
في هذا المستند، ستتعرّف على كيفية استخدام بيانات أرقام تعريف الأماكن النموذجية من إحصاءات الأماكن، باستخدام دوال عدد الأماكن، بالإضافة إلى عمليات البحث المستهدَفة عن تفاصيل المكان لتعزيز الثقة في نتائجك.
للحصول على نموذج مرجعي مفصّل لتنفيذ هذا النمط، اطّلِع على دفتر الملاحظات التوضيحي هذا:
 عرض المصدر على GitHub
عرض المصدر على GitHub
النمط المعماري
يمنحك هذا النمط المعماري سير عمل قابلاً للتكرار لسدّ الفجوة بين التحليل الإحصائي العالي المستوى والتحقّق من البيانات الأساسية. من خلال الجمع بين نطاق BigQuery ودقة Places API، يمكنك التحقّق من صحة نتائجك التحليلية بثقة. ويكون ذلك مفيدًا بشكل خاص لاختيار المواقع وتحليل المنافسين وأبحاث السوق، حيث تكون الثقة في البيانات أمرًا بالغ الأهمية.
يتضمّن جوهر هذا النمط أربع خطوات رئيسية:
- إجراء تحليل على نطاق واسع: استخدِم "دالة عدد الأماكن" من "إحصاءات الأماكن" في BigQuery لتحليل بيانات الأماكن على نطاق جغرافي واسع، مثل مدينة أو منطقة بأكملها.
- عزل العيّنات واستخراجها: حدِّد المناطق التي تهمّك (مثل "المناطق الساخنة" ذات الكثافة العالية) من النتائج المجمّعة واستخرِج
sample_place_idsالتي توفّرها الدالة. - استرداد التفاصيل الأساسية: استخدِم أرقام تعريف الأماكن المستخرَجة لإجراء طلبات بحث مستهدَفة إلى Place Details API لاسترداد تفاصيل غنية، وواقعية لكل مكان.
- إنشاء تمثيل مرئي مجمّع: ضَع بيانات المكان التفصيلية أعلى الخريطة الإحصائية الأولية العالية المستوى للتحقّق مرئيًا من أنّ الأعداد المجمّعة تعكس الواقع على الأرض.
سير عمل الحلّ
يتيح لك سير العمل هذا سدّ الفجوة بين المؤشرات على المستوى الكلّي والحقائق على المستوى الجزئي. تبدأ بعرض إحصائي واسع النطاق وتنتقل بشكل استراتيجي إلى مستوى أكثر تفصيلاً للتحقّق من البيانات باستخدام أمثلة محدّدة من العالم الحقيقي.
تحليل كثافة الأماكن على نطاق واسع باستخدام "إحصاءات الأماكن"
تتمثّل خطوتك الأولى في فهم المشهد على مستوى عالٍ. بدلاً من استرداد آلاف النقاط الفردية المثيرة للاهتمام، يمكنك إجراء طلب بحث واحد للحصول على ملخّص إحصائي.
تُعدّ دالة PLACES_COUNT_PER_H3
من "إحصاءات الأماكن" مثالية لذلك. فهي تجمع أعداد النقاط المثيرة للاهتمام في نظام شبكة سداسية (H3)، ما يتيح لك تحديد المناطق ذات الكثافة العالية أو المنخفضة بسرعة استنادًا إلى المعايير المحدّدة (مثل المطاعم ذات التقييم العالي التي تعمل).
في ما يلي مثال على طلب البحث. يُرجى العِلم أنّه سيُطلب منك تقديم الموقع الجغرافي لمنطقة البحث. يمكن استخدام مجموعة بيانات مفتوحة، مثل Overture Maps Data BigQuery public dataset لاسترداد بيانات الحدود الجغرافية.
بالنسبة إلى حدود مجموعات البيانات المفتوحة التي يتم استخدامها بشكل متكرّر، ننصحك بتخزينها في جدول في مشروعك الخاص. يؤدي ذلك إلى خفض تكاليف BigQuery بشكل كبير وتحسين أداء طلبات البحث.
-- This query counts all highly-rated, operational restaurants
-- across a large geography, grouping them into H3 cells.
SELECT *
FROM
`places_insights___gb.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'types', ['restaurant'],
'business_status', ['OPERATIONAL'],
'min_rating', 3.5
)
);
الفلترة والتحقّق من الصحة حسب رقم تعريف العلامة التجارية
إذا أردت التحقّق من صحة الأعداد وأرقام تعريف الأماكن النموذجية لعلامات تجارية محدّدة، قدِّم قائمة بأرقام تعريف العلامات التجارية باستخدام الفلتر brand_ids.
