Deploy and manage this service to produce summary reports for the Attribution Reporting API or the Private Aggregation API.
Deploy and manage an Aggregation Service to process aggregatable reports from the Attribution Reporting API or the Private Aggregation API to create a summary report.
Implementation status
- The Aggregation Service has now moved to general availability.
- The Aggregation Service can be tested with the Attribution Reporting API and the Private Aggegration API for Protected Audience API and Shared Storage.
The explainer outlines key terms, useful for understanding the Aggregation Service.
Availability
| Proposal | Status |
|---|---|
| Aggregation Service support for Amazon Web Services (AWS) across Attribution Reporting API, Private Aggregation API
Explainer |
Available |
| Aggregation Service support for Google Cloud across Attribution Reporting API, Private Aggregation API Explainer |
Available in beta |
| Aggregation Service site enrollment and mapping of a site to cloud accounts (AWS, or GCP) FAQs on GitHub |
Available |
| The Aggregation Service's epsilon value will be kept as a range of up to 64, to facilitate experimentation and feedback on different parameters.
Submit ARA epsilon feedback. Submit PAA epsilon feedback. |
Available. We will provide advanced notice to the ecosystem before the epsilon range values are updated. |
| More flexible contribution filtering for Aggregation Service queries
Explainer |
Expected Q2 2024 |
| Process for budget recovery post-disasters (errors, misconfigurations, and so on)
GitHub issue |
Expected Q2 2024 |
| Accenture operating as one of the Coordinators on AWS
Developer Blog |
Available |
| Independent party operating as one of the Coordinators on Google Cloud
Developer Blog |
Expected Q3 2024 |
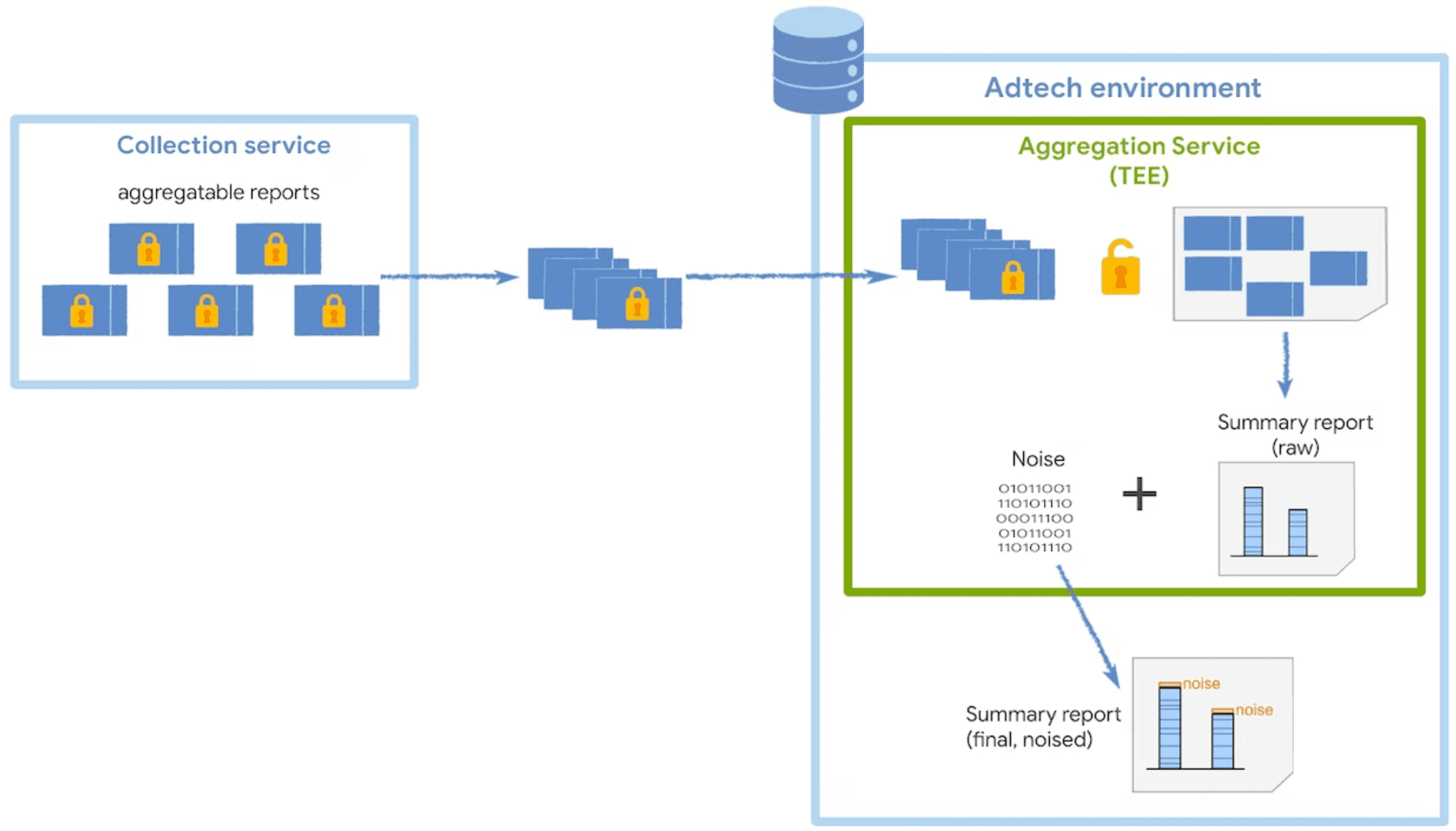
Secure data processing
The Aggregation Service decrypts and combines the collected data from the aggregatable reports, adds noise, and returns the final summary report. This service runs in a trusted execution environment (TEE), which is deployed on a cloud service that supports necessary security measures to protect this data.
