
Introdução
Este documento descreve como criar uma solução de seleção de locais combinando o conjunto de dados do Insights de Lugares, dados geoespaciais públicos no BigQuery, e a API Place Details.
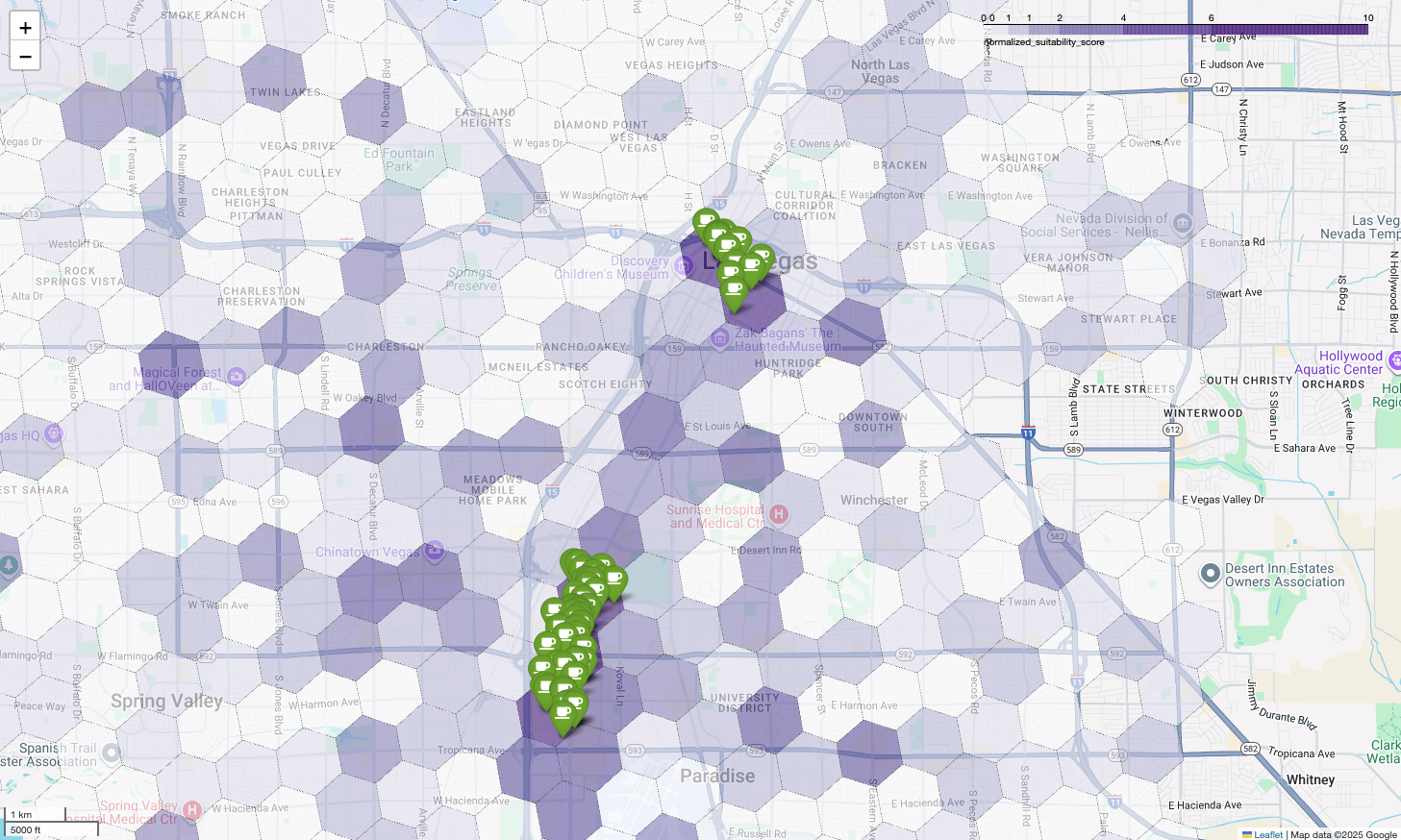
O mapa acima ilustra a saída de uma demonstração apresentada no Google Cloud Next 2025, que está disponível no YouTube. É possível executar o código usado para gerar esses resultados usando o notebook de exemplo.
 Ver código-fonte no GitHub
Ver código-fonte no GitHub
O desafio das empresas
Imagine que você tem uma rede de cafeterias de sucesso e quer expandir para um novo estado, como Nevada, onde você não tem presença. Abrir um novo local é um investimento significativo, e tomar uma decisão baseada em dados é fundamental para o sucesso. Por onde começar?