للحصول على رقم تعريف العلامة التجارية المستهدَفة، اطلُب جدول brands في BigQuery:
SELECT id, name
FROM `YOUR_PROJECT.places_insights___us.brands`
WHERE LOWER(name) LIKE "%starbucks%";
بعد استرداد رقم تعريف العلامة التجارية المستهدَفة (على سبيل المثال، "1413758728321880760"
لـ Starbucks)، مرِّره داخل مصفوفة الفلتر brand_ids
SELECT *
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
'geography', your_defined_geography,
'h3_resolution', 8,
'brand_ids', ["1413758728321880760"]
)
);
في الخطوة 3، وهي التحقّق من البيانات الأساسية، بدلاً من التأكّد من أنّ المكان يطابق فئات عامة، يمكنك مقارنة الاسم المعروض الذي تعرضه Place Details API بالاسم المتوقّع للعلامة التجارية آليًا باستخدام تطابق التعبير العادي. على سبيل المثال، يمكنك مقارنة الحقل response.display_name.text.
تمنحك نتيجة طلب البحث هذا جدولاً بخلايا H3 وعدد الأماكن داخل كل خلية، ما يشكّل أساس خريطة حرارية للكثافة.
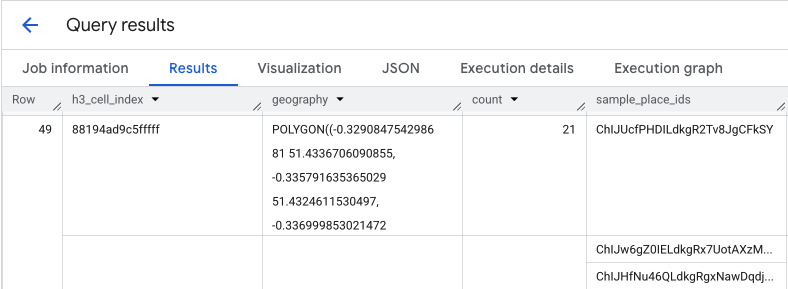
عزل المناطق الساخنة واستخراج أرقام تعريف الأماكن النموذجية
تعرض نتيجة الدالة PLACES_COUNT_PER_H3 أيضًا مصفوفة من sample_place_ids، يصل إلى 250 رقم تعريف مكان لكل عنصر من عناصر الردّ. تربط أرقام التعريف هذه الإحصاءات المجمّعة بالأماكن الفردية التي تساهم فيها.
يمكن أن يحدّد نظامك أولاً الخلايا الأكثر صلةً من طلب البحث الأولي.
على سبيل المثال، يمكنك اختيار أفضل 20 خلية بأعلى الأعداد. بعد ذلك، من هذه المناطق الساخنة، يمكنك دمج sample_place_ids في قائمة واحدة.
تمثّل هذه القائمة عينة منسّقة من النقاط المثيرة للاهتمام الأكثر إثارةً للاهتمام من المناطق الأكثر صلةً، ما يجهّزك للتحقّق المستهدَف.
إذا كنت تعالج نتائج BigQuery في Python باستخدام pandas DataFrame، يكون منطق استخراج أرقام التعريف هذه بسيطًا:
# Assume 'results_df' is a pandas DataFrame from your BigQuery query.
# 1. Identify the 20 busiest H3 cells by sorting and taking the top results.
top_hotspots_df = results_df.sort_values(by='count', ascending=False).head(20)
# 2. Extract and flatten the lists of sample_place_ids from these hotspots.
# The .explode() function creates a new row for each ID in the lists.
all_sample_ids = top_hotspots_df['sample_place_ids'].explode()
# 3. Create a final list of unique Place IDs to verify.
place_ids_to_verify = all_sample_ids.unique().tolist()
print(f"Consolidated {len(place_ids_to_verify)} unique Place IDs for spot-checking.")
يمكن تطبيق منطق مشابه في حال استخدام لغات برمجة أخرى.
استرداد التفاصيل الأساسية باستخدام Places API
باستخدام قائمتك المجمّعة من "أرقام تعريف الأماكن"، يمكنك الآن الانتقال من التحليلات على نطاق واسع إلى استرداد البيانات المحدّدة. ستستخدم أرقام التعريف هذه لطلب Place Details API للحصول على معلومات مفصّلة عن كل موقع جغرافي نموذجي.
