Dataset (Dataset, DataCatalog, DataDownload) structured data
Datasets are easier to find in the Dataset Search tool when you provide supporting information such as their name, description, creator and distribution formats as structured data. Google's approach to dataset discovery makes use of schema.org and other metadata standards that can be added to pages that describe datasets. The purpose of this markup is to improve discovery of datasets from fields such as life sciences, social sciences, machine learning, civic and government data, and more.
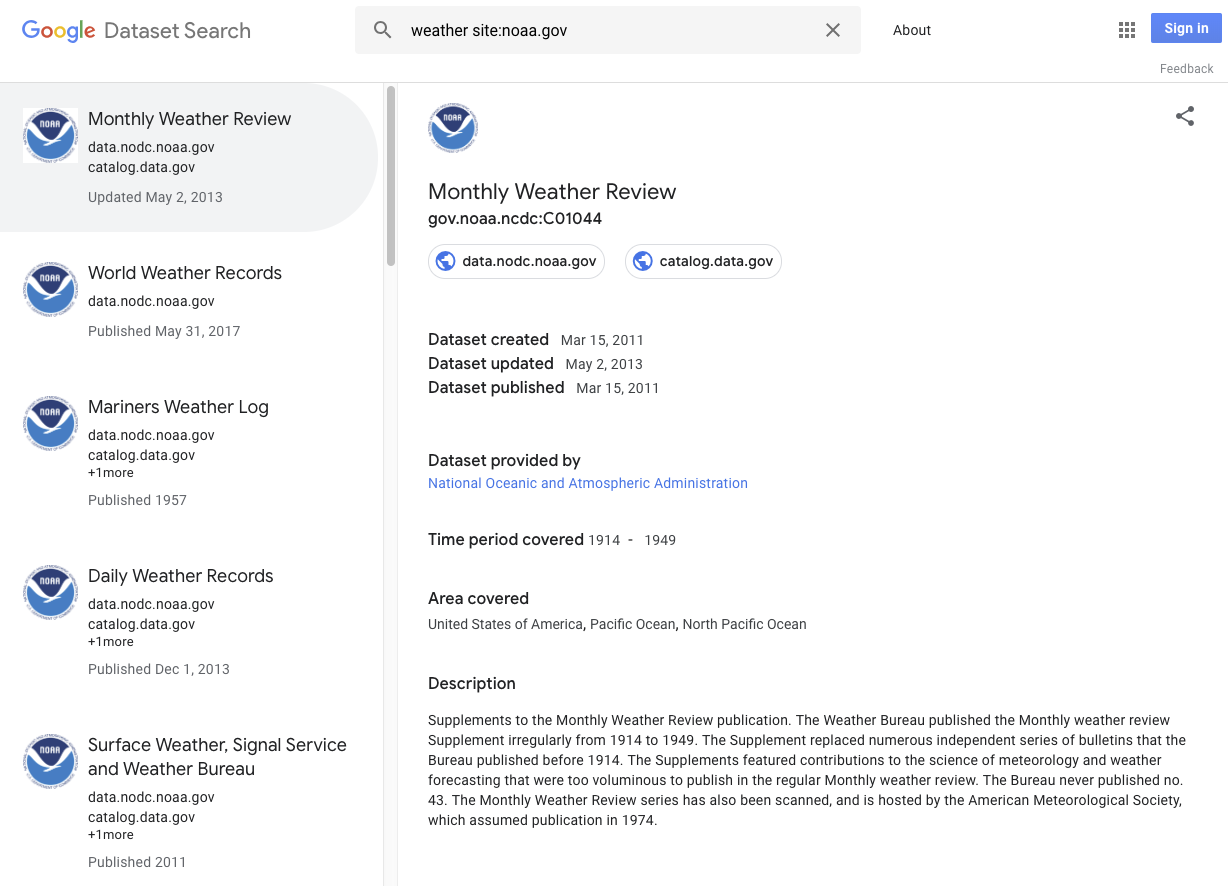
Here are some examples of what can qualify as a dataset:
- A table or a CSV file with some data
- An organized collection of tables
- A file in a proprietary format that contains data
- A collection of files that together constitute some meaningful dataset
- A structured object with data in some other format that you might want to load into a special tool for processing
- Images capturing data
- Files relating to machine learning, such as trained parameters or neural network structure definitions
How to add structured data
Structured data is a standardized format for providing information about a page and classifying the page content. If you're new to structured data, you can learn more about how structured data works.