Este guia orienta você em uma análise de várias camadas para identificar o local ideal para uma nova cafeteria. Vamos começar com uma visão geral do estado, restringir progressivamente nossa pesquisa a um condado/município e zona comercial específicos e, por fim, realizar uma análise hiperlocal para classificar áreas individuais e identificar lacunas de mercado mapeando concorrentes.
Fluxo de trabalho da solução
Esse processo segue um funil lógico, começando de forma ampla e ficando cada vez mais granular para refinar a área de pesquisa e aumentar a confiança na seleção final do site.
Pré-requisitos e configuração do ambiente
Antes de mergulhar na análise, você precisa de um ambiente com alguns recursos importantes. Embora este guia mostre uma implementação usando SQL e Python, os princípios gerais podem ser aplicados a outras pilhas de tecnologia.
Como pré-requisito, verifique se o ambiente pode:
- Executar consultas no BigQuery.
- Acessar o Insights de Lugares. Consulte Configurar o Insights de Lugares para mais informações.
- Inscrever-se em conjuntos de dados públicos de
bigquery-public-datae do US Census Bureau County Population Totals
Você também precisa visualizar dados geoespaciais em um mapa, o que é fundamental para interpretar os resultados de cada etapa analítica. Existem muitas maneiras de fazer isso. Você pode usar ferramentas de BI, como Looker Studio que se conecta diretamente ao BigQuery, ou linguagens de ciência de dados, como Python.
Análise no nível do estado: encontrar o melhor condado
Nossa primeira etapa é uma análise ampla para identificar o condado mais promissor em Nevada. Vamos definir promissor como uma combinação de alta população e alta densidade de restaurantes existentes, o que indica uma forte cultura de alimentos e bebidas.
Nossa consulta do BigQuery realiza isso aproveitando os componentes de endereço integrados disponíveis no conjunto de dados do Insights de Lugares. A consulta conta restaurantes filtrando os dados para incluir apenas lugares no estado de Nevada, usando o campo administrative_area_level_1_name. Em seguida, ela refina ainda mais esse conjunto para incluir apenas lugares em que a matriz de tipos contém "restaurant". Por fim, ela agrupa esses resultados por nome do condado (administrative_area_level_2_name) para produzir uma contagem para cada condado. Essa abordagem usa a estrutura de endereço integrada e pré-indexada do conjunto de dados.
Este trecho mostra como unimos geometrias de condado com o Insights de Lugares e filtramos um tipo de lugar específico, restaurant:
SELECT WITH AGGREGATION_THRESHOLD
administrative_area_level_2_name,
COUNT(*) AS restaurant_count
FROM
`places_insights___us.places`
WHERE
-- Filter for the state of Nevada
administrative_area_level_1_name = 'Nevada'
-- Filter for places that are restaurants
AND 'restaurant' IN UNNEST(types)
-- Filter for operational places only
AND business_status = 'OPERATIONAL'
-- Exclude rows where the county name is null
AND administrative_area_level_2_name IS NOT NULL
GROUP BY
administrative_area_level_2_name
ORDER BY
restaurant_count DESC
Uma contagem bruta de restaurantes não é suficiente. Precisamos equilibrá-la com dados de população para ter uma noção real da saturação e da oportunidade de mercado. Vamos usar dados de população do US Census Bureau County Population Totals (link em inglês).
Para comparar essas duas métricas muito diferentes (uma contagem de lugares versus um grande número de população), usamos a normalização min-max. Essa técnica dimensiona as duas métricas para um intervalo comum (0 a 1). Em seguida, combinamos todos eles em um único
normalized_score, atribuindo a cada métrica um peso de 50% para uma comparação equilibrada.
Este trecho mostra a lógica principal para calcular a pontuação. Ele combina a população normalizada e as contagens de restaurantes:
(
-- Normalize restaurant count (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(restaurant_count - min_restaurants, max_restaurants - min_restaurants) * 0.5
+
-- Normalize population (scales to a 0-1 value) and apply 50% weight
SAFE_DIVIDE(population_2023 - min_pop, max_pop - min_pop) * 0.5
) AS normalized_score
Depois de executar a consulta completa, uma lista dos condados, a contagem de restaurantes, a população e a pontuação normalizada são retornadas. A ordenação por normalized_score
DESC revela o condado de Clark como o vencedor claro para uma investigação mais aprofundada como o
principal concorrente.
