Read how topics are inferred, how they're assigned to users' browsers, and how users can control their topics list.
Implementation status
- The Topics API has completed the public discussion phase and is currently available to 99 percent of users, scaling up to 100 percent.
- To provide your feedback on the Topics API, create an Issue on the Topics explainer or participate in discussions in the Improving Web Advertising Business Group. The explainer has a number of open questions that still require further definition.
- The Privacy Sandbox timeline provides implementation timelines for the Topics API and other Privacy Sandbox proposals.
- Topics API: latest updates details changes and enhancements to the Topics API and implementations.
What is a topic?
A topic, in the Topics API, is a subject a user is interested in as evidenced by the websites they visit.
Topics are a signal to help ad tech platforms select relevant ads. Unlike third-party cookies, this information is shared without revealing further information about the user themself or the user's browsing activity.
The Topics API allows third parties, such as ad tech platforms, to observe and then access topics of interest to a user. For example, the API might suggest the topic "Fiber & Textile Arts" for a user who visits the website knitting.example.
The list of topics used by the Topics API is public, human-curated, human-readable, and designed to avoid sensitive categories. This is the current list, which will expand over time. The list is structured as a taxonomy. The topics can be high-level or more specific. For example, Food & Drink is a broad category, with a subcategory of Cooking & Recipes. Subcategories may be further divided into additional subcategories.
Such a taxonomy of topics needs to make a tradeoff between utility and privacy. If topics are too specific, they could be used to identify an individual user. If they are too general, they aren't useful for selecting advertising or other content.
The topics taxonomy is constructed with two underlying requirements in mind:
- Support interest-based advertising
- Keep users safe and protect their privacy
This suggests several questions. For example:
- What's the best way for the API to infer topics of interest for a user, based on their browsing activity, while preserving the user's privacy?
- How could the taxonomy be structured to make it more useful?
- What specific items should the taxonomy include?
How the API infers topics for a site
Topics are derived from a classifier model that maps website hostnames to zero or more topics. Analyzing additional information (such as full URLs or page contents) might allow for more relevant ads, but might also reduce privacy.
The classifier model for mapping hostnames to topics is publicly available, and as the explainer notes, it is possible to view the topics for a site via browser developer tools. The model is expected to evolve and improve over time and be updated periodically; the frequency of this is still under consideration.
Only sites that include code that calls the Topics API are included in the browsing history eligible for topic frequency calculations, and API callers only receive topics they've observed. In other words, sites are not eligible for topic frequency calculations without the site or an embedded service calling the API.
In addition, a caller can only receive topics that their code has "seen." So if another caller's code registered a topic, say /Autos & Vehicles/Motor Vehicles (By Type)/Hatchbacks, for a user's browser and your code did not cause that topic to be registered for that user's browser, you will not be able to learn of that topic of interest for that user's browser when you call the API from your embedded code. Note that because the API now includes ancestors as having been observed, the example above, /Autos & Vehicles/Motor Vehicles (By Type)/Hatchbacks, would also cause Autos & Vehicles and Motor Vehicles to be observed.
Topics returned for a user are recalculated for a caller depending on the top-level site. For example, if adtech.example requests the user's topics on news-a.example, then on news-b.example, and then on news-c.example, topics returned to them will be recalculated on each site. This means a caller is likely to get different topics for a user on different top-level sites, since the (maximum) three topics returned for a user are chosen at random from the top five for the past three epochs (with a 5% chance of getting a random topic). That makes it harder for a caller to identify a user by their topics, since these are likely to be different across different top-level sites (even for the same user, caller, and epoch).
The classifier model
Topics are manually curated for 50,000 top domains, and this curation is used to train the classifier. This list can be found in override_list.pb.gz, which is available at chrome://topics-internals/ under the current model in the Classifier tab. The domain-to-topics associations in the list are used by the API in lieu of the output of the model itself.