Here's an overview of how to build, test, and release structured data.
- Add the required properties. Based on the format you're using, learn where to insert structured data on the page.
- Follow the guidelines.
- Validate your code using the Rich Results Test and fix any critical errors. Consider also fixing any non-critical issues that may be flagged in the tool, as they can help improve the quality of your structured data (however, this isn't necessary to be eligible for rich results).
- Deploy a few pages that include your structured data and use the URL Inspection tool to test how Google sees the page. Be sure that your page is
accessible to Google and not blocked by a robots.txt file, the
noindextag, or login requirements. If the page looks okay, you can ask Google to recrawl your URLs. - To keep Google informed of future changes, we recommend that you submit a sitemap. You can automate this with the Search Console Sitemap API.
Deleting a dataset from Dataset Search results
If you don't want a dataset to show up in Dataset Search results, use the robots meta tag to control how your dataset is indexed. Keep in mind that it might take some time (days or weeks, depending on the crawl schedule) for the changes to be reflected on Dataset Search.
Our approach to dataset discovery
We can understand structured data in web pages about datasets, using either schema.org Dataset markup, or equivalent
structures represented in W3C's Data Catalog Vocabulary (DCAT) format. We also are exploring
experimental support for structured data based on W3C CSVW, and expect to evolve and adapt our approach as best practices for dataset description emerge. For more information about our
approach to dataset discovery, see
Making it easier to discover datasets.
Examples
Here's an example for datasets using JSON-LD and schema.org syntax (preferred) in the Rich Results Test. The same schema.org vocabulary can also be used in RDFa 1.1 or Microdata syntaxes. You can also use the W3C DCAT vocabulary to describe the metadata. The following example is based on a real-world dataset description.
Here's an example of a dataset in JSON-LD:
<html>
<head>
<title>NCDC Storm Events Database</title>
<script type="application/ld+json">
{
"@context":"https://schema.org/",
"@type":"Dataset",
"name":"NCDC Storm Events Database",
"description":"Storm Data is provided by the National Weather Service (NWS) and contain statistics on...",
"url":"https://catalog.data.gov/dataset/ncdc-storm-events-database",
"sameAs":"https://gis.ncdc.noaa.gov/geoportal/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510",
"identifier": ["https://doi.org/10.1000/182",
"https://identifiers.org/ark:/12345/fk1234"],
"keywords":[
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > CYCLONES",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > DROUGHT",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FOG",
"ATMOSPHERE > ATMOSPHERIC PHENOMENA > FREEZE"
],
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"isAccessibleForFree" : true,
"hasPart" : [
{
"@type": "Dataset",
"name": "Sub dataset 01",
"description": "Informative description of the first subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 01 creator"
}
},
{
"@type": "Dataset",
"name": "Sub dataset 02",
"description": "Informative description of the second subdataset...",
"license" : "https://creativecommons.org/publicdomain/zero/1.0/",
"creator":{
"@type":"Organization",
"name": "Sub dataset 02 creator"
}
}
],
"creator":{
"@type":"Organization",
"url": "https://www.ncei.noaa.gov/",
"name":"OC/NOAA/NESDIS/NCEI > National Centers for Environmental Information, NESDIS, NOAA, U.S. Department of Commerce",
"contactPoint":{
"@type":"ContactPoint",
"contactType": "customer service",
"telephone":"+1-828-271-4800",
"email":"ncei.orders@noaa.gov"
}
},
"funder":{
"@type": "Organization",
"sameAs": "https://ror.org/00tgqzw13",
"name": "National Weather Service"