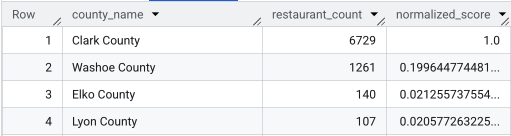
Esta captura de tela mostra os quatro principais condados por pontuação normalizada. A contagem bruta da população foi propositalmente omitida deste exemplo.
Análise no nível do condado: encontrar as zonas comerciais mais movimentadas
Agora que identificamos o condado de Clark, a próxima etapa é aumentar o zoom para encontrar os códigos postais com a maior atividade comercial. Com base nos dados das nossas cafeterias atuais, sabemos que a performance é melhor quando estão localizadas perto de uma alta densidade de grandes marcas. Portanto, vamos usar isso como um proxy para alto tráfego de pedestres.
Essa consulta usa a tabela brands no Insights de Lugares, que contém informações sobre marcas específicas. Essa tabela pode ser
consultada para descobrir a lista de
marcas compatíveis. Primeiro, definimos uma lista das nossas marcas-alvo e, em seguida, unimos isso ao conjunto de dados principal do Insights de Lugares para contar quantas dessas lojas específicas estão em cada código postal no condado de Clark.
A maneira mais eficiente de fazer isso é com uma abordagem de duas etapas:
- Primeiro, vamos realizar uma agregação rápida e não geoespacial para contar as marcas em cada código postal.
- Em segundo lugar, vamos unir esses resultados a um conjunto de dados público para receber os limites do mapa para visualização.
Contar marcas usando o campo postal_code_names
Essa primeira consulta realiza a lógica de contagem principal. Ela filtra lugares no condado de Clark e, em seguida, desaninha a matriz postal_code_names para agrupar as contagens de marcas por código postal.
WITH brand_names AS (
-- First, select the chains we are interested in by name
SELECT
id,
name
FROM
`places_insights___us.brands`
WHERE
name IN ('7-Eleven', 'CVS', 'Walgreens', 'Subway Restaurants', "McDonald's")
)
SELECT WITH AGGREGATION_THRESHOLD
postal_code,
COUNT(*) AS total_brand_count
FROM
`places_insights___us.places` AS places_table,
-- Unnest the built-in postal code and brand ID arrays
UNNEST(places_table.postal_code_names) AS postal_code,
UNNEST(places_table.brand_ids) AS brand_id
JOIN
brand_names
ON brand_names.id = brand_id
WHERE
-- Filter directly on the administrative area fields in the places table
places_table.administrative_area_level_2_name = 'Clark County'
AND places_table.administrative_area_level_1_name = 'Nevada'
GROUP BY
postal_code
ORDER BY
total_brand_count DESC
A saída é uma tabela de códigos postais e as contagens de marcas correspondentes.
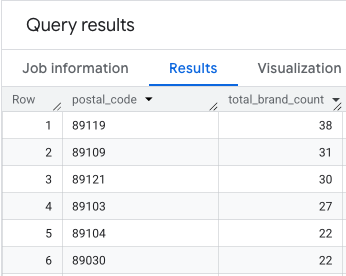
Anexar geometrias de código postal para mapeamento
Agora que temos as contagens, podemos receber as formas de polígono necessárias para a visualização. Essa segunda consulta usa a primeira consulta, a envolve em uma expressão de tabela comum (CTE, na sigla em inglês) chamada brand_counts_by_zip e une os resultados à
tabela pública geo_us_boundaries.zip_codes table. Isso anexa com eficiência a geometria às nossas contagens pré-calculadas.
WITH brand_counts_by_zip AS (
-- This will be the entire query from the previous step, without the final ORDER BY (excluded for brevity).
. . .
)
-- Now, join the aggregated results to the boundaries table
SELECT
counts.postal_code,
counts.total_brand_count,
-- Simplify the geometry for faster rendering in maps
ST_SIMPLIFY(zip_boundaries.zip_code_geom, 100) AS geography
FROM
brand_counts_by_zip AS counts
JOIN
`bigquery-public-data.geo_us_boundaries.zip_codes` AS zip_boundaries
ON counts.postal_code = zip_boundaries.zip_code
ORDER BY
counts.total_brand_count DESC
A saída é uma tabela de códigos postais, as contagens de marcas correspondentes e a geometria do código postal.