هذه خطوة مهمة للتحقّق من الصحة. في حين أنّ "إحصاءات الأماكن" أخبرتك بعدد المطاعم في منطقة معيّنة، يخبرك Places API بأسماء هذه المطاعم، ويقدّم اسمها وعنوانها الدقيق وخطوط الطول والعرض وتقييم المستخدمين وحتى رابطًا مباشرًا إلى موقعها الجغرافي على "خرائط Google". يؤدي ذلك إلى إثراء بياناتك النموذجية، وتحويل أرقام التعريف المجرّدة إلى أماكن ملموسة يمكن التحقّق منها.
للاطّلاع على القائمة الكاملة للبيانات المتاحة من Place Details API والتكلفة المرتبطة باستردادها، راجِع مستندات واجهة برمجة التطبيقات documentation.
سيبدو طلب Places API لرقم تعريف معيّن باستخدام مكتبة برامج Python العميل على النحو التالي. لمزيد من التفاصيل، اطّلِع على أمثلة مكتبة برامج Places API (الجديدة).
# A request to fetch details for a single Place ID.
request = {"name": f"places/{place_id}"}
# Define the fields you want returned in the response as a comma-separated string.
fields_to_request = "formattedAddress,location,displayName,googleMapsUri"
# The response contains ground truth data.
response = places_client.get_place(
request=request,
metadata=[("x-goog-fieldmask", fields_to_request)]
)
يُرجى العِلم أنّ الحقول في هذا الطلب تجلب البيانات من رمزَي تخزين تعريفي مختلفَين للفوترة.
formattedAddressوlocationجزء من رمز التخزين التعريفي Place Details Essentials.displayNameوgoogleMapsUriجزء من رمز التخزين التعريفي Place Details Pro.
عندما يتضمّن طلب Place Details واحد حقولاً من رموز تخزين تعريفية متعددة، تتم فوترة الطلب بالكامل بسعر رمز التخزين التعريفي الأعلى مستوى. لذلك، سيتم تحصيل رسوم هذا الطلب المحدّد كطلب Place Details Pro.
للتحكّم في التكاليف، استخدِم دائمًا FieldMask لطلب الحقول التي يتطلبها تطبيقك فقط.
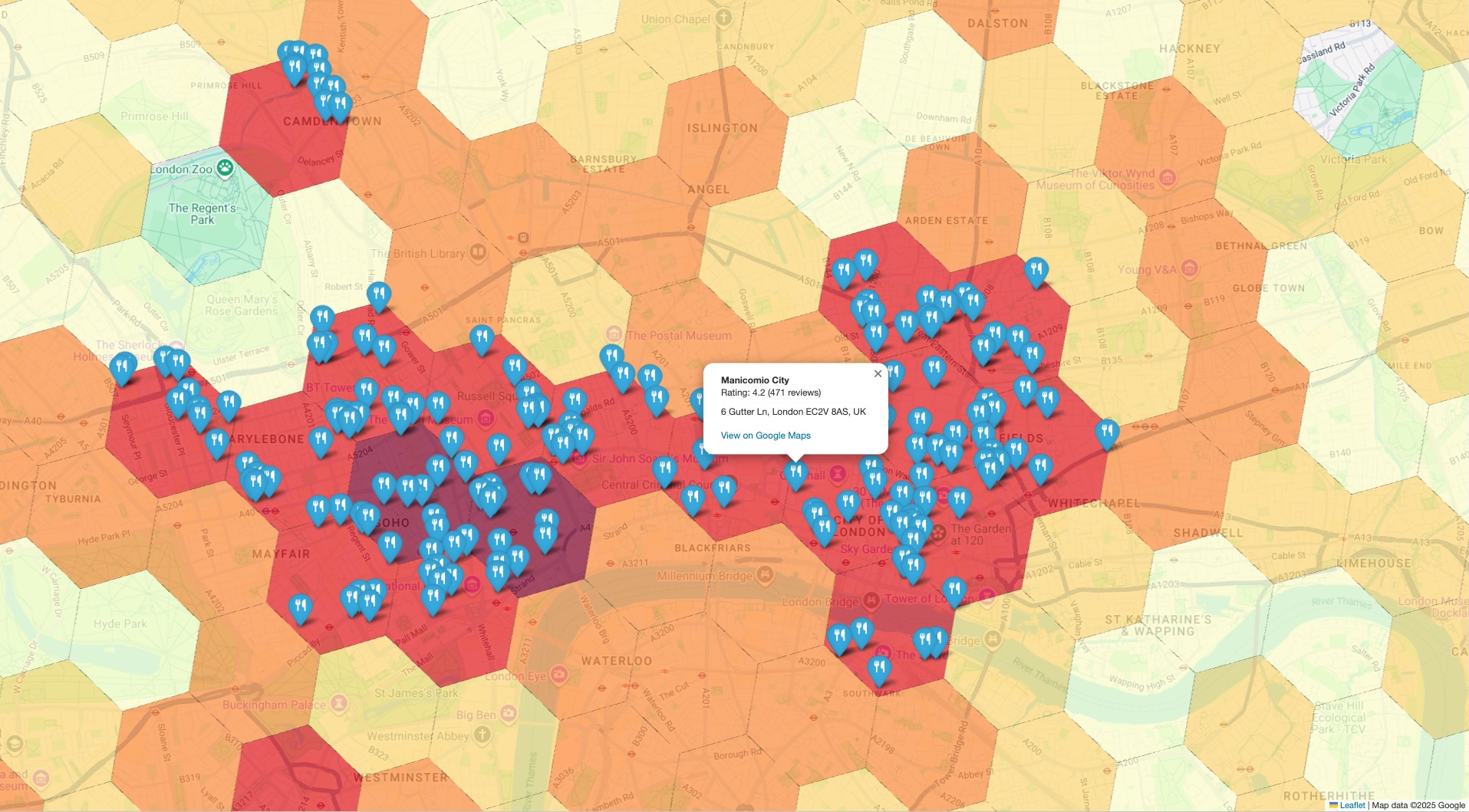
إنشاء تمثيل مرئي مجمّع للتحقّق من الصحة
الخطوة الأخيرة هي جمع مجموعتَي البيانات معًا في عرض واحد. يوفّر ذلك طريقة فورية وبديهية للتحقّق من صحة تحليلك الأولي. يجب أن يتضمّن التمثيل المرئي طبقتَين:
- الطبقة الأساسية: خريطة توزيعية أو خريطة حرارية تم إنشاؤها من نتائج
PLACES_COUNT_PER_H3الأولية، تعرض الكثافة الإجمالية للأماكن في نطاقك الجغرافي. - الطبقة العلوية: مجموعة من العلامات الفردية لكل نقطة مثيرة للاهتمام نموذجية، يتم رسمها باستخدام الإحداثيات الدقيقة التي تم استردادها من Places API في الخطوة السابقة.
