Understand the JavaScript SEO basics
JavaScript is an important part of the web platform because it provides many features that turn the web into a powerful application platform. Making your JavaScript-powered web applications discoverable via Google Search can help you find new users and re-engage existing users as they search for the content your web app provides. While Google Search runs JavaScript with an evergreen version of Chromium, there are a few things that you can optimize.
This guide describes how Google Search processes JavaScript and best practices for improving JavaScript web apps for Google Search.
How Google processes JavaScript
Google processes JavaScript web apps in three main phases:
- Crawling
- Rendering
- Indexing
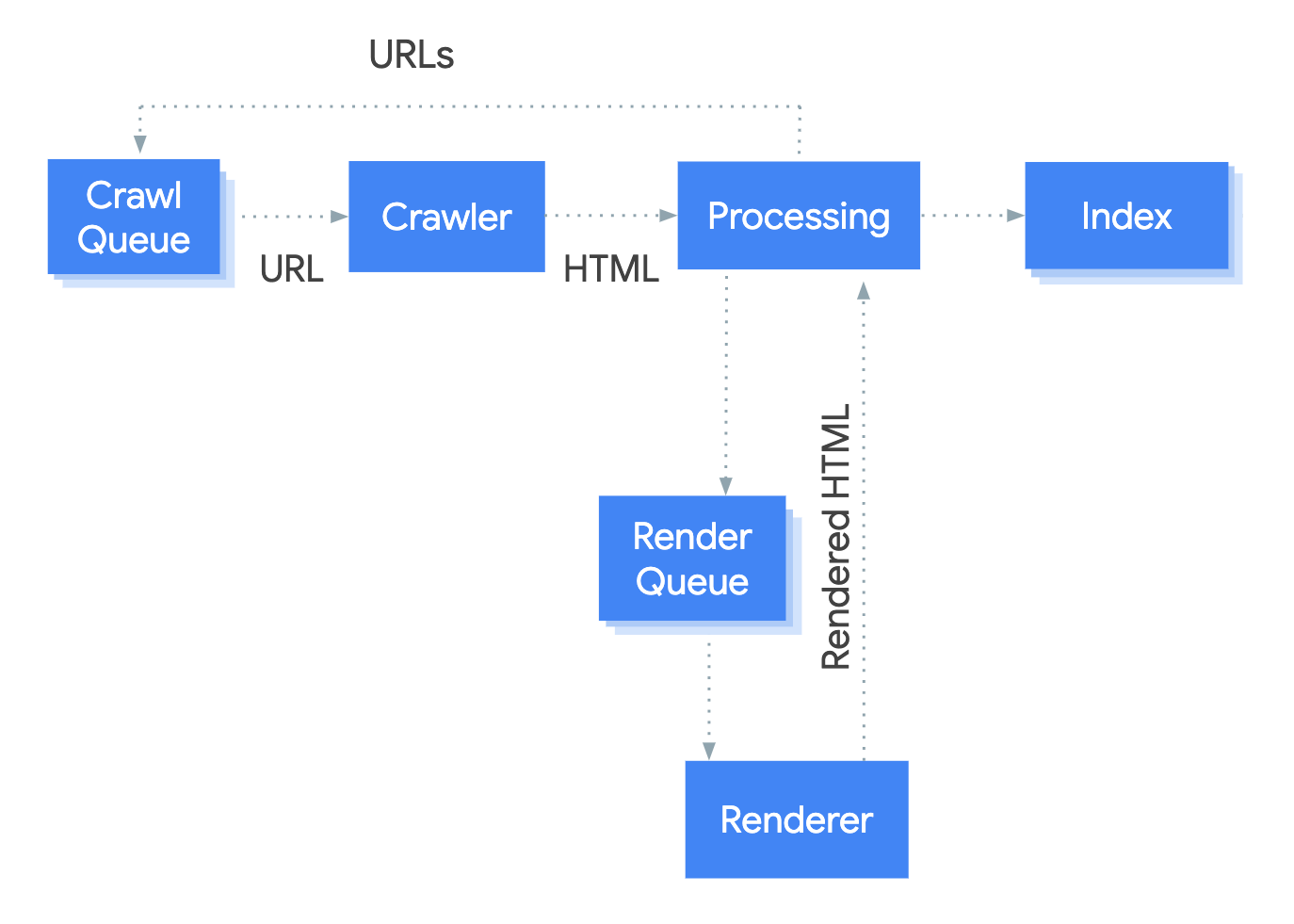
Googlebot queues pages for both crawling and rendering. It is not immediately obvious when a page is waiting for crawling and when it is waiting for rendering. When Googlebot fetches a URL from the crawling queue by making an HTTP request, it first checks if you allow crawling. Googlebot reads the robots.txt file. If it marks the URL as disallowed, then Googlebot skips making an HTTP request to this URL and skips the URL. Google Search won't render JavaScript from blocked files or on blocked pages.