},
"includedInDataCatalog":{
"@type":"DataCatalog",
"name":"data.gov"
},
"distribution":[
{
"@type":"DataDownload",
"encodingFormat":"CSV",
"contentUrl":"https://www.ncdc.noaa.gov/stormevents/ftp.jsp"
},
{
"@type":"DataDownload",
"encodingFormat":"XML",
"contentUrl":"https://gis.ncdc.noaa.gov/all-records/catalog/search/resource/details.page?id=gov.noaa.ncdc:C00510"
}
],
"temporalCoverage":"1950-01-01/2013-12-18",
"spatialCoverage":{
"@type":"Place",
"geo":{
"@type":"GeoShape",
"box":"18.0 -65.0 72.0 172.0"
}
}
}
</script>
</head>
<body>
</body>
</html>Here's an example of a dataset in RDFa using the DCAT vocabulary (not supported in Rich Results Test):
<article about="/node/1234" typeof="dcat:Dataset">
<dl>
<dt>Name:</dt>
<dd property="dc:title">ACME Inc Cash flow data</dd>
<dt>Identifiers:</dt>
<dd property="dc:identifier">https://doi.org/10.1000/182</dd>
<dd property="dc:identifier">https://identifiers.org/ark:/12345/fk1234</dd>
<dt>Description:</dt>
<dd property="dc:description">Financial Statements - Consolidated Statement of Cash Flows</dd>
<dt>Category:</dt>
<dd rel="dc:subject">Financial</dd>
<dt class="field-label">Downloads:</dt>
<dd>
<ul>
<li>
<a rel="dcat:distribution" href="Consolidated_Statement_of_Cash_Flows_en.csv"><span property="dcat:mediaType" content="text/csv" >Consolidated_Statement_of_Cash_Flows_en.csv</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/Consolidated_Statement_of_Cash_Flows_en.xls"><span property="dcat:mediaType" content="application/vnd.ms-excel">Consolidated_Statement_of_Cash_Flows_en.xls</span></a>
</li>
<li>
<a rel="dcat:distribution" href="files/consolidated_statement_of_cash_flows_en.xml"><span property="dcat:mediaType" content="application/xml">consolidated_statement_of_cash_flows_en.xml</span></a>
</li>
</ul>
</dd>
</dl>
</article>Guidelines
Sites must follow the structured data guidelines. In addition to the structured data guidelines, we recommend the following sitemap and source and provenance best practices.
Sitemap best practices
Use a sitemap file to help
Google find your URLs. Using sitemap files and sameAs markup helps document how
dataset descriptions are published throughout your site.
If you have a dataset repository, you likely have at least two types of pages: the canonical
("landing") pages for each dataset and pages that list multiple datasets (for example, search
results, or some subset of datasets). We recommend that you add structured data about a dataset to
the canonical pages. Use the sameAs
property to link to the canonical page if you add structured data to multiple copies of the
dataset, such as listings in search results pages.
Source and provenance best practices
It is common for open datasets to be republished, aggregated, and to be based on other datasets. This is an initial outline of our approach to representing situations in which a dataset is a copy of, or otherwise based upon, another dataset.
- Use the
sameAsproperty to indicate the most canonical URLs for the original in cases when the dataset or description is a simple republication of materials published elsewhere. The value ofsameAsneeds to unambiguously indicate the dataset's identity - in other words, don't use the samesameAsvalue for two different datasets. - Use the
isBasedOnproperty in cases where the republished dataset (including its metadata) has been changed significantly. - When a dataset derives from or aggregates several originals, use the
isBasedOnproperty. - Use the
identifierproperty to attach any relevant Digital Object identifiers (DOIs) or Compact Identifiers. If the dataset has more than one identifier, repeat theidentifierproperty. If using JSON-LD, this is represented using JSON list syntax.
We hope to improve our recommendations based on feedback, in particular around the description of provenance, versioning, and the dates associated with time series publication. Please join in community discussions.