The TEE's code is the only place in the Aggregation Service which has access to raw reports—this code will be auditable by security researchers, privacy advocates, and ad techs. To confirm that the TEE is running the exact approved software and that data remains secured, a coordinator performs attestation.
Coordinator attestation of the TEE
The coordinator is an entity responsible for key management and aggregatable report accounting.
A coordinator has several responsibilities:
- Maintain a list of authorized binary images. These images are cryptographic hashes of the Aggregation Service software builds, which Google will periodically release. This will be reproducible so that any party can verify the images are identical to the Aggregation Service builds.
- Operate a key management system. Encryption keys are required for the Chrome on a user's device to encrypt aggregatable reports. Decryption keys are necessary for proving the Aggregation Service code matches the binary images.
- Track the aggregatable reports to prevent reuse in aggregation for summary reports, as reuse may reveal personal identifying information (PII).
"No duplicates" rule
To gain insight into the contents of a specific aggregatable report, an attacker might make multiple copies of the report and include those copies in a single or multiple batches. Because of this, the Aggregation Service enforces a "no duplicates" rule:
- In a batch: An aggregatable report can only appear once within a batch.
- Across batches: Aggregatable reports cannot appear in more than one batch or contribute to more than one summary report.
To accomplish this, the browser assigns each aggregatable report a shared ID.
The browser generates the shared ID from several data points, including: API
version, reporting origin, destination site, source registration time, and
scheduled report time. This data comes from the
shared_info field in the report.
The Aggregation Service confirms that all aggregatable reports with the same shared ID are in the same batch and reports to the coordinator that the shared ID was processed. If multiple batches are created with the same ID, only one batch can be accepted for aggregation, and other batches are rejected.
When you perform a debug run, the "no duplicates" rule is not enforced across batches. In other words, reports from previous batches may appear in a debug run. However, the rule is still enforced within a batch. This allows you to experiment with the service and various batching strategies, without limiting future processing in a production environment.
Noise and scaling
To protect user privacy, the Aggregation Service applies an additive noise mechanism to the raw data from aggregatable reports. This means that a certain amount of statistical noise is added to each aggregate value before its release in a summary report.
While you are not in direct control of the ways noise is added, you can influence the impact of noise on its measurement data.

The noise value is randomly drawn from a Laplace probability distribution, and the distribution is the same regardless of the amount of data collected in aggregatable reports. The more data you collect, the less impact the noise will have on the summary report results. You can multiply the aggregatable report data by a scaling factor to reduce the impact of noise.
To understand how noise is added, your controls, and the impact on your reports, refer to the Contribution budget and Scale up to contribution budget in Working with noise.
Generate summary reports
Summary report generation is dependent on your API usage. Learn more about generating summary reports for the Private Aggregation API and the Attribution Reporting API.
Test the Aggregation Service
We recommend reading the corresponding guide for each API you're testing:
To test the Aggregation Service on AWS, see these instructions.
A local testing tool is also available to process aggregatable reports for Attribution Reporting and the Private Aggregation API.
The Aggregation Service Load Testing Framework provides a suggested testing framework.
Engage and share feedback
The Aggregation Service is a key piece of the Privacy Sandbox measurement APIs. Like other Privacy Sandbox APIs, this is documented and discussed publicly on GitHub.
- Github: Read the explainer, raise questions and participate in the discussion. Also take a look at the Aggregation Service implementation and provide feedback on the implementation.
- Developer support: Ask questions and join discussions on the Privacy Sandbox Developer Support repo.