Googlebot then parses the response for other URLs in the href attribute of HTML links and adds the URLs to the crawl queue. To prevent link discovery, use the nofollow mechanism.
Crawling a URL and parsing the HTML response works well for classical websites or server-side rendered pages where the HTML in the HTTP response contains all content. Some JavaScript sites may use the app shell model where the initial HTML does not contain the actual content and Google needs to execute JavaScript before being able to see the actual page content that JavaScript generates.
Googlebot queues all pages with a 200 HTTP status code for rendering, unless a robots meta tag or header tells Google not to index the page.
The page may stay on this queue for a few seconds, but it can take longer than that. Once Google's resources allow, a headless Chromium renders the page and executes the JavaScript.
Googlebot parses the rendered HTML for links again and queues the URLs it finds for crawling. Google also uses the rendered HTML to index the page.
Keep in mind that server-side or pre-rendering is still a great idea because it makes your website faster for users and crawlers, and not all bots can run JavaScript.
Describe your page with unique titles and snippets
Unique, descriptive <title> elements and meta descriptions help users quickly identify the best result for their goal.
You can use JavaScript to set or change the meta description as well as the <title> element.
Set the canonical URL
The rel="canonical" link tag helps Google find the canonical version of a page.
You can use JavaScript to set the canonical URL, but keep in mind that you shouldn't use JavaScript to change the canonical URL to something else than the URL you specified as the canonical URL in the original HTML.
The best way to set the canonical URL is to use HTML, but if you have to use JavaScript, make sure that you always set the canonical URL to the same value as the original HTML.
If you can't set the canonical URL in the HTML, then you can use JavaScript to set the canonical URL and leave it out of the original HTML.
Write compatible code
Browsers offer many APIs and JavaScript is a quickly-evolving language. Google has some limitations regarding which APIs and JavaScript features it supports. To make sure your code is compatible with Google, follow our guidelines for troubleshooting JavaScript problems.
We recommend using differential serving and polyfills if you feature-detect a missing browser API that you need. Since some browser features cannot be polyfilled, we recommend that you check the polyfill documentation for potential limitations.
Use meaningful HTTP status codes
Googlebot uses HTTP status codes to find out if something went wrong when crawling the page.
To tell Googlebot if a page can't be crawled or indexed, use a meaningful status code, like a 404 for a page that could not be found or a 401 code for pages behind a login.
You can use HTTP status codes to tell Googlebot if a page has moved to a new URL, so that the index can be updated accordingly.
Here's a list of HTTP status codes and how they effect Google Search.
Avoid soft 404 errors in single-page apps
In client-side rendered single-page apps, routing is often implemented as client-side routing.
In this case, using meaningful HTTP status codes can be impossible or impractical.
To avoid soft 404 errors when using client-side rendering and routing, use one of the following strategies:
- Use a JavaScript redirect to a URL for which the server responds with a
404HTTP status code (for example/not-found). - Add a
<meta name="robots" content="noindex">to error pages using JavaScript.
Here is sample code for the redirect approach:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. window.location.href = '/not-found'; // redirect to 404 page on the server. } })
Here is sample code for the noindex tag approach:
fetch(`/api/products/${productId}`) .then(response => response.json()) .then(product => { if(product.exists) { showProductDetails(product); // shows the product information on the page } else { // this product does not exist, so this is an error page. // Note: This example assumes there is no other robots meta tag present in the HTML. const metaRobots = document.createElement('meta'); metaRobots.name = 'robots'; metaRobots.content = 'noindex'; document.head.appendChild(metaRobots); } })
Use the History API instead of fragments
Google can only discover your links if they are <a> HTML elements with an href attribute.
