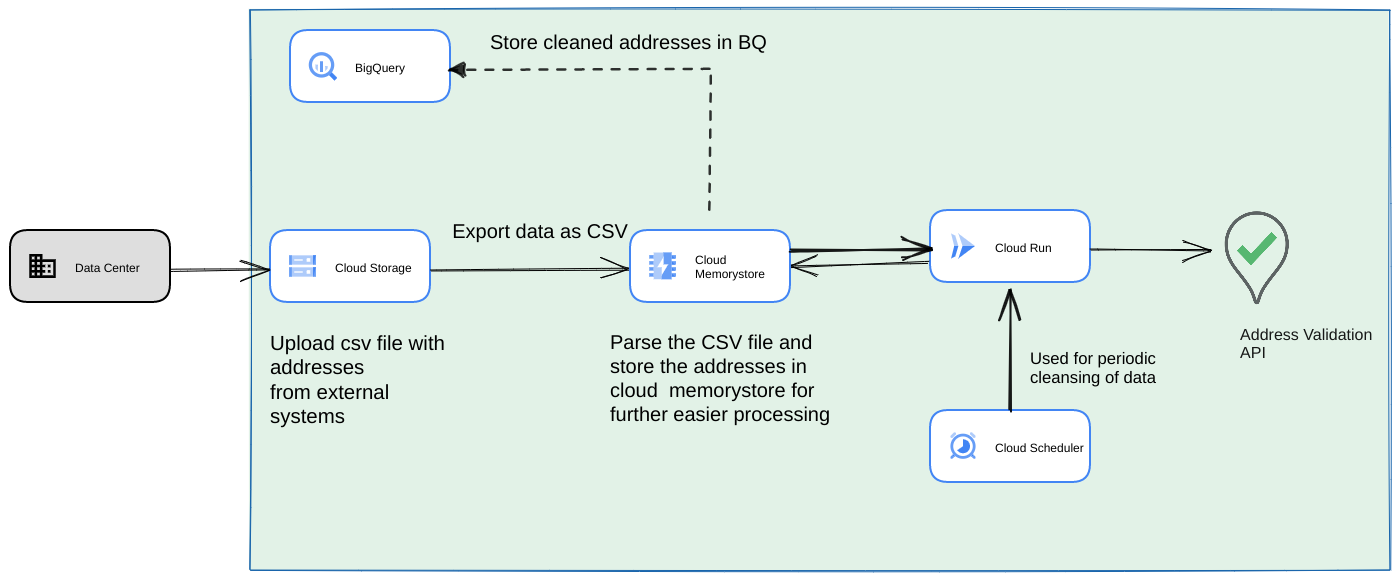
- מעלים את קובץ ה-CSV הראשוני לקטגוריה ב-Cloud Storage.
- משתמשים ב-Memorystore כמאגר נתונים קבוע כדי לשמור את המצב הביניים של התהליך הארוך.
- שמירת הכתובות הסופיות במטמון במאגר נתונים של BigQuery.
- מגדירים את Cloud Scheduler להרצת הסקריפט באופן תקופתי.
לארכיטקטורה הזו יש את היתרונות הבאים:
- אפשר להשתמש ב-Cloud Scheduler כדי לבצע אימות של כתובות באופן תקופתי. מומלץ לאמת מחדש את הכתובות מדי חודש או לאמת כתובות חדשות מדי חודש או רבעון. הארכיטקטורה הזו עוזרת לפתור את תרחיש השימוש הזה.
אם נתוני הלקוחות נמצאים ב-BigQuery, אפשר לשמור במטמון ישירות שם את הכתובות שאומתו או את דגלי האימות. הערה: פירוט לגבי מה אפשר לשמור במטמון ואיך אפשר לעשות את זה מופיע במאמר בנושא Address Validation בכמויות גדולות
שימוש ב-Memorystore מספק עמידות גבוהה יותר ויכולת לעבד יותר כתובות. השלב הזה מוסיף שמירת מצב לכל פייפליין העיבוד, שנדרש לטיפול במערכי נתונים גדולים מאוד של כתובות. אפשר להשתמש כאן גם בטכנולוגיות אחרות של מסדי נתונים, כמו Cloud SQL[https://cloud.google.com/sql] או כל סוג אחר של מסד נתונים שמוצע ב-Google Cloud Platform. עם זאת, לדעתנו, שירות Memorystore מאזן בצורה מושלמת בין הצורך בהרחבה לבין הצורך בפשטות, ולכן הוא הבחירה הראשונה המומלצת.
סיכום
בעזרת הדפוסים שמתוארים כאן, תוכלו להשתמש ב-Address Validation API בתרחישי שימוש שונים ובמגוון תרחישי שימוש ב-Google Cloud Platform.
כתבנו ספריית Python בקוד פתוח כדי לעזור לכם להתחיל להשתמש בתרחישי השימוש שמתוארים למעלה. אפשר להפעיל אותו משורת פקודה במחשב, או מ-Google Cloud Platform או מספקי ענן אחרים.
מידע נוסף על השימוש בספרייה זמין במאמר הזה.
השלבים הבאים
אפשר להוריד את מאמר המדיניות בנושא שיפור תהליך התשלום, המשלוח והתפעול באמצעות כתובות מהימנות ולצפות בוובינר בנושא שיפור תהליך התשלום, המשלוח והתפעול באמצעות Address Validation .
הצעות לקריאה נוספת:
תורמים
Google היא זו שכותבת את המאמר הזה. הוא נכתב במקור על ידי התורמים הבאים.
המחברים הראשיים:
Henrik Valve | Solutions Engineer
Thomas Anglaret | Solutions Engineer
Sarthak Ganguly | Solutions Engineer