Textual property recommendations
We recommend limiting all textual properties to 5000 characters or less. Google Dataset Search only uses the first 5000 characters of any textual property. Names and titles are typically a few words or a short sentence.
Known Errors and Warnings
You may experience errors or warnings in Google's Rich Results Test and other validation systems. Specifically, validation systems may
suggest that organizations must have contact information including a contactType; useful values include
customer service, emergency, journalist, newsroom, and public engagement.
You can also ignore errors for csvw:Table being an unexpected value for the mainEntity property.
Structured data type definitions
You must include the required properties for your content to be eligible for display as a rich result. You can also include the recommended properties to add more information about your content, which could provide a better user experience.
You can use the Rich Results Test to validate your markup.
The focus is on describing information about a dataset (its metadata) and representing its contents. For example, dataset metadata states what the dataset is about, which variables it measures, who created it, and so on. It does not, for example, contain specific values for the variables.
Dataset
The full definition of Dataset is available at
schema.org/Dataset.
You can describe additional information about the publication of the dataset, such as the
license, when it was published, its
DOI,
or a sameAs pointing to a canonical version of the dataset in a different
repository. Add identifier, license, and sameAs for
datasets that provide provenance and license information.
The Google-supported properties are the following:
| Required properties | |
|---|---|
description
|
Text
A short summary describing a dataset. Guidelines
|
name
|
Text
A descriptive name of a dataset. For example, "Snow depth in the Northern Hemisphere". Guidelines
Recommended: Not recommended: |
| Recommended properties | |
|---|---|
alternateName
|
Text
Alternative names that have been used to refer to this dataset, such as aliases or abbreviations. Example (in JSON-LD format): "name": "The Quick, Draw! Dataset" "alternateName": ["Quick Draw Dataset", "quickdraw-dataset"] |
creator
|
Person or
Organization
The creator or author of this dataset. To uniquely identify individuals, use
ORCID ID as the value of the "creator": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0000", "givenName": "Jane", "familyName": "Foo", "name": "Jane Foo" }, { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0001", "givenName": "Jo", "familyName": "Bar", "name": "Jo Bar" }, { "@type": "Organization", "sameAs": "https://ror.org/xxxxxxxxx", "name": "Fictitious Research Consortium" } ] |
citation
|
Text or CreativeWork
Identifies academic articles that are recommended by the data provider be cited in addition to the
dataset itself. Provide the citation for the dataset itself with other properties, such as "citation": "https://doi.org/10.1111/111" "citation": "https://identifiers.org/pubmed:11111111" "citation": "https://identifiers.org/arxiv:0111.1111v1" "citation": "Doe J (2014) Influence of X ... https://doi.org/10.1111/111" Additional guidelines
|
funder
|
Person or
Organization
A person or organization that provides financial support for this dataset. To uniquely identify individuals, use
ORCID ID as the value of the "funder": [ { "@type": "Person", "sameAs": "https://orcid.org/0000-0000-0000-0002", "givenName": "Jane", "familyName": "Funder", "name": "Jane Funder" }, { "@type": "Organization", "sameAs": "https://ror.org/yyyyyyyyy", "name": "Fictitious Funding Organization" } ] |
hasPart or isPartOf
|
URL or
Dataset
If the dataset is a collection of smaller datasets, use the "hasPart" : [ { "@type": "Dataset", "name": "Sub dataset 01", "description": "Informative description of the first subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 01 creator" } }, { "@type": "Dataset", "name": "Sub dataset 02", "description": "Informative description of the second subdataset...", "license": "https://creativecommons.org/publicdomain/zero/1.0/", "creator": { "@type":"Organization", "name": "Sub dataset 02 creator" } } ] "isPartOf" : "https://example.com/aggregate_dataset" |