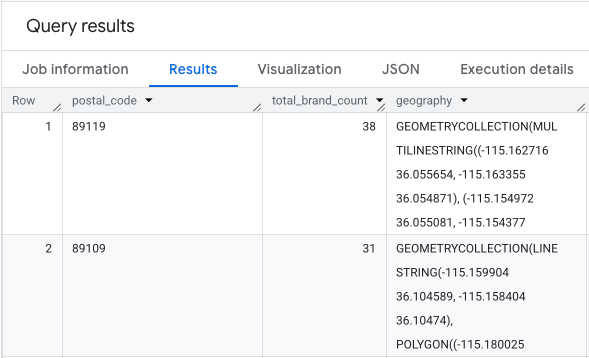
Podemos visualizar esses dados como um mapa de calor. As áreas vermelhas mais escuras indicam uma maior concentração das nossas marcas-alvo, apontando para as zonas mais densas comercialmente em Las Vegas.
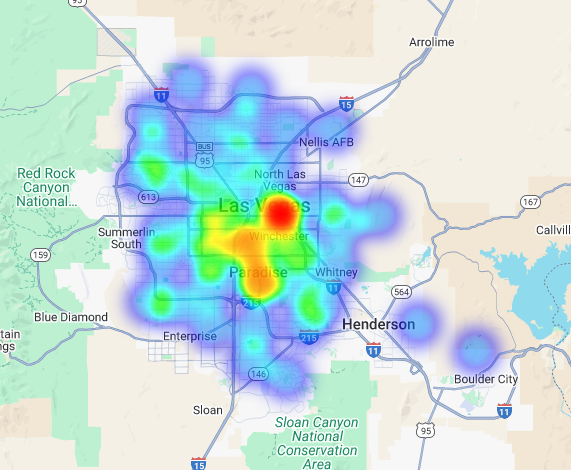
Análise hiperlocal: classificar áreas de grade individuais
Depois de identificar a área geral de Las Vegas, é hora de uma análise granular. É aqui que colocamos nosso conhecimento comercial específico. Sabemos que uma ótima cafeteria prospera perto de outras empresas que estão ocupadas durante nossos horários de pico, como o final da manhã e o horário do almoço.
Nossa próxima consulta é muito específica. Ela começa criando uma grade hexagonal refinada na área metropolitana de Las Vegas usando o índice geoespacial H3 padrão (na resolução 8) para analisar a área em um nível micro. A consulta primeiro identifica todas as empresas complementares que estão abertas durante nosso horário de pico (segunda-feira, das 10h às 14h).
Em seguida, aplicamos uma pontuação ponderada a cada tipo de lugar. Um restaurante próximo é mais valioso para nós do que uma loja de conveniência, então ele recebe um multiplicador maior. Isso nos dá uma suitability_score personalizada para cada pequena área.
Este trecho destaca a lógica de pontuação ponderada, que faz referência a uma flag pré-calculada (is_open_monday_window) para a verificação do horário de funcionamento:
. . .
(
COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 +
COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 +
COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 +
COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 +
COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7
) AS suitability_score
. . .
Abrir para consulta completa
-- This query calculates a custom 'suitability score' for different areas in the Las Vegas -- metropolitan area to identify prime commercial zones. It uses a weighted model based -- on the density of specific business types that are open during a target time window. -- Step 1: Pre-filter the dataset to only include relevant places. -- This CTE finds all places in our target localities (Las Vegas, Spring Valley, etc.) and -- adds a boolean flag 'is_open_monday_window' for those open during the target time. WITH PlacesInTargetAreaWithOpenFlag AS ( SELECT point, types, EXISTS( SELECT 1 FROM UNNEST(regular_opening_hours.monday) AS monday_hours WHERE monday_hours.start_time <= TIME '10:00:00' AND monday_hours.end_time >= TIME '14:00:00' ) AS is_open_monday_window FROM `places_insights___us.places` WHERE EXISTS ( SELECT 1 FROM UNNEST(locality_names) AS locality WHERE locality IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester') ) AND administrative_area_level_1_name = 'Nevada' ), -- Step 2: Aggregate the filtered places into H3 cells and calculate the suitability score. -- Each place's location is converted to an H3 index (at resolution 8). The query then -- calculates a weighted 'suitability_score' and individual counts for each business type -- within that cell. TileScores