يتم التعبير عن منطق إنشاء هذا العرض المجمّع في مثال التعليمات البرمجية الزائفة هذا:
# Assume 'h3_density_data' is your aggregated data from Step 1.
# Assume 'detailed_places_data' is your list of place objects from Step 3.
# Create the base choropleth map from the H3 density data.
# The 'count' column determines the color of each hexagon.
combined_map = create_choropleth_map(
data=h3_density_data,
color_by_column='count'
)
# Iterate through the detailed place data to add individual markers.
for place in detailed_places_data:
# Construct the popup information with key details and a link.
popup_html = f"""
<b>{place.name}</b><br>
Address: {place.address}<br>
<a href="{place.google_maps_uri}" target="_blank">View on Maps</a>
"""
# Add a marker for the current place to the base map.
combined_map.add_marker(
location=[place.latitude, place.longitude],
popup=popup_html,
tooltip=place.name
)
# Display the final map with both layers.
display(combined_map)
من خلال وضع العلامات المحدّدة للبيانات الأساسية أعلى خريطة الكثافة العالية المستوى، يمكنك التأكّد على الفور من أنّ المناطق التي تم تحديدها على أنّها مناطق ساخنة تحتوي في الواقع على تركيز عالٍ من الأماكن التي تحلّلها. يؤدي هذا التأكيد المرئي إلى تعزيز الثقة بشكل كبير في استنتاجاتك المستندة إلى البيانات.
الخاتمة
يوفّر هذا النمط المعماري طريقة قوية وفعّالة للتحقّق من صحة الإحصاءات الجغرافية المكانية على نطاق واسع. من خلال الاستفادة من "إحصاءات الأماكن" لإجراء تحليل واسع النطاق وقابل للتوسّع وPlace Details API للتحقّق من البيانات الأساسية المستهدَفة، يمكنك إنشاء حلقة ملاحظات قوية. يضمن ذلك أنّ قراراتك الاستراتيجية، سواء كانت في اختيار موقع متجر بيع بالتجزئة أو في التخطيط اللوجستي، تستند إلى بيانات ليست ذات أهمية إحصائية فحسب، بل يمكن أيضًا التحقّق من دقتها.
الخطوات التالية
- استكشِف "دوال عدد الأماكن " الأخرى لمعرفة كيف يمكنها الإجابة عن أسئلة تحليلية مختلفة.
- راجِع مستندات Places API لاكتشاف الحقول الأخرى التي يمكنك طلبها لزيادة إثراء تحليلك.
المساهمون
هنريك صمام | مهندس تجربة المطوّرين