identifier
|
URL, Text, or PropertyValue
An identifier, such as a DOI or a Compact Identifier. If the dataset has more than one
identifier, repeat the |
isAccessibleForFree
|
Boolean
Whether the dataset is accessible without payment. |
keywords
|
Text
Keywords summarizing the dataset. |
license
|
URL or CreativeWork
A license under which the dataset is distributed. For example: "license" : "https://creativecommons.org/publicdomain/zero/1.0/" "license" : { "@type": "CreativeWork", "name": "Custom license", "url": "https://example.com/custom_license" } Additional guidelines
|
measurementTechnique
|
Text or URL
The technique, technology, or methodology used in a dataset, which can correspond to the variable(s) described in |
sameAs
|
URL
The URL of a reference web page that unambiguously indicates the dataset's identity. |
spatialCoverage |
Text or Place
You can provide a single point that describes the spatial aspect of the dataset. Only include this property if the dataset has a spatial dimension. For example, a single point where all the measurements were collected, or the coordinates of a bounding box for an area. Points "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoCoordinates", "latitude": 39.3280, "longitude": 120.1633 } } Shapes Use "spatialCoverage:" { "@type": "Place", "geo": { "@type": "GeoShape", "box": "39.3280 120.1633 40.445 123.7878" } } Points inside Named locations "spatialCoverage:" "Tahoe City, CA" |
temporalCoverage |
Text
The data in the dataset covers a specific time interval. Only include this property if the
dataset has a temporal dimension. Schema.org uses the ISO 8601 standard
to describe time intervals and time points. You can describe dates differently depending
upon the dataset interval. Indicate open-ended intervals with two decimal points ( Single date "temporalCoverage" : "2008" Time period "temporalCoverage" : "1950-01-01/2013-12-18" Open-ended time period "temporalCoverage" : "2013-12-19/.." |
variableMeasured
|
Text or PropertyValue
The variable that this dataset measures. For example, temperature or pressure. |
version
|
Text or Number
The version number for the dataset. |
url
|
URL
Location of a page describing the dataset. |
DataCatalog
The full definition of DataCatalog is available at
schema.org/DataCatalog.
Datasets are often published in repositories that contain many other datasets. The same dataset can be included in more than one such repository. You can refer to a data catalog that this dataset belongs to by referencing it directly by using the following properties:
| Recommended properties | |
|---|---|
includedInDataCatalog
|
DataCatalog
The catalog to which the dataset belongs.
|
DataDownload
The full definition of DataDownload is available at
schema.org/DataDownload. In addition to Dataset properties,
add the following properties for datasets that provide download options.
The distribution property describes how to get the dataset itself because the URL
often points to the landing page describing the dataset. The distribution
property describes where to get the data and in what format. This property can
have several values: for instance, a CSV version has one URL and an Excel
version is available at another.
| Required properties | |
|---|---|
distribution.contentUrl
|
URL
The link for the download. |
| Recommended properties | |
|---|---|
distribution
|
DataDownload
The description of the location for download of the dataset and the file format for download.
|
distribution.encodingFormat
|
Text or URL
The file format of the distribution.
|
Tabular datasets
A tabular dataset is one organized primarily in terms of a grid of rows and columns. For pages that embed tabular datasets, you can also create more explicit markup, building on the basic approach. At this time we understand a variation of CSVW ("CSV on the Web", see W3C), provided in parallel to user-oriented tabular content on the HTML page.
Here is an example showing a small table encoded in CSVW JSON-LD format. There are some known errors in the Rich Results Test.