AS ( SELECT WITH AGGREGATION_THRESHOLD -- Convert each place's geographic point into an H3 cell index. `carto-os.carto.H3_FROMGEOGPOINT`(point, 8) AS h3_index, -- Calculate the weighted score based on the count of places of each type -- that are open during the target window. ( COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) * 8 + COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) * 3 + COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) * 7 + COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) * 6 + COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) * 7 ) AS suitability_score, -- Also return the individual counts for each category for detailed analysis. COUNTIF('restaurant' IN UNNEST(types) AND is_open_monday_window) AS restaurant_count, COUNTIF('convenience_store' IN UNNEST(types) AND is_open_monday_window) AS convenience_store_count, COUNTIF('bar' IN UNNEST(types) AND is_open_monday_window) AS bar_count, COUNTIF('tourist_attraction' IN UNNEST(types) AND is_open_monday_window) AS tourist_attraction_count, COUNTIF('casino' IN UNNEST(types) AND is_open_monday_window) AS casino_count FROM -- CHANGED: This now references the CTE with the expanded area. PlacesInTargetAreaWithOpenFlag -- Group by the H3 index to ensure all calculations are per-cell. GROUP BY h3_index ), -- Step 3: Find the maximum suitability score across all cells. -- This value is used in the next step to normalize the scores to a consistent scale (e.g., 0-10). MaxScore AS ( SELECT MAX(suitability_score) AS max_score FROM TileScores ) -- Step 4: Assemble the final results. -- This joins the scored tiles with the max score, calculates the normalized score, -- generates the H3 cell's polygon geometry for mapping, and orders the results. SELECT ts.h3_index, -- Generate the hexagonal polygon for the H3 cell for visualization. `carto-os.carto.H3_BOUNDARY`(ts.h3_index) AS h3_geography, ts.restaurant_count, ts.convenience_store_count, ts.bar_count, ts.tourist_attraction_count, ts.casino_count, ts.suitability_score, -- Normalize the score to a 0-10 scale for easier interpretation. ROUND( CASE WHEN ms.max_score = 0 THEN 0 ELSE (ts.suitability_score / ms.max_score) * 10 END, 2 ) AS normalized_suitability_score FROM -- A cross join is efficient here as MaxScore contains only one row. TileScores ts, MaxScore ms -- Display the highest-scoring locations first. ORDER BY normalized_suitability_score DESC;
A visualização dessas pontuações em um mapa revela locais vencedores claros. Os blocos roxos mais escuros, principalmente perto da Las Vegas Strip e do centro da cidade, são as áreas com maior potencial para nossa nova cafeteria.
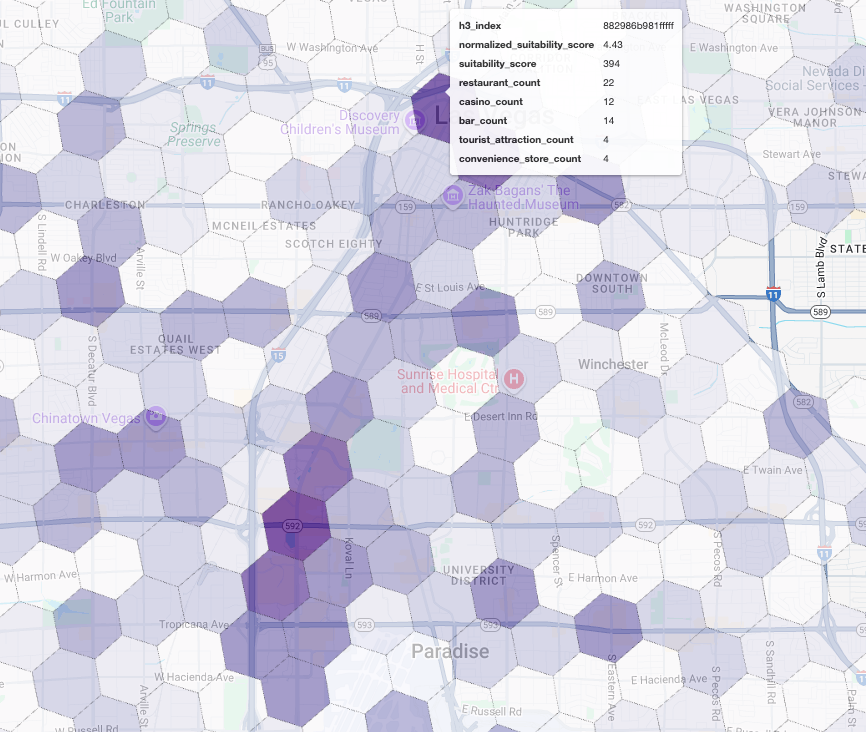
Análise de concorrentes: identificar cafeterias existentes
Nosso modelo de adequação identificou com sucesso as zonas mais promissoras, mas uma pontuação alta por si só não garante o sucesso. Agora precisamos sobrepor isso com dados de concorrentes. O local ideal é uma área de alto potencial com baixa densidade de cafeterias existentes, já que estamos procurando uma lacuna de mercado clara.