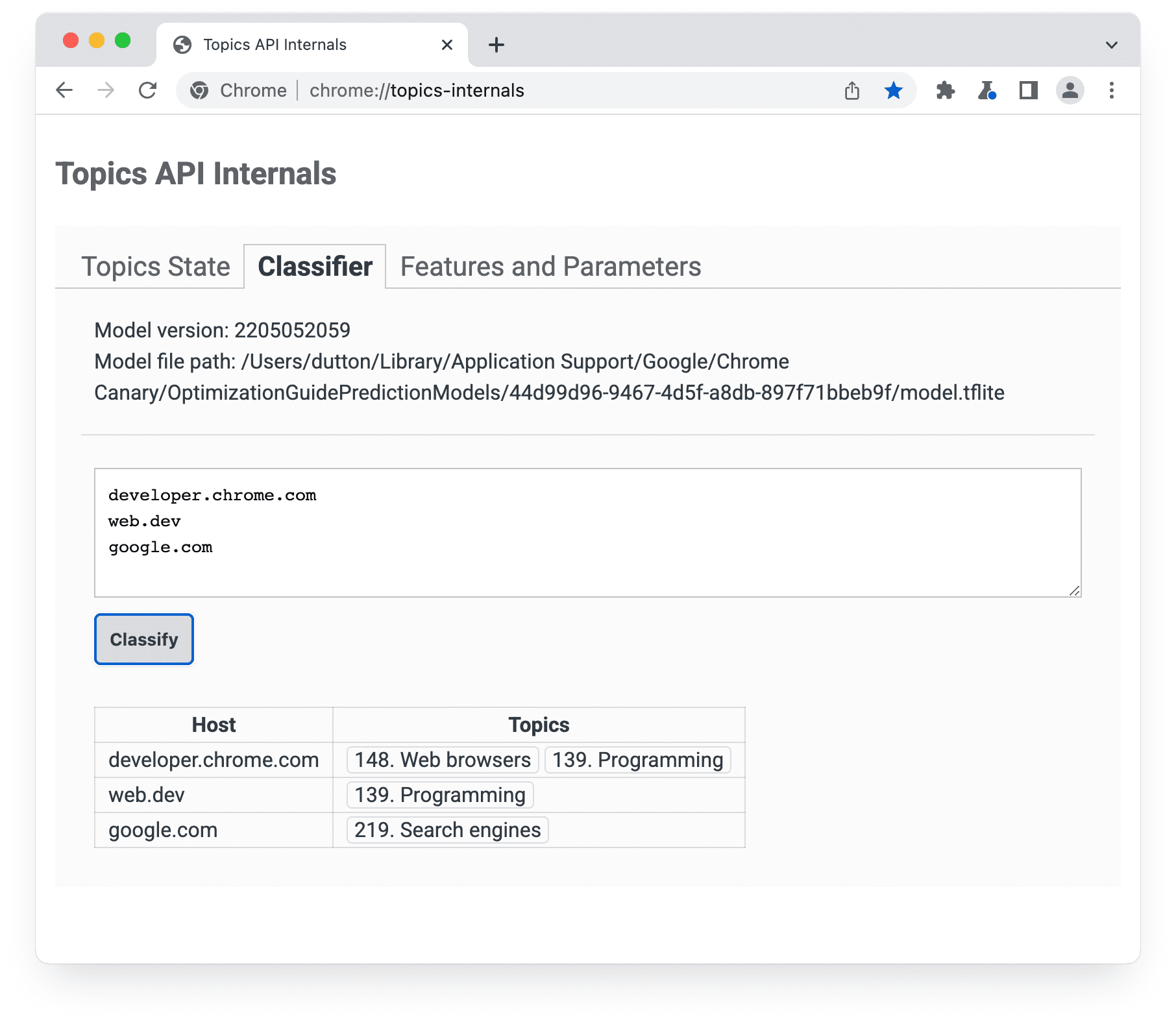
chrome://topics-internals page Classifier panel lists the model version, its path, and the topics associated with each host listed.To run the model directly, refer to TensorFlow's guide to running a model.
To inspect the override_list.pb.gz file, first unpack it:
gunzip -c override_list.pb.gz > override_list.pb
Use protoc to inspect it as text:
protoc --decode_raw < override_list.pb > output.txt
A full taxonomy of topics with IDs is available on GitHub.
Providing feedback or input on the classifier model
There are several channels for providing feedback on the Topics API. For feedback on the classifier model, we recommend submitting a GitHub issue or replying to an existing issue. For example:
How the user's top five topics are selected
The API returns one topic for each epoch, up to a maximum of three. If three are returned, this includes topics for the current epoch and the previous two.
- At the end of each epoch, the browser compiles a list of pages that meet the following criteria:
- The page was visited by the user during the epoch.
- The page includes code that calls
document.browsingTopics(). - The API was enabled (for example, not blocked by the user or via a response header).
- The browser, on the user's device, uses the classifier model provided by the Topics API to map the hostname for each page to a list of topics.
- The browser accumulates the list of topics.
- The browser generates a list of the top five topics by frequency.