<html>
<head>
<title>American Humane Association</title>
<script type="application/ld+json">
{
"@context": ["https://schema.org", {"csvw": "https://www.w3.org/ns/csvw#"}],
"@type": "Dataset",
"name":"AMERICAN HUMANE ASSOCIATION",
"description": "ProPublica's Nonprofit Explorer lets you view summaries of 2.2 million tax returns from tax-exempt organizations and see financial details such as their executive compensation and revenue and expenses. You can browse raw IRS data released since 2013 and access over 9.4 million tax filing documents going back as far as 2001.",
"publisher": {
"@type": "Organization",
"name": "ProPublica"
},
"mainEntity" : {
"@type" : "csvw:Table",
"csvw:tableSchema": {
"csvw:columns": [
{
"csvw:name": "Year",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "2024",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization name",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "AMERICAN HUMANE ASSOCIATION",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization address",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "1400 16TH STREET NW",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Organization NTEE Code",
"csvw:datatype": "string",
"csvw:cells": [
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "D200",
"csvw:notes": "Animal Protection and Welfare",
"csvw:primaryKey": "2024"
}]
},
{
"csvw:name": "Total functional expenses ($)",
"csvw:datatype": "integer",
"csvw:cells": [
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
},
{
"csvw:value": "13800212",
"csvw:primaryKey": "2024"
}]
}]
}
}
}
</script>
</head>
<body>
</body>
</html>Monitor rich results with Search Console
Search Console is a tool that helps you monitor how your pages perform in Google Search. You don't have to sign up for Search Console to be included in Google Search results, but it can help you understand and improve how Google sees your site. We recommend checking Search Console in the following cases:
- After deploying structured data for the first time
- After releasing new templates or updating your code
- Analyzing traffic periodically
After deploying structured data for the first time
After Google has indexed your pages, look for issues using the relevant Rich result status report. Ideally, there will be an increase of valid items, and no increase in invalid items. If you find issues in your structured data:
- Fix the invalid items.
- Inspect a live URL to check if the issue persists.
- Request validation using the status report.
After releasing new templates or updating your code
When you make significant changes to your website, monitor for increases in structured data invalid items.- If you see an increase in invalid items, perhaps you rolled out a new template that doesn't work, or your site interacts with the existing template in a new and bad way.
- If you see a decrease in valid items (not matched by an increase in invalid items), perhaps you are no longer embedding structured data in your pages. Use the URL Inspection tool to learn what is causing the issue.
Analyzing traffic periodically
Analyze your Google Search traffic using the Performance Report. The data will show you how often your page appears as a rich result in Search, how often users click on it and what is the average position you appear on search results. You can also automatically pull these results with the Search Console API.Troubleshooting
If you're having trouble implementing or debugging structured data, here are some resources that may help you.
- If you're using a content management system (CMS) or someone else is taking care of your site, ask them to help you. Make sure to forward any Search Console message that details the issue to them.
- Google does not guarantee that features that consume structured data will show up in search results. For a list of common reasons why Google may not show your content in a rich result, see the General Structured Data Guidelines.
- You might have an error in your structured data. Check the list of structured data errors and the Unparsable structured data report.
- If you received a structured data manual action against your page, the structured data on the page will be ignored (although the page can still appear in Google Search results). To fix structured data issues, use the Manual Actions report.
- Review the guidelines again to identify if your content isn't compliant with the guidelines. The problem can be caused by either spammy content or spammy markup usage. However, the issue may not be a syntax issue, and so the Rich Results Test won't be able to identify these issues.
- Troubleshoot missing rich results / drop in total rich results.
- Allow time for re-crawling and re-indexing. Remember that it may take several days after publishing a page for Google to find and crawl it. For general questions about crawling and indexing, check the Google Search crawling and indexing FAQ.
- Post a question in the Google Search Central forum.
Specific dataset isn't showing up in Dataset Search results
error What caused the issue: Your site doesn't have structured data on the page that describes the datasets or the page hasn't been crawled yet.
done Fix the issue
- Copy the link for the page that you expect to see in Dataset Search results, and put it into the Rich Results Test. If the message "Page not eligible for rich results known by this test" or "Not all markup is eligible for rich results" appears, this means there's no dataset markup on the page or it's incorrect. You can fix it by referring to the How to add structured data section.
- If there is markup on the page, it may not have been crawled yet. You can check the crawl status with Search Console.
Company logo is missing or not appearing correctly by results
error What caused the issue: Your page may be missing schema.org markup for organization logos or your business isn't established with Google.
done Fix the issue
- Add logo structured data to your page.
- Establish your business details with Google.