Para isso, usamos a
PLACES_COUNT_PER_H3
função. Essa função foi projetada para retornar com eficiência as contagens de lugares em uma geografia especificada, por célula H3.
Primeiro, definimos dinamicamente a geografia para toda a área metropolitana de Las Vegas.
Em vez de depender de uma única localidade, consultamos o conjunto de dados público do Overture Maps para receber os limites de Las Vegas e suas principais localidades vizinhas, mesclando-as em um único polígono com ST_UNION_AGG. Em seguida, transmitimos essa área para a função, pedindo que ela conte todas as cafeterias operacionais.
Essa consulta define a área metropolitana e chama a função para receber contagens de cafeterias em células H3:
-- Define a variable to hold the combined geography for the Las Vegas metro area.
DECLARE las_vegas_metro_area GEOGRAPHY;
-- Set the variable by fetching the shapes for the five localities from Overture Maps
-- and merging them into a single polygon using ST_UNION_AGG.
SET las_vegas_metro_area = (
SELECT
ST_UNION_AGG(geometry)
FROM
`bigquery-public-data.overture_maps.division_area`
WHERE
country = 'US'
AND region = 'US-NV'
AND names.primary IN ('Las Vegas', 'Spring Valley', 'Paradise', 'North Las Vegas', 'Winchester')
);
-- Call the PLACES_COUNT_PER_H3 function with our defined area and parameters.
SELECT
*
FROM
`places_insights___us.PLACES_COUNT_PER_H3`(
JSON_OBJECT(
-- Use the metro area geography we just created.
'geography', las_vegas_metro_area,
-- Specify 'coffee_shop' as the place type to count.
'types', ["coffee_shop"],
-- Best practice: Only count places that are currently operational.
'business_status', ['OPERATIONAL'],
-- Set the H3 grid resolution to 8.
'h3_resolution', 8
)
);
A função retorna uma tabela que inclui o índice de célula H3, a geometria, a contagem total de cafeterias e uma amostra dos IDs de lugar:
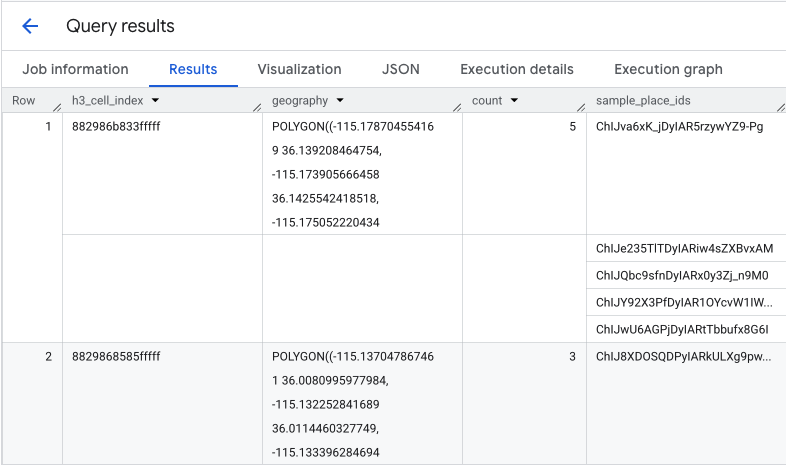
Embora a contagem agregada seja útil, é essencial ver os concorrentes reais.
É aqui que fazemos a transição do conjunto de dados do Insights de Lugares para a API Places. Ao extrair os
sample_place_ids das células com a maior pontuação de adequação normalizada,
podemos chamar a API Place Details para recuperar detalhes avançados de cada concorrente, como nome, endereço, classificação e local.
Isso exige a comparação dos resultados da consulta anterior, em que a pontuação de adequação foi gerada, e a consulta PLACES_COUNT_PER_H3. O índice de célula H3 pode ser usado para receber as contagens e os IDs de cafeterias das células com a maior pontuação de adequação normalizada.
Este código Python demonstra como essa comparação pode ser realizada.
# Isolate the Top 5 Most Suitable H3 Cells
top_suitability_cells = gdf_suitability.head(5)
# Extract the 'h3_index' values from these top 5 cells into a list.
top_h3_indexes = top_suitability_cells['h3_index'].tolist()
print(f"The top 5 H3 indexes are: {top_h3_indexes}")
# Now, we find the rows in our DataFrame where the
# 'h3_cell_index' matches one of the indexes from our top 5 list.
coffee_counts_in_top_zones = gdf_coffee_shops[
gdf_coffee_shops['h3_cell_index'].isin(top_h3_indexes)
]
Agora temos a lista de IDs de lugar para cafeterias que já existem nas células H3 com a maior pontuação de adequação. Mais detalhes sobre cada lugar podem ser solicitados.
Isso pode ser feito enviando uma solicitação diretamente para a API
Place Details para cada ID
de lugar ou usando uma Biblioteca
de cliente para fazer a
chamada. Defina o
FieldMask
parâmetro para solicitar apenas os dados necessários.
Por fim, combinamos tudo em uma única visualização poderosa. Plotamos nosso mapa coroplético de adequação roxo como a camada de base e, em seguida, adicionamos alfinetes para cada cafeteria individual recuperada da API Places. Esse mapa final oferece uma visão geral que sintetiza toda a nossa análise: as áreas roxas escuras mostram o potencial, e os alfinetes verdes mostram a realidade do mercado atual.
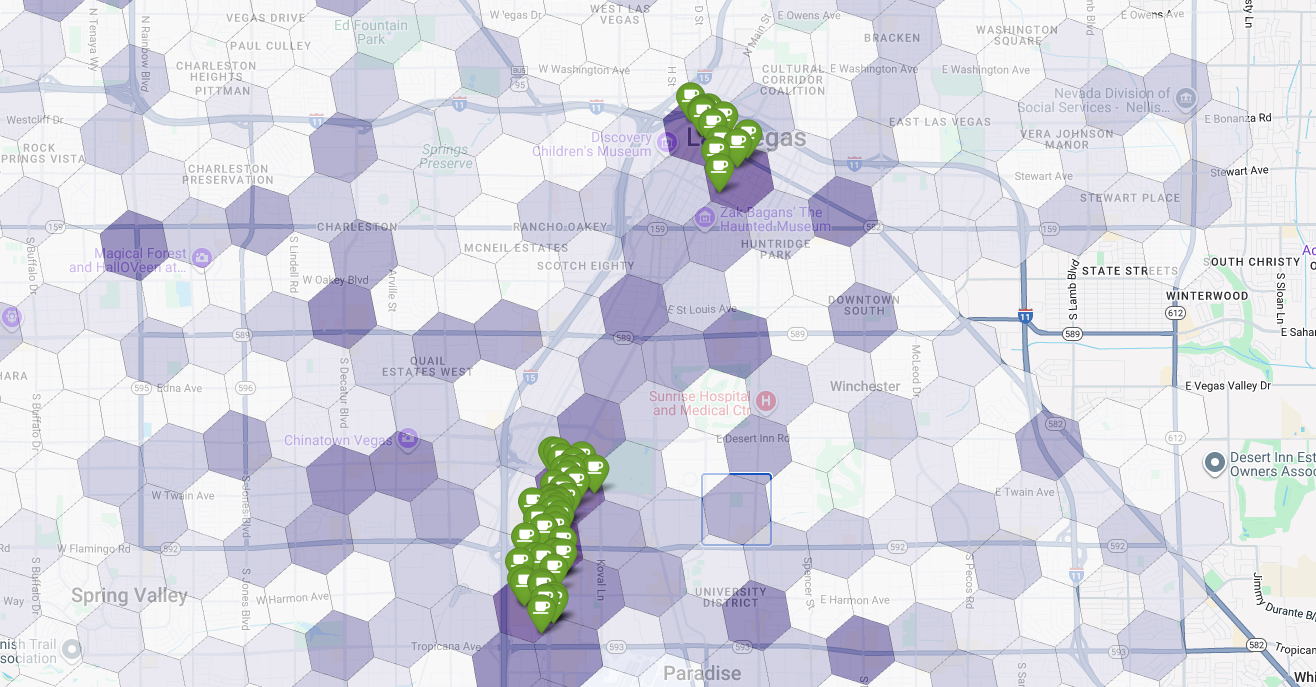
Ao procurar células roxas escuras com poucos ou nenhum alfinete, podemos identificar com confiança as áreas exatas que representam a melhor oportunidade para nosso novo local.
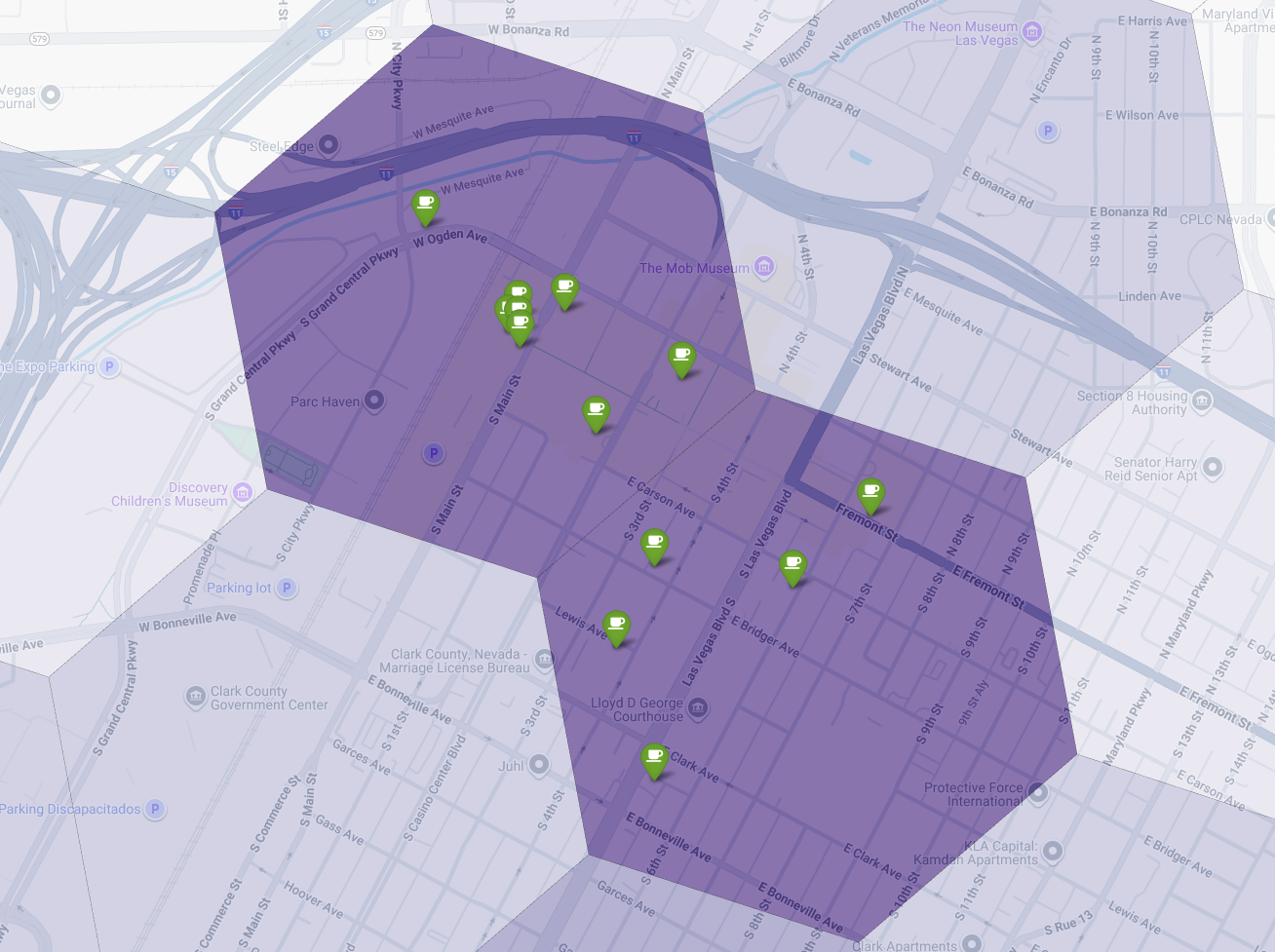
As duas células acima têm uma pontuação de adequação alta, mas algumas lacunas claras que podem ser locais potenciais para nossa nova cafeteria.
Conclusão
Neste documento, passamos de uma pergunta estadual de onde expandir? para uma resposta local baseada em dados. Ao sobrepor diferentes conjuntos de dados e aplicar uma lógica de negócios personalizada, você pode reduzir sistematicamente o risco associado a uma decisão comercial importante. Esse fluxo de trabalho, que combina a escala do BigQuery, a riqueza do Insights de Lugares e os detalhes em tempo real da API Places, fornece um modelo poderoso para qualquer organização que queira usar a inteligência de localização para crescimento estratégico.
Próximas etapas
- Adapte esse fluxo de trabalho com sua própria lógica de negócios, geografias-alvo e conjuntos de dados proprietários.
- Explore outros campos de dados no conjunto de dados do Insights de Lugares, como contagens de avaliações, níveis de preços e classificações de usuários, para enriquecer ainda mais seu modelo.
- Automatize esse processo para criar um painel de seleção de sites interno que possa ser usado para avaliar novos mercados de forma dinâmica.
Saiba mais na documentação:
Colaboradores
Henrik Valve | Engenheiro de DevX