The document.browsingTopics() method then returns a random topic from the top five for each epoch, with a 5% chance that any of these may be randomly chosen from the full taxonomy of topics. In Chrome, users are also able to remove individual topics, or clear their browsing history to reduce the number of topics returned by the API. Users may also opt out of the API.
You can view information about topics observed during the current epoch from the chrome://topics-internals page.
How the API decides which callers see which topics
API callers only receive topics they've recently observed, and the topics for a user are refreshed once each epoch. That means the API provides a rolling window in which a given caller may receive certain topics.
The table below outlines an example (though unrealistically small) of a hypothetical browsing history for a user during a single epoch, showing topics associated with the sites they've visited, and the API callers present on each site (the entities that call document.browsingTopics() in JavaScript code included on the site).
| Site | Topics | API callers on site |
|---|---|---|
| yoga.example | Fitness | adtech1.example adtech2.example |
| knitting.example | Crafts | adtech1.example |
| hiking-holiday.example | Fitness, Travel & Transportation | adtech2.example |
| diy-clothing.example | Crafts, Fashion & Style | [none] |
At the end of the epoch (currently one week) the Topics API generates the browser's top topics for the week.
- adtech1.example is now eligible to receive the "Fitness" and "Crafts" topics, since it observed them on yoga.example and also on knitting.example.
- adtech1.example is not eligible to receive the "Travel & Transportation" topic for this user as it is not present on any sites the user visited recently that are associated with that topic.
- adtech2.example has seen the "Fitness" and "Travel & Transportation" topics, but has not seen the "Crafts" topic.
The user visited diy-clothing.example, which has the "Fashion & Style" topic, but there were no calls to the Topics API on that site. At this point, this means the "Fashion & Style" topic would not be returned by the API for any caller.
In week two, the user visits another site:
| Site | Topics | API callers on site |
|---|---|---|
| sewing.example | Crafts | adtech2.example |
In addition, code from adtech2.example is added to diy-clothing.example:
| Site | Topics | API callers on site |
|---|---|---|
| diy-clothing.example | Crafts, Fashion & Style | adtech2.example |
As well as "Fitness" and "Travel & Transportation" from week 1, this means that adtech2.example will now be able to receive the "Crafts" and "Fashion & Style" topic — but not until the following epoch, week 3. This ensures that third parties can't learn more about a user's past (in this case, an interest in fashion) than they could with cookies.
After another two weeks, "Fitness" and "Travel & Transportation" may drop out of adtech2.example's list of eligible topics if the user doesn't visit any sites with those topics that include code from adtech2.example.
User controls, transparency, and opting out
Users should be able to understand the purpose of the Topics API, recognize what is being said about them, know when the API is in use, and be provided with controls to enable or disable it.
The API's human-readable taxonomy enables users to learn about and control the topics that may be suggested for them by their browser. Users can remove topics they specifically do not want the Topics API to share with advertisers or publishers, and there can be controls to inform the user about the API and show how to enable or disable it. Chrome provides information and settings for the Topics API at chrome://settings/adPrivacy. In addition, topics are not available to API callers in Incognito mode, and topics are cleared when browsing history is cleared.
The list of topics returned will be empty if:
- The user opts out of the Topics API via browser settings at
chrome://settings/adPrivacy. - The user has cleared their topics (via the browser settings at
chrome://settings/adPrivacy) or cleared their cookies. - The browser is in Incognito mode.
The explainer provides more detail about privacy goals and how the API seeks to address them.
Site opt out
In addition to the user's ability to opt out, you can opt out of Topics for your site or pages on it. The Developer guide explains how.
Using the Topics API on websites with prebid.js
As noted in the release of Prebid 7, the community actively developed an integration with the Topics API via a new module. This module was merged in December 2022.
Learn more here:
- Read Prebid's Topics API module documentation.
- For more information, reach out to Prebid.js through whatever standard channel they offer.
Next steps
- If you're an ad tech developer, experiment and participate with the Topics API.
- Read the developer guide for more in-depth resources.
- Check out the Topics API integration guide for details on specific ad tech use cases.
Engage and share feedback
- GitHub: Read the Topics API explainer, and raise questions and follow discussion in issues on the API repo.
- W3C: Discuss industry use cases in the Improving Web Advertising Business Group.
- Announcements: Join or view the mailing list.
- Privacy Sandbox developer support: Ask questions and join discussions on the Privacy Sandbox Developer Support repo.
- Chromium: File a Chromium bug to ask questions about the implementation currently available to test in Chrome.