For single-page applications with client-side routing, use the History API to implement routing between different views of your web app. To ensure that Googlebot can parse and extract your URLs, don't use fragments to load different page content. The following example is a bad practice, because Googlebot can't reliably resolve the URLs:
<nav> <ul> <li><a href="#/products">Our products</a></li> <li><a href="#/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="#/products">our products</a> and <a href="#/services">our services</a></p> </div> <script> window.addEventListener('hashchange', function goToPage() { // this function loads different content based on the current URL fragment const pageToLoad = window.location.hash.slice(1); // URL fragment document.getElementById('placeholder').innerHTML = load(pageToLoad); }); </script>
Instead, you can make sure your URLs are accessible to Googlebot by implementing the History API:
<nav> <ul> <li><a href="/products">Our products</a></li> <li><a href="/services">Our services</a></li> </ul> </nav> <h1>Welcome to example.com!</h1> <div id="placeholder"> <p>Learn more about <a href="/products">our products</a> and <a href="/services">our services</a></p> </div> <script> function goToPage(event) { event.preventDefault(); // stop the browser from navigating to the destination URL. const hrefUrl = event.target.getAttribute('href'); const pageToLoad = hrefUrl.slice(1); // remove the leading slash document.getElementById('placeholder').innerHTML = load(pageToLoad); window.history.pushState({}, window.title, hrefUrl) // Update URL as well as browser history. } // Enable client-side routing for all links on the page document.querySelectorAll('a').forEach(link => link.addEventListener('click', goToPage)); </script>
Properly inject the rel="canonical" link tag
While we don't recommend using JavaScript for this, it is possible to inject a rel="canonical" link tag with JavaScript.
Google Search will pick up the injected canonical URL when rendering the page. Here is an example to inject a rel="canonical" link tag with JavaScript:
fetch('/api/cats/' + id) .then(function (response) { return response.json(); }) .then(function (cat) { // creates a canonical link tag and dynamically builds the URL // e.g. https://example.com/cats/simba const linkTag = document.createElement('link'); linkTag.setAttribute('rel', 'canonical'); linkTag.href = 'https://example.com/cats/' + cat.urlFriendlyName; document.head.appendChild(linkTag); });
Use robots meta tags carefully
You can prevent Google from indexing a page or following links through the robots meta tag.
For example, adding the following meta tag to the top of your page blocks Google from indexing the page:
<!-- Google won't index this page or follow links on this page --> <meta name="robots" content="noindex, nofollow">
You can use JavaScript to add a robots meta tag to a page or change its content.
The following example code shows how to change the robots meta tag with JavaScript to prevent indexing of the current page if an API call doesn't return content.
fetch('/api/products/' + productId) .then(function (response) { return response.json(); }) .then(function (apiResponse) { if (apiResponse.isError) { // get the robotsmetatag var metaRobots = document.querySelector('meta[name="robots"]'); // if there was no robotsmetatag, add one if (!metaRobots) { metaRobots = document.createElement('meta'); metaRobots.setAttribute('name', 'robots'); document.head.appendChild(metaRobots); } // tell Google to exclude this page from the index metaRobots.setAttribute('content', 'noindex'); // display an error message to the user errorMsg.textContent = 'This product is no longer available'; return; } // display product information // ... });
Use long-lived caching
Googlebot caches aggressively in order to reduce network requests and resource usage. WRS may ignore caching headers. This may lead WRS to use outdated JavaScript or CSS resources.
Content fingerprinting avoids this problem by making a fingerprint of the content part of the filename, like main.2bb85551.js.
The fingerprint depends on the content of the file, so updates generate a different filename every time.
Check out the web.dev guide on long-lived caching strategies to learn more.
Use structured data
When using structured data on your pages, you can use JavaScript to generate the required JSON-LD and inject it into the page. Make sure to test your implementation to avoid issues.
Follow best practices for web components
Google supports web components. When Google renders a page, it flattens the shadow DOM and light DOM content. This means Google can only see content that's visible in the rendered HTML. To make sure that Google can still see your content after it's rendered, use the Rich Results Test or the URL Inspection Tool and look at the rendered HTML.
If the content isn't visible in the rendered HTML, Google won't be able to index it.
The following example creates a web component that displays its light DOM content inside its shadow DOM. One way to make sure both light DOM and shadow DOM content is displayed in the rendered HTML is to use a Slot element.
<script>
class MyComponent extends HTMLElement {
constructor() {
super();
this.attachShadow({ mode: 'open' });
}
connectedCallback() {
let p = document.createElement('p');
p.innerHTML = 'Hello World, this is shadow DOM content. Here comes the light DOM: <slot></slot>';
this.shadowRoot.appendChild(p);
}
}
window.customElements.define('my-component', MyComponent);
</script>
<my-component>
<p>This is light DOM content. It's projected into the shadow DOM.</p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>After rendering, Google can index this content:
<my-component>
Hello World, this is shadow DOM content. Here comes the light DOM:
<p>This is light DOM content. It's projected into the shadow DOM<p>
<p>WRS renders this content as well as the shadow DOM content.</p>
</my-component>
Fix images and lazy-loaded content
Images can be quite costly on bandwidth and performance. A good strategy is to use lazy-loading to only load images when the user is about to see them. To make sure you're implementing lazy-loading in a search-friendly way, follow our lazy-